Name Sanitization
On This Page
Hevo uses a Name Sanitization system to provide a consistent user experience across Destinations. This system encourages the use of a simple, consistent, and readable vocabulary when naming the tables and columns. To achieve this, Hevo replaces all non-alphanumeric characters and spaces in a table or column name with an underscore.
When are names sanitized?
Names are sanitized while mapping a Source Event Type to a table in the Destination using Auto Mapping or when you try to create a table manually using the Hevo UI. In the latter case, Hevo validates the table name you provide before creating a Destination table with it. If the validation fails, a message is displayed on the Hevo UI.
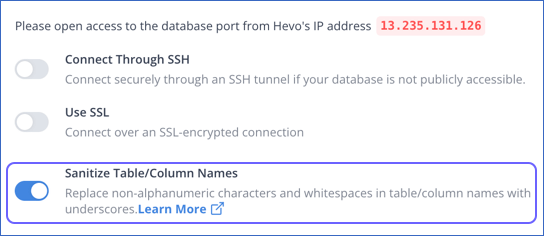
Hevo performs sanitization if you enable the Sanitize Table/Column Names option while configuring the Destination. By default, this option is enabled for most Destinations, except Databricks. You can turn off this feature if you do not want Hevo to perform sanitization.
Note: The Sanitize Table/Column Names option is not available for Snowflake Destinations.
Name Sanitization in the Destination
The way in which Hevo sanitizes your Destination table and column names depends on the Auto Mapping setting. However, in the case of Amazon Redshift and Snowflake Destinations, sanitization is enforced if Auto Mapping is active.
Auto Mapping is enabled
As a part of sanitizing the names, Hevo:
-
Converts the table and column names to lowercase, except for Snowflake where the table and column names are converted to uppercase.
-
Replaces each non-alphanumeric (special) character with an underscore.
-
Removes the trailing underscores.
For example, the Source Event Type, Table$namE_05_ is converted to table_name_05, and in the case of Snowflake, to TABLE_NAME_05. The same conventions apply to column names.
Note:
-
In the case of Amazon Redshift Destinations, even when Name Sanitization is not selected, Hevo converts the table and column names to lowercase. This is because, by default, Amazon Redshift does not allow uppercase names for tables and columns. Read the Amazon Redshift Developer Guide for information on naming database objects.
-
For MySQL, Amazon Aurora MySQL, and SQL Server Destination types, even when Name Sanitization is not selected, Hevo sanitizes table and column names if they do not follow Hevo’s defined safe pattern, which means names can only contain alphanumeric characters, underscores, and dollar signs, with a maximum length of 64 characters. If a name contains a space, Hevo sanitizes the entire name, even if all other characters are safe. As part of this process, spaces and dollar signs are converted to underscores. For example, Table Name$05 is sanitized to table_name_05.
Auto Mapping is turned off
When creating tables manually, how names are sanitized depends on the Destination type:
-
Amazon Redshift: Hevo converts the table name to lowercase and does not sanitize it. For example, the table name Table$namE_05_ is converted to table$name_05_. The same conventions apply to column names.
Note:
-
In the case of Amazon Redshift Destinations, even when Name Sanitization is not selected, Hevo converts the tables and columns to lowercase. This is because, by default, Amazon Redshift does not allow uppercase names for tables and columns. Read the Amazon Redshift Developer Guide for information on naming database objects.
-
For MySQL, Amazon Aurora MySQL, and SQL Server Destination types, even when Name Sanitization is not selected, Hevo sanitizes table and column names if they do not follow Hevo’s defined safe pattern, which means names can only contain alphanumeric characters, underscores, and dollar signs, with a maximum length of 64 characters. If a name contains a space, Hevo sanitizes the entire name, even if all other characters are safe. As part of this process, spaces and dollar signs are converted to underscores. For example, Table Name$05 is sanitized to table_name_05.
-
-
Google BigQuery: According to the Google BigQuery reference guide for naming tables, you cannot create a table name with special characters. Hevo displays an error message if a table name with special characters, such as Table$n@mE_05_, is provided manually. However, you can name your tables with uppercase characters and trailing underscores. The same conventions apply to column names.
-
Snowflake: According to Snowflake’s Identifier requirements, you can create table names with any valid characters by specifying the names in double quotes. For example, “agents.name”. Hevo displays an error message if a table name with special characters, such as Table$n@mE_05_, is provided manually. However, you can name your tables with lowercase characters and trailing underscores. The same conventions apply to column names.
-
Database Destinations: In the case of database Destinations, such as MySQL, PostgreSQL, SQL Server, and Amazon Aurora MySQL, Hevo converts the table name to lowercase. For example, the table name Table$namE_05_ is converted to table$name_05_. The same conventions apply to column names.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Mar-27-2025 | NA | Added a note to provide information about sanitized column names for MySQL and SQL Server Sources. |
| Dec-11-2023 | NA | Added information for name sanitization in Snowflake. |
| Oct-03-2023 | NA | Updated the content to reflect the latest product functionality and removed section, What Happens to Field Separators and Delimiters? |
| Dec-19-2022 | 2.04 | Removed section, Name Sanitization in Snowflake as table and column names are not sanitized for Snowflake Destinations now. |