HubSpot
On This Page
HubSpot is a system for managing customer relationships and storing data. You can use Hevo Pipelines to replicate data from your HubSpot account to the Destination database or data warehouse using HubSpot REST API.
You can use Open Authorization (OAuth) to authenticate your HubSpot account with Hevo.
Prerequisites
-
An active HubSpot account from which data is to be ingested exists.
-
The following permissions in HubSpot to configure a HubSpot account in Hevo:
-
Administrator: To replicate CRM and Marketing objects. -
Super Admin: To replicate Email Events. -
Sales Administrator: To replicate Sales objects.
Read more about HubSpot user permissions at HubSpot Knowledge Base.
-
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Configuring HubSpot as a Source
Perform the following steps to configure HubSpot as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
In the Select Source Type page, select HubSpot.
-
In the Configure your HubSpot Account page, do one of the following:
-
Select a previously configured account and click CONTINUE.
-
Click + ADD HUBSPOT ACCOUNT and perform the following steps to configure an account:

-
Log in to your HubSpot account.
-
In the HubSpot Accounts page, select the HubSpot account whose data you would like to synchronize.

-
Authorize Hevo Data Inc to access your HubSpot data.

-
-
-
In the Configure your HubSpot Source page, specify the following:
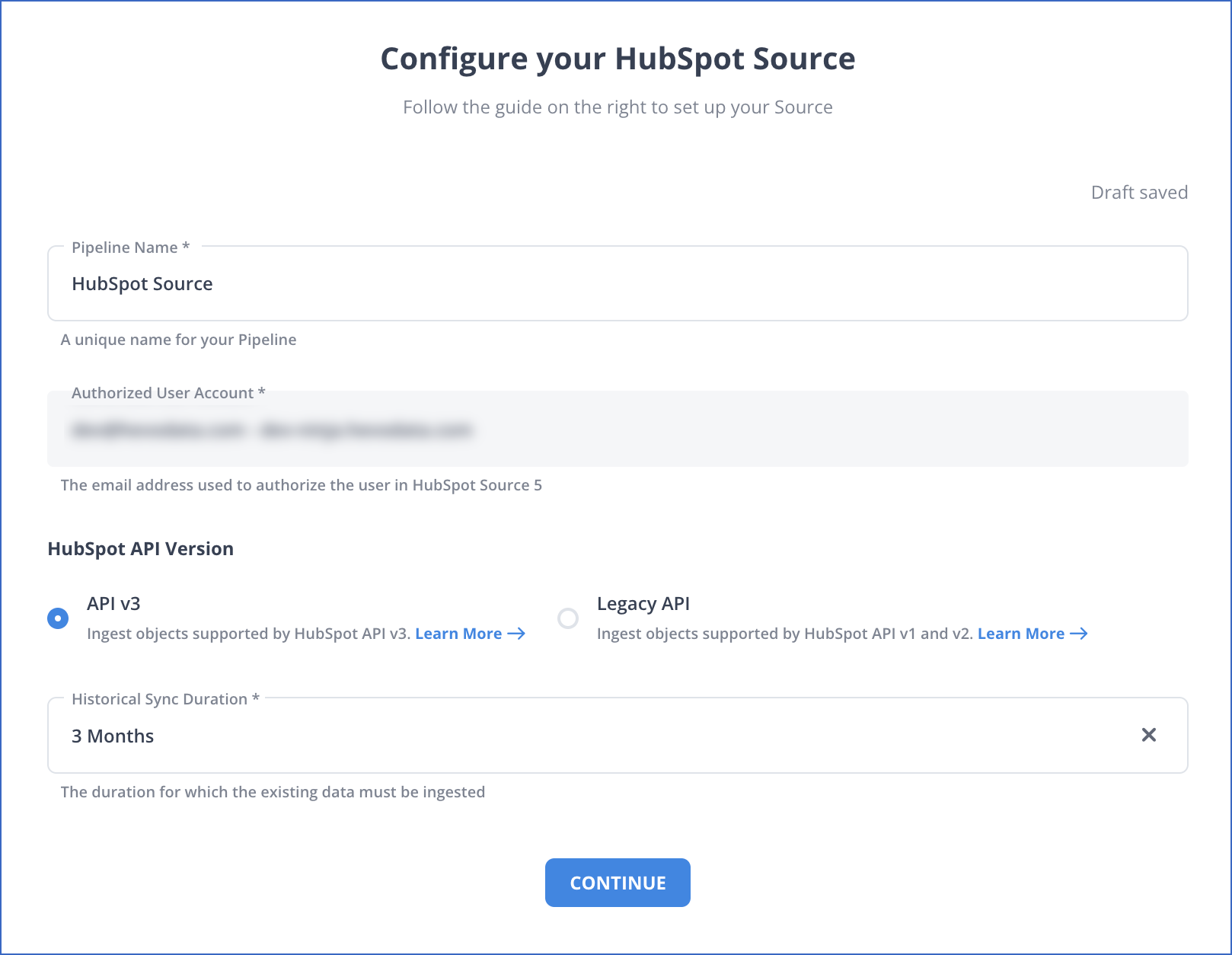
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Authorized Account (Non-editable): This field is pre-filled with the email address that you selected earlier when connecting to your HubSpot account.
