Heroku PostgreSQL
On This Page
Starting Release 2.19, Hevo has stopped supporting XMIN as a query mode for all variants of the PostgreSQL Source. As a result, you will not be able to create new Pipelines using this query mode. This change does not affect existing Pipelines. However, you will not be able to change the query mode to XMIN for any objects currently ingesting data using other query modes.
Heroku PostgreSQL is Heroku’s reliable and powerful database as a service based on PostgreSQL. With the fully-managed Heroku Postgres, you can focus on getting the most out of your data without the admin overhead.
You can ingest data from your Heroku PostgreSQL database using Hevo Pipelines and replicate it to a Destination of your choice.
Heroku is a platform where you can deploy applications directly on the cloud. These applications can have add-ons such as databases and email services. To ingest your data, Hevo needs to access the application and the database within. A database can be shared by multiple apps. However, one app can only have one database.
Prerequisites
-
An active Heroku account with an active PostgreSQL database instance.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Perform the following steps to configure your Heroku PostgreSQL Source:
Obtain PostgreSQL Database Credentials
-
Log in to your Heroku account.
-
To access your database, do one of the following:
-
Select your database from the app:
-
Select the app your database is stored in from the drop-down list.
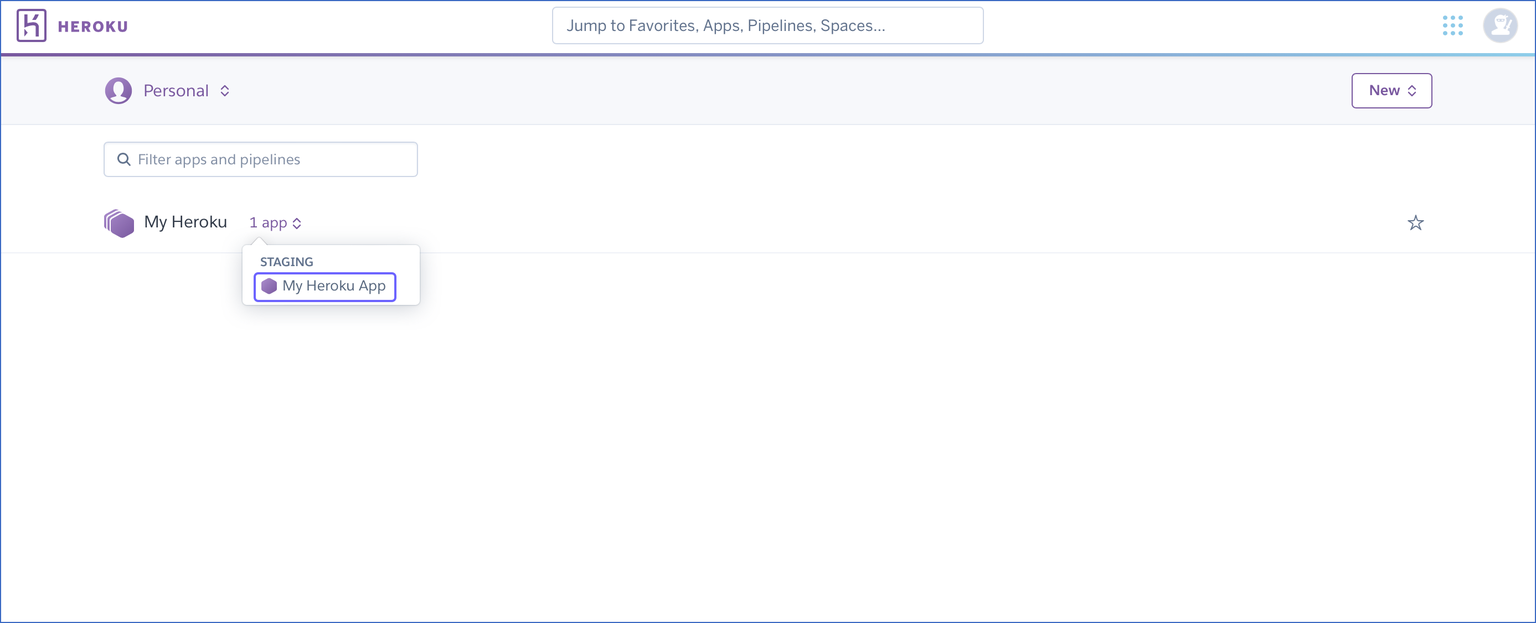
-
Click on your database in the Installed add-ons section.

