Freshdesk
On This Page
Freshdesk is a cloud-based customer support platform that enables companies of all sizes to provide great customer service.
Hevo uses Freshdesk API v2.0 , which uses your personal API Key to fetch the customer support-related data stored in your Freshdesk account and synchronize it to your desired Destination.
Prerequisites
-
An active Freshdesk account from which data is to be ingested exists.
-
The API key is available to authenticate Hevo on your Freshdesk account. The API key has access to the /v2/tickets API endpoint.
-
You are logged in as an Admin user to create the API key.
-
The Freshdesk account domain used to access the dashboard is available. It is usually in the format,
<companyname>.freshdesk.com. -
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Creating the API Key
The API key that you generate in Freshdesk does not expire. Therefore, you can use an existing key or create a new one to authenticate Hevo on your Freshdesk account.
Note: You must log in as an Admin user to perform these steps.
To obtain the API key:
-
Log in to your Freshdesk account.
-
In the top right corner of the page, click your profile icon.
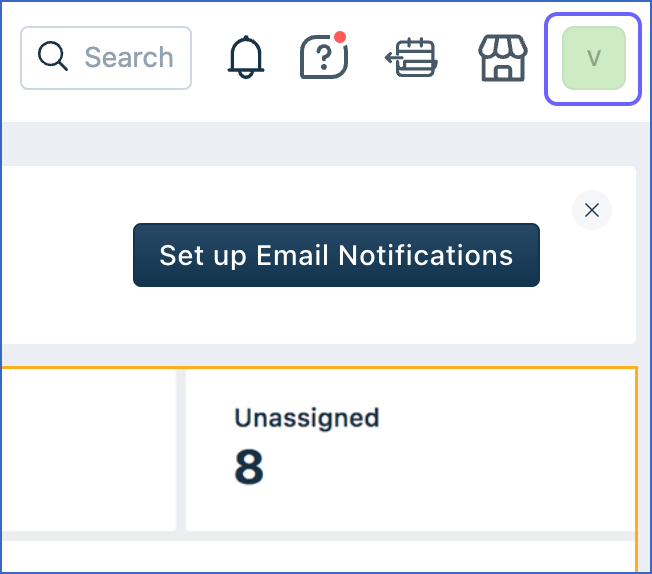
-
In the drop-down, click Profile Settings.
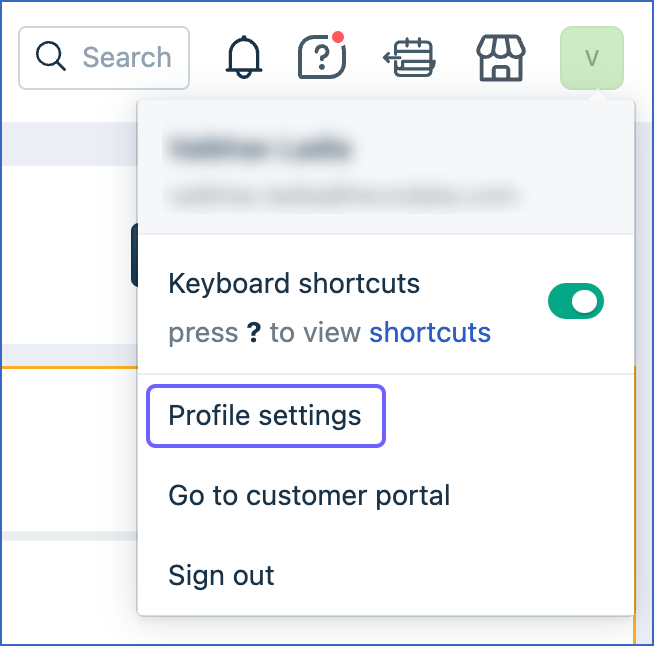
-
In the top right section of the page that appears, click View API Key.
