TikTok Ads
On This Page
Effective August 15, 2023, TikTok Ads will deprecate API v1.2 and support only v1.3 of the API. Hence, your Pipelines will not replicate data for the v1.2 objects.
In the API v1.3, the names and data types of some of the fields for the objects and reports have been changed. As a result, starting Release 2.15.2, Hevo will create tables for both v1.2 and v1.3 objects and reports in your Destination. The v1.3 objects will be identified by the suffix _v2. If you want tables from API v1.3 only, you can create a new Pipeline or skip the v1.2 objects from the Pipeline Overview page.
For all Pipelines created after Release 2.15.2, Hevo will ingest only the v1.3 objects and reports; they will still be suffixed with _v2.
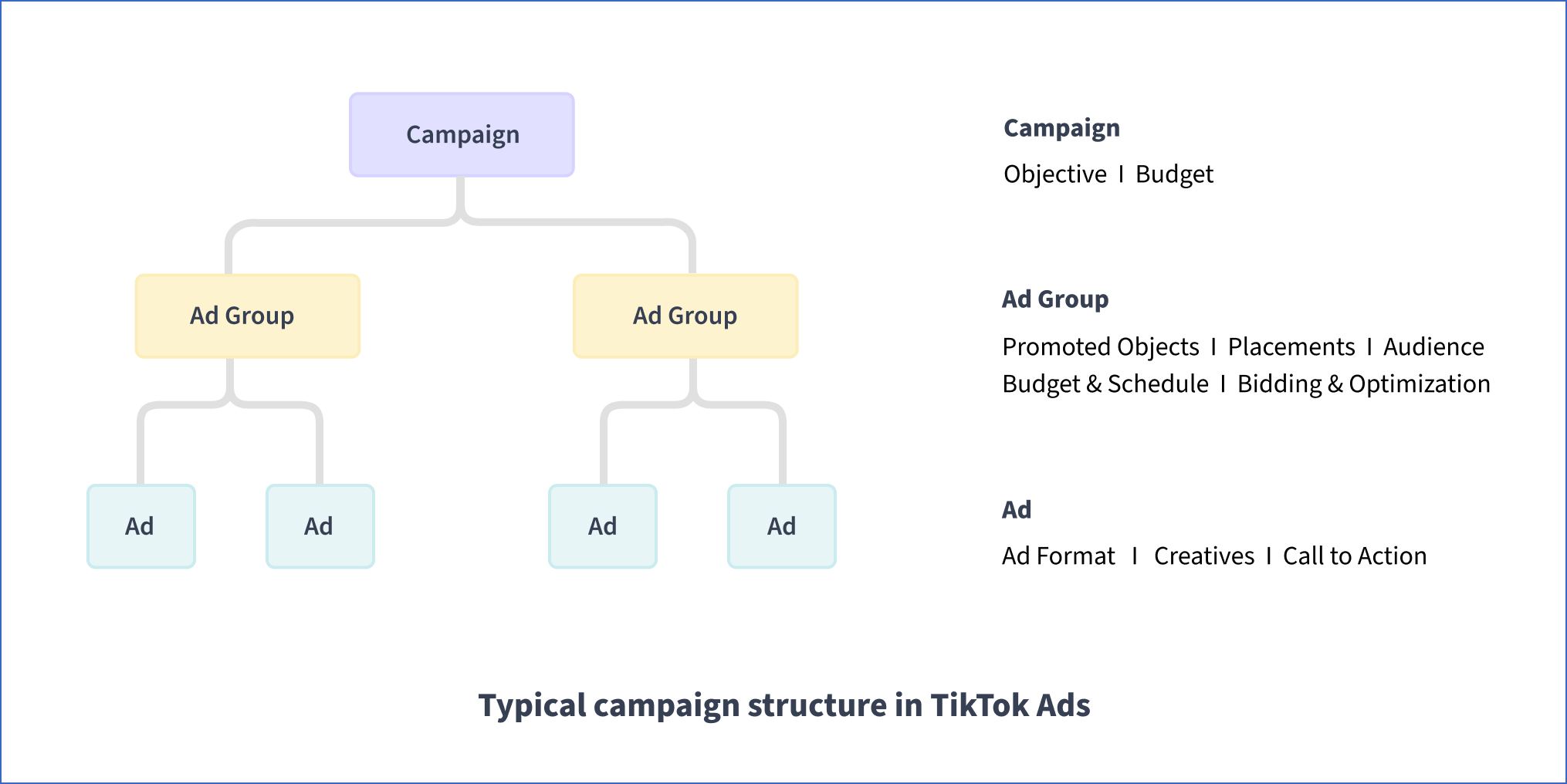
TikTok Ads allows marketers to retrieve statistics about their ad account, ads, ad sets, and campaigns running on TikTok. Each ad account can contain one or more campaigns, which are mainly used for setting an objective and configuring a corresponding budget. Within each campaign, you can create multiple ad groups to configure settings like target audience, placements, budget, and schedule, and create ads within each group. The Ad object contains the details needed for displaying an ad, such as the format of the ad, or its creative content.