-
-
Select the database from a list:
-
Click the menu icon, and select Data.

-
Click on the PostgreSQL database you want to ingest data from.

-
-
-
Click Settings, and then View Credentials.
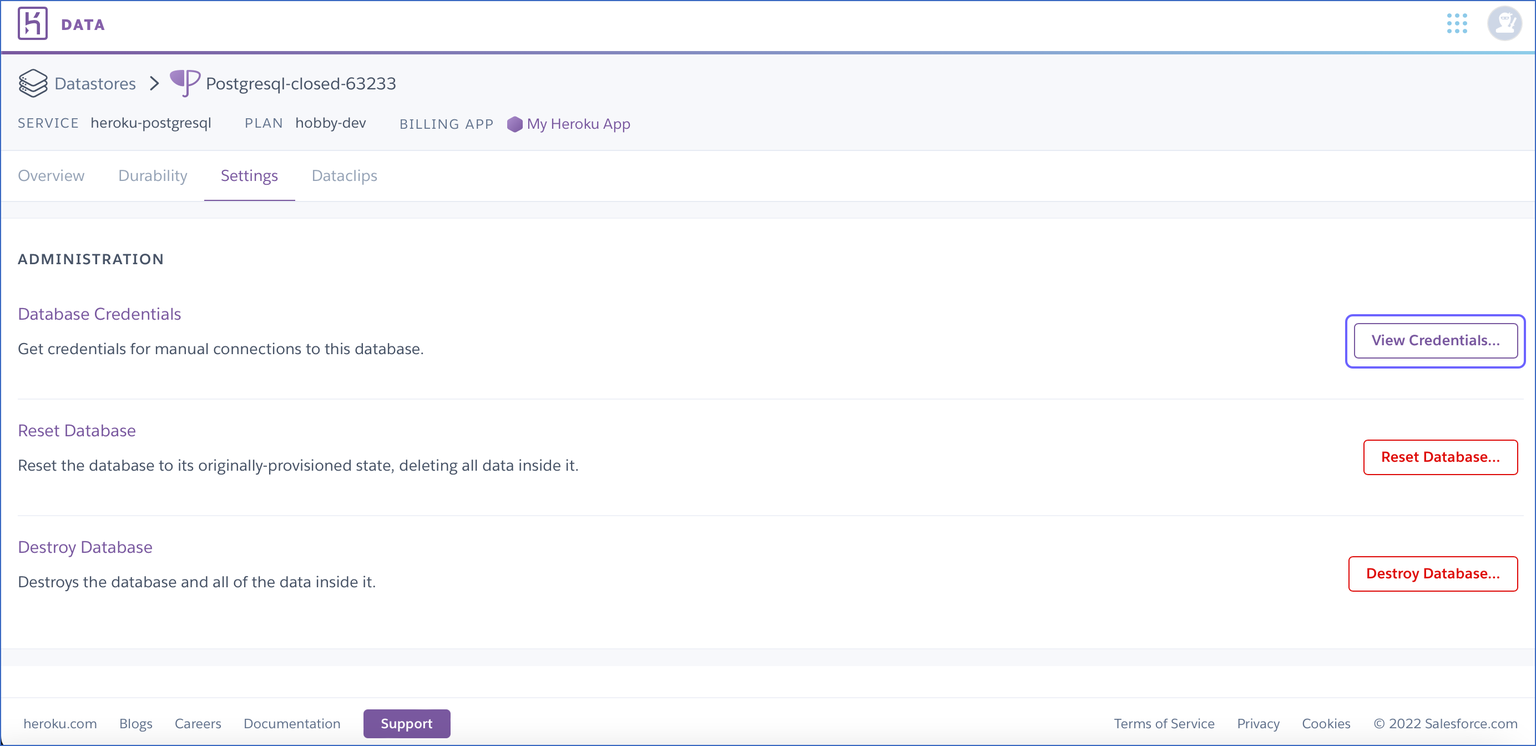
-
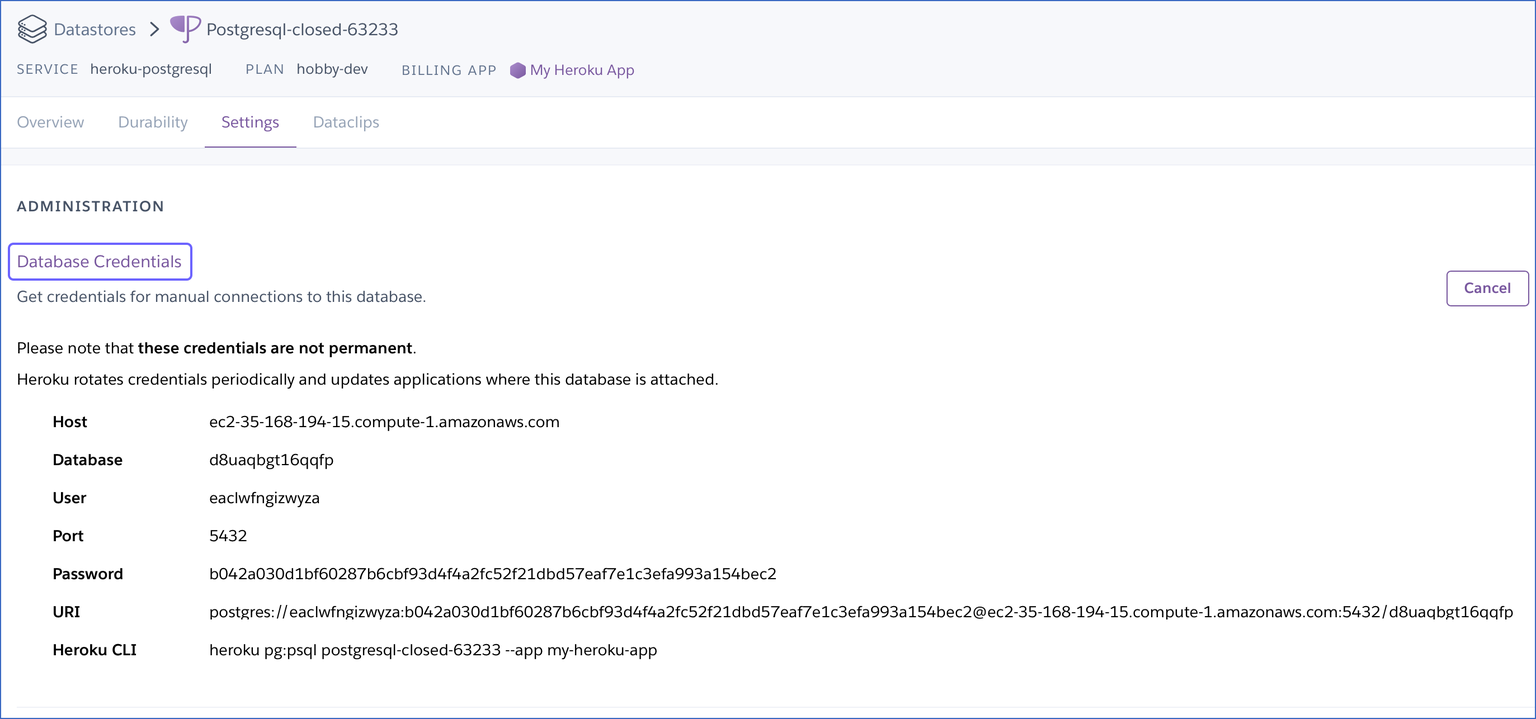
Use the credentials displayed in the Database Credentials section while setting up your Heroku PostgreSQL Source in Hevo.
Specify Heroku PostgreSQL Connection Settings
Perform the following steps to configure Heroku PostgreSQL as a Source in Hevo:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE in the Pipelines List View.
-
In the Select Source Type page, select Heroku PostgreSQL.
