Google BigQuery
On This Page
Google BigQuery is a fully-managed, serverless data warehouse that enables scalable analysis over huge sizes of data. Hevo allows users to migrate multiple datasets and tables within a BigQuery project to any other data warehouse of their choice.
Organization of data in BigQuery
Google BigQuery uses Projects to store data. An organization can have multiple projects associated with it. However, each Pipeline can be associated with only one BigQuery project.
Within a project, the data tables are organized into units called datasets.
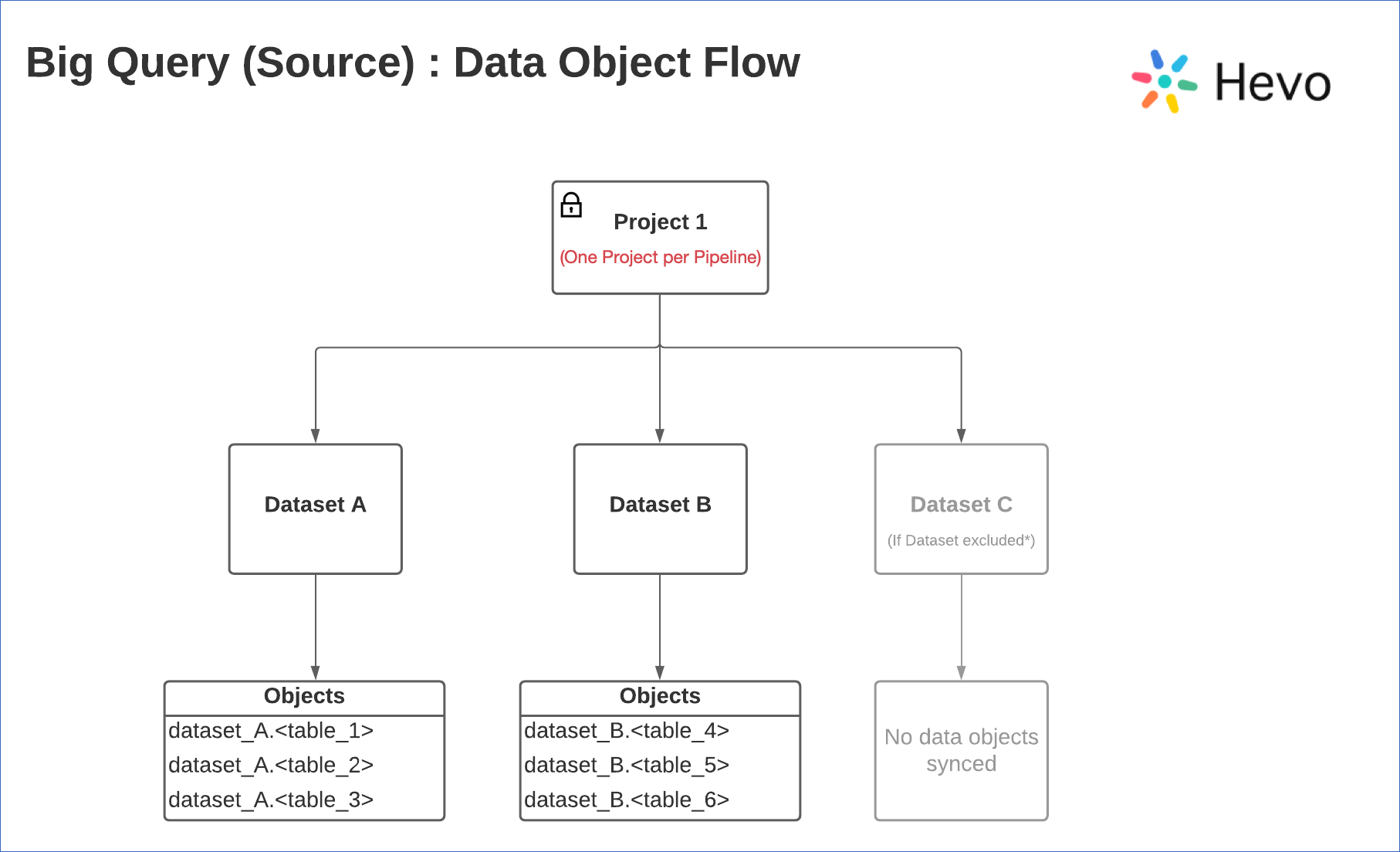
Permissions
Hevo needs permission to access your data in BigQuery as well as GCS. The files written to GCS are deleted as soon as they are moved to the next stage in the Pipeline. These permissions are assigned to the account you use to authenticate Hevo on BigQuery. Read Google Account Authentication Methods for more information.
