Pingdom
On This Page
Pingdom is a web performance monitoring platform that allows you to track metrics such as the uptime, downtime, speed of your website, and transactions in real-time. You can use these metrics to generate reports that summarize the performance of your website for the selected time period. It also sends immediate alerts in case of any disruptions complemented with a root-cause analysis report and outage details for efficient troubleshooting.
You can replicate the data from your Pingdom account to a Destination database or data warehouse using Hevo Pipelines. Refer to section, Data Model for the list of supported objects.
Hevo uses the Pingdom Public API (3.1) to replicate the data present in your Pingdom account to the desired Destination database or data warehouse for scalable analysis.
Prerequisites
-
An active Pingdom account from which data is to be ingested exists.
-
The API token is available to provide Hevo access to your Pingdom account data.
-
You must be logged in as an Account Owner, Editor, or Admin user to obtain the API key. Else, you can obtain it from your account editor, owner or administrator.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Obtaining the API Token
The API token that you generate in Pingdom does not expire. Therefore, you can use an existing token or create a new one to authenticate Hevo on your Pingdom account.
Note: You must log in as an Account Owner, Editor, or Admin user to perform these steps.
To obtain the API token:
-
Log in to your Pingdom account.
-
In the bottom left corner of the page, click the Arrow (
 ) icon to expand the left navigation panel.
) icon to expand the left navigation panel. -
In the Home navigation panel, Settings section, click Pingdom API.
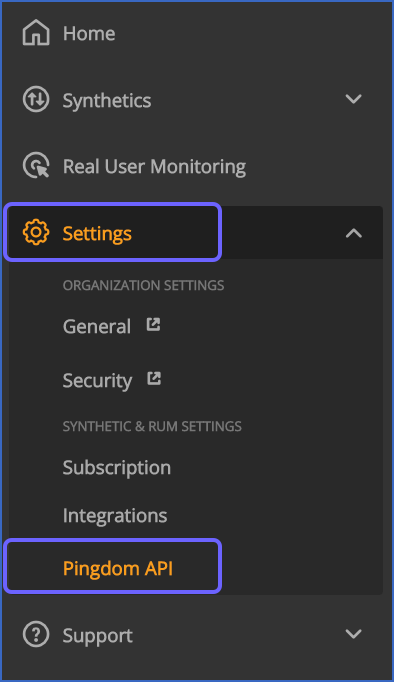
-
In the Pingdom API page, click Add API token.
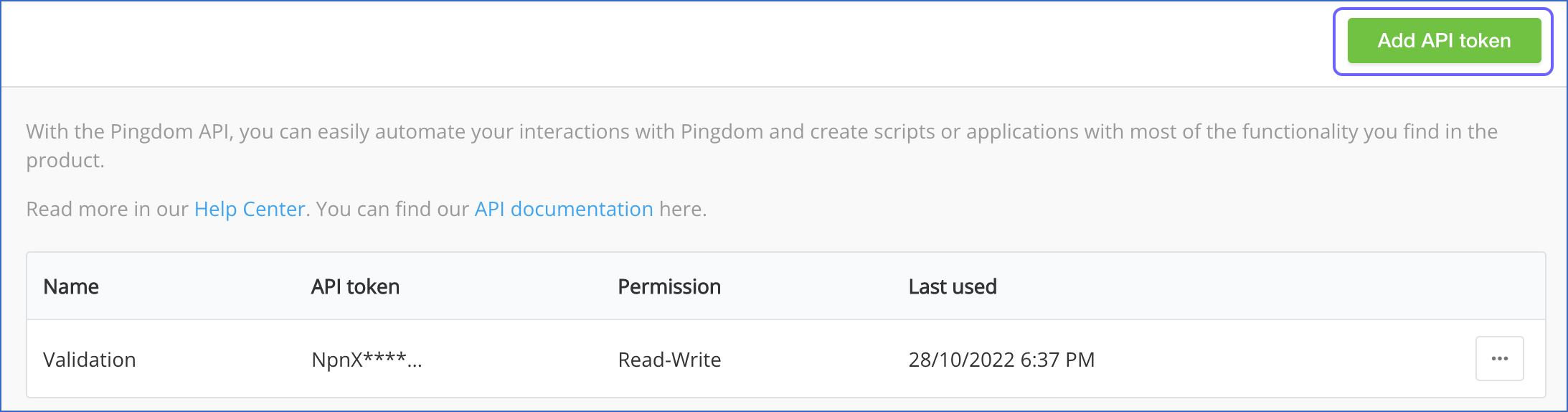
-
In the Add API token pop-up window, specify the following:
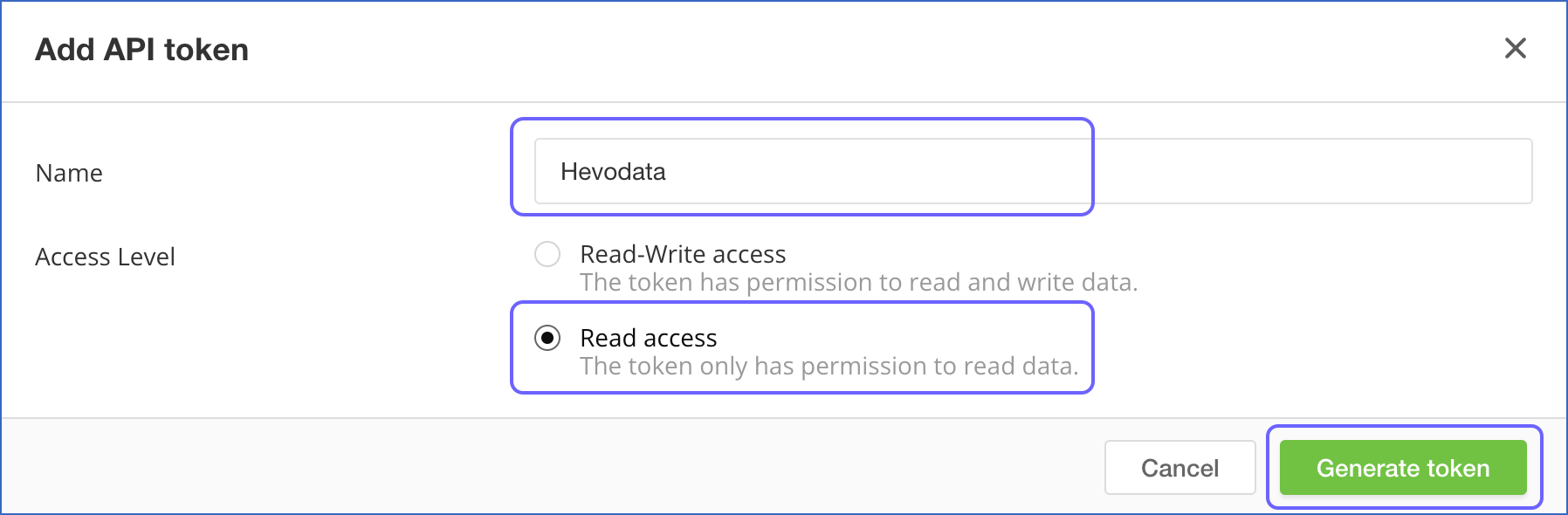
-
Name: A unique name for your API token.
-
Access Level: Select the Read access permission to allow Hevo to ingest your data.
-
-
Click Generate token.
