Taboola
On This Page
Taboola helps you create targeted advertising campaigns to market your products and services to the most receptive and relevant audiences and drives up clicks, traffic and conversions.
You can replicate the data associated with your Taboola account and the campaigns to a Destination of your choice using Hevo Pipelines.
Hevo uses the Taboola Backstage API to replicate the data present in your Taboola account to the desired Destination database or data warehouse for scalable analysis.
Prerequisites
-
An active Taboola account from which data is to be ingested exists.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
-
The client ID and client secret for the account. The client secret is shared by the Taboola team via email during account onboarding.
Configuring Taboola as a Source
Perform the following steps to configure Taboola as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
On the Select Source Type page, select Taboola.
-
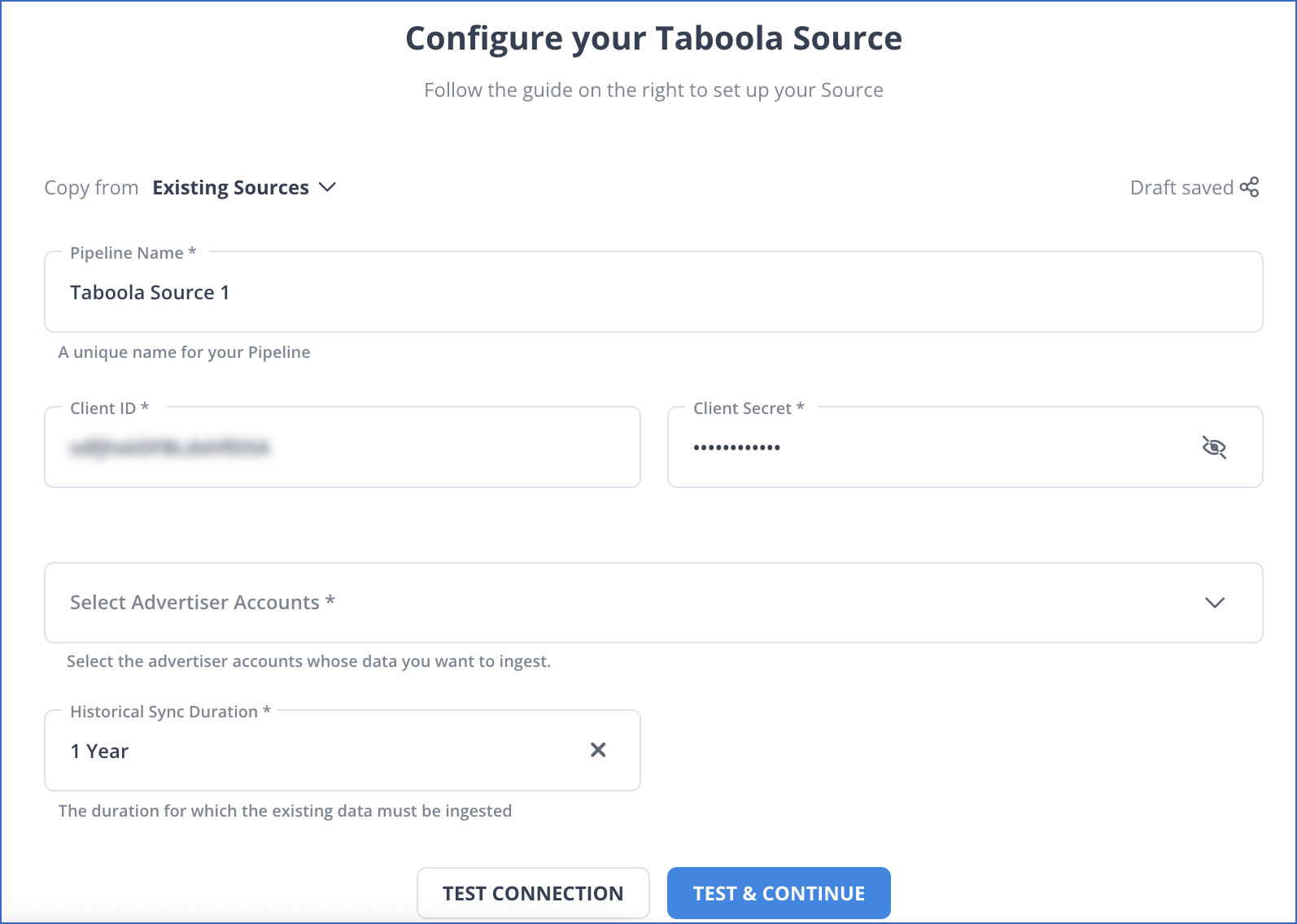
On the Configure your Taboola Source page, specify the following:
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Client ID: The Client ID of your Taboola advertiser account
-
Client Secret: The Client Secret of your Taboola advertiser account
NOTE: The Client ID and Client Secret are shared by your Taboola Account Manager in the onboarding email communication. You can request these again from the Taboola team if required.