Data Replication Strategy
Hevo adopts one of the following strategies to replicate data from your Google BigQuery Source:
-
Direct Query: Hevo adopts this replication strategy to ingest data from non-partitioned tables in your dataset. This is also used with partitioned tables if a GCS bucket is not specified at the time of creating the Pipeline. In this strategy, Hevo first scans the selected objects (tables), and then reads data from them. To identify the incremental data, Hevo scans the entire table to find the difference between the new and existing data.
Hevo saves the ingested data in temporary tables to avoid fetching any data that is already ingested. Hevo writes this data using streaming inserts. As streaming is not available for GCP free tier accounts, billing must be enabled for your GCP project.
-
GCS Export: Hevo adopts this replication strategy to ingest data from partitioned tables in your dataset if you have specified a GCS bucket at the time of creating the Pipeline. In this strategy, Hevo first ingests data from the partitions and then temporarily exports it into a bucket in your Google Cloud Storage. From there, the data is loaded into the Destination. An offset is maintained to help identify the latest partition, and data from that partition is ingested as incremental data.
Read Introduction to partitioned tables to understand how partitioning affects the data processing performance and costs in Google BigQuery.
Prerequisites
-
Access to a BigQuery project with one or more datasets containing at least one table.
-
An active billing account is linked to your GCP project, as Hevo writes incremental data to temporary tables using streaming inserts.
-
You are granted the BigQuery Data Editor, Data Viewer, and Job User permissions at the dataset level.
-
Access to an existing GCS bucket in the BigQuery location as your datasets. You can specify this when creating your Pipeline to enable Hevo to use the GCS Export strategy for partitioned tables.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Note: You can select only one project per Pipeline.
Configuring Google BigQuery as a Source
Perform the following steps to configure BigQuery as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE in the Pipelines List View.
-
In the Select Source Type page, select Google BigQuery.
-
In the Configure your BigQuery Account page, connect to your BigQuery data warehouse using one of the following ways:
Note: You cannot switch from a service account to a user account and vice-versa once you create the Pipeline.
-
To connect with a User Account, do one of the following:
-
Select a previously configured account and click CONTINUE.
-
Click + ADD BIGQUERY ACCOUNT and perform the following steps to configure an account:

-
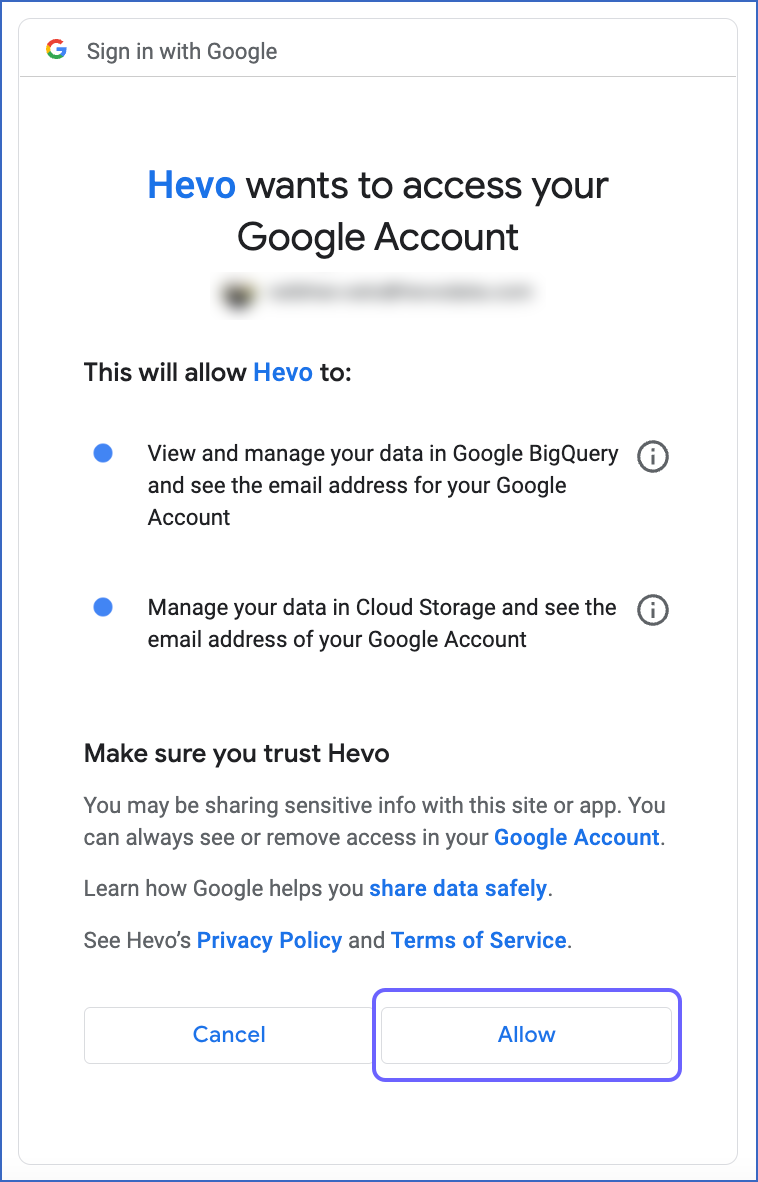
Sign in to your account.
-
Click Allow to authorize Hevo to access your data.
-
-
-
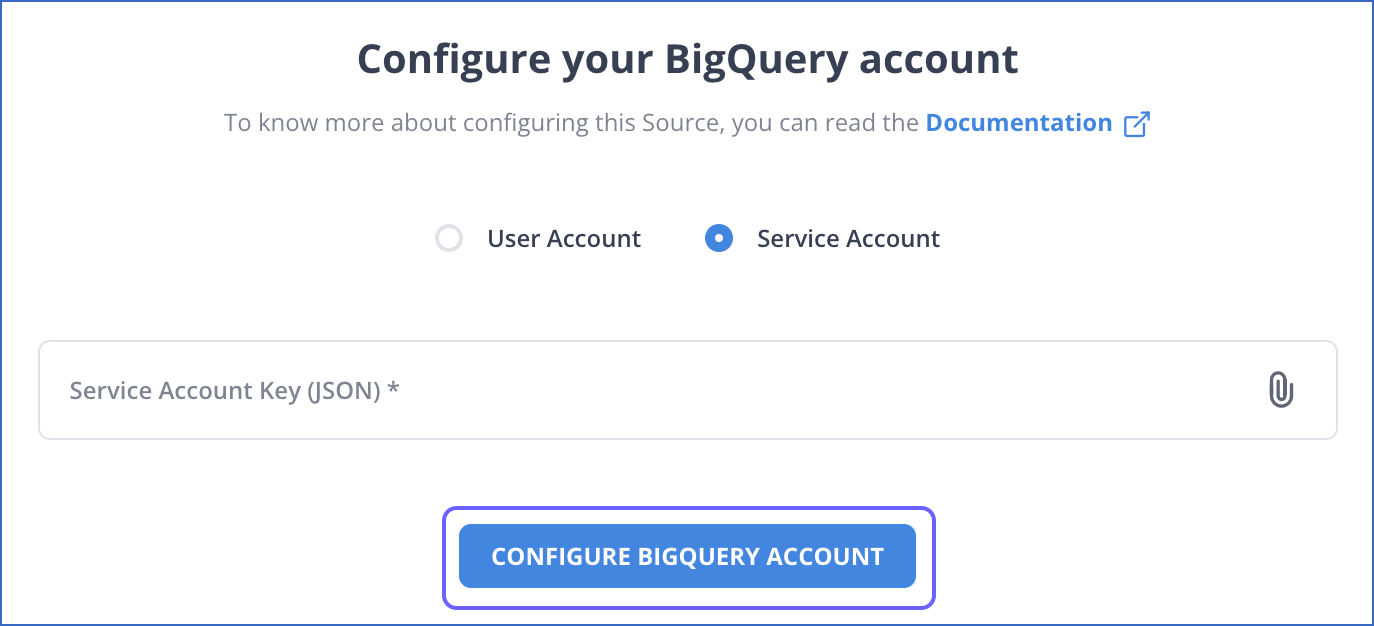
To connect with a Service Account, do one of the following:
-
Select a previously configured account and click CONTINUE.