-
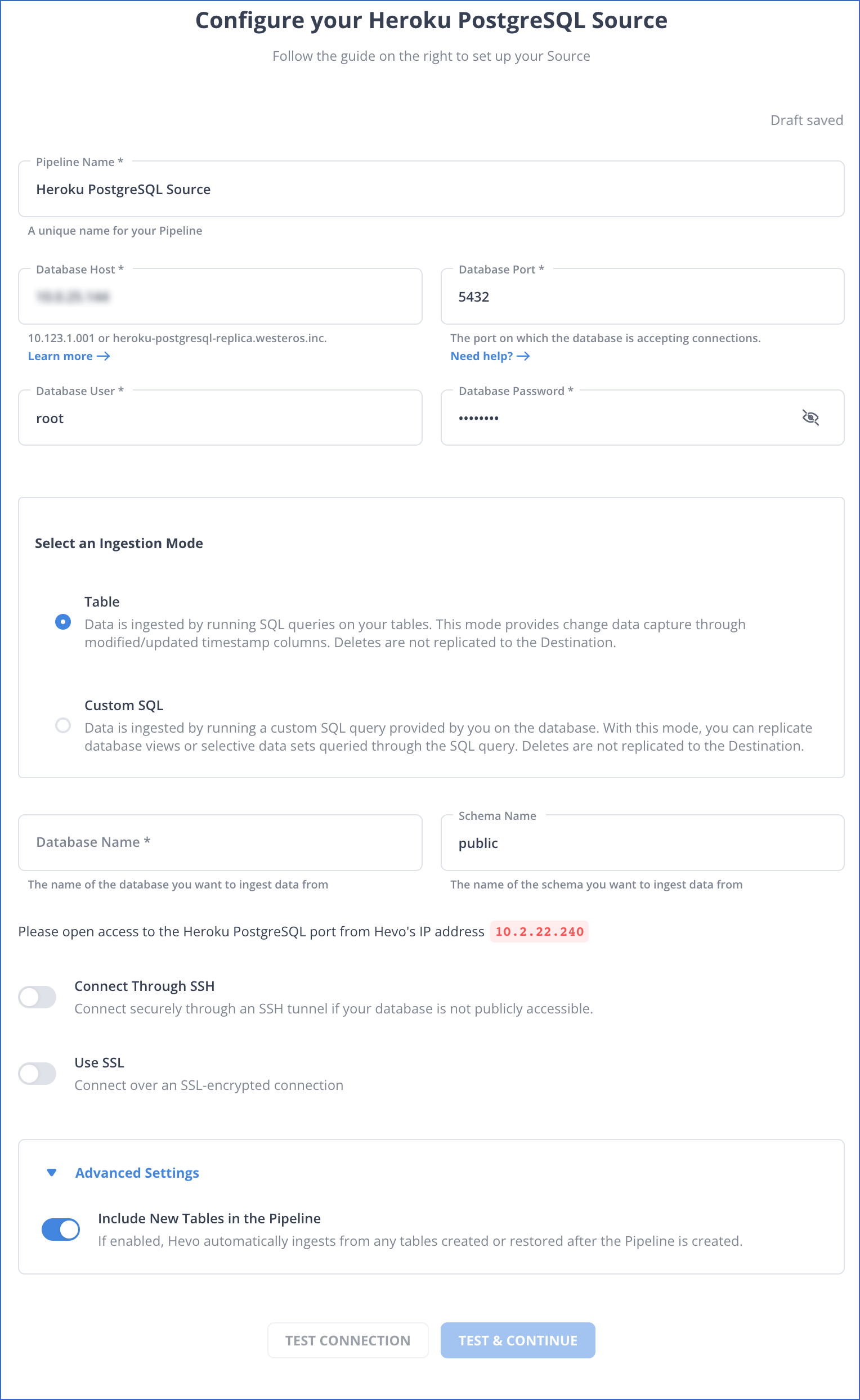
In the Configure your Heroku PostgreSQL Source page, specify the following:
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Database Host: The Heroku PostgreSQL host’s IP address or DNS.
-
Database Port: The port on which your Heroku PostgreSQL server listens for connections. Default value: 5432.
-
Database User: The read-only user who has the permission to read tables in your database.
-
Database Password: The password for the read-only user.
-
Select an Ingestion Mode: The desired mode by which Hevo must ingest data from the Source. The available ingestion modes are Table and Custom SQL. Additionally, the XMIN ingestion mode is available for Early Access. Read Ingestion Modes for more information.
Depending on the ingestion mode you select, you must configure the objects to be replicated. Refer to section, Object and Query Mode Settings for the steps to do this.
Note: For the Custom SQL ingestion mode, all Events loaded to the Destination are billable.
-
Database Name: The name of an existing database that you wish to replicate.
-
Schema Name (Optional): The schema in your database that holds the tables to be replicated. Default value: public.