The following image illustrates the typical campaign structure in TikTok Ads:
Hevo uses the TikTok Marketing API to replicate your TikTok Ads data into the desired Destination database or data warehouses for scalable analysis. For this, you must authorize Hevo to access data from your TikTok Ads account.
Note: TikTok’s authentication system uses pop-ups. Therefore, you must disable ad and pop-up blockers in your internet browser to avoid issues during the Source setup.
If you reside in a country which has blocked TikTok, for example India, you need to use a VPN to connect to your TikTok Ads account and create the Pipeline. Alternatively, set up your Hevo account in any of the following instances: US, EU, or AU. Refer to Selecting your Hevo Region for the instance URLs.
Prerequisites
-
An active TikTok Ads Manager account with permissions to access data from the ad accounts you want to sync.
-
You are connected via a VPN, if the country you are in has blocked TikTok.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Configuring TikTok Ads as a Source
Perform the following steps to configure TikTok Ads as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
In the Select Source Type page, select TikTok Ads.
-
In the Configure your TikTok Ads page, do one of the following:
-
Select a previously configured account and click CONTINUE.
-
Click + ADD TIKTOK ADS ACCOUNT and perform the following steps to configure an account:
-
Log in to your TikTok Ads account using your phone number or email ID.
-
Click Confirm to authorize Hevo to access your TikTok Ads account and related statistics.
Note: The permissions that Hevo needs to successfully ingest data are auto-selected.

-
-
-
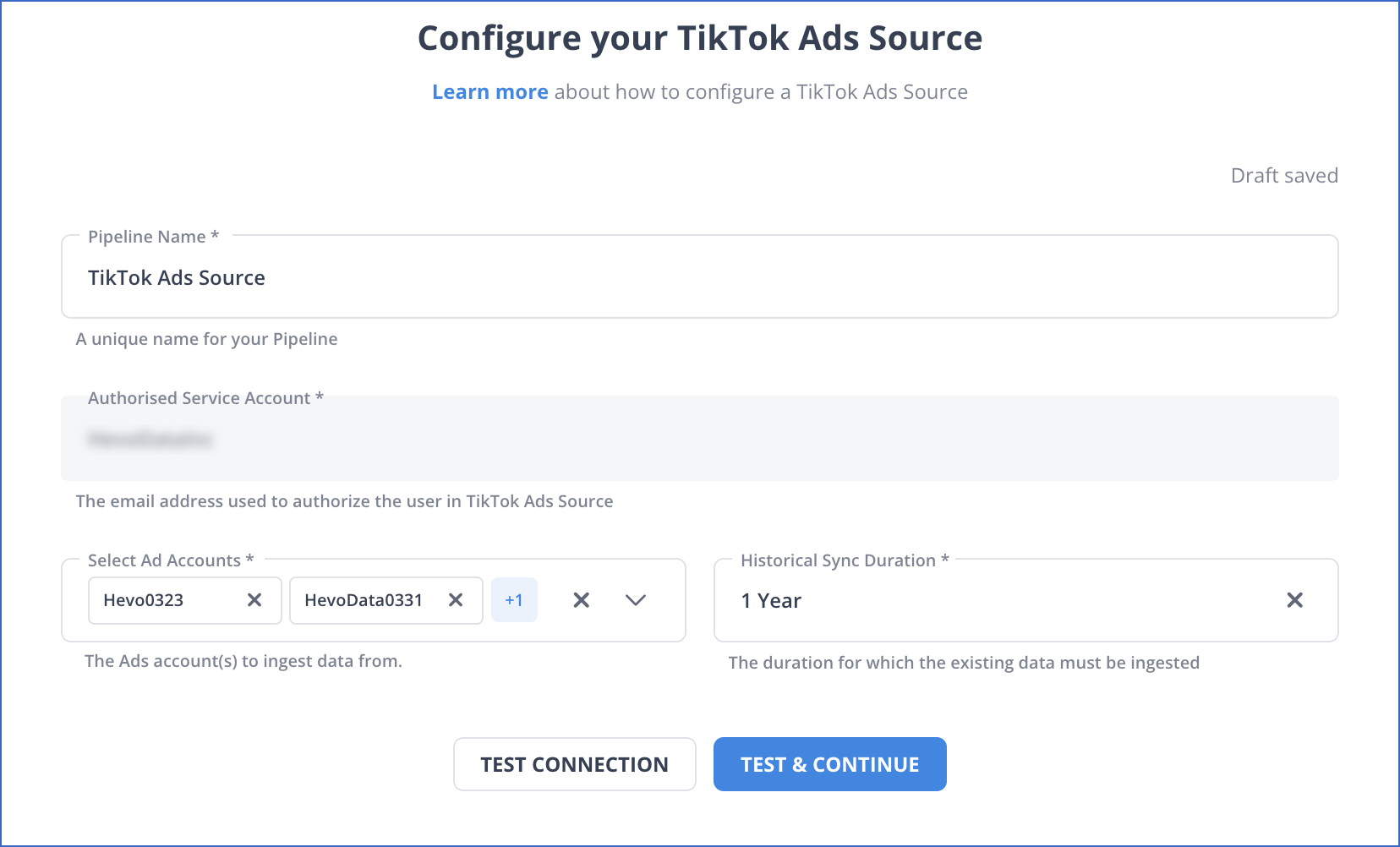
In the Configure your TikTok Ads Source page, specify the following:
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Ad Accounts: The TikTok Ad account(s) from which you want to fetch the data.
-