-
Attach the Service Account Key JSON file that you created in Google Cloud Platform (GCP) and click CONFIGURE BIGQUERY ACCOUNT.
-
-
-
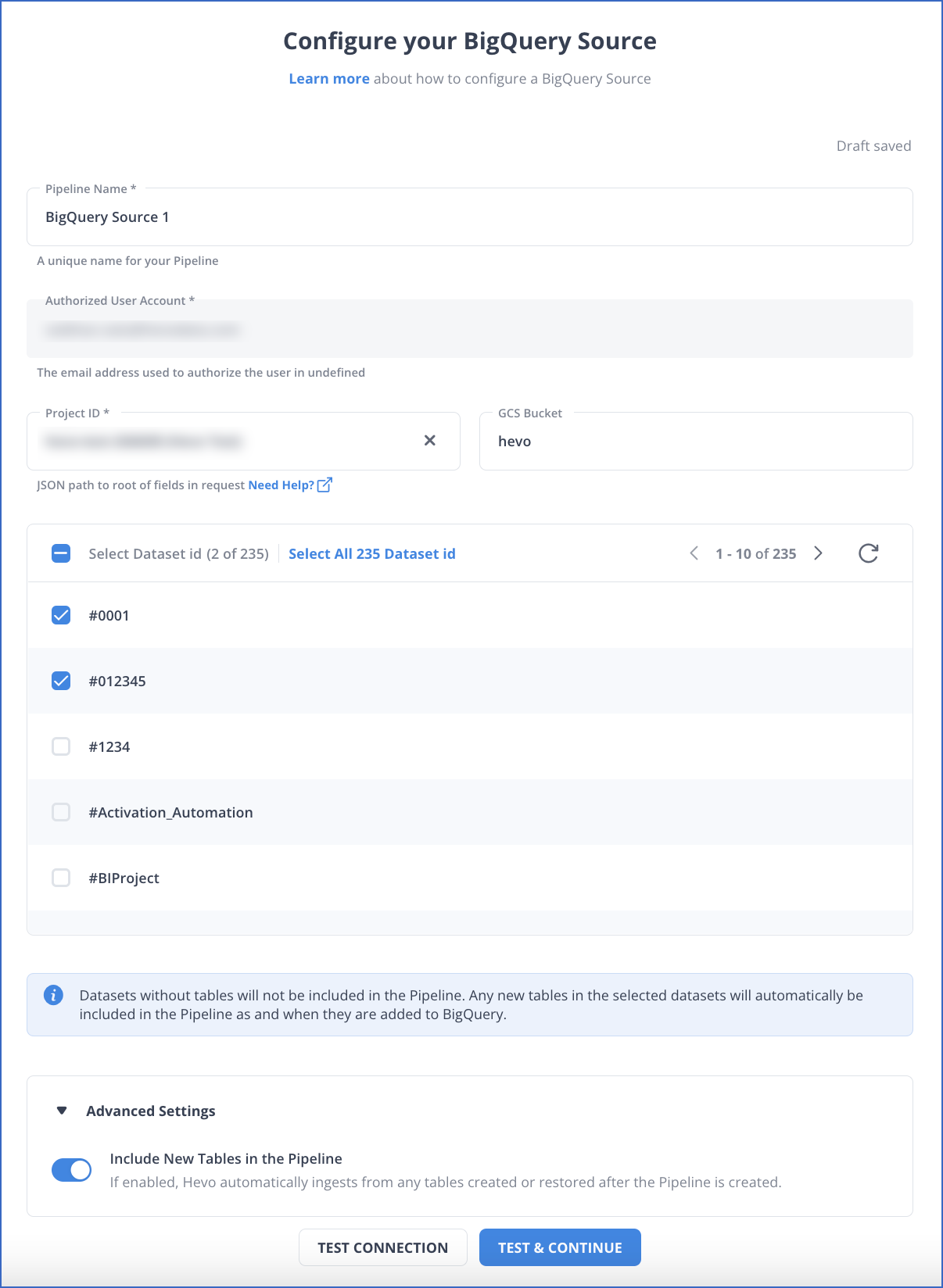
In the Configure your BigQuery Source page, specify the following:
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Authorized User/Service Account (Non-editable): The email address that you selected when connecting to your Google BigQuery account. This value is pre-filled.
