Help Scout
On This Page
Help Scout is an email-based customer support software that assists small businesses and teams manage their customer relationships. Help Scout is similar to your email with a mailbox at the top of the hierarchy. All customer-related communication is tracked through conversations and threads in the mailbox, eliminating the need to manage ticket numbers and case numbers. In Help Scout, you can create multiple mailboxes for each shared email address. This allows your users across various departments, such as support, marketing, and customer success, to collaborate and manage different products or brands from a single account. Help Scout also provides your users visibility into the emails being responded to in real-time.
You can replicate the data from your HelpScout account to a Destination database or data warehouse using Hevo Pipelines. Refer to the Data Model section for information on the objects that Hevo creates in your Destination.
Prerequisites
-
An active Help Scout account from which data is to be ingested exists.
-
An active Help Scout user with access to at least one customer mailbox.
-
A subscription to Help Scout’s Plus or Company plan if you want to read data from the Custom Fields object.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Configuring Help Scout as a Source
Perform the following steps to configure Help Scout as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
In the Select Source Type page, select Help Scout.
-
In the Configure your Help Scout account page, do one of the following:
-
Select a previously configured account and click CONTINUE.
-
Click + ADD HELP SCOUT ACCOUNT and perform the following steps to configure an account:

-
Log in to your Help Scout account.
-
Click Authorize, providing Hevo access to your Help Scout data.
-
-
-
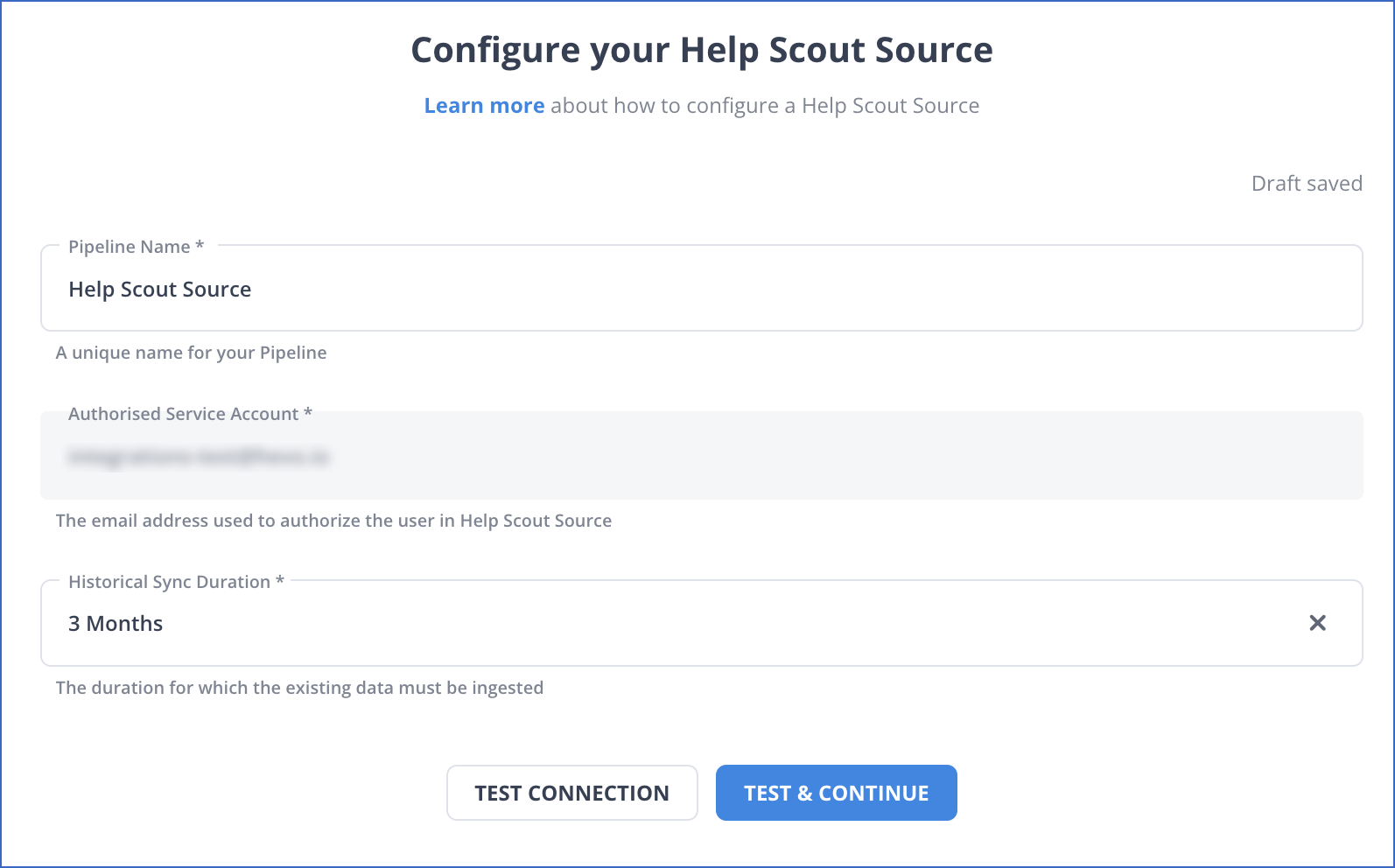
In the Configure your Help Scout Source page, specify the following:
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Authorized Account (Non-editable): This field is pre-filled with the email address that you selected earlier when connecting to your Help Scout account.
