Google Sheets
On This Page
User account-based authentication is no longer supported for the Google Sheets Source. We recommend that you migrate your existing Pipelines to a service account for uninterrupted data replication. Read Migrating User Account-Based Pipelines to Service Account for the steps to do this.
Hevo can replicate your Google Sheets data to your Destination using Google’s Sheets API.
User Authentication
You can connect to the Google Sheets Source only via service accounts. One service account can be mapped to your entire team. Read Google Account Authentication Methods to know how to set up a service account if you do not already have one.
Prerequisites
-
The Google Sheets and Google Drive APIs are enabled for the service account, if connecting via it.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo, to create the Pipeline.
Configuring Google Sheets as a Source
Perform the following steps to configure Google Sheets as a Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Google Sheets.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
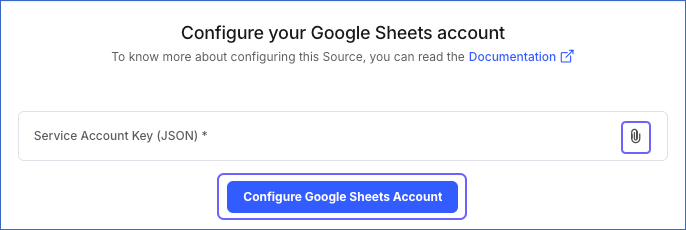
On the Configure your Google Sheets account page, do one of the following:
-
Select a previously configured account and click Continue.
-
Click the attach icon (
 ) to upload the Service Account Key and click Configure Google Sheets Account.
) to upload the Service Account Key and click Configure Google Sheets Account.Note:
-
Hevo supports only JSON format for the key file.
-
The service account must be granted access to the resources from which you want to ingest data.
-
The service account cannot be changed after Pipeline creation.
-
-
-
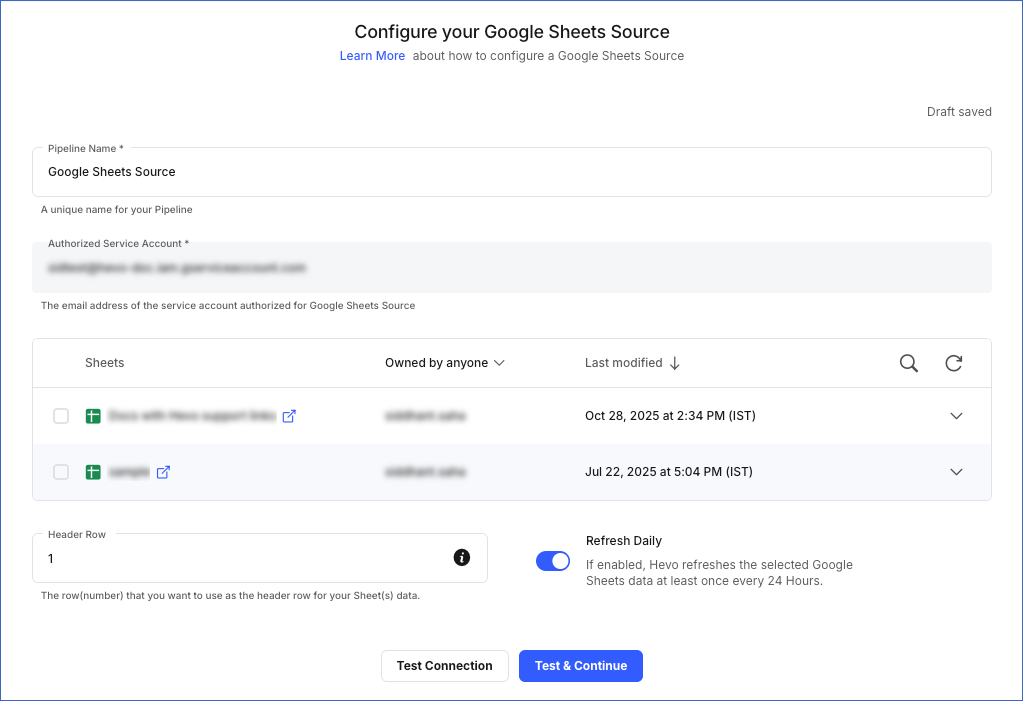
On the Configure your Google Sheets Source page, specify the following:
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Authorized Service Account (Non-editable): The email address of the service account that you configured earlier. This value is pre-filled.
Note: The authorized service account cannot be changed after the Pipeline is created. If you need to use a different account, create a new Pipeline. Data ingested by the previous Pipeline remains in its Destination tables; the new Pipeline ingests data independently using the new account.
-
Sheets: The Sheets whose data you wish to replicate. When you select a sheet, by default, all the tabs within it get selected. However, you can click on the Expand icon for a sheet to display the list of tabs it contains and select the ones you need.
-
Header Row (Optional): The row number in the sheet(s) you want to use as the header row. Leave this field blank if you want to use the first row as the header.
Note: The data from your selected sheet(s) is ingested starting from the specified custom header row, which means that all rows before it are skipped.