-
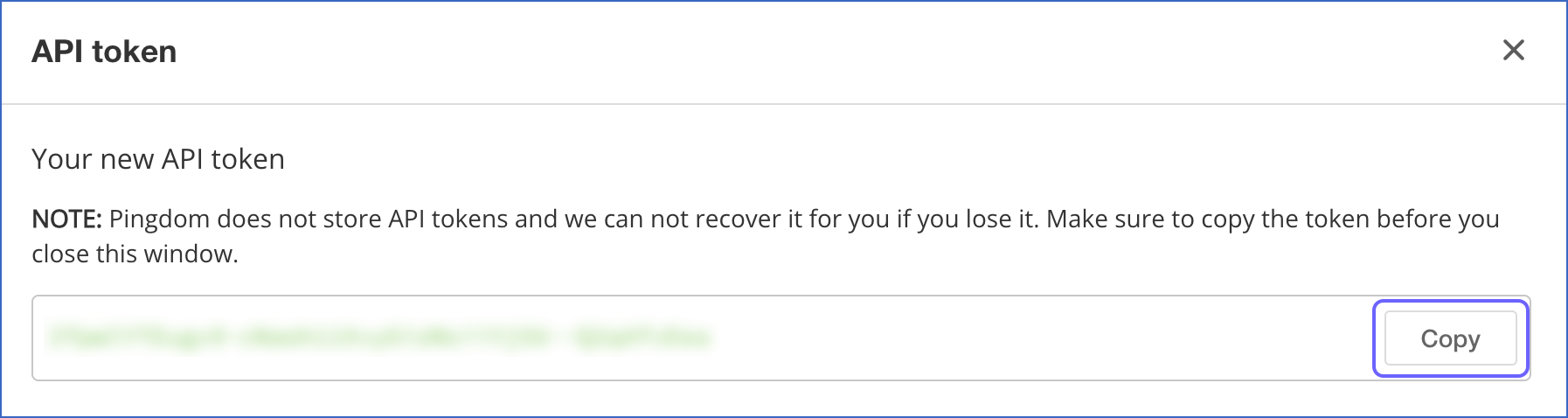
In the API token pop-up dialog, under the Your new API token section, click Copy corresponding to the API token to copy it and save it securely like any other password. Use this token while configuring your Hevo Pipeline.
Configuring Pingdom as a Source
Perform the following steps to configure Pingdom as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
In the Select Source Type page, select Pingdom.
-
In the Configure your Pingdom Source page, specify the following:
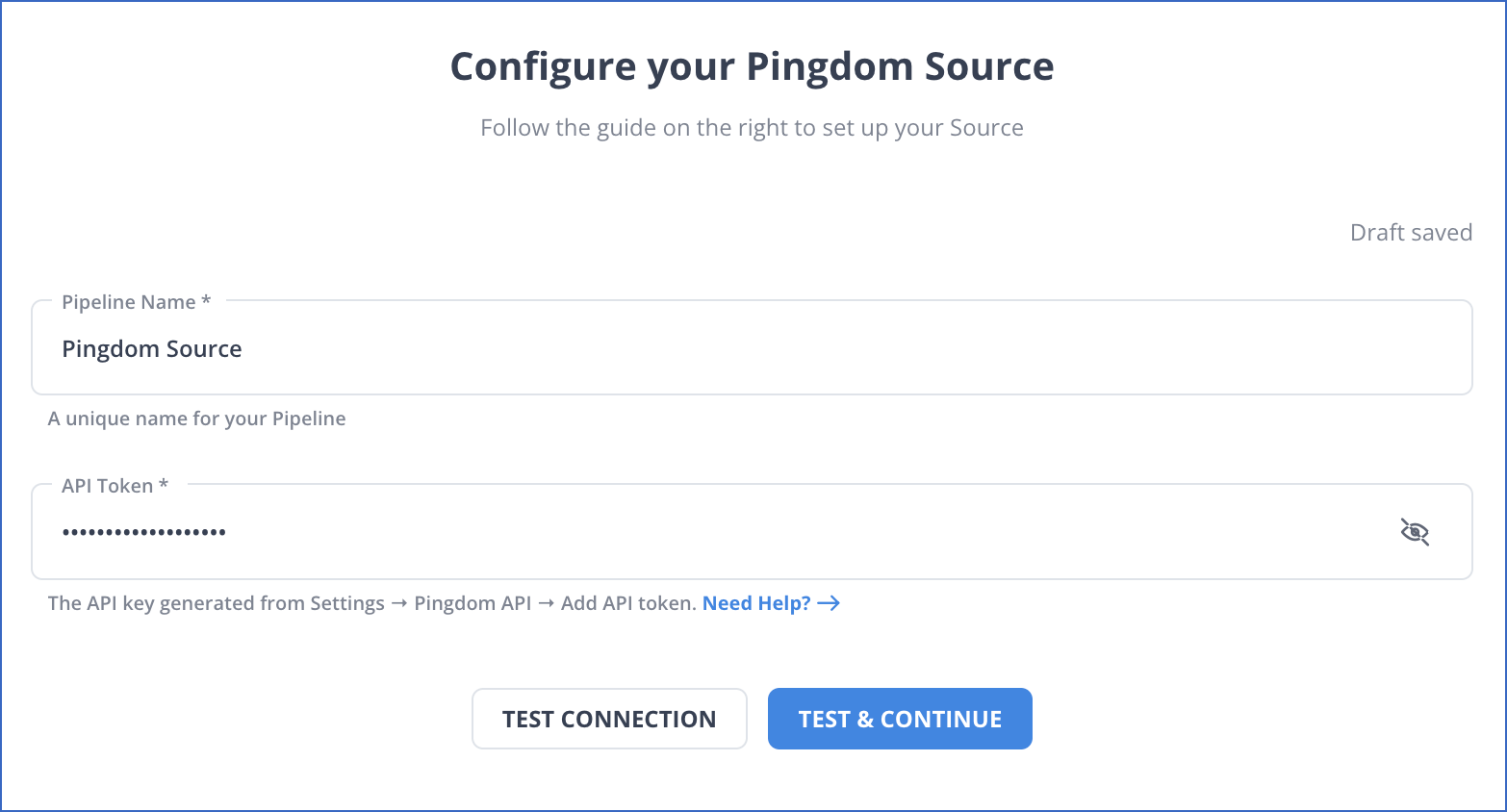
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
API Token: The API token that you generated in your Pingdom account to allow Hevo to access your data.
-
-
Click TEST & CONTINUE.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 1 Hr | 1 Hr | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests all the existing data for the selected objects from your Pingdom account and loads it to the Destination.
-
Incremental Data: Once the historical load is complete, all new and updated records for the Actions, Maintenance Occurrences, and Results objects are ingested as per the ingestion frequency. The remaining objects are ingested in Full Load mode.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination database:
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
| Object | Mode | Description |
|---|---|---|
| Actions | Incremental | Contains the details of all the alerts generated in your account. |
| Checks | Full Load | Contains the details of all the monitoring tests that you have specified to ensure all the services are functioning as expected in your website. |
| Credits | Full Load | Contains the details about the number of exhausted and remaining credits in your Pingdom account. Credits are a way to regulate how many alerts you can receive from Pingdom in a month. |
| Maintenance | Full Load | Contains the details about the time intervals for which the website monitoring is disabled, so you can perform maintenance on the host machines. |
| Maintenance Occurrences | Incremental | Contains the start and end timestamp for a maintenance activity. |
| Probes | Full Load | Contains the list of all the servers that Pingdom uses to test your website. |
