Delighted
On This Page
Delighted is a survey creation and management platform that enables you to gather feedback through metrics such as Net Promoter Score (NPS) and Customer Satisfaction Score (CSAT) from your desired audience. It provides a user-friendly interface to easily create surveys, and distribute them through multiple channels such as emails and text messages. It also provides tools that allow you to gain insights into the survey responses to improve customer satisfaction, reduce churn, and increase brand loyalty.
Delighted authenticates API requests from Hevo to access your account data with HTTP Basic authentication.
Prerequisites
-
An active Delighted account from which data is to be ingested exists.
-
The API key is available to provide Hevo access to your Delighted account data.
-
You are logged in as an Admin or a Standard user to obtain the API key. Else, you can obtain the API key from an administrator or a standard user. Read User Types to know about the different types of user accounts in Delighted.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Obtaining the API Key
You require an API key to authenticate Hevo on your Delighted account. The API key does not expire and can be reused for all your Pipelines.
Note: You must log in as an Admin or a Standard user to perform these steps.
-
Log in to your Delighted account.
-
On the Delighted home page, click Integrations.
-
Click API.
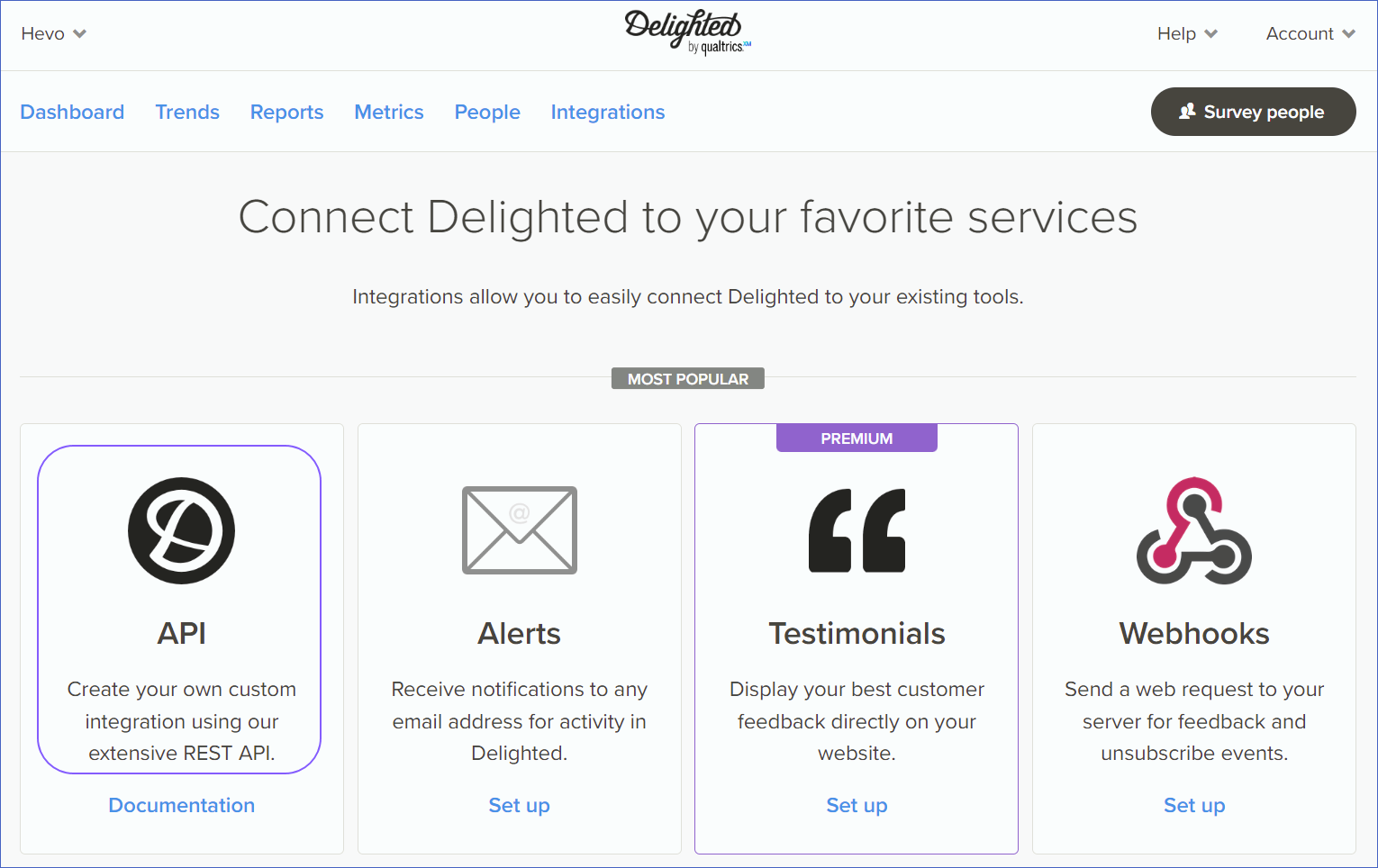
-
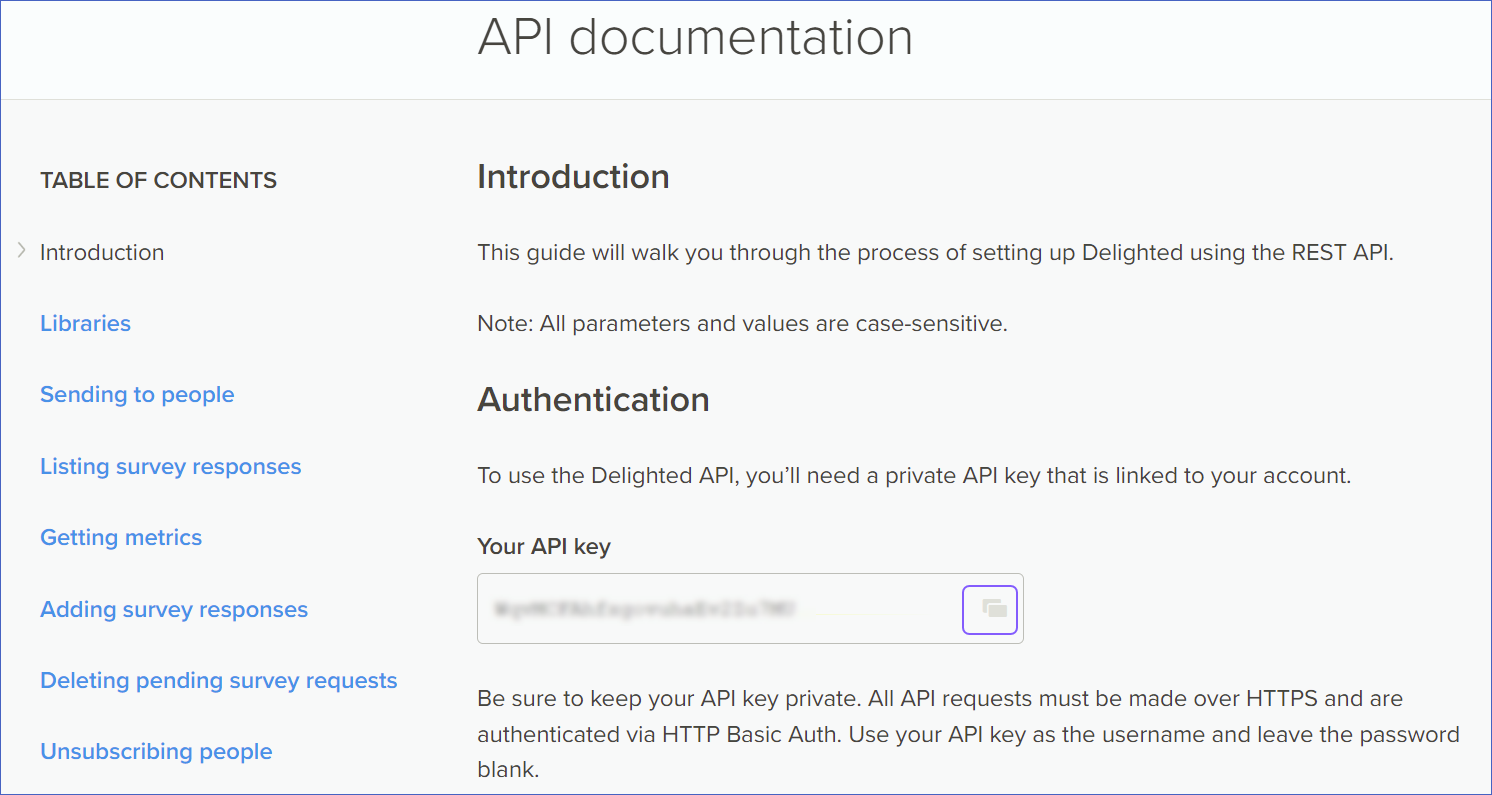
On the API documentation page, Your API key field, click the copy icon to copy the API key and save it securely like any other password. Use this key while configuring your Hevo Pipeline.
Configuring Delighted as a Source
Perform the following steps to configure Delighted as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
On the Select Source Type page, select Delighted.
