Amazon DynamoDB
On This Page
Amazon DynamoDB is a fully managed, multi-master, a multi-region non-relational database that offers built-in in-memory caching to deliver reliable performance at any scale.
Hevo uses DynamoDB’s data streams to support change data capture (CDC). Data streams are time-ordered sequences of item-level changes in the DynamoDB tables. All data in DynamoDB streams are subject to a 24-hour lifetime and are automatically removed after this time. We suggest that you keep the ingestion frequency accordingly.
To facilitate incremental data loads to a Destination, Hevo needs to keep track of the data that has been read so far from the data stream. Hevo supports two ways of replicating data to manage the ingestion information:
Refer to the table below to know the differences between the two methods.
| Kinesis Data Streams | DynamoDB Streams |
|---|---|
| Recommended method. | Default method, if DynamoDB user does not have dynamodb:CreateTable permissions. |
User permissions needed on the DynamoDB Source: - Read-only - dynamodb:CreateTable |
User permissions needed on the DynamoDB Source: - Read-only |
| Uses the Kinesis Client Library (KCL) to ingest the changed data from the database. | Uses the DynamoDB library. |
| Guarantees real-time data ingestion | Data might be ingested with a delay |
The Kenesis driver maintains the context. KCL creates an additional table (with prefix hevo_kcl) per table in the Source system, to store the last processed state for a table. |
Hevo keeps the entire context of data replication as metadata, including positions to indicate the last record ingested. |
The following image illustrates the key steps that you need to complete to configure Amazon DynamoDB as a Source in Hevo:
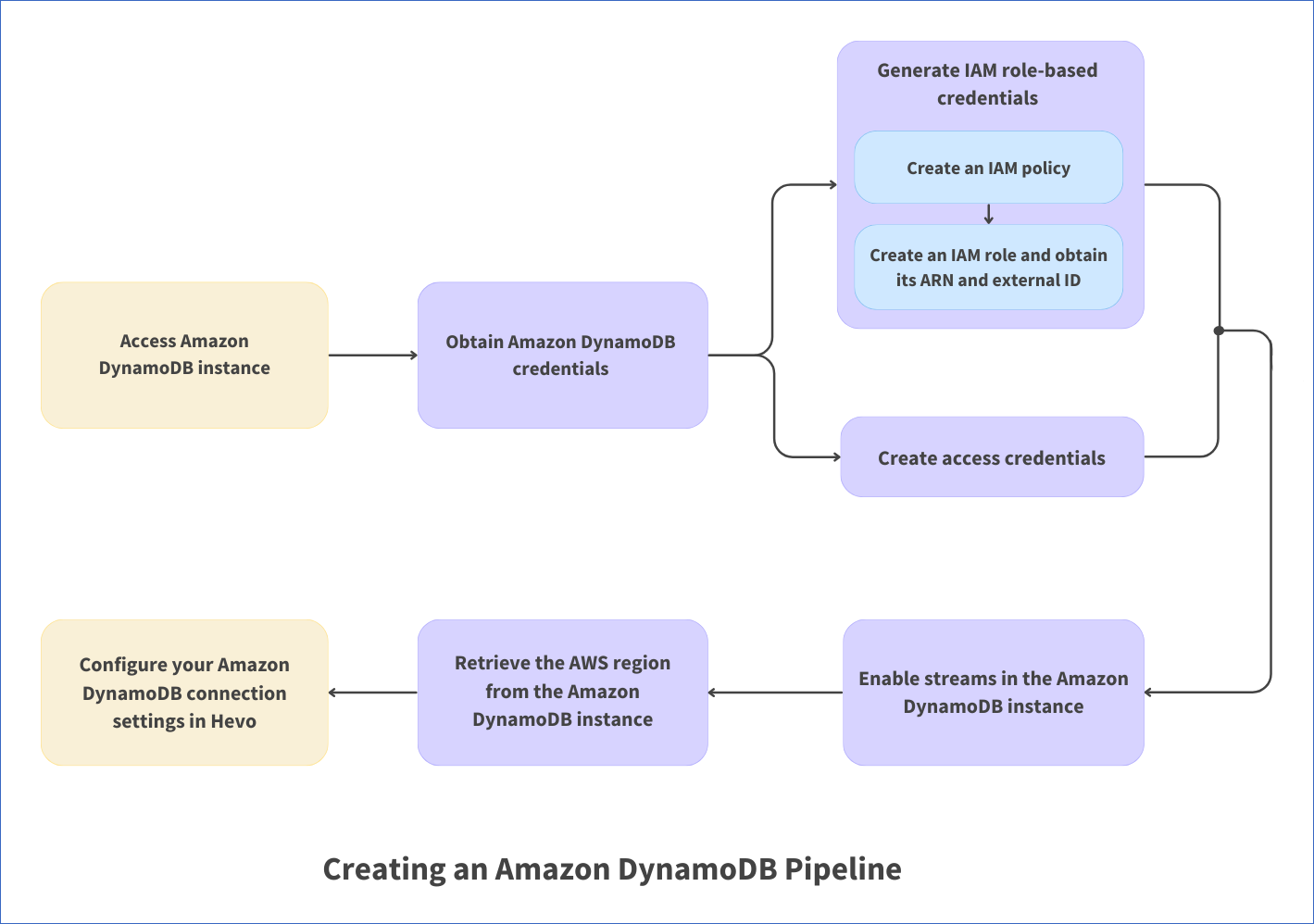
Prerequisites
-
An active Amazon Web Services (AWS) account is available.
-
If you are logged in as an IAM user, you have permission to:
-
Create the access credentials or generate IAM role-based credentials.
-
Obtain or create the IAM policies
-
-
Streams are enabled on the DynamoDB tables to be replicated and the value of the StreamViewType parameter is set to New and old images (NEW_AND_OLD_IMAGES in the CLI). Without this configuration, while the historical data is successfully ingested, the incremental data ingestion fails.
Note: Hevo does not modify any data in the Source tables. The permissions are used solely to store the last processed state for a table by the Kinesis Client Library (KCL).
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo, to create the Pipeline.
Obtain Amazon DynamoDB Credentials
You must either Create access credentials or Generate IAM role based credentials to allow Hevo to connect to your Amazon DynamoDB account and ingest data from it.
Create access credentials
You need the access key and secret access key from your Amazon DynamoDB account to allow Hevo to access the data from it.