| Reference | Full Load | Contains the details such as the ID and name of the regions, countries, and timezones associated with your Pingdom account, which you can use to reference them when making API requests. |
| Teams | Full Load | Contains the details of all the groups of users present in your Pingdom account. |
| Contacts | Full Load | Contains the details of the team members eligible to receive email notifications when an alert is triggered, or who can receive scheduled reports through email. |
| Transaction Checks | Full Load | Contains the list of all the tests that verify if the transactions on your website are working as expected, by reproducing them at regular intervals. A transaction on your website involves several steps or scripts working together to produce a result. For example, a user creating a new account on the website or adding items to the shopping cart. |
| Summary HoursOfDay | Full Load | Contains the details about the average response time for each hour of the day during a check. |
| Summary Outage | Full Load | Contains the details of the average uptime and downtime during a specific check. |
| Summary Performance | Full Load | Contains the details of the average performance of the website over a certain period of time. |
| Results | Incremental | Contains the details of all the test results for a specific check on your website. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
Pagination: An API call for each Pingdom object fetches one page with up to 100 records.
-
Rate Limit: Pingdom imposes two layers of limits. The first covers a shorter period of time and the second a longer period of time to ensure that their system remains stable for usage by all users. If the limit is exceeded, Hevo defers the ingestion till the limits reset. Read Limits to know more about the rate limits, and configure a suitable ingestion frequency for your Pipeline.
Limitations
-
Hevo currently does not support deletes. Therefore, any data deleted in the Source may continue to exist in the Destination.
-
Hevo does not load an Event into the Destination table if its size exceeds 128 MB, which may lead to discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each row in your Source objects contains less than 100 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Nov-23-2022 | 2.02 | New document. |