-
Advertiser Accounts: This field is displayed once you enter the correct Client ID and Secret. Select the advertiser accounts whose data you want to ingest.
-
Historical Sync Duration: The duration for which you want to ingest the existing data from the Source. Default duration: 1 Year.
Note: If you select All Available Data, Hevo ingests all the data available in your Taboola account since January 01, 2018.
-
-
Click TEST & CONTINUE.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 3 Hrs | 1 Hr | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests historical data for all the reports on the basis of the historical sync duration selected at the time of creating the Pipeline and loads it to the Destination. Default duration: 1 Year.
-
Incremental Data: Once the historical data ingestion is complete, every subsequent run of the Pipeline fetches new and updated data for the reports as per the ingestion frequency.
-
Data Refresh: Data for the last 30 days is refreshed on a rolling basis for all report objects.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination database.
To determine the primary keys for replicating the data:
-
If the primary key list count in the Source object is > 3, the
__hevo_idis used as the single primary key -
For fewer than three primary keys in the Source object, the individual fields are retained as primary keys.
Data Model
| Report Name | Primary Key | Description |
|---|---|---|
| Account | - id |
Contains details of the prime advertiser under which you perform campaigning operations. The advertiser account is provided to you by Taboola when your account credentials are first created. If you manage multiple accounts, this is also called your Network Account. This object is empty if no advertiser accounts exist. |
| Campaign | - account_id - id |
Contains the list of all campaigns for all the accounts that the data Pipeline is created for. Data for deleted campaigns is also included in this object with status as TERMINATED. Targeting information associated with each campaign can be seen in the _targeting column. |
| Campaign Breakdown Report | - account_id - campaign - __hevo_report_date |
Contains reporting data grouped by campaign. |
| Campaign Day Breakdown Report | - account_id - campaign - __hevo_report_date |
Contains reporting data grouped by campaign and day. |
| Campaign Item | - account_id - id |
Contains items such as images, approval states, statuses, and link URLs for each campaign’s creative strategy. |
| Campaign Site Daily Report | - account_id - campaign - campaign_name - date - site - site_name |
Contains reporting data grouped by date, campaign level, and site. |
| Content Provider Report | - account_id - content_provider - content_provider_name - __hevo_report_date |
Contains reporting data grouped by content provider. |
| Country Breakdown Report | - account_id - country - country_name, - __hevo_report_date |
Contains reporting data grouped by content provider and country. Note: This object is available only for the Network Account and not for any linked accounts of other advertisers. |
| DMA Country Report | - account_id - country - dma - __hevo_report_date |
Contains reporting data grouped by DMA and country. |
| Hour of Day Report | - account_id - __hevo_report_date - hour_of_day |
Contains reporting data grouped by date and campaign. |
| Platform Report | - account_id - __hevo_report_date - platform - platform_name |
Contains reporting data grouped by platform name. |
| Region Country Report | - account_id - country - __hevo_report_date - region |
Contains reporting data grouped by region and country. |
| Site Breakdown Report | - account_id - __hevo_report_date - site_id |
Contains reporting data grouped by site. |
| Top Campaign Content Report | - account_id - __hevo_report_date - item |
Enables you to view the performance of the top 500 campaigns items by URL and Creative for one or all campaigns. |
| User Segment Report | - account_id - audience_name - data_partner_audience_id - __hevo_report_date - partner_name |
Contains reporting data grouped by marketplace audience. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
- The Content Provider Report is available only for the network account whose credentials are used at the time of configuring the Source.
Limitations
- Hevo does not load an Event into the Destination table if its size exceeds 128 MB, which may lead to discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each row in your Source objects contains less than 100 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Feb-20-2023 | NA | Updated section, Configuring Taboola as a Source to update the information about historical sync duration. |
| Jan-10-2023 | 2.05 | Updated section, Schema and Primary Keys to remove the time_zone_name field from the Account object as it is not supported by the latest Taboola Backstage API version 1.1.3. |
| Dec-07-2022 | NA | Updated section, Data Replication to reorganize the content for better understanding and coherence. |
| Oct-25-2021 | NA | Added the Pipeline frequency information in the Data Replication section. |
| Jul-22-2021 | NA | - Updated the Data Model with additional reports. - Added a note in the Overview section about Hevo providing a fully-managed Google BigQuery Destination for Pipelines created with this Source. |
| Jul-12-2021 | 1.67 | New document. |