-
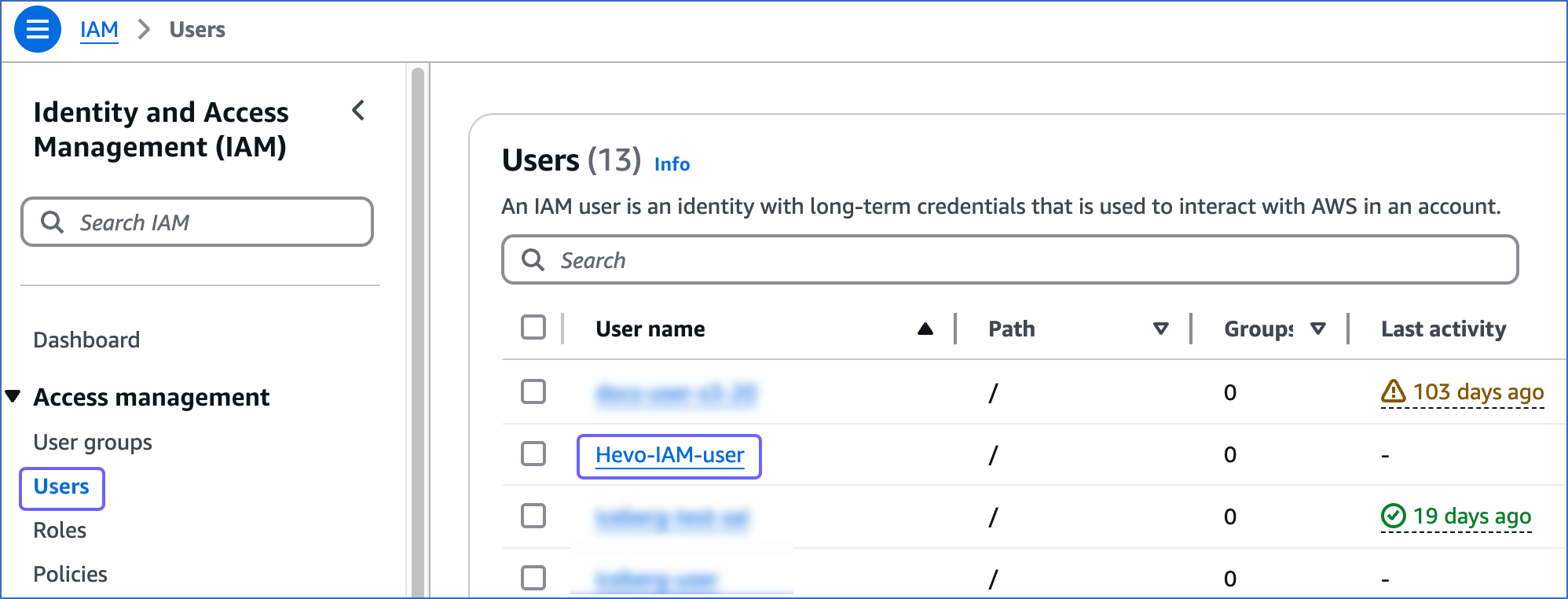
Log in to the AWS IAM Console.
-
In the left navigation bar, under Access management, click Users. Then, in the right pane, click the User name for which you want to create an access key.
-
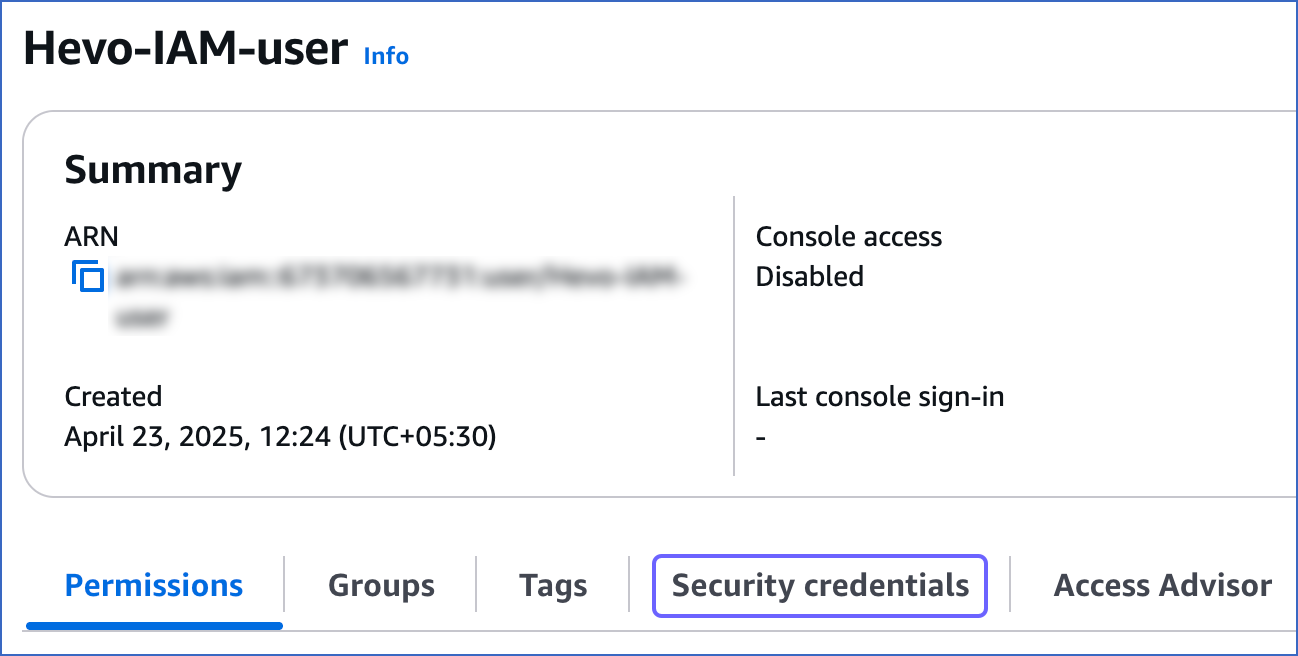
On the <User name> page, click the Security credentials tab and scroll down to the Access keys section.
-
Click Create access key.

-
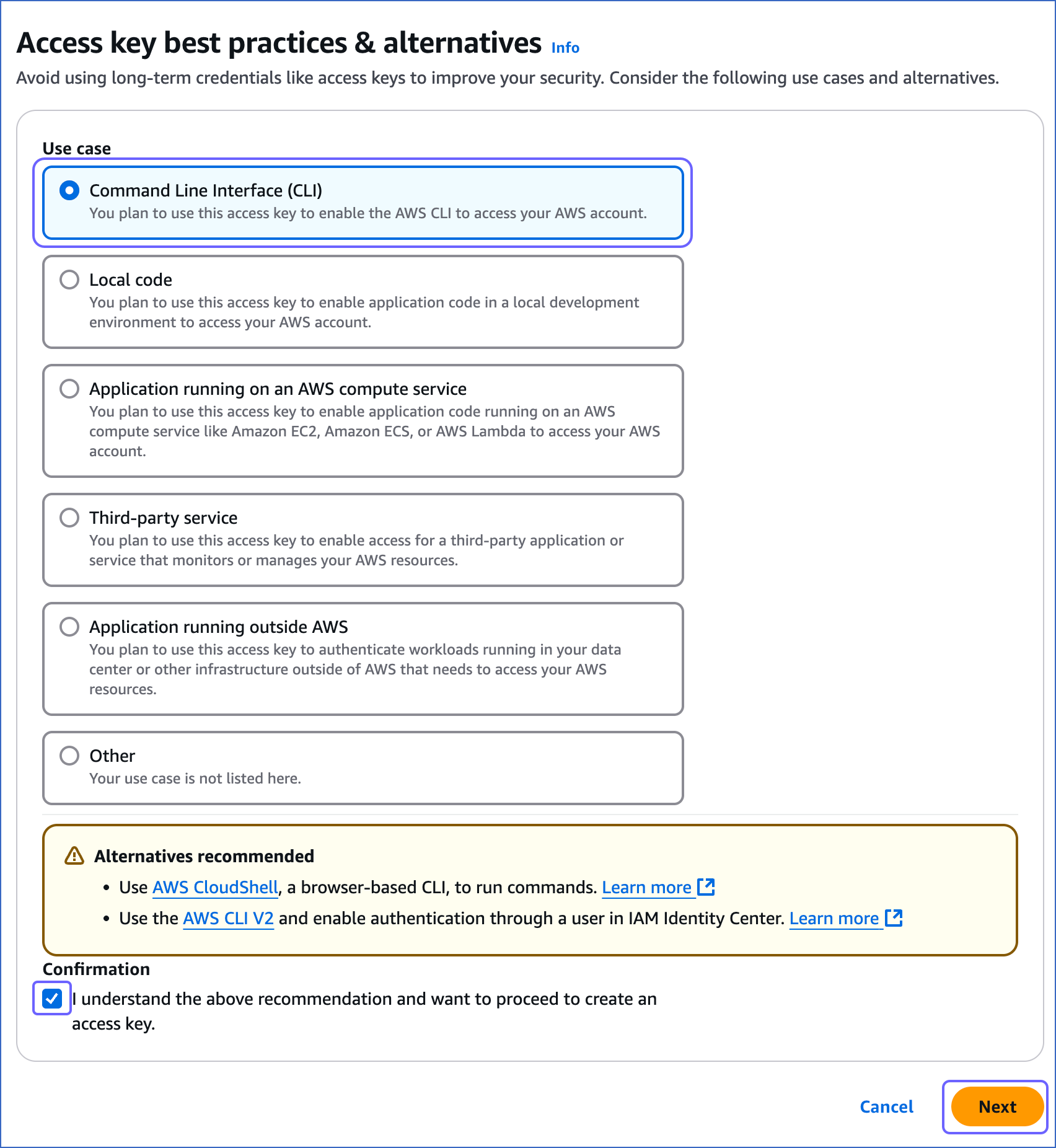
On the Access key best practices & alternatives page, do the following:
-
Select one of the following recommended methods. For example, in the image above, Command Line Interface (CLI) is selected.