-
Connection Settings:
-
Connect through SSH: Enable this option to connect to Hevo using an SSH tunnel, instead of directly connecting your PostgreSQL database host to Hevo. This provides an additional level of security to your database by not exposing your PostgreSQL setup to the public. Read Connecting Through SSH.
If this option is turned off, you must whitelist Hevo’s IP addresses. Read Heroku documentation for the steps to do this.
-
Use SSL: Enable this option to use an SSL-encrypted connection. You should enable it for your Heroku PostgreSQL database. Specify the following:
-
CA File: The file containing the SSL server certificate authority (CA).
-
Load all CA Certificates: If selected, Hevo loads all CA certificates (up to 50) from the uploaded CA file, else it loads only the first certificate.
Note: Select this check box if you have more than one certificate in your CA file.
-
-
Client Certificate: The client’s public key certificate file.
-
Client Key: The client’s private key file.
-
-
-
Advanced Settings
-
Include New Tables in the Pipeline: Applicable for all ingestion modes except Custom SQL.
If enabled, Hevo automatically ingests data from tables created in the Source after the Pipeline has been built. These may include completely new tables or previously deleted tables that have been re-created in the Source.
If disabled, new and re-created tables are not ingested automatically. They are added in SKIPPED state in the objects list, in the Pipeline Overview page. You can include these objects post-Pipeline creation to ingest data.You can change this setting later.
-
-
-
Click TEST CONNECTION. This button is enabled once you specify all the mandatory fields. Hevo’s underlying connectivity checker validates the connection settings you provide.
-
Click TEST & CONTINUE to proceed with setting up the Destination. This button is enabled once you specify all the mandatory fields.
Object and Query Mode Settings
Once you have specified the Source connection settings in Step 2 above, do one of the following:
-
For Pipelines configured with the Table mode:
-
In the Select Objects page, select the objects you want to replicate and click CONTINUE.
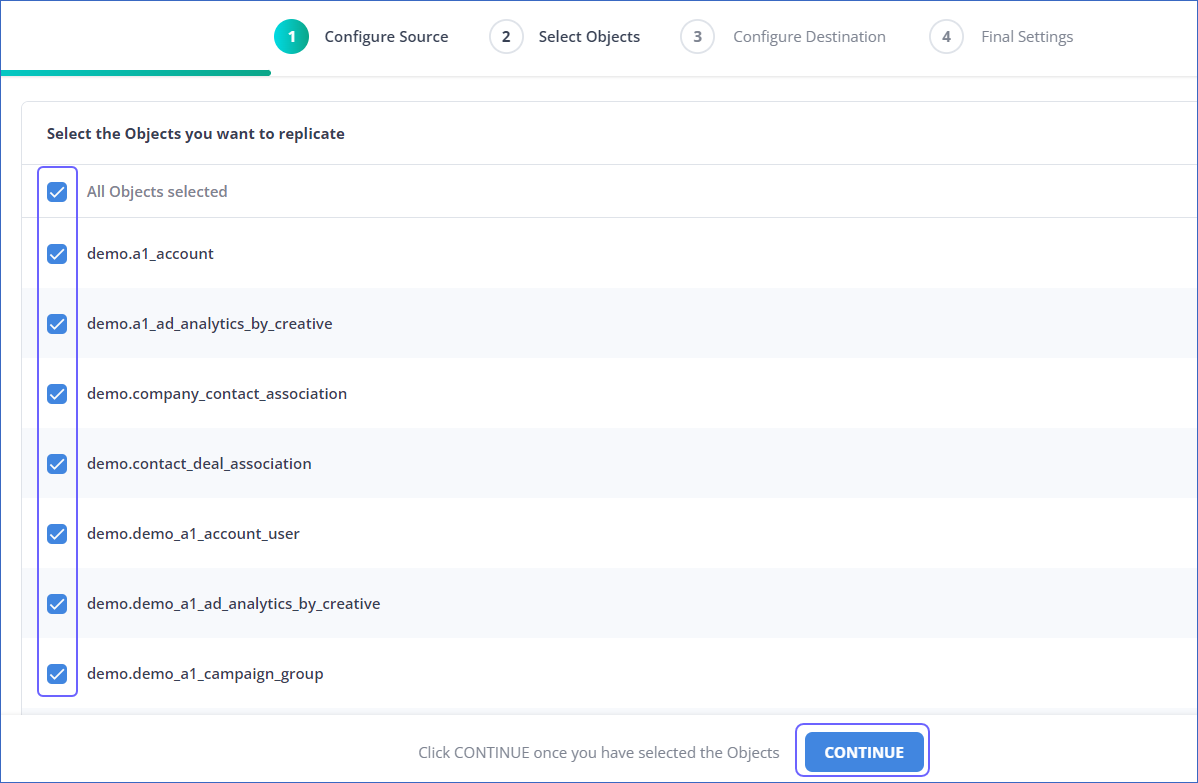
Note: Each object represents a table in your database.