-
HubSpot API Version: The API version that you want to use to ingest data from the Source. Default value: API v3.
-
Historical Sync Duration: The duration for which you want to ingest the existing data from the Source. Default duration: 3 Months.
Note: If you select All Available Data, Hevo ingests all the data available in your HubSpot account since January 01, 1970.
-
-
Click CONTINUE.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 1 Hr | 30 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: The first run of the Pipeline ingests historical data for the selected objects on the basis of the historical sync duration specified at the time of creating the Pipeline and loads it to the Destination. Default duration: 3 Months
-
Incremental Data: Once the historical load is complete, new and updated records for all objects except Owners and Email Campaigns are ingested as per the ingestion frequency.
Archived Objects
Hevo synchronizes the archived records for all the standard objects in Hubspot. For any archived record fetched from your Hubspot data, the archived flag is set to true.
The ingestion of archived Events is not coupled with the scheduled Pipeline runs due to the Source consideration around the handling of deletes. To reduce the number of Events being ingested during each Pipeline run, the ingestion frequency for deleted Events is set to 24 Hours. You can change this by reaching out to Hevo Support.
Merged Records
When two or more records within a standard or custom object are merged in HubSpot, only the resulting primary record is retained. This record consolidates the data of all secondary merged records. Subsequently, the secondary merged records are removed from HubSpot.
If the merge occurs before Hevo ingests the records, only the primary record is ingested into the Destination. However, if the merge occurs after ingestion, Hevo retains the secondary records in the Destination and flags them using the following fields:
| Fields | Data type | Description |
|---|---|---|
__hevo_merged |
boolean | Contains the merged status of a record. It is set to TRUE only if the record is merged with another. |
__hevo_merged_into |
long | Contains the ID of the record into which it has been merged. |
Using these fields, you can identify the stale data, if any, in the Destination.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination:
Note: Effective Release 2.16, in Pipelines created with JDBC-based Destinations, Hevo creates the Destination schema based on the data retrieved from HubSpot. As a result, only fields that contain data are created in Destination tables, and the column limit is not exceeded.
Data Model
Hevo supports two API versions for ingesting data from HubSpot, v3 API and legacy API (v1 and v2). Depending on the API version you select, Hevo creates the following tables (objects) in the Destination when you run the Pipeline:
Note:
-
Owners and Email Campaigns are Full Load objects, and the entire data is fetched in each run of the Pipeline. This may lead to higher Events quota consumption.
-
For Pipelines created from Release 1.98 onwards: Hevo supports the data ingestion of custom objects and their associations. However, to ingest the data for associations, you need to contact Hevo Support.
-
Effective Aug 31, 2023, HubSpot has stopped supporting the Calendar Events object. As a result, Hevo has stopped replicating data for the same.
HubSpot Legacy API
Note: If you select the Legacy API option while configuring your Source, Hevo ingests all the objects supported by legacy and v3 API. However, in subsequent updates, Hevo replicates data only for the legacy objects under the Legacy API option.
| Object | Description |
|---|---|
| Calendar Events | Contains details of the events, such as meetings and appointments, in your HubSpot account. |
| Email Events | Contains details of user engagement with marketing emails sent from your HubSpot account. |
| Form Submissions | Contains details of form interactions, including contact ID, form ID, and the exact submission time. |
HubSpot v3 API
As part of the latest API version in HubSpot, Hevo ingests the following tables (objects) in the Destination using HubSpot v3 API.