Historical Sync Duration: The duration for which you want to ingest the existing data from the Source. Default duration: 1 Year.
Note: If you select All Available Data, Hevo ingests all the data available in your TikTok Ads account since September 01, 2016.
-
-
Click TEST & CONTINUE.
-
Proceed to configuring the data ingestion and setting up the Destination.
Note: If you own or have access to multiple ad accounts, Hevo can access all those ad accounts and create tables with account IDs appended to the object and report type.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 3 Hrs | 1 Hr | 24 Hrs | 1-48 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: The first run of the Pipeline ingests historical data for the selected reports and objects on the basis of the historical sync duration specified at the time of creating the Pipeline and loads it to the Destination. Default duration: 1 Year.
-
Incremental Data: Once the historical data ingestion is complete, every subsequent run of the Pipeline fetches new and updated data for the reports as per the ingestion frequency. For core entities (objects), Hevo performs a Full Load to capture any data changes.
-
Refresher Data: Hevo performs a Full Load for the core entities (objects) every time your Pipeline runs, which means that the entire data in the object is refreshed/replicated on each ingestion. In case of reports, Hevo refreshes the data once every 24 hours for daily reports and once every six hours for hourly reports. Data refresh is required to capture any attribution data and updates made to the data since the last incremental load.
Handling of updates
The status of all fields that are updated in the Destination during replication is changed to STATUS_UPDATE.
Handling of deletes
All fields deleted in the Source are ingested with the status, STATUS_DELETE. When the Events are loaded to the Destination tables, the status of the respective fields is accordingly updated.