-
In the Configure Objects page, specify the query mode you want to use for each selected object.
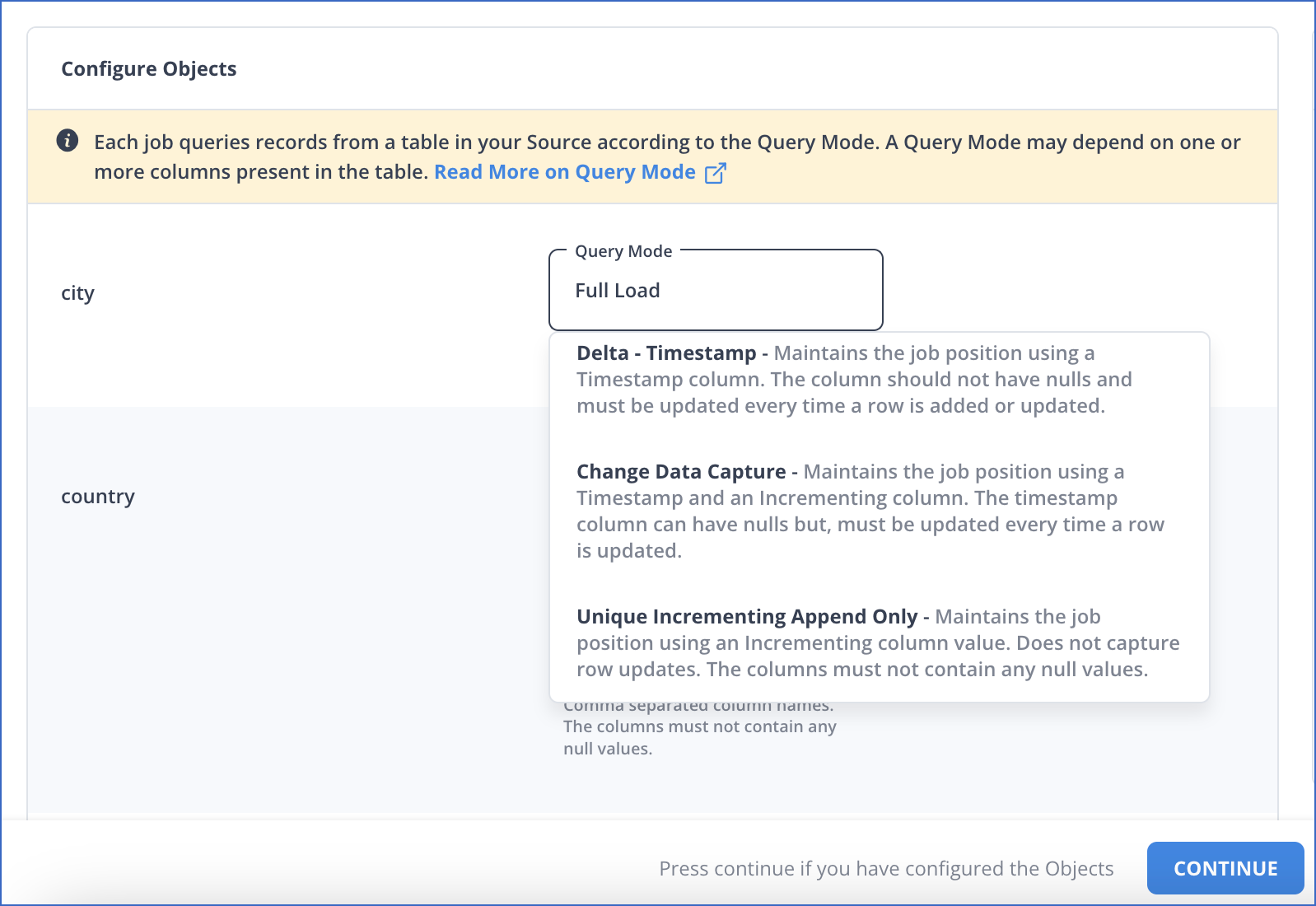
Note: In Full Load mode, Hevo attempts to replicate the full table in a single run of the Pipeline, with an ingestion limit of 25 Million rows.
