Release Version 1.86
On This Page
Note: The content on this site may have changed or moved since you last viewed it. Always access the latest content via the Hevo Docs website.
In this Release
New and Changed Features
Account Management
-
On-Demand Credit
-
Hevo now enables all paid users to maintain a credit balance of Events using the On-Demand Credit feature. Maintaining an On-Demand Credit limit allows your Pipelines to switch to using the credit Events when all your base Events and any On-Demand Events that you have purchased are exhausted.

-
Pipelines
-
Enhanced Support During Events Quota Exhaustion
-
Provided a grace period that allows you to continue running your Pipeline for an extended period even after the Events quota gets exhausted.
Read Pricing Plans and Understanding Events Usage for Billing.
-
-
Optimizing Data Loading Costs
-
Provided the option in the Pipeline Overview page to allow you to avoid deduplication of tables when not needed and save on Destination costs.
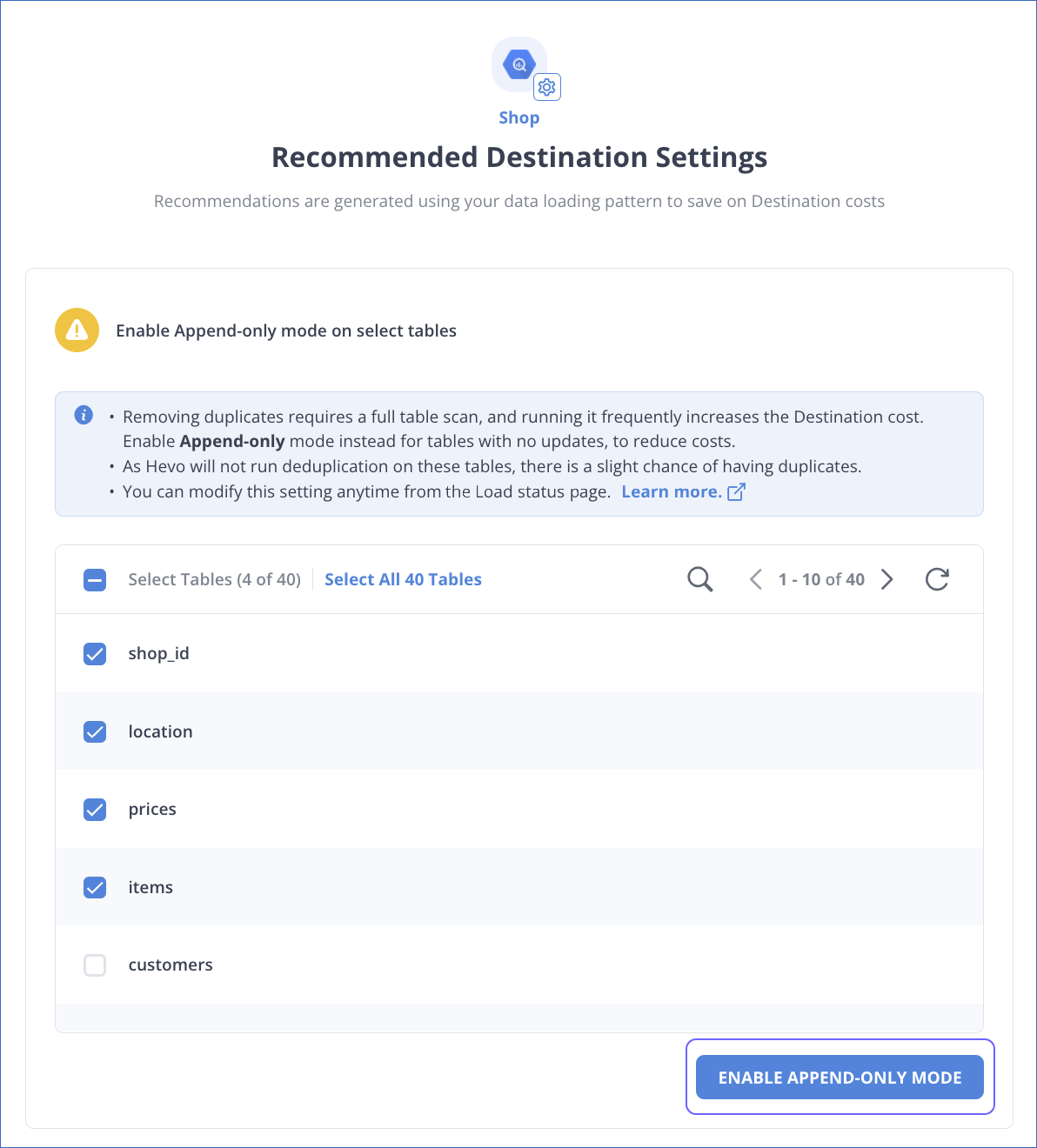
-
Sources
-
Capturing Deletes in Stripe Objects
-
Enhanced the integration to support the replication of deleted records in certain Stripe objects. This feature is provided for new and existing Pipelines; however, for existing Pipelines, records deleted in the Stripe objects before Release 1.86 are not replicated.
