Marketo
On This Page
Marketo is a marketing automation platform used by B2B and B2C companies to manage and deliver personalized multi-channel programs and campaigns to prospects and customers. Marketo enables companies to curate their raw user data and create programs and focussed campaigns for different marketing activities, from lead generation to marketing ROI measurement, across multiple channels.
With the help of Pipelines in Hevo, you can synchronize Marketo with a database or data warehouse Destination to always have access to the latest data, which you can feed into your enterprise BI solution for custom reporting and analysis. Hevo Pipelines use Marketo’s bulk (preferred) and REST APIs to fetch both historical and changed data, which you can replicate to the Destination after performing any necessary transformations on it.
Prerequisites
- You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Configuring Marketo as a Source
To configure Marketo as a Source:
-
Obtain authenticated access credentials for your Marketo instance.
Note: While creating a new role, you must either individually select all
Read-Onlyprivileges or provide all Access-API privileges. -
Click PIPELINES in the Navigation Bar.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
On the Select Source Type page, select Marketo.
-
On the Configure your Marketo Source page, specify the following:
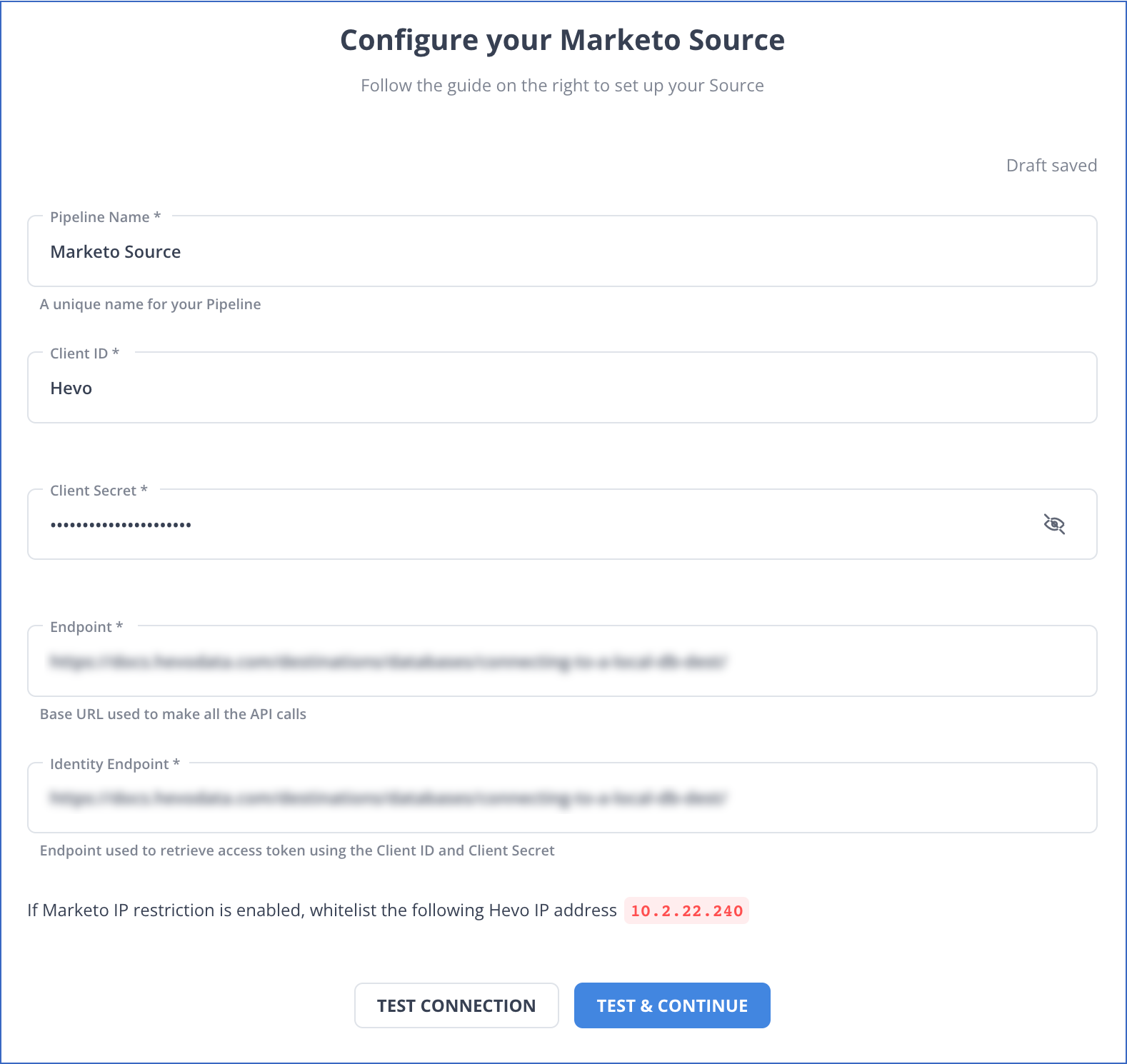
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Client ID - Available at the newly created service.
-
Client Secret - Available at the newly created service.
-
Endpoint - The base URL used to make all the API calls.
Example: https://469-HOO-201.mktorest.com/rest
-
Identity Endpoint - The endpoint used to retrieve access tokens using the Client ID and Client Secret.
Example: https://469-HOO-201.mktorest.com/identity
-
-
Click TEST & CONTINUE.