-
-
For Pipelines configured with the XMIN mode:
-
In the Select Objects page, select the objects you want to replicate.
Note:
-
Each object represents a table in your database.
-
For the selected objects, only new and updated records are ingested using the
XMINcolumn. -
The Edit Config option is unavailable for the objects selected for XMIN-based ingestion. You cannot change the ingestion mode for these objects post-Pipeline creation.
-
-
Click CONTINUE.
-
-
For Pipelines configured with the Custom SQL mode:
-
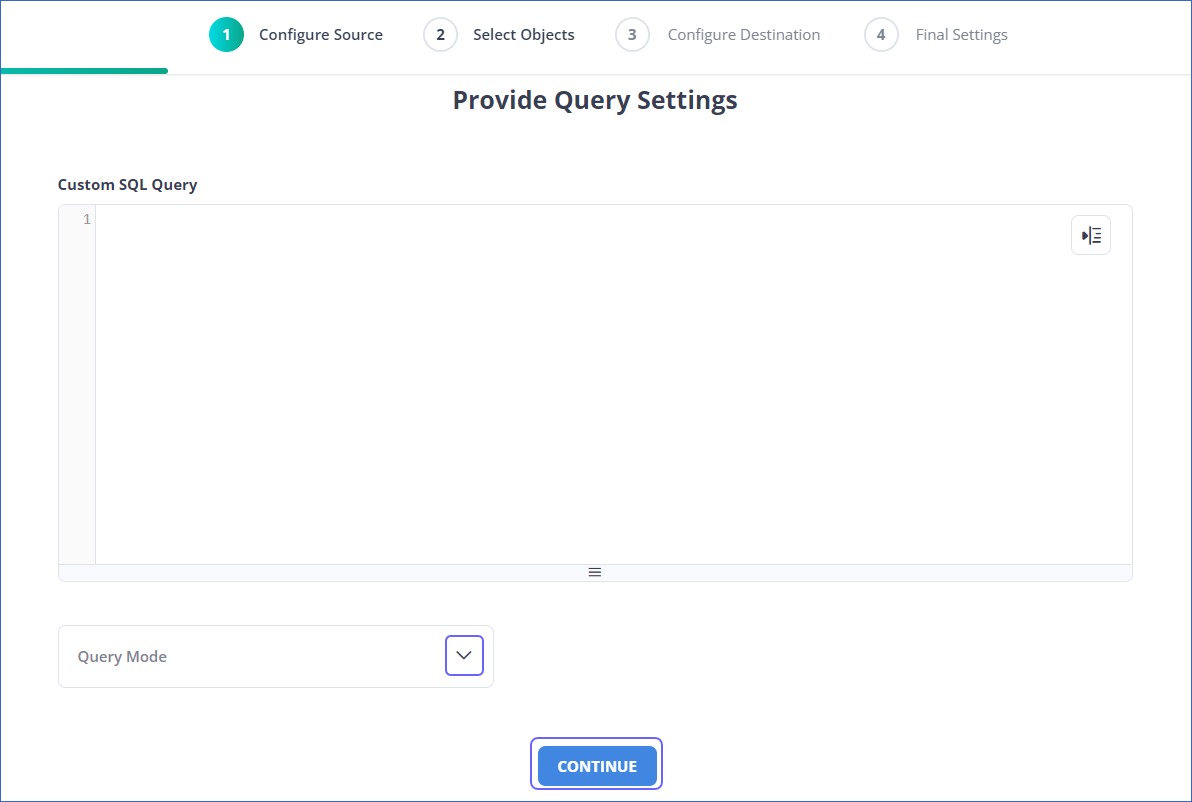
In the Provide Query Settings page, enter the custom SQL query to fetch data from the Source.
-
In the Query Mode drop-down, select the query mode, and click CONTINUE.
-
</div>
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 15 Mins | 15 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3 but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests all available data for the selected objects from your Source database.