Note: For both deletes and updates, the MODIFY_TIME field is updated to the time of the most recent change.
Schema and Primary Keys
The schema details for uploading records into the Destination database differ based on the TikTok Ads API version that you are using.
In v1.2 of the TikTok Ads API, Hevo uses the following schema:
In v1.3 of the TikTok Ads API, Hevo uses the following schema:
In API v1.3, some of the field names and data types within objects and reports are changed. The following section highlights the changes:
Difference between API v1.2 and v1.3 object and report definition
Reports
TikTok Ads has changed the fields with Long data types to String for all supported reports. For example, in the Ad_Age_Gender_Report, the data type of the ad_id field is changed from Long in v1.2 to String in v1.3.
Objects
| Object | Old Field Name and Data Type | New Field Name and Data Type |
|---|---|---|
| Ad | - status (String) - optStatus (String) - openUrl (String) - profileImage (String) - isCreativeAuthorized (Boolean) |
- secondaryStatus (String) - operationStatus (String) - deeplink (String) - profileImageUrl (String) - creativeAuthorized (Boolean) |
| Ad Group | - externalAction (String) - deepExternalAction (String) - androidOsv (String) - iosOsv (String) - optimizeGoal (String) - status (String) - optStatus (String) - videoDownload (String) - bid (Double) - conversionBid (Double) - enableInventoryFilter (Boolean) - category (Integer) - isCommentDisable (Integer) - audience (List) - excludedAudience (List) - location (List) - interestCategoryV2 (List) - pangleBlockAppListId (List) - actionV2 (List) - placement (List) - age (List) - operationSystem (List) - connectionType (List) - carriers (List) |
- optimizationEvent (String) - secondaryOptimizationEvent (String) - minAndroidVersion (String) - minIosVersion (String) - optimizationGoal (String) - secondaryStatus (String) - operationStatus (String) - videoDownloadDisabled (Boolean) - bidPrice (Double) - conversionBidPrice (Double) - inventoryFilterEnabled (Boolean) - categoryId (String) - commentDisabled (Boolean) - audienceIds (List) - excludedAudienceIds (List) - location_ids (List) - interestCategoryIds (List) - blockedPangleAppIds (List) - actions (List) - placements (List) - ageGroups (List) - operatingSystems (List) - networkTypes (List) - carrierIds (List) |
| Advertisers | - phoneNumber (String) - reason (String) - telephone (String) |
- cellphoneNumber (String) - rejectionReason (String) - telephoneNumber (String) |
| Campaign | - campaignId (Long) - updatedAt (String) - advertiserId (Long) - campaignName (String) - campaignType (String) - budget (Double) - budgetMode (String) - optStatus (String) - objectiveType (String) - isNewStructure (String) - splitTestVariable (String) - status (String) - createTime (String) |
- campaignId (String) - updatedAt (String) - advertiserId (String) - campaignName (String) - campaignType (String) - budget (Double) - budgetMode (String) - operationStatus (String) - objectiveType (String) - isNewStructure (Double) - splitTestVariable (String) - secondary_status (String) - createTime (String) |
Data Model
You can replicate object and report data from your TikTok Ads account.
Objects
Objects are the core entities of TikTok Ads. The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
| Object | Description |
| Advertisers | Contains information about the advertiser account. |
| Campaign | Contains information about campaigns. |
| Ad Group | Contains information about ad groups existing in the campaigns. |
| Ad | Contains information about ads running as part of each ad group. |
Reports
Reports are objects that contain data related to the metrics and statistics of the core entities. These can be generated at two levels of time granularity: Daily and Hourly. Reports are generated for the following objects:
-
Ads
-
Ad Groups
-
Campaigns
You can also generate reports based on the parameters, Country, Language, Age Gender, and Platform, as described in the table below.