-
Proceed to configuring the data ingestion and setting up the Destination.
Note: If IP restriction is enabled in your Marketo account, you must either whitelist Hevo IPs or disable IP restriction to allow Hevo to make API calls.
Marketo API Limits
Marketo imposes strict limits on the API calls you can make within a given time frame to retrieve the data. Some of these include:
-
Rate Limit: Marketo imposes a limit of 100 API calls per 20 seconds per instance. If the limit is exceeded, Hevo defers the ingestion till the limits reset.
-
Concurrency Limit: Maximum of 10 concurrent API calls.
-
Daily Quota: Up to 50,000 API calls per day with a max export of 500 MB for bulk jobs for paid subscription (quota resets daily at midnight CST).
Read more about Marketo API limits.
Hevo Pipelines overcome these limitations by using Bulk APIs to fetch the data.
Data Ingestion using Bulk APIs
The Hevo connector uses Bulk APIs by default for all Marketo objects that allow this, namely, Program members, Activities and Leads. As a result, Hevo can minimize the number of API calls, while maximising the number of Events fetched per API call, and thereby, help you to remain within the imposed limits to the extent possible. This becomes specially useful while retrieving historical data.
Bulk APIs in Marketo uses the same permissions as the REST APIs, therefore, the job or API type that is running is transparent to you except for the API endpoint.
Compared to a REST API, for a bulk extract:
-
The Hevo connector submits the job for the data you need, with the required metadata, to Marketo.
-
Marketo queues and runs the job.
-
Hevo queries for the status intermittently and when the job completes, Hevo makes one single call to fetch the data, extract the input stream, and process the records in order.
See Appendix 1 - Destination Tables for the list of Marketo objects that allow bulk operations.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 3 Hrs | 3 Hrs | 48 Hrs | 3-48 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: - In the first run of the Pipeline, Hevo ingests all the existing data for the selected objects from your Marketo account using the Recent Data First approach and loads it to the Destination.
-
Incremental Data: Once the historical load is complete, all new and updated records for all objects except Activity New Lead, List, Program Membership, and Program are ingested as per the ingestion frequency.
-
Data Refresh: The data for the past three months is ingested on every run to ensure that your data is up to date and any data freshness issues are overcome.
Refer to the table below for the type of data that is fetched for each object.
| Data Type | Object Names | Schedule | Additional Information |
|---|---|---|---|
| Historical | Activities | During the first run of the Pipeline | |
| Incremental | Activities, Activity Types, Campaigns, Leads, Programs | During each run of the Pipeline | For the Campaigns object, data for the past 12 months is fetched on the first run. |
| Refresh Data | Leads | Every 24 hours post-completion of ingestion | Ensures that leads, opportunity, opportunity roles, and salespersons data is up to date. |
Note: The time taken for the historical data load is determined by the amount of data and processing time for the ingestion from Marketo.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination database:
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
| Object | Mode | Description |
|---|---|---|
| Activities | Incremental | Contains details of all the events or happenings regarding leads in your Marketo account. For example, opening an email and clicking a link, submitting a form, and visiting a web page. |
| Activity New Lead | Full Load | Contains details about a new lead added to the Marketo database. |
| Campaign | Incremental | Contains details of the events executed to increase engagement and streamline communications with leads and existing customers. |
| Leads | Incremental | Contains details of prospective customers. |
| List | Full Load | Contains details of the leads present in a database in the Marketo account. |
| List Membership | Incremental | Contains details of the lists that a lead is a member of. |
| Opportunity Role | Incremental | Contains details of the relationship between an opportunity and a lead and the function of this lead in the organization. |
| Opportunity | Incremental | Contains details of a potential sales deal or a lead that is identified as a potential customer. |
| Program Membership | Full Load | Contains details of the membership of a person in different programs. |
| Program | Full Load | Contains details of the marketing activities organized and executed in an organization. For example, campaigns, events, webinars, and email drip campaigns. |
| Sales Person | Incremental | Contains details of the sales people who are in charge of leads, and who remain in contact with them for selling the product. |
| Smart List | Incremental | Contains the list of specific leads and groups that can be searched in your Marketo account using filters. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
Refresher tasks for the Leads object in Marketo use the
createdAttimestamp to query data. This may result in data mismatches, as leads created over 3 months ago but updated recently might not sync to the Destination. This limitation occurs because some Marketo accounts do not support querying using theupdatedAttimestamp, which is required to fetch updated data for leads created more than 3 months ago. When attempting to query usingupdatedAtin unsupported accounts, Marketo returns an error. Read Filters - Bulk Lead Extract for more information.As a result, for unsupported Marketo accounts, Hevo defaults to using the
createdAttimestamp, which may not reflect recent updates for older leads.To enable data fetching using the
updatedAttimestamp, contact Hevo Support.
Limitations
- Hevo does not load an Event into the Destination table if its size exceeds 128 MB, which may lead to discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each row in your Source objects contains less than 100 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Jan-06-2025 | 2.31.2 | Updated the Source Considerations section to specify data fetch behaviour for the Leads object. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Feb-07-2023 | 2.07 | Updated section, Data Model to add the List and List Membership objects. - Updated section, Schema and Primary Keys to add the new ERD link with the List and List Membership objects. |
| Dec-07-2022 | NA | Updated section, Data Replication to reorganize the content for better understanding and coherence. |
| Oct-25-2021 | NA | Added the Pipeline frequency information in the Data Replication section. |