-
Select the I understand the above recommendation… check box, to proceed with creating the access key.
-
Click Next.
-
-
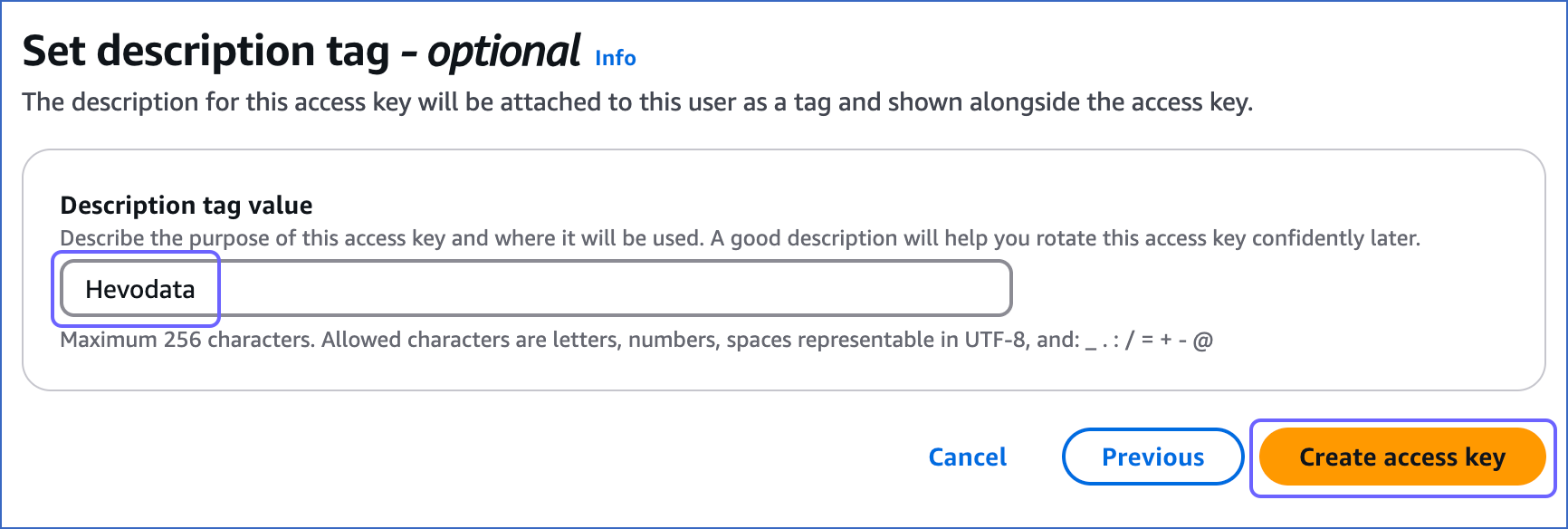
On the Set description tag - optional page, do the following:
-
(Optional) Specify a description for the access key in the Description tag value field.
-
Click Create access key.
-
-
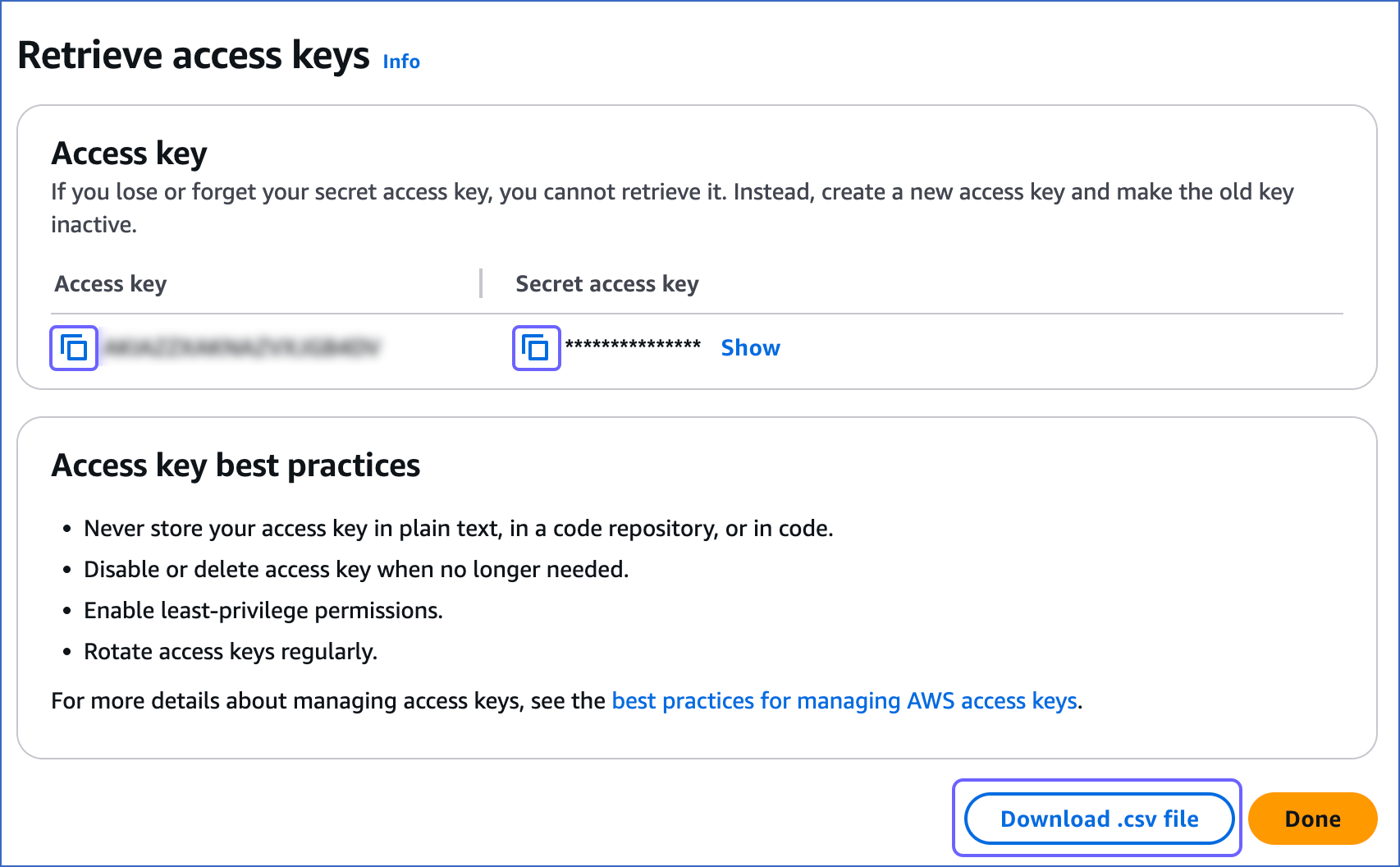
On the Retrieve access keys page, do the following:
-
Click the copy icon in the Access key field and save the key securely like any other password.
-
Click the copy icon in the Secret access key field and save the key securely like any other password.
Note: Once you exit this page, you cannot view these keys again.
-
(Optional) Click Download .csv file to save the access key and the secret access key on your local machine.
-
Generate IAM role-based credentials
To generate your IAM role-based credentials, you need to:
-
Create an IAM policy with the permission to allow Hevo to access data from your DynamoDB database.
-
Create an IAM role for Hevo, as the Amazon Resource Name (ARN) and the external ID from this role are required to configure Amazon DynamoDB as a Source in Hevo.
These steps are explained in details below:
1. Create an IAM policy
-
Log in to the AWS IAM Console.
-
In the left navigation bar, under Access management, click Policies.
-
On the Policies page, click Create policy.
-
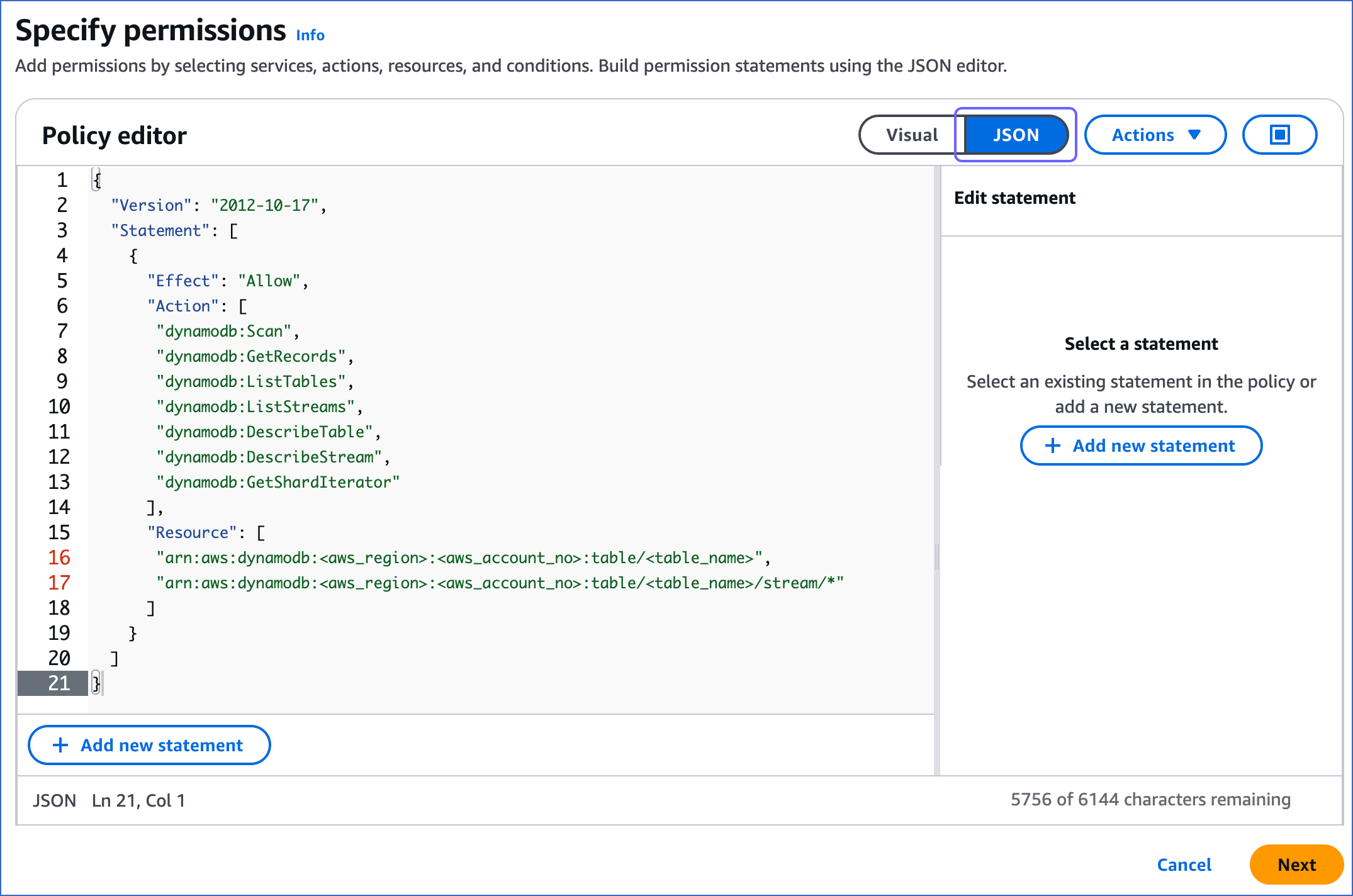
On the Specify permissions page, click the JSON tab and paste the following policy in the editor. The JSON statements list the permissions the policy would assign to Hevo.
Note:
-
Replace the placeholder values in the commands below with your own. For example, <aws_region> with us-east-1.
-
You can replace the <table_name> in the command below with
*to ingest data from all the tables in your database.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "dynamodb:Scan", "dynamodb:GetRecords", "dynamodb:ListTables", "dynamodb:ListStreams", "dynamodb:DescribeTable", "dynamodb:DescribeStream", "dynamodb:GetShardIterator" ], "Resource": [ "arn:aws:dynamodb:<aws_region>:<aws_account_no>:table/<table_name>", "arn:aws:dynamodb:<aws_region>:<aws_account_no>:table/<table_name>/stream/*" ] } ] }Note: Hevo does not modify any data in the Source tables. The permissions are used solely to store the last processed state for a table by the KCL.
-
-
Click Next.
-
On the Review and create page, specify a Policy name and Description for your policy and click Create policy.
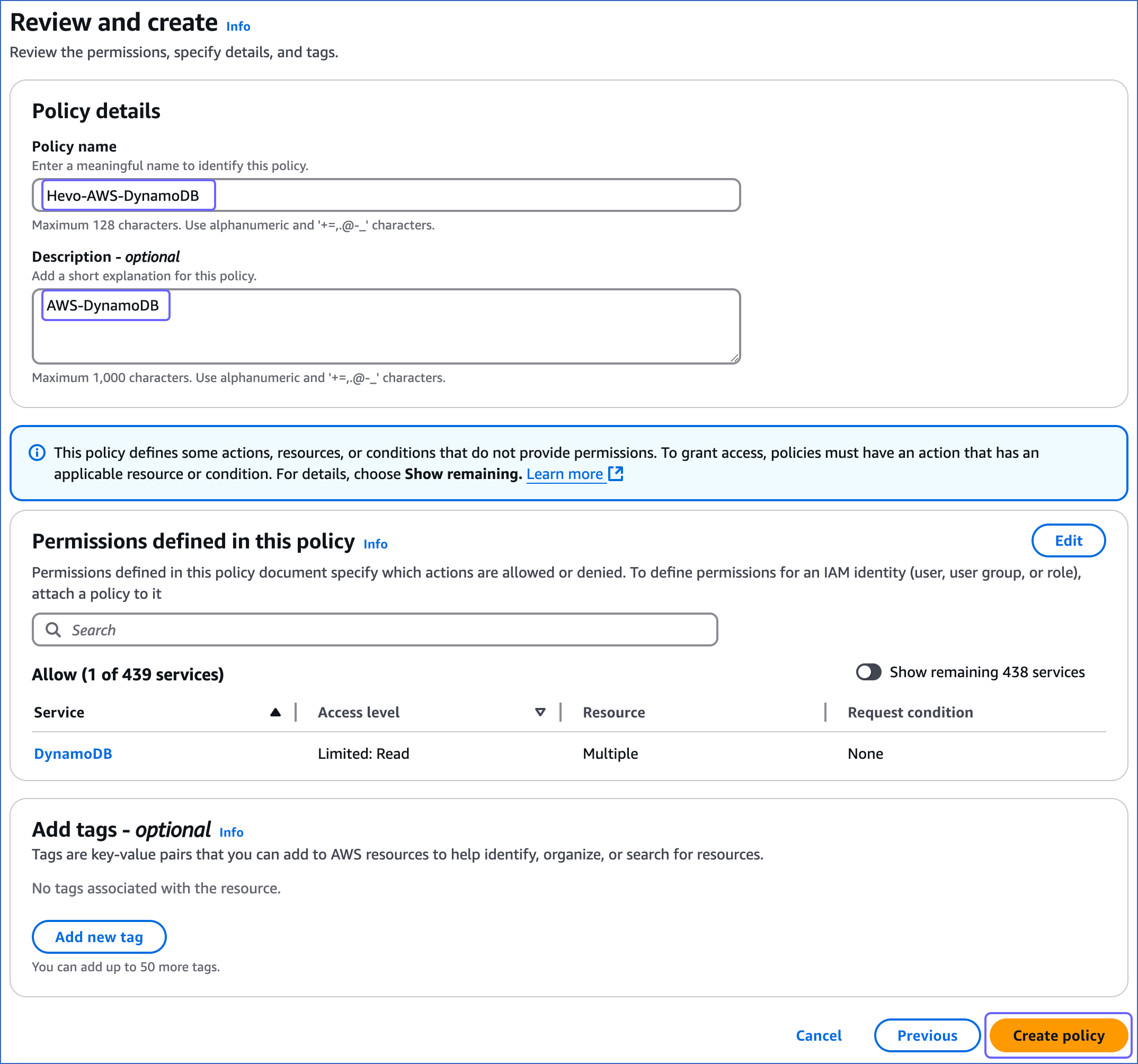
You are redirected to the Policies page, where you can see the policy that you created.
2. Create an IAM role and obtain its ARN and External ID
Perform the following steps to create an IAM role:
-
Log in to the AWS IAM Console.
-
In the left navigation bar, under Access management, click Roles.
-
On the Roles page, click Create role.

-
On the Select trusted entity page:
-
In the Trusted entity type section, select AWS account.

-
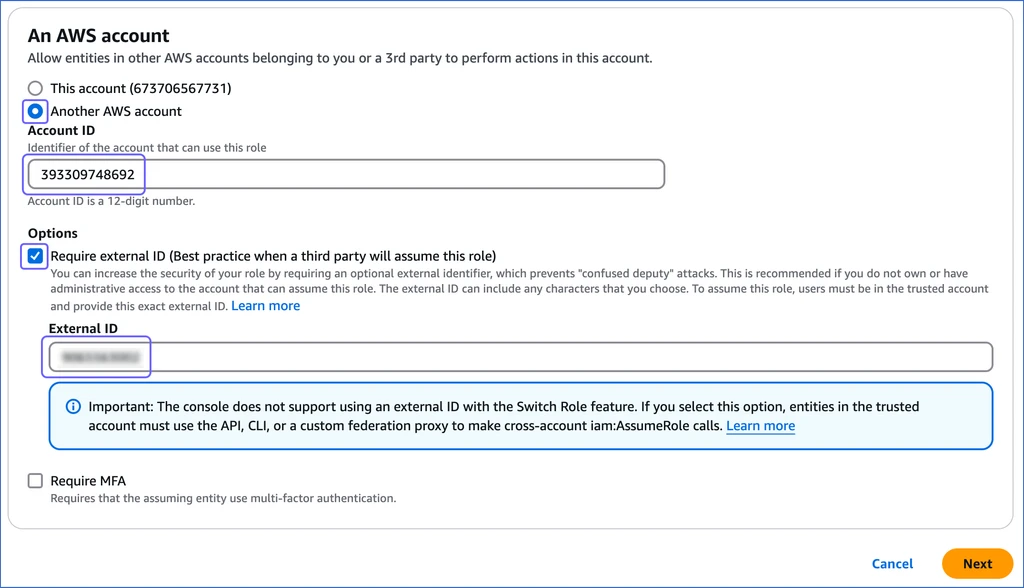
In the An AWS account section, do the following:
-
Select the Another AWS account option, and specify Hevo’s Account ID, 393309748692.
-
In the Options section, select the Require external ID… check box, and specify an External ID of your choice.
Note: You must save this external ID in a secure location like any other password. This is required while setting up a Pipeline in Hevo.
-
-
-
Click Next.
-
In the Permissions policies section, search and select the check box corresponding to the policy that you created in the create an IAM policy section above, and then click Next at the bottom of the page.
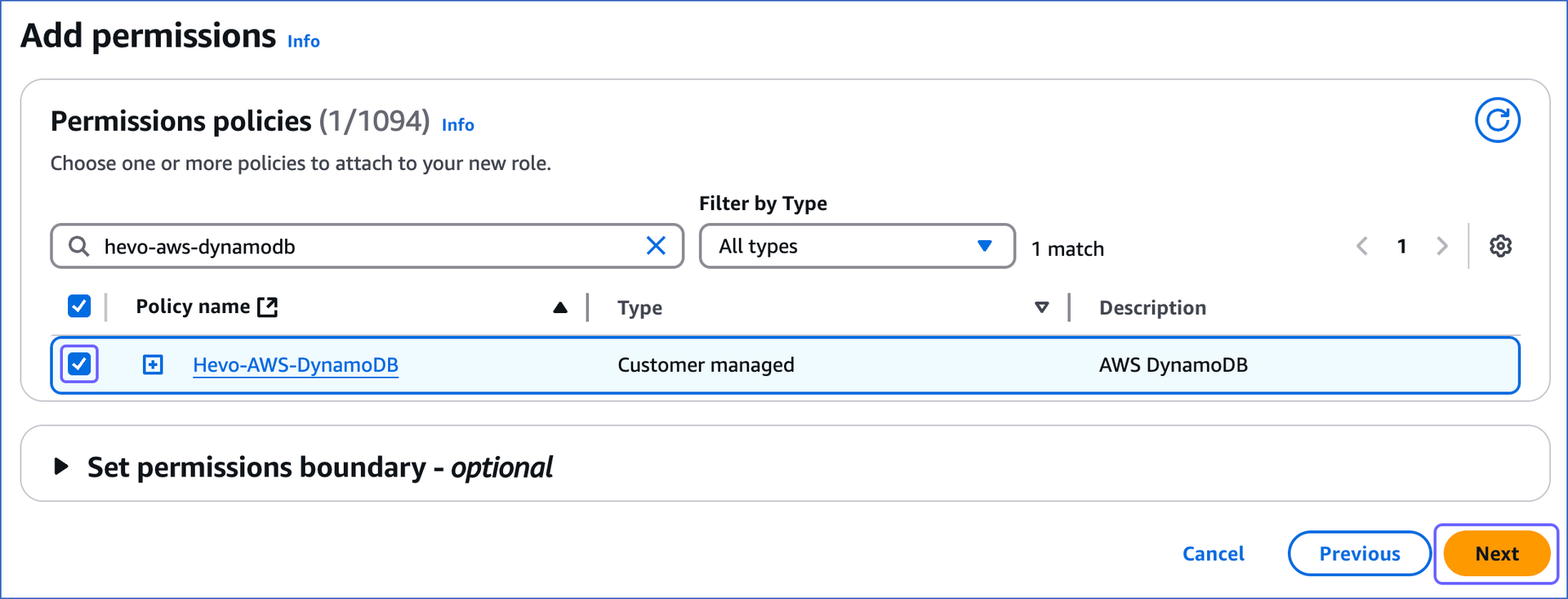
-
On the Name, review, and create page, specify the Role name and Description, and then click Create role.
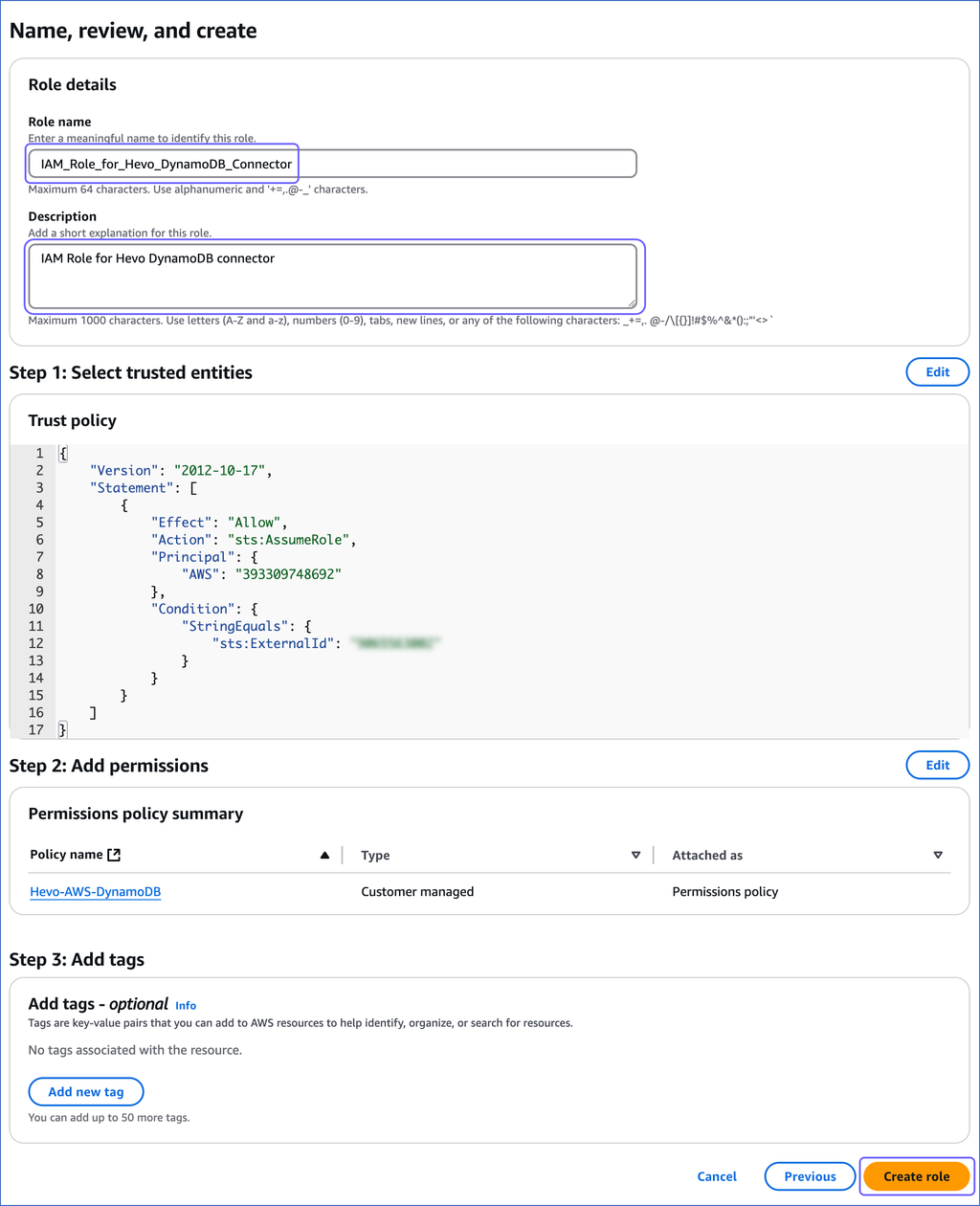
-
On the Roles page, search and click the role that you created above.
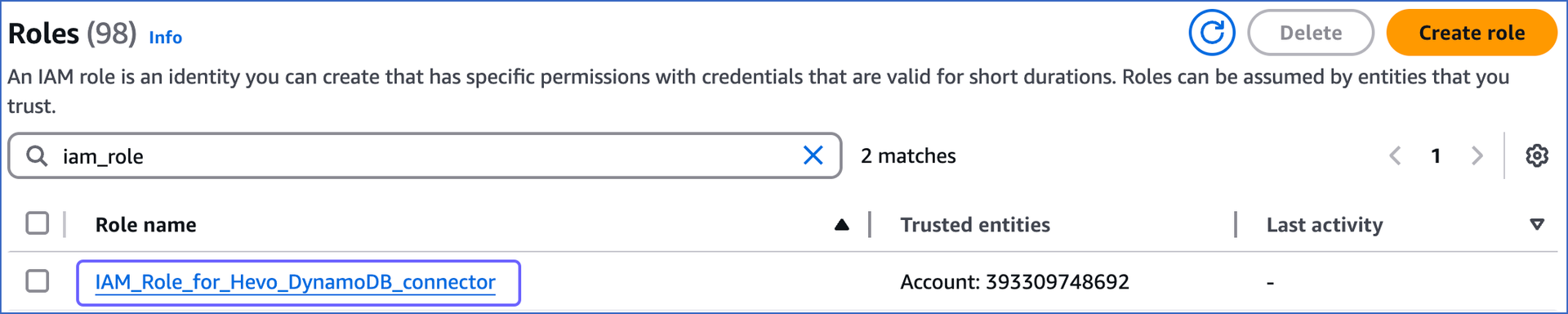
-
On the <Role name> page, in the Summary section, click the copy icon to copy the ARN and save it securely like any other password. Use this ARN while configuring Amazon DynamoDB as a Source in Hevo.

Enable Streams
You need to enable Streams for all DynamoDB tables you want to sync through Hevo. To do this:
-
Sign in to the AWS DynamoDB Console.
-
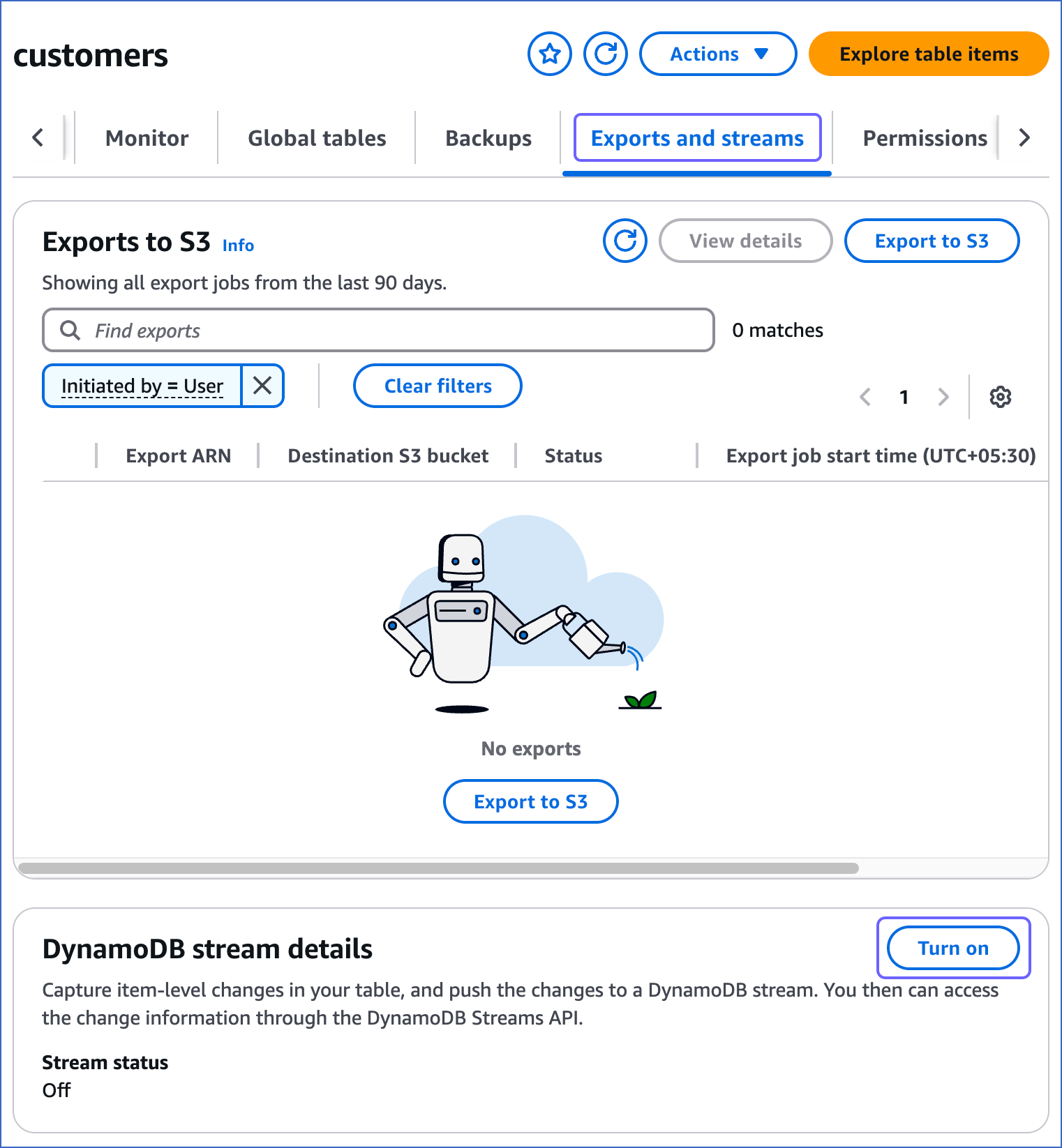
In the left navigation bar, click Tables, and then click the table for which you want to enable streams. For example, customers in the image below.
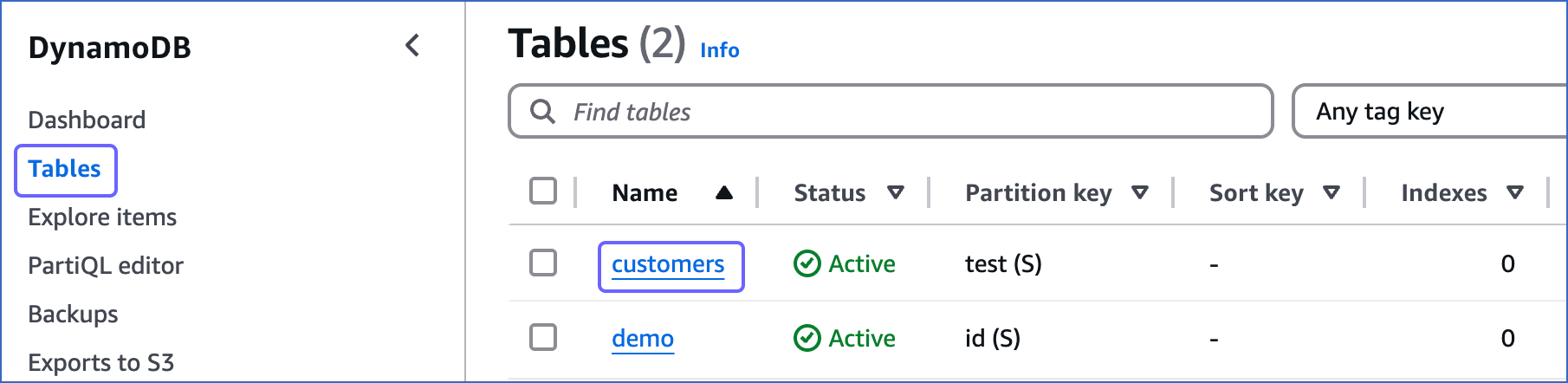
-
On the <Table name> page, click the Exports and streams tab, scroll down to the DynamoDB stream details section and click Turn on.
-
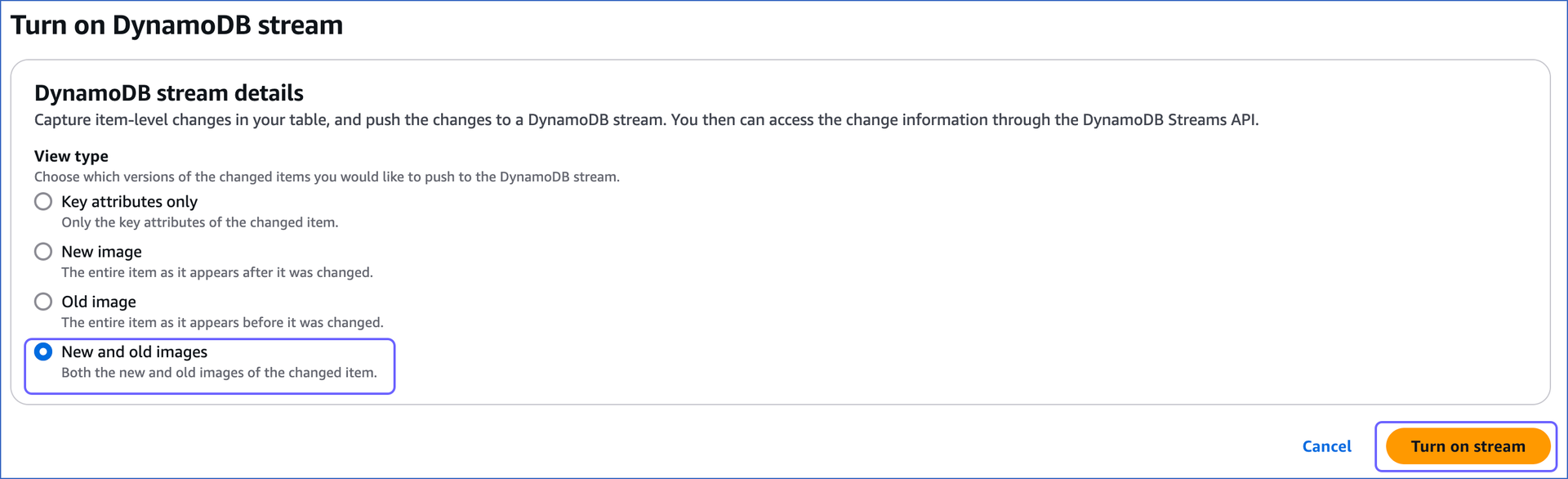
On the Turn on DynamoDB stream page, select New and old images and click Turn on stream.
-
Repeat Steps 2-4 for all the tables you want to synchronize.
Retrieve the AWS Region
To configure Amazon DynamoDB as a Source in Hevo you need to provide the AWS region where your DynamoDB instance is running.
To retrieve your AWS region:
-
Log in to your Amazon DynamoDB Console, and in the top-right corner of the page, locate the AWS region.
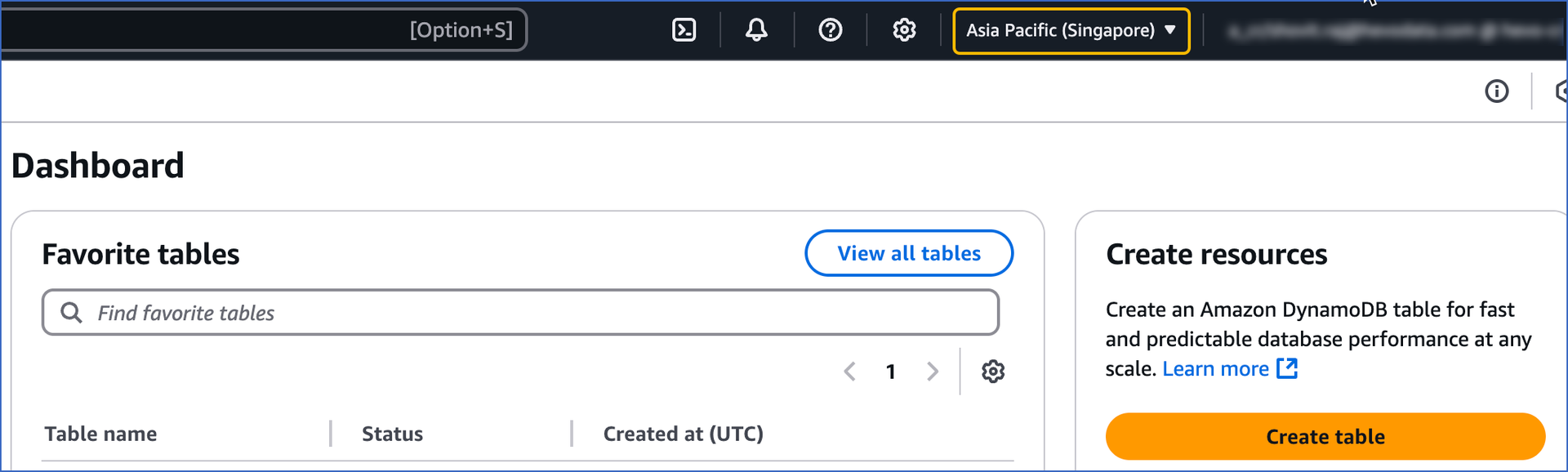
Note: Your Amazon DynamoDB instance must be created in one of the AWS regions supported by Hevo.
Configure Amazon DynamoDB Connection Settings
Perform the following steps to configure DynamoDB as a Source in Hevo:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
On the Select Source Type page, select DynamoDB.
-
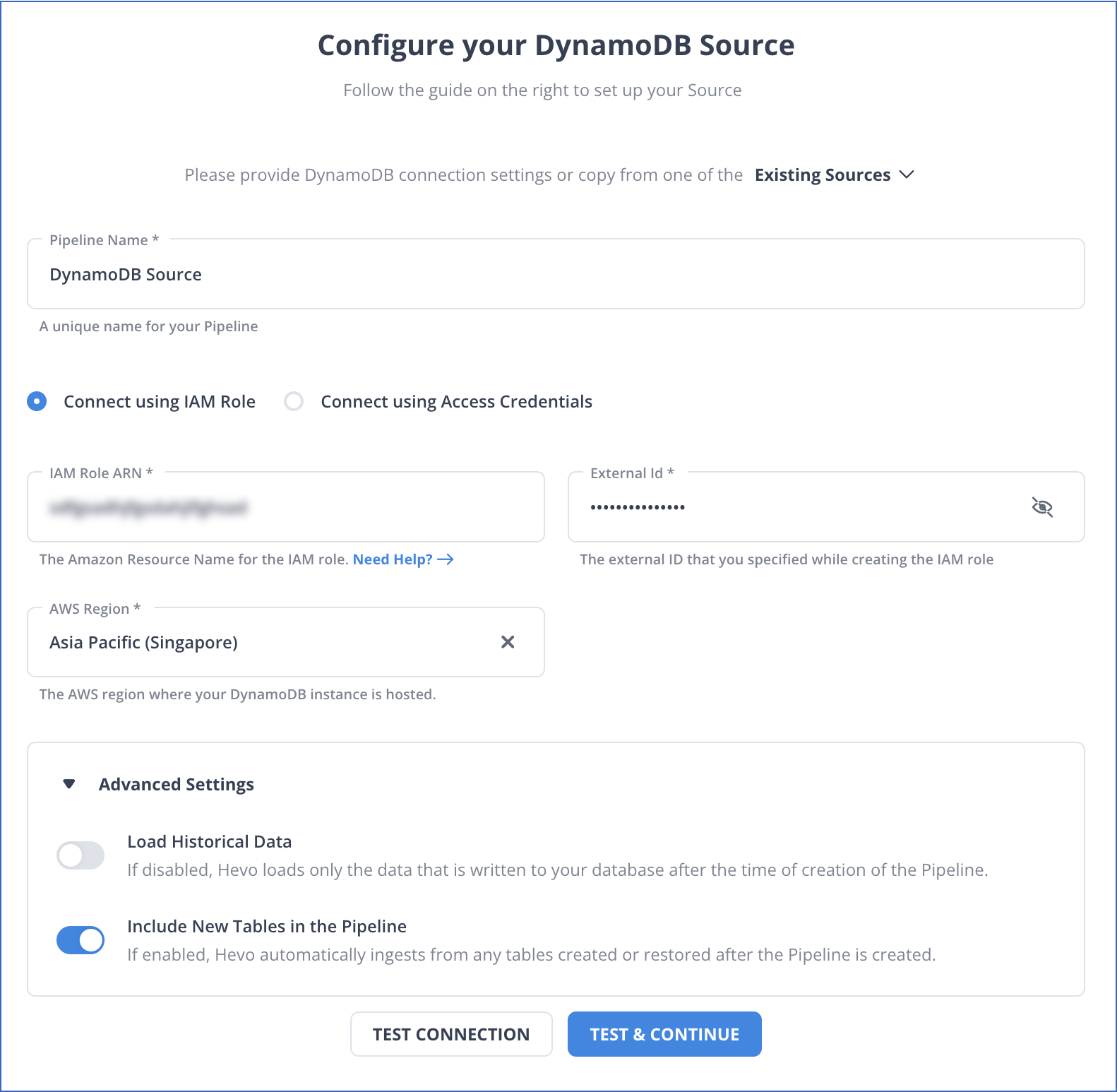
On the Configure your DynamoDB Source page, specify the following:
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Select one of the methods to connect to your Amazon DynamoDB database:
-
Connect using IAM Role:

-
IAM Role ARN: The Amazon Resource Name (ARN) of the IAM role that you retrieved in the section above.
-
External Id: The external ID that you specified above.
-
AWS Region: The AWS region where your DynamoDB instance is running.
-
-
Connect using Access Credentials:

-
Access Key ID: The AWS access key that you retrieved in the Create access credentials section above.
-
Secret Access Key: The AWS secret access key for the access key ID that you retrieved in the Create access credentials section above.
-
AWS Region: The AWS region where your DynamoDB instance is running.
-
-
-
Advanced Settings:
-
Load Historical Data: If this option is enabled, the entire table data is fetched during the first run of the Pipeline. If disabled, Hevo loads only the data that was written in your database after the time of creation of the Pipeline.
-
Include New Tables in the Pipeline: Applicable for all Pipeline modes except Custom SQL.
If enabled, Hevo automatically ingests data from tables created in the Source after the Pipeline has been built. These may include completely new tables or previously deleted tables that have been re-created in the Source.
-
-
-
Click TEST CONNECTION to check connectivity with the Amazon DynamoDB database.
-
Click TEST & CONTINUE.
-
Proceed to configuring the data ingestion and setting up the Destination.
Hevo defers the data ingestion for a pre-determined time in the following scenarios:
- If your DynamoDB Source does not contain any new Events to be ingested.
- If you are using DynamoDB Streams and the required permissions are not granted to Hevo.
Hevo re-attempts to fetch the data only after the deferment period elapses.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 5 Mins | 5 Mins | 1 Hr | NA |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests all the data available in your Amazon DynamoDB database.
-
Incremental Data: Once the historical load is complete, all new and updated data is synchronized with your Destination as per the ingestion frequency.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Schema and Type Mapping
Hevo replicates the schema of the tables from the Source DynamoDB as-is to your Destination database or data warehouse. In rare cases, we skip some columns with an unsupported Source data type while transforming and mapping.
The following table shows how your DynamoDB data types get transformed to a warehouