Structure of Data in the PostgreSQL Database
On This Page
PostgreSQL is an object-relational database management system (ORDBMS) that provides a robust platform for storing and analyzing large amounts of data. It uses SQL as the main query language and adheres to the relational database principles.
You can create Destinations in Hevo with PostgreSQL versions 9.6 and higher.
PostgreSQL supports structured, semi-structured, and unstructured data such as JSON, XML, and key-value pairs. This allows you to store and analyze diverse data formats within a single database system. You can also define your own data types using its CREATE TYPE command to store and process complex and specialized data. Hevo supports the following datatypes for loading data to PostgreSQL:
| Data Types supported by Hevo |
|---|
| BIGINT/ BIGSERIAL |
| BIT |
| BOOLEAN |
| BYTEA |
| CHARACTER VARYING |
| CHARACTER |
| DATE |
| DOUBLE PRECISION |
| GEOMETRY |
| INTEGER/ SERIAL |
| INTERVAL |
| JSON |
| JSONB |
| MONEY |
| NUMERIC/ DECIMAL |
| REAL |
| SMALLINT/ SMALLSERIAL |
| TEXT |
| TIME WITH TIME ZONE |
| TIME WITHOUT TIME ZONE |
| TIMESTAMP WITH TIME ZONE |
| TIMESTAMP WITHOUT TIME ZONE |
| TSRANGE |
| TSTZRANGE |
| UUID |
| BIT VARYING |
| BOX |
| CIRCLE |
| DATERANGE |
| ENUM |
| XML |
| INET |
PostgreSQL Architecture
PostgreSQL is based on the client-server architecture model. In this model, the client refers to the graphical or character-based interface that you can use to interact with the database for storing and retrieving data. The server, also called postgres, refers to the main process that manages the database and allows it to access the client programs.
This diagram illustrates the key components of the PostgreSQL architecture:

-
Postmaster: This is the main process that manages the connections on the database server. These connections may be multiple and concurrent. It is a listener process that accepts connections from the client applications. It is responsible for starting and stopping the database server and managing the processes used to write to the database.
-
Shared Memory: This is a temporary memory cache shared by the processes connected to the database. PostgreSQL uses this memory to store tables, records, and Write Ahead Logs (WAL) changes. It consists of two parts:
-
Shared buffer: The main constituent of the shared memory, used to store the frequently accessed data.
-
WAL buffer: A smaller part of the shared memory, used to store any changes made to the database.
-
-
Backend Process: This process communicates with the postmaster process and executes the query received from the client app. Upon query execution, it copies the data to the shared memory for writing to the database. PostgreSQL creates the backend process when the Hevo Pipeline connects to the database, and terminates it at the end of the session.
-
Background Processes: PostgreSQL uses these processes to perform background tasks such as:
-
Checkpointing: This process creates a checkpoint to ensure the reliability of the database. This checkpoint is a time at which the data in the database is accurate and up-to-date (consistent).
-
WAL writing: The Write Ahead Log, or WAL, contains a log of any changes made to the records in the database. The WAL writing process is used to write the WAL to the disk. The data from the disk is then copied into the secondary storage using the archiver. This removes the WAL files from the main servers and frees up space for other records.
-
Vacuuming: This process removes old records, for example, deleted rows and columns, from the database to ensure efficient data storage. The vacuuming process enhances the performance of PostgreSQL by freeing up space in the database.
-
Background Writing: Background processes, unlike backend processes, perform tasks that are not directly related to the user or client application. They are used to write data that has not been written yet to the disk. This frees up the processes for handling other user requests.
-
When a cluster is created, a database named postgres is created by default. You can use this database instance to set up the Destination or create a new database. The database stores tables that contain the data loaded by the Pipeline.
PostgreSQL Database Structure
The PostgreSQL database is created on the postgres server or host. The hostname is the domain name assigned to the host computer, for example, localhost, for referring to a local computer. You can create multiple databases and multiple schemas within each database. The schema defines the structure and type of your data. Each schema can include multiple tables, indexes, views, functions, and so on. The following diagram illustrates the structure of databases in PostgreSQL:

For each database, also called the primary or master database, you can create multiple read replicas. A read replica is a copy of the primary database that shows the changes to the data in near-real-time and provides only Read access to it. A replica database allows PostgreSQL to divert the read requests and analytics traffic from the primary database, thereby improving the latter’s efficiency. While the data is read from the replica database, the writes are always made to the primary database. This means that Hevo loads the data to the primary database or a specific schema within it. The loaded data is subsequently copied asynchronously to the read replicas.