-
Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
If you add a column with a default value to a table in PostgreSQL, entries with it are created in the WAL only for the rows that are added or updated after the column is added. As a result, in the case of log-based Pipelines, Hevo cannot capture the column value for the unchanged rows. To capture those values, you need to:
-
Restart the historical load for the respective object.
-
Run a query in the Destination to add the column and its value to all rows.
-
-
As Heroku does not support log-based replication, you must use Table or Custom SQL ingestion mode while creating your Pipeline in Hevo.
-
When you delete a row in the Source table, its XMIN value is deleted as well. As a result, for Pipelines created with the XMIN ingestion mode, Hevo cannot track deletes in the Source object(s). To capture deletes, you need to restart the historical load for the respective object.
-
XMIN is a system-generated column in PostgreSQL, and it cannot be indexed. Hence, to identify the updated rows in Pipelines created with the XMIN ingestion mode, Hevo scans the entire table. This action may lead to slower data ingestion and increased processing overheads on your PostgreSQL database host.
Note: The XMIN limitations specified above are applicable only to Pipelines created using the XMIN ingestion mode, which is currently available for Early Access.
Limitations
-
The data type Array in the Source is automatically mapped to Varchar at the Destination. No other mapping is currently supported.
-
Hevo does not support data replication from foreign tables, temporary tables, and views.
-
If your Source data has indexes (indices) and constraints, you must recreate them in your Destination table, as Hevo does not replicate them from the Source. It only creates the existing primary keys.
-
Hevo does not set the
__hevo_marked_deletedfield to True for data deleted from the Source table using the TRUNCATE command. This could result in a data mismatch between the Source and Destination tables. -
Hevo supports only RSA-based keys for establishing SSL connections. RSA is an encryption algorithm used for certificate private keys. You must ensure that your SSL certificates and keys are RSA-based.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jun-27-2024 | NA | Updated section, Limitations to add information about Hevo supporting only RSA-based keys. |
| Apr-29-2024 | NA | Updated section, Specify Heroku PostgreSQL Connection Settings to include more detailed steps. |
| Mar-18-2024 | 2.21.2 | Updated section, Specify Heroku PostgreSQL Connection Settings to add information about the Load all CA certificates option. |
| Mar-05-2024 | 2.21 | Added the Data Replication section. |
| Feb-05-2024 | NA | Updated sections, Specify Heroku PostgreSQL Connection Settings and Object and Query Mode Settings to add information about the XMIN ingestion mode. |
| Jan-10-2024 | NA | - Updated section, Source Considerations to add information about limitations of XMIN query mode. - Removed mentions of XMIN as a query mode. |
| Nov-03-2023 | NA | Renamed section, Object Settings to Object and Query Mode Settings. |
| Oct-03-2023 | NA | - Updated sections: - Specify Heroku PostgreSQL Connection Settings to describe the schema name displayed in Table and Custom SQL ingestion modes, - Source Considerations to add information about logical replication not supported on read replicas, and - Limitations to add limitations about data replicated by Hevo. |
| Sep-19-2023 | NA | Updated section, Limitations to add information about Hevo not supporting data replication from certain tables. |
| Jun-26-2023 | NA | Added section, Source Considerations. |
| Apr-21-2023 | NA | Updated section, Specify Heroku PostgreSQL Connection Settings to add a note to inform users that all loaded Events are billable for Custom SQL mode-based Pipelines. |
| Dec-19-2022 | 2.04 | Updated section, Specify Heroku PostgreSQL Connection Settings to add information that you must specify all fields to create a Pipeline. |
| Dec-07-2022 | 2.03 | Updated section, Specify Heroku PostgreSQL Connection Settings to mention about including skipped objects post-Pipeline creation. |
| Dec-07-2022 | 2.03 | Updated section, Specify Heroku PostgreSQL Connection Settings to mention about the connectivity checker. |
| Sep-05-2022 | NA | Updated sections, Obtain PostgreSQL Database Credentials and Specify Heroku PostgreSQL Connection Settings for more clarity and detail. |
| Jul-04-2022 | NA | - Added section, Specify Heroku PostgreSQL Connection Settings and Object Settings. |
| Jan-24-2022 | 1.80 | Removed from Limitations that Hevo does not support UUID datatype as primary key. |
| Sep-09-2021 | 1.71 | Updated the section, Limitations to include information about columns with the UUID data type not being supported as a primary key. |