| REPORT NAME | DESCRIPTION |
|---|---|
| Ad_Age_Gender_Report | The report on the Ad object, grouped by Age Gender. |
| Ad_Country_Report | The report on the Ad object, grouped by Country. |
| Ad_Daily_Report | The report on the Ad object, grouped daily. |
| Ad_Hourly_Report | The report on the Ad object, grouped hourly. |
| Ad_Language_Report | The report on the Ad object, grouped by Language. |
| Ad_Platform_Report. | The report on the Ad object, grouped by Platform. |
| Ad_Reservation_Daily_Report | The report on the Ad object, grouped daily. Captures reserved ads information. |
| Ad_Reservation_Hourly_Report | The report on the Ad object, grouped hourly. Captures reserved ads information. |
| AdGroup_Daily_Report | The report on the Ad Group object, grouped daily. |
| AdGroup_Hourly_Report | The report on the Ad Group object, grouped hourly. |
| AdGroup_Reservation_Daily_Report | The report on the Ad Group object, grouped daily. Captures reserved ad groups information. |
| AdGroup_Reservation_Hourly_Report | The report on the Ad Group object, grouped hourly Captures reserved ad groups information. |
| Campaign_Age_Gender_Report | The report on the Campaign object, grouped by Age Gender. |
| Campaign_Country_Report | The report on the Campaign object, grouped by Country. |
| Campaign_Daily_Report | The report on the Campaign object, grouped daily. |
| Campaign_Hourly_Report | The report on the Campaign object, grouped hourly. |
| Campaign_Language_Report | The report on the Campaign object, grouped by Language. |
| Campaign_Platform_Report | The report on the Campaign object, grouped by Platform. |
| Campaign_Reservation_Daily_Report | The report on the Campaign object, grouped daily.Captures reserved ads information. |
| Campaign_Reservation_Hourly_Report | The report on the Campaign object, grouped hourly. Captures reserved ads information. |
Refer to the Schema and Primary Keys section for more details.
Note: Reservation Ads reporting is currently in Beta. Read Reservation ads reports for more information.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
Country-specific availability: TikTok has been removed by Internet Service Providers (ISPs) in a few countries. If your Hevo account is in any of these countries, you will not be able to create Pipelines. Use a VPN to side-step this issue. Alternatively, set up your Hevo account in any of the following instances: US, EU, or AU. Refer to Selecting your Hevo Region for the instance URLs.
-
Maturity of the API : The TikTok Marketing API is still under active development and has not reached a stable state. As a result, attribution functionalities and API rate limits are prohibitive and Hevo adheres to these while running your Pipelines.
-
Attributions: For TikTok App Marketers, it is recommended to use a Mobile Measurement Partner (MMP) to track conversions from your TikTok app campaigns till other solutions, such as server-to-server and SDK, mature and can handle different attribution windows. For now, Hevo only supports a click attribution window of 7 days and a view attribution window of 1 day.
-
Data latency in reports: The reports generated from your TikTok Ads account may experience data latency, which varies depending on the data type and the specific fields. The latency occurs due to the different refreshing mechanisms for the two data types, Real-time and Offline Data. Real-time Data is refreshed frequently but may be adjusted the following day to include the Offline Data. Offline Data is refreshed less frequently but has finalized and accurate values upon release. This may result in delays and variations in data freshness. Read Data latency for reports.
Limitations
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
-
By default, Hevo schedules data ingestion based on Coordinated Universal Time (UTC), regardless of your Source account’s time zone. This can cause delays if the account operates in a different time zone. To address this, Hevo allows you to align the data ingestion with your preferred time zone; contact Hevo Support.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Mar-21-2025 | 2.34.1 | Updated the Limitations section to add information on ingestion delay due to time zone. |
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Aug-12-2024 | NA | Updated section, Source Considerations to add information about data latency in reports. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Aug-07-2023 | 2.15 | Updated section, Schema and Primary Keys to mention about the schema differences between TikTok Ads API v1.2 and v1.3. |
| Apr-04-2023 | NA | Updated section, Configuring TikTok Ads as a Source to update the information about historical sync duration. |
| Dec-07-2022 | NA | Updated section, Data Replication to reorganize the content for better understanding and coherence. |
| May-24-2022 | 1.89 | New document. |