-
Refresh Daily (Optional): If enabled, Hevo re-ingests the selected sheet(s), in case no change to the data is detected for 24 hours since the last ingestion. If disabled, Hevo only re-ingests the sheet if it detects any new changes to the data.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 12 Hrs | 5 Mins | 48 Hrs | 1-48 |
| After Release 2.21 | 12 Hrs | 30 Mins | 24 Hrs | 1-24 |
-
Historical Data: By default, Hevo starts fetching data from the time your Google Sheets account was created. The Pipeline takes the offset for ingesting data from the
last_modified_attimestamp of the Sheet. -
Incremental Data: Google Sheets does not provide any mechanism to detect changes made to specific rows in a Sheet. The only available information is the
last_modified_attimestamp of the Sheet, resulting in a timestamp-based offset. If any changes are detected via the modification time, then all the data present in that Sheet is ingested again. Hevo also fetches theEventsobject from Google Sheets, which tracks the updates made in the last 30 days, to sync the related Events with your Destination. -
Data Refresh: If the Refresh Daily option is enabled during Source configuration, Hevo re-ingests all the data from the selected Google Sheets in case no changes are detected via the modification time for 24 hours. So, every time there is no data ingestion for 24 hours, a data refresh happens. This is done in order to ensure no Events are missed for ingestion.
Additional Information
Read the detailed Hevo documentation for the following related topics:
- Pipeline Behavior
- Treatment of Duplicate Column Headers
- Source Considerations
- Billing Considerations
- Limitations
Pipeline Behavior
-
Values in the first row of the Sheet are treated as field headers. These headers need to be unique. Read Treatment of Duplicate Column Headers.
If a header is missing, then the column name is used as the header.
-
Renaming your Sheet does not cause your Pipeline to break.
-
Row number is used as a primary key which is represented by a field called
__hevo_idin your Destination table. Read Treatment of Duplicate Column Headers. -
Cells containing formulas or scientific numbers are loaded as their calculated value.
Example: 6.16E+12 is loaded as 6160000000000.
-
Search option while selecting your Sheets only works on prefixes.
-
The Pipeline supports only Google Sheets. For MS Excel files, please check out the Drive Source.
Treatment of Duplicate Column Headers
To identify each column in the Source uniquely during ingestion, Hevo renames any duplicate column headers that are found, as:
-
Columns with the same header: The column header is changed to lowercase and the column number is suffixed to it. For example, if there are three columns, test, test, and test in columns G, H, and K, respectively, these are changed to test_g, test_h, and test_k. The same happens for headers with space between them. For example, if there are three columns, Software Used, Software Used, and Software Used in columns H, I, and J, respectively, these are changed to software_used_h, software_used_i, and software_used_j.
-
Columns with same header but different case: All column headers are changed to lowercase and assigned a sequential, numeric suffix. For example, if there are three columns, test, Test, and tEst, these are changed to test, test_1, and test_2 during the Auto Mapping phase. The same happens for headers with space between them. For example, if there are two columns, Software Used and Software used, these are changed to software_used, and software_used_1.
-
Columns with __Hevo_id as the header: The column header is changed to __hevo_id, and the __hevo_id column that Hevo adds to keep track of offsets during ingestion is named as __hevo_id_1.
-
Columns with __hevo_id as the header: Hevo suffixes the column number to the column header. For example, if the __hevo_id_ column lies in column number B, it is renamed to __hevo_id_b. If the __hevo_id_b column is also present in the Source column list, the original __hevo_id column is named to __hevoid_b_b. This is done because Hevo adds the column, __hevo_id_ as a primary key to keep track of offsets during the ingestion process. Towards this purpose, any existing column with that name is renamed.
Source Considerations
We recommend enabling the Refresh Daily option in the Source configuration if you are importing data from other worksheets into the Google Sheets selected for replication. At times, there can be a delay between the last_modified_at timestamp change and the data getting successfully imported. As a result, no new data may get ingested if Hevo polls for a last_modified_at time between this delay, as the import operation would still be incomplete but the timestamp-based offset would have been incremented. A daily refresh ensures all such data gets synchronized to the Destination successfully by re-ingesting all the data in the Google Sheets if no changes are detected for 24 hours. All Events ingested during data refresh count towards your Events quota consumption.
Billing Considerations
For Google Sheets, if any data changes in the Source, the entire sheet is re-ingested, as there is no way to identify incremental changes. All such subsequent loads count toward your Events quota consumption and are billed accordingly.
Limitations
-
The
hevo_marked_deletedcolumn is displayed in the Destination; however, Hevo does not capture the information for records deleted in your sheet(s). -
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Apr-01-2026 | NA | Updated section, Configuring Google Sheets as a Source to add a note about non-editable authorized service account. |
| Nov-07-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring Google Sheets as a Source as per the latest UI. |
| Aug-22-2025 | NA | Updated section, Configuring Google Sheets as a Source to add a note that service accounts are non-editable after Pipeline creation. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Aug-19-2024 | NA | Updated section, Configuring Google Sheets as a Source to remove mentions of user account-based authentication. |
| Jul-16-2024 | 2.25.2 | Updated section, Data Replication to change the default ingestion frequency to 12 Hrs. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Jul-20-2023 | NA | Added section, Limitations to add information about Hevo not capturing deletes. |
| Jun-26-2023 | 2.14 | Updated section, Configuring Google Sheets as a Source to add information about custom header row. |
| Apr-11-2022 | NA | Updated screenshot in the Configuring Google Sheets as a Source section to reflect the latest UI. |
| Feb-21-2022 | 1.82 | Added section, Treatment of Duplicate Column Headers. |
| Dec-06-2021 | 1.77 | - Added section, Source Considerations. - Updated section, Configuring Google Sheets as a Source to add information about data refresh. |
| Oct-25-2021 | NA | Added the Pipeline frequency information in the Data Replication section. |
| Sep-20-2021 | 1.72 | Added the section, Data Replication. |
| May-05-2021 | 1.62 | Added steps to connect to Google Sheets Source using a service account. |
| Apr-13-2021 | NA | Added the section, Billing Considerations. |