Within a PostgreSQL database, you can create multiple schemas having the same table structure. For example, suppose you have a billing management system that handles the billing for 10 clients, and all of them maintain the same type of data, such as bill number, date, bill amount, payment status, business unit ID, client ID, and so on. Then, you can create 10 schemas with a similar table structure, and load data to these using 10 different Pipelines, one for each client.
Data layout and structure
PostgreSQL stores the tables present in a database in an array of pages having a default size of 8kB each. You can select a different size while compiling your server.
Each page has the following layout:

-
Page Header: The page header contains metadata to determine details, such as the updates on the page, WAL entries related to the page, and offsets for the free and special space.
-
Item ID: The item ID contains the reference, or pointer, that is used to locate the item (record) on the page.
-
Items: The items are the table records that are stored on the page. These are referenced using the item ID.
-
Free Space: The free space is the available space on each page for adding more records.
-
Special Space: The special space is the reserved area of the page where PostgreSQL stores the information that cannot be accommodated in the page header.
PostgreSQL contains the header at the start of the page, followed by the item IDs, which are allocated from the start of the free space. The end of the page contains the database records (items) and lastly, the special space. Items are added in reverse order from the end of the free space. For example, in the above diagram, Item ID 1 and Item 1 are added first, with Item ID 1 pointing to Item 1. Subsequently, Item ID 2 and Item 2 are added, and so on.
The page layout is internally used by PostgreSQL to efficiently read and write data and is not visible to you.
Data Storage and Retrieval
PostgreSQL provides different types of tables that your Hevo Pipeline leverages to write data to your Destination. It efficiently queries this data with the help of space and visibility maps that identify space for data storage and help it easily locate the required data.
Table types
PostgreSQL supports three types of tables:
-
Temporary: Tables that are similar to Views. Hevo uses these tables to identify the changed data and perform deduplication of records to be loaded.
-
Regular: Tables created by users within a schema. Hevo uses these tables to add or update the data ingested from the Source.
-
Foreign: Tables referenced from another database.
Free space maps
A Free Space Map (FSM) tracks the available space in each table. These maps are stored along with the tables and are named tablename.fsm. For example, if the table is customer, the FSM is stored in the file customer.fsm.
Visibility maps
Each table is stored as a file in PostgreSQL. If your table contains more than 1 GB of data, the rows are divided into multiple files (or segments), and each additional file name is suffixed with a file number. For example, consider a table, customer, which contains 3.5 GB of data. The data from these tables is divided into four files, namely, customer, customer.1, customer.2, and customer.3. These divisions are used by PostgreSQL for internal implementation only and are not visible to you. Within each file, the data is stored in an array of pages having a default size of 8kB each.
When you run a query, PostgreSQL uses the concept of Visibility Maps (VM) to query these files. A VM uses two flags for each page in the file. One flag is used to indicate that the page has only active transactions or unprocessed rows. An active transaction is one that has not yet been committed or rolled back. The other flag is used to indicate that the page contains already processed rows or frozen transactions. The flags are set for a page only if they are valid for ALL row versions stored on that page.
The VMs are stored along with the files and are named <filename>_vm. For example, if the table name is customer, the VM file name is customer_vm.
Visual maps reduce the amount of time required to query the data in your Destination by helping PostgreSQL identify the pages that contain rows to be processed and the pages that can be skipped by the query.
Traditional and materialized views
A View represents the data fetched as a result of any query that is run on your PostgreSQL data. Based on your data needs, you can choose between the following two views:
-
Traditional (Standard): This provides a logical view of the data and is created when you run a query, for example,
SELECT * from sales_data. While you can store the query, the view is temporary and cannot be stored. For queries that are fast to execute and or when you can accept slow performance, you can use the traditional view. It always brings you the most up-to-date results. This is also the better choice when you require fresh data. -
Materialized: A view in which, along with the query, the data is also physically stored on the disk and can be reused later like any other table. The materialized view is helpful for generating repetitive reports across tables. It helps you provide quick data access to your BI applications, especially in case of queries that are too heavy to run. However, if the base table data is changed, you need to re-run the query to update the view; it is not updated automatically.
You can create a materialized view in your database from the database console or the Hevo UI using the following query:
CREATE MATERIALIZED VIEW <view_name> AS <query>;Note: Replace the placeholder values in the command above with your own. For example, <query> with:
SELECT product_id, quantity, value FROM orders GROUP BY product_id.