-
Project ID: The project ID for which you want to create the Pipeline. Select the required ID from the drop-down.
-
GCS Bucket (Optional): The name of an existing container in your Google Cloud Storage, into which Hevo exports the ingested data before loading it to the Destination.
-
Select Dataset ID: Select one or more datasets that contain the data tables. You can select the tables you want to replicate from these datasets in subsequent Pipeline configuration steps.
-
Advanced Settings:
-
Include New Tables in the Pipeline: If enabled, Hevo automatically ingests data from tables created after the Pipeline has been built. If disabled, the new tables are listed in the Pipeline Detailed View in Skipped state, and you can manually include the ones you want and load their historical data.
You can change this setting later.
-
-
-
Click TEST & CONTINUE.
-
Proceed to configuring the data ingestion and setting up the Destination.
Selecting Source Objects for Ingestion
By default, all datasets and the tables within these are selected to be replicated. You can change this setting by selecting specific dataset IDs while configuring your Pipeline. In the subsequent configuration pages, you can select the tables (Source objects) of these datasets that you want to ingest.
You can edit these settings at a later time through the Overview tab of the Pipeline Detailed View page as follows:
Note: Re-run the Pipeline for changes to take effect.
To include/skip a table:
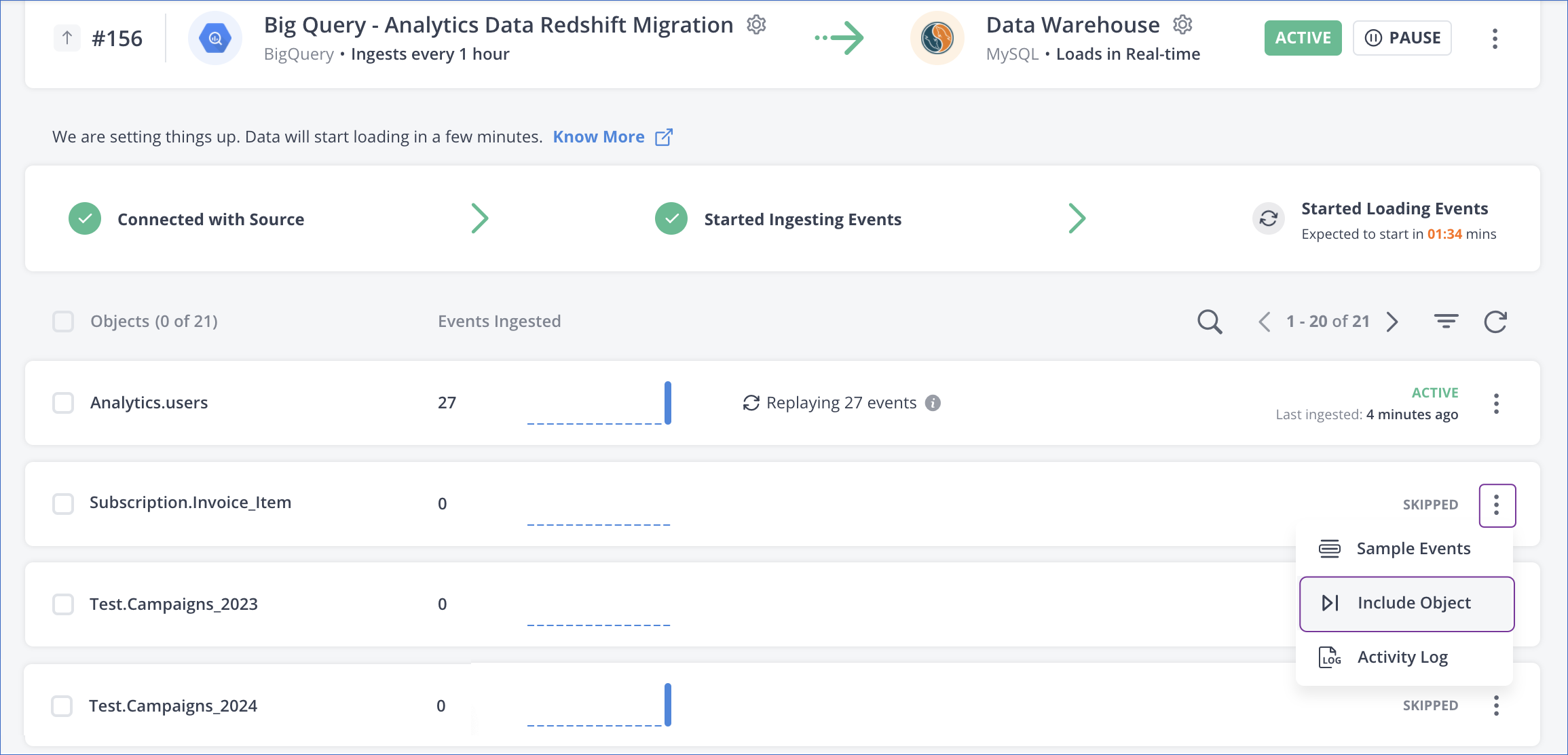
-
Click the Kebab menu of the object
-
Click Include Object or Skip Object. Excluded tables have the status, SKIPPED.