| Object | Description |
|---|---|
| Contacts | Contains details of individuals that your organization interacts with. |
| Contact Deal Association | Contains details of the contacts associated with a deal within your HubSpot account. |
| Companies | Contains details about of the business your organization interacts with. |
| Custom Objects | Contains details of custom objects created in the HubSpot account for specific business requirements. |
| Deals | Contains details of an ongoing transaction associated with a contact or company. |
| Deal Company Association | Contains details of the deals associated with a company in your HubSpot account. |
| Deal Stage Pipeline | Contains details of the current status of deals in a HubSpot pipeline. |
| Deal Line Item Association | Contains details of the line items associated with a deal in your HubSpot account. |
| Email Campaigns | Contains details of the marketing emails sent to contacts to enhance engagement. |
| Engagements | Contain details of the interactions between your team and contacts via various modes of communication, such as emails, meetings, calls, and tasks. |
| Engagement Call | Contains details of all the calls made to the contacts in your HubSpot account. |
| Engagement Communications | Contains details of the interactions between a user and a contact via third-party channels, such as WhatsApp and LinkedIn. |
| Engagement Company Association | Contains details of the engagements associated with businesses within your HubSpot account. |
| Engagement Contact Association | Contains details of the engagements associated with contacts within your HubSpot account. |
| Engagement Deal Association | Contains details of engagements associated with dealswithin your HubSpot account. |
| Engagement Email | Contains details of all the email interactions between a user and a contact in your HubSpot account. |
| Engagement Meeting | Contains details of all the meetings that have been scheduled and managed in your HubSpot account. It includes meeting dates, participants, locations, agendas, and any additional relevant data related to the meetings. |
| Engagement Note | Contains details of the information captured for the interaction or communication with a contact. |
| Engagement Task | Contains details of the tasks assigned to a user in your Hubspot account. These tasks may include calls, emails, descriptions and relevant details. |
| Engagement Postal Mail | Contains details of the mail communications that a user has created and sent through HubSpot. It allows users to manage offline communications with contacts and track their interactions. |
| Line Items | Contains details of products or services that are associated with a deal. |
| Owners | Contains the list of HubSpot users with the owner role. |
| Products | Contains details of goods or services that your company sells. |
| Tickets | Contains details of the inquiries, support requests, or issues raised by the customers. |
| Ticket Stage Pipeline | Contains details of the current status of a ticket. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
HubSpot stores archived records and restorable deleted records in its recycle bin. These records remain in the recycle bin for up to 90 days, during which they can be restored and accessed through HubSpot APIs. After this period, the records are permanently deleted and can no longer be accessed. As a result, Hevo cannot retrieve these records.
-
HubSpot does not allow fetching deleted records based on a timestamp. While this can lead to a higher number of ingested Events, Hevo deduplicates such Events upon ingestion. Only the Events that were deleted after the last run of the Pipeline (based on the
archived_attimestamp) count as new Events and are treated as billable. -
In HubSpot, association objects can be created to track relationships within and between objects. Whenever records in an object are updated, HubSpot automatically syncs the data for the corresponding associated records of that object. Hence, when Hevo ingests data from an object, data from its association objects, if any, is also ingested, which can lead to a higher number of ingested Events in every Pipeline run.
For example, suppose some records in the
Contactsobject are associated with records from theCompanyobject. To track this relationship, HubSpot creates theContact Company Associationobject. Now, when you configure a Hevo Pipeline to ingest data from theContactsobject, data from theContact Company Associationobject is also ingested, leading to a higher number of Events being consumed.
Limitations
-
HubSpot CRM API returns the updates for up to 10,000 records for the same modified timestamp. If other records are updated at that particular point of time, they are not reflected or synchronized with the Destination.
-
Hevo does not support replication of the
Company Contactobject for all Pipelines created after March 31, 2023. -
Hevo does not load an Event into the Destination table if its size exceeds 128 MB, which may lead to discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each row in your Source objects contains less than 100 MB of data.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| May-08-2025 | NA | - Remamed section, Merged Objects to Merged Records. - Updated section, Merged Records with latest information on merged records. |
| Apr-14-2025 | NA | Added a Source Consideration about association objects. |
| Apr-11-2025 | NA | Updated section, Source Considerations to add information about the retention period of HubSpot’s recycle bin. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Dec-29-2023 | NA | Updated the page to reflect the latest Hevo functionality. |
| Sep-04-2023 | NA | Updated the note in the Schema and Primary Keys section to state that the Destination schema for Pipelines with JDBC Destinations is derived from the Source data. |
| Jul-25-2023 | 2.15 | Updated sections: - Configuring HubSpot as a Source to add information about HubSpot API version option. - Data Model with the latest list of objects and their respective descriptions. |
| Jul-20-2023 | NA | Updated section, Data Model to add information about HubSpot deprecating an object. |
| Apr-25-2023 | 2.12 | Updated section, Data Model to add a note regarding the ingestion of custom object associations. |
| Apr-04-2023 | NA | Updated section, Configuring HubSpot as a Source to update the information about historical sync duration. |
| Jan-10-2023 | 2.05 | Updated section, Data Model to include information about the new object supported by Hevo. |
| Nov-07-2022 | NA | Updated section, Data Model for more clarity and detail. |
| Sep-21-2022 | 1.98 | Updated sections, Data Model and Source Considerations to include information about custom objects. |
| Sep-05-2022 | NA | - Updated section, Data Replication to restructure the content for better understanding and coherence. - Updated section, Configuring HubSpot as a Source to reflect the latest UI changes. |
| Apr-25-2022 | 1.87 | Updated section, Limitations about Hevo using the CRM API v3 to fetch HubSpot data. |
| Nov-22-2021 | 1.76 | In the Data Model section: - Added the Owner object. - Changed the description for the Email Campaigns object. - Added a note to indicate that Email Campaign and Owner are Full Load objects. |
| Oct-25-2021 | 1.74 | - Updated the page overview. - Added the section, Source Considerations. - Added information about handling of deleted records and the available Pipeline frequencies in the Data Replication section. |
| Aug-09-2021 | 1.69 | Added a note in the Data Replication section about archived objects ingested from the Source. |
| Jul-12-2021 | 1.67 | Updated the Data Model section with additional objects that Hevo now supports. |