Note: This feature is currently available on request only. You need to contact Hevo Support to enable it for your team.
Read Data Replication and Source Considerations.
-
-
Enhanced Security with OAuth 2.0 for REST API Sources
-
Implemented OAuth 2.0 protocol for account authorization for REST API Sources. This feature applies only to new Pipelines.
Note: This feature is currently available on request only. You need to contact Hevo Support to enable it for your team.
-
-
Support for Ingesting Tables Renamed in the MySQL Source
-
Support for TSV File Format
- Enhanced the integration with file-based Sources Amazon S3, Google Drive, and FTP/SFTP Sources to support the ingestion of TSV files.
User Experience
-
Improved Report Data Representation in Xero
-
Implemented the feature to convert the nested JSON strings data of the Balance Sheet and Profit and Loss report to a tabular format for better readability. To use this tabular format, contact Hevo Support.
Read Data Model.
-
Fixes and Improvements
Destinations
-
Resolved Destination Connection Failure
- Fixed the issue whereby the connection to a Destination that requires a database user and password to connect failed when the existing configuration was modified.
Sources
-
Handling Data Load Failures due to Pre-existing
__hevo_idField in Google Drive Data-
Fixed the ingestion process to rename any existing column with the name, __hevo_id in the Source file using appropriate suffixes. Hevo adds the __hevo_id column as a primary key for keeping track of offsets during the ingestion process. Therefore, any existing columns with that name are renamed. Other duplicate column headers are also similarly renamed.
-
-
Improved Support for Campaign Report in Apple Search Ads
-
Enhanced the integration to include the
country_or_regionfield in the Campaign Report object. This allows Hevo to handle discrepancies in the Campaign Report data at the Source and Destination.Read Data Model and Schema and Primary Keys.
-
-
Quicker Access to Historical Data for Stripe, MS SQL, MongoDB, and Facebook Ads
-
Implemented historical load parallelization for new Pipelines. Hevo now divides the historical data into multiple parts and then ingests these parts simultaneously. This enables you to have quicker access to your historical data.
The number of parts is decided based on the Source API limits and the resource constraints of the system.
-
-
Reduced Quota Consumption for Instagram Business, Jira, and Shopify
-
Optimized the quota consumption for Pipelines created with the Instagram Business, Jira, or Shopify Source by loading only new and changed data in case of Full Load objects. This feature is available for both new and existing Pipelines.
Read Instagram Business, Jira, and Shopify.
-
User Experience
-
Improved Pipeline Setup for JDBC Sources
-
Enhanced the user interface to select the Ingestion Mode in the Connection Settings page while creating a Pipeline for JDBC Sources such as Amazon Redshift, MySQL, and MongoDB.
Read your respective Database Source page for the steps to set up a Pipeline.
-
Documentation Updates
The following pages have been created, enhanced, or removed in Release 1.86:
Account Management
Activate
Alerts
Data Ingestion
Data Loading
Hevo API
Pipelines
Release Notes
Sources
-
Query Modes for Ingesting Data from Relational Databases (renamed to Query Modes for Ingesting Data)
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Apr-21-2022 | NA | Added section, User Experience to add Improved Pipeline Setup for JDBC Sources. |