-
On the Configure your Delighted Source page, specify the following:
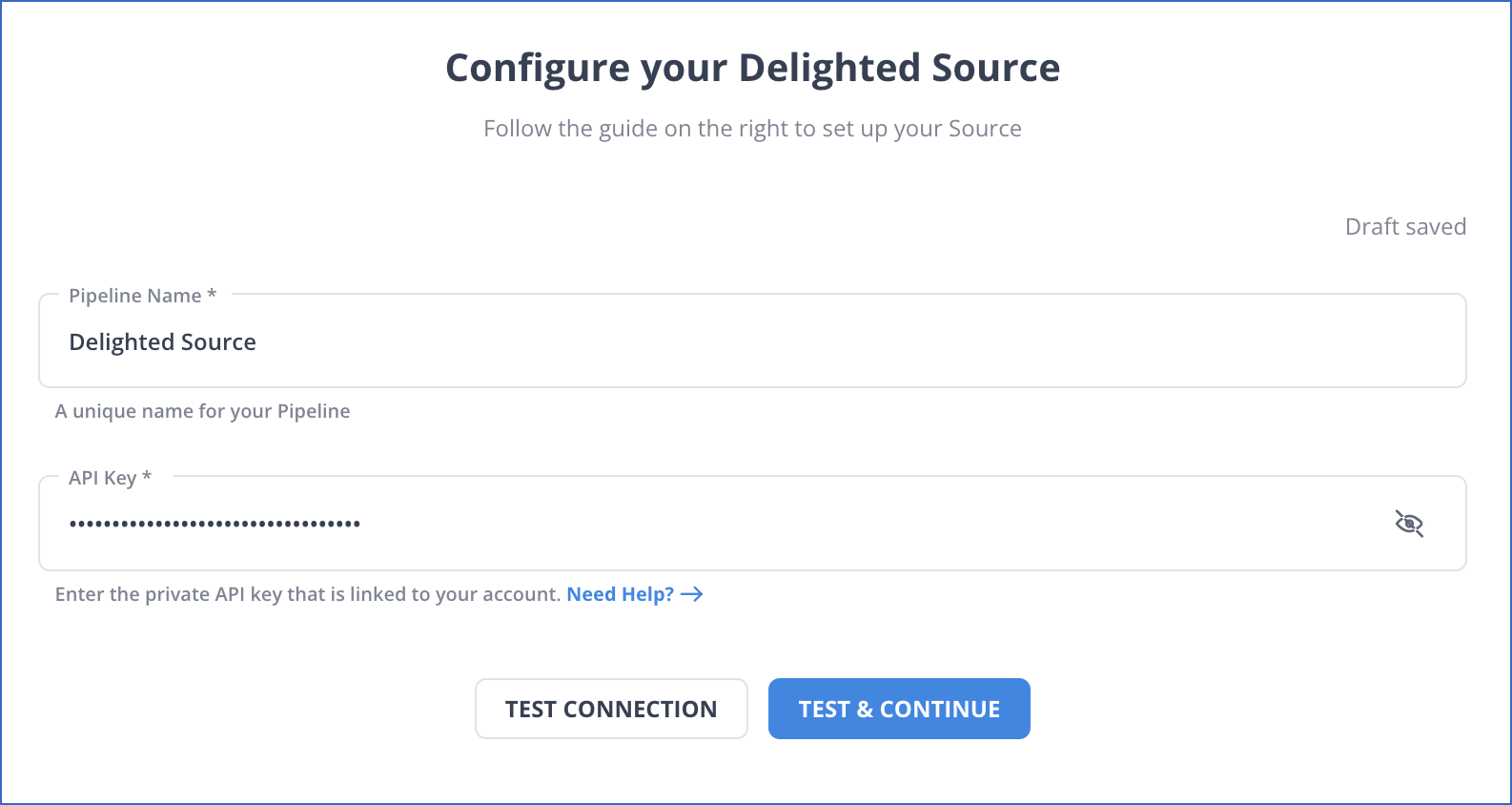
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
API Key: The private key that you obtained from your Delighted account.
-
-
Click TEST & CONTINUE.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 1 Hr | 1 Hr | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
Hevo ingests all the objects in Full Load mode in each run of the Pipeline.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination:
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
| Object | Description |
|---|---|
| Unsubscribed People | Contains the list of all the unsubscribed people for your account, along with the details such as person ID, name, and email ID, and the timestamp at which they unsubscribed. Unsubscribed people do not receive any surveys. |
| Bounced People | Contains the details of all the people who did not receive surveys due to the survey emails being bounced. The details include each person’s email address, name, and the timestamp of the bounced email. |
| Survey Responses | Contains the details of all the survey responses for your account such as the survey ID, survey type, person’s details, survey questions, survey answers, and timestamp at which the survey was created or updated. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
Pagination: An API response for each Delighted object fetches one page with up to 200 records.
-
Rate Limit: Delighted does not impose a hard limit on the number of API calls that can be made in a specific time interval. Read API Rate Limits to know more about rate limits, and configure a suitable ingestion frequency for your Pipeline.
Limitations
-
Hevo currently does not support deletes. Therefore, any data deleted in the Source may continue to exist in the Destination.
-
The data is loaded in Full Load mode in each Pipeline run. As a result, you cannot load the historical data alone at any time.
-
Hevo does not load an Event into the Destination table if its size exceeds 128 MB, which may lead to discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each row in your Source objects contains less than 100 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Dec-14-2022 | NA | Updated section, Configuring Delighted as a Source to reflect the latest Hevo UI. |
| Jul-05-2022 | 1.92 | New document. |