Viewing Data in a PostgreSQL Table
To view the data present in a table, you can execute SQL queries in the Destination workbench in Hevo or in third-party applications such as Data Grip. For example, let us say that you create the table, city in your PostgreSQL database and load data into it using Hevo Pipelines. PostgreSQL stores this data in a page layout. When you execute an SQL query to retrieve, say, the first 10 rows of the table, then the data is displayed in the Query Results section as shown below:
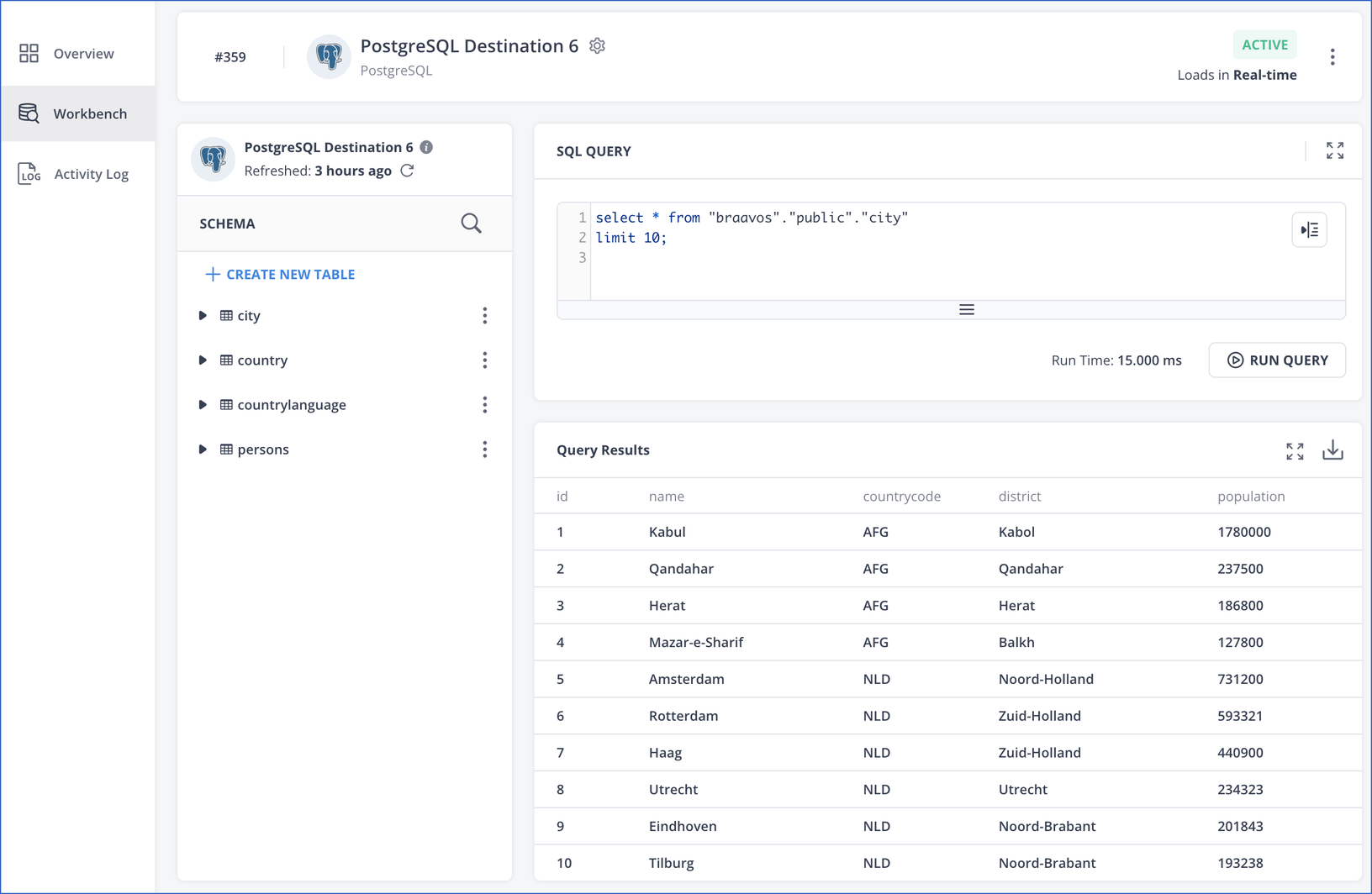
Read Querying a Table to know more about retrieving data from a database or table.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jan-10-2024 | NA | New document. |