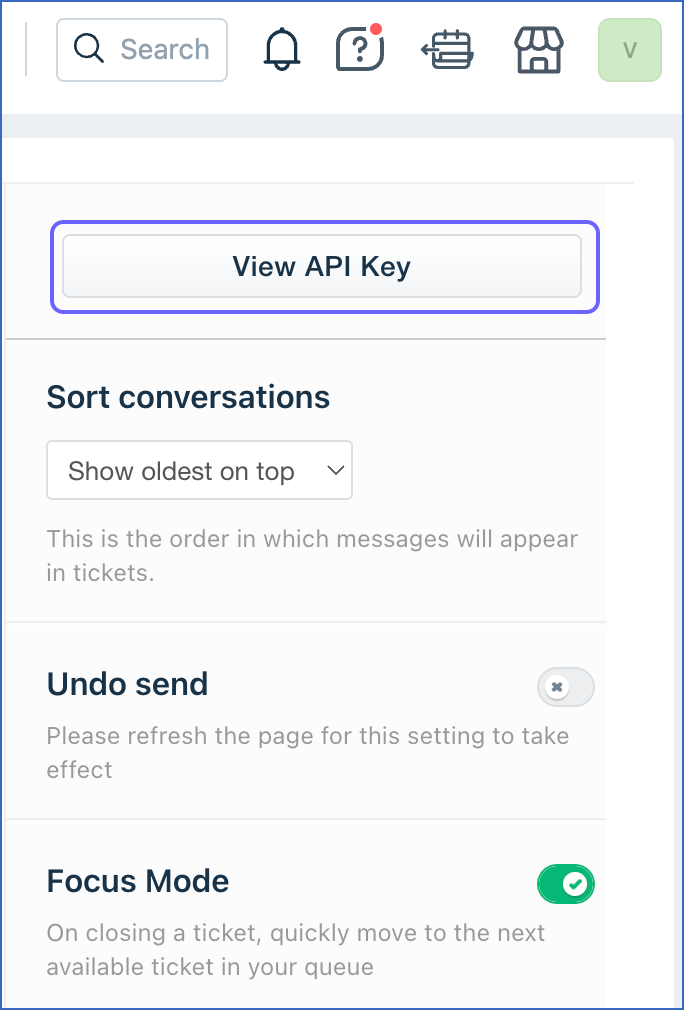
-
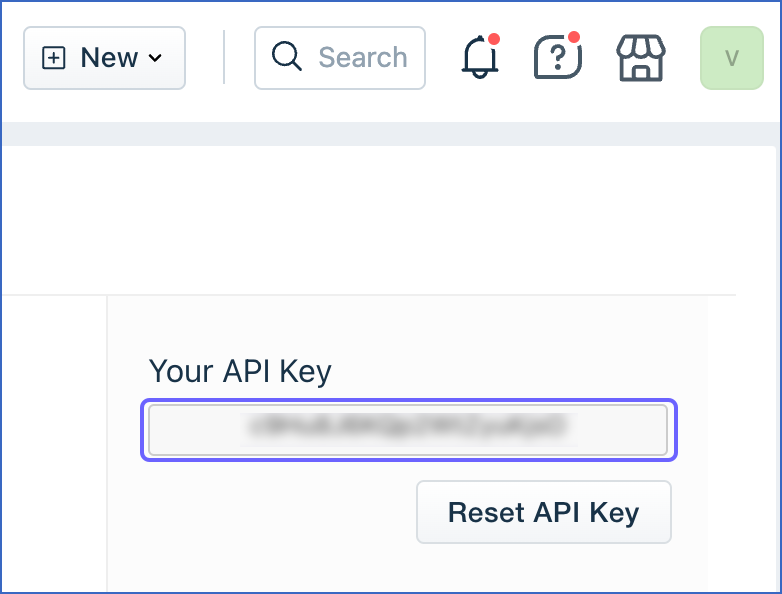
Verify your identity to obtain the API key.
-
Copy the API key and save it securely like any other password. Use this key as the API token while configuring your Hevo Pipeline.
Configuring Freshdesk as a Source
Perform the following steps to configure Freshdesk as a Source in Hevo:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
In the Select Source Type page, select Freshdesk.
-
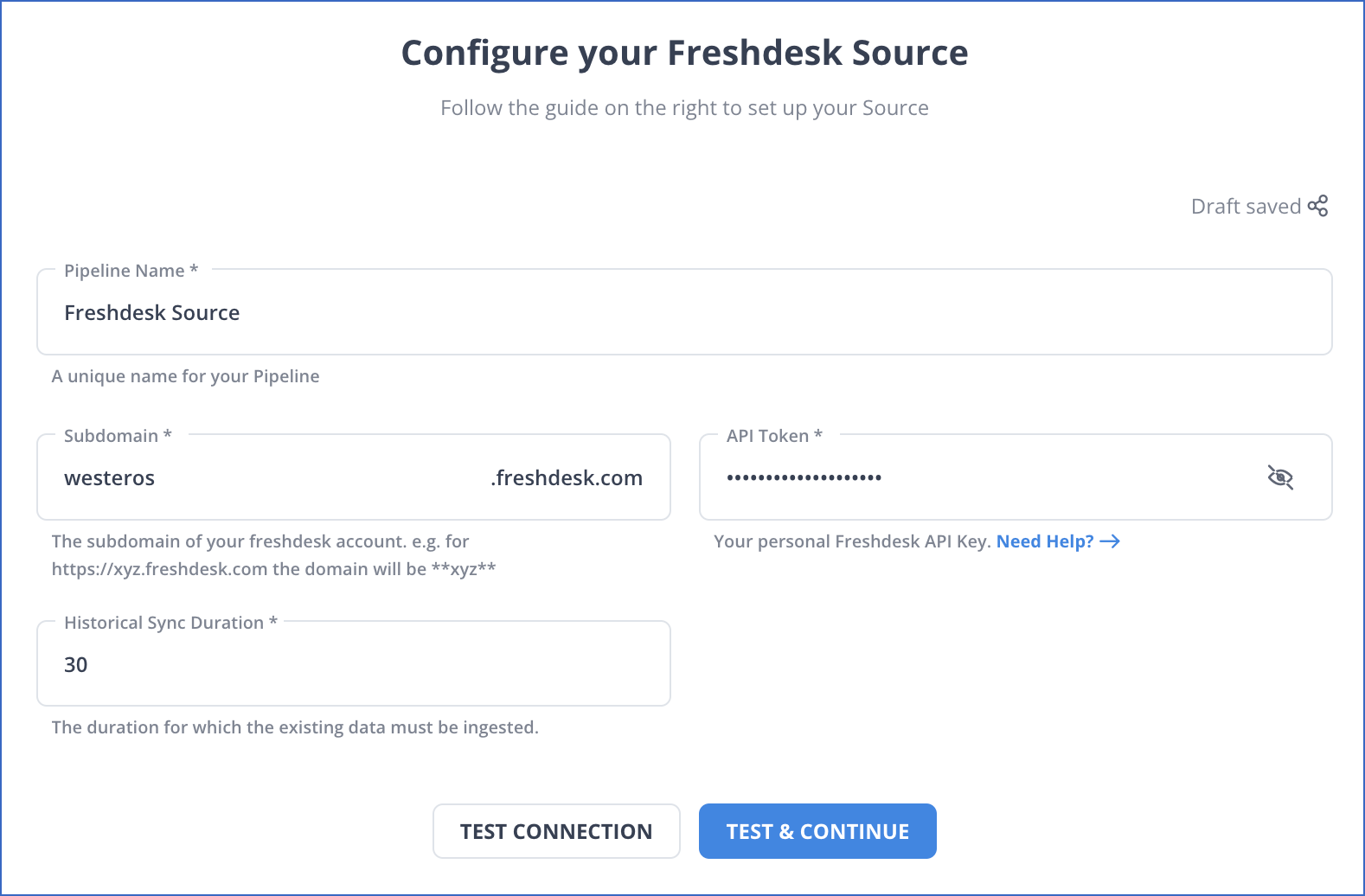
In the Configure your Freshdesk Source page, specify the following:
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Subdomain: The domain identifier for your Freshdesk account. For example, in http://westeros.freshdesk.com, the domain name is westeros.
-
API Token: The API token that you created above.
-
Historical Sync Duration: The duration for which you want to ingest the existing data from the Source. Default duration: 30 Days.
-
-
Click TEST & CONTINUE.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 30 Mins | 5 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests the data of the past 30 days for the selected objects in your Freshdesk account. You can use the Change Position option for an object to load data older or recent than 30 days.
Note: Hevo ingests all available data for the Conversations object by default, potentially exceeding the Freshdesk API rate limit and increasing your Events quota consumption. However, you can disable the data ingestion for this object by contacting Hevo Support.
-
Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency in Full Load or Incremental mode, as applicable.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination:
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline.
| Table Name | Description |
|---|---|
| Agents | Contains details of all the full-time or and occasional users who log in to your help-desk. Full-time agents are those who log in to your help-desk every day, such as, support engineers. Occasional agents are those who need to log in only a few times every month, such as, the CEO or field staff. |
| Business Hours | Contains details of the working hours of your company. If business hours are configured, anything outside of these hours is not timed by Freshdesk. |
| Companies | Contains details of all the companies that contact you. All contacts from the same company are grouped under that company name for easy reference. |
| Contacts | Contains details of all the existing or potential customers who have raised a support ticket through any channel. |
| Conversations | Contains details of all the replies, as well as public and private notes added to a ticket. Notes are non-invasive ways of sharing updates about a ticket amongst agents and customers. Note: Hevo ingests all available data for this object by default, potentially exceeding the Freshdesk API rate limit and increasing your Events quota consumption. However, you can disable the data ingestion for this object by contacting Hevo Support. |
| Discussions | Contains details of all the conversations between customers, for example, sharing of queries, responses and ideas. |
| Email Configs | Contains details of all the emails received and sent through your Freshdesk account. |
| Groups | Contains details of collections of agents who will focus on one kind of problem and get to know the solutions and customers better. |
| Products | Contains details of the different products offered by your company. Each product has its own support portal URL, and agents can support all the products through a single helpdesk. |
| Roles | Contains details of a set of the different privileges and profiles specifying what an agent can see and do within the Freshdesk support portal. |
| Satisfaction Ratings | Contains details of the responses received for a customer satisfaction survey. These responses are used to generate a customer satisfaction report and evaluate the agents’ performance in addressing customer expectations. |
| Surveys | Contains details of customer surveys, a built-in feature in Freshdesk which is used to directly measure help-desk efficiency and customer satisfaction with every support ticket. |
| Tickets | Contains details of the tickets raised by a requester that need to be solved by the agents. Tickets are assigned to agents based on the subject of the ticket and agents’ expertise. |
| Time Entries | Contains details of the time spent by agents in resolving the issue. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Limitations
-
Objects such as Agents, Business Hours, Groups, and Email Groups require
ADMINaccess to fetch data. -
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change | |
|---|---|---|---|
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. | lumn size in an Event. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. | |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. | |
| Oct-03-2023 | NA | Updated section, Creating the API Key as per the latest Freshdesk UI. | |
| Mar-23-2023 | NA | Updated sections, Data Replication and Data Model to add a note regarding Hevo ingesting all available data for the Conversations object. | |
| Jan-10-2023 | 2.05 | Updated section, Data Replication to mention about custom ingestion frequency. | |
| Dec-19-2022 | 2.04 | Updated section, Data Model to include information about the new objects supported by Hevo. | |
| Dec-14-2022 | NA | Updated section, Configuring Freshdesk as a Source to reflect the latest Hevo UI. | |
| May-10-2022 | NA | Updated section, Prerequisites to add information about the API endpoint that your API key should have access to. | |
| Aug-09-2021 | NA | Updated the default historical load duration to 30 days in the Data Replication section and suggested the Change Position option to fetch Events beyond or more recent than 30 days. |