To add or remove a dataset:

-
Click the Settings icon next to the Source name.
-
Click the Edit icon in the pop-up dialog and re-configure the integration.
Datasets that do not have tables are not included in the Pipeline.
Hevo automatically loads the historical data for the newly added tables. If you are creating a table in a dataset that is included in the Pipeline, Hevo automatically starts ingesting its Events in the Pipeline. If you exclude a table, its status is updated to SKIPPED in the Pipeline Overview section.
Data Replication
| For Teams Created | Default Pipeline Frequency | Minimum Pipeline Frequency | Maximum Pipeline Frequency | Custom Frequency Range (Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 3 Hrs | 15 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3 but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests data from tables in the selected datasets in your BigQuery project in the following manner:
-
For partitioned tables: If you specified a GCS bucket at the time of creating the Pipeline, Hevo ingests all the data up to the latest table partition; else, Hevo ingests the entire existing data.
-
For non-partitioned tables: Hevo ingests the entire data existing in your table. This behavior is unchanged even if a GCS bucket is specified at the time of creating the Pipeline.
-
-
Incremental Data: Once the historical load is complete, Hevo synchronizes data with your Destination as per the ingestion frequency in the following manner:
-
For partitioned tables: Hevo performs a full load to ingest all the data available in the latest partition of your table.
-
For non-partitioned tables: Hevo synchronizes all new and updated records.
-
Hevo does not track deletes or support Change Data Capture for BigQuery.
Schema and Primary Keys
The Schema is derived based on the data in your BigQuery Source tables.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
- The Cloud Storage bucket into which Hevo temporarily exports your ingested data must exist in the BigQuery location as your dataset with the exception of the datasets in the US multi-region. Read Location considerations for further details on the requirements.
Limitations
-
Updates in the BigQuery Source data are appended as new rows in the Destination. The existing rows are not modified. Therefore, both old and new entries exist in the Destination.
-
Deleted data is not marked or removed in the Destination.
-
Hevo requests access to your data in Cloud Storage even if you do not specify a GCS bucket while configuring the Pipeline.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Feb-02-2024 | NA | Updated section, Prerequisites to add information about the required permissions. |
| Jun-19-2023 | NA | - Updated sections, Data Replication Strategy and Prerequisites to add information about enabling billing to use streaming inserts. |
| Mar-09-2023 | NA | Updated section, Configuring Google BigQuery as a Source to add a note about switching your authentication method post-Pipeline creation. |
| Dec-07-2022 | 2.03 | Updated section, Configuring Google BigQuery as a Source to add information about support for service accounts. |
| Sep-13-2022 | 1.97 | - Added the Data Replication Strategy subsection in the overview text to explain the different data ingestion strategies, - Added the Source Considerations section, - Updated the Configuring your Google BigQuery Source section to add the GCS bucket field description, - Updated the Limitations section to inform about Hevo requesting access to data in GCS, - Modified the content for historical and incremental data in the Data Replication section to describe the impact of providing a GCS bucket on data ingestion. |
| Mar-22-2022 | NA | Updated information regarding Historical Data in the Data Replication section to remove the mention of historical sync duration. |
| Jul-12-2021 | 1.67 | Added the field Include New Tables in the Pipeline under Source configuration settings. |
| Apr-20-2021 | 1.61 | New document. |