-
Historical Sync Duration: The duration for which you want to ingest the existing data from the Source. Default duration: 3 Months.
Note: If you select All Available Data, Hevo ingests all the data available in your HelpScout account since January 01, 2011.
-
-
Click TEST & CONTINUE.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 15 Mins | 5 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests the historical data for all the objects and loads it to the Destination. For the Conversation and Customer objects, the historical data is ingested based on the historical sync duration selected when creating the Pipeline. Default duration: 3 Months.
For the objects, Mailbox, Tag, Team, User, and Workflow, Hevo ingests all historical data present in your account.
-
Incremental Data: Once the historical load is complete, all new and updated records for the Conversation and Customer objects are ingested as per the ingestion frequency. The remaining objects are ingested in Full Load mode.
For Mailbox, Tag, Team, User, and Workflow, which are Full Load objects, Hevo fetches all the data but loads only the new and updated records to the Destination as per the ingestion frequency. It achieves this by filtering the previously ingested data based on the position stored at the end of the last ingestion run.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination:
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
| Object | Description |
|---|---|
| Mailbox | Contains details about the mailboxes in your Help Scout account. A mailbox is similar to an inbox and holds the emails sent by your customers. |
| Mailbox Folders | Contains details about the folders that you may have created to organize the conversations sent to your mailboxes. |
| Conversation | Contains details about the communications with your customers. A conversation can be of the type: - chat - phone |
| Conversation Threads | Contains details about the parts of a conversation, such as an email, a note, or a response sent to a mailbox. In Help Scout, each part of the conversation is called a thread. |
| Conversation Attachments | Contains details about the attachments associated with the conversation threads in your mailboxes. |
| Customers | Contains details about the customers in your Help Scout account. |
| Customer Address | Contains the addresses of the customers in your Help Scout account. |
| Customer Chat | Contains details about the chat handles that your customers use. |
| Customer Email | Contains details about the email addresses of the customers in your Help Scout account. |
| Customer Phone | Contains details about the phone numbers associated with a customer in your Help Scout account. |
| Customer Profile | Contains details about the social media profiles of your customers. |
| Customer Website | Contains details about all the websites associated with a particular customer in your Help Scout account. |
| User | Contains details about the users, who are members of an organization or a team, in your Help Scout account. |
| Team | Contains details about the group of users who work together as a single unit on conversations in a mailbox. |
| Team User | Contains details about the users and the teams to which they belong. |
| Tag | Contains details about the tags that you have added to the conversations in your mailbox. For example, a tag to track conversations from priority customers. |
| Workflow | Contains details about the workflows created for the mailboxes in your account. A workflow is similar to an email filter and can be automatic or manual. For example, an automatic workflow to filter conversations based on their subject line. |
| Custom Fields | Contains details about the custom fields that you may have created to categorize, prioritize, or diagnose conversations. For example, a custom field to identify the priority level of a conversation received in your mailbox. Note: You need to be subscribed to Help Scout’s Plus or Company plan to ingest data from this object. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
Help Scout restricts the number of API requests and access to certain API endpoints based on your Help Scout pricing plan. If Hevo exceeds the number of calls allowed by your plan, data ingestion is deferred until the limits are reset (approximately five minutes).
Refer to the following table for the applicable rate limits:
Help Scout Pricing Plan Rate Limit Standard Up to 200 calls per minute Plus Up to 400 calls per minute Company Up to 800 calls per minute
Limitations
- Hevo does not load an Event into the Destination table if its size exceeds 128 MB, which may lead to discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each row in your Source objects contains less than 100 MB of data.
See Also
- Create a Team
- Create and Manage Tags
- Create and Manage Teams
- Create and Manage User Accounts
- Edit Threads and Notes
- Get Started With Workflows
- Work with Custom Fields
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Dec-14-2022 | NA | Updated section, Configuring Help Scout as a Source to reflect the latest Hevo UI. |
| Jul-12-2022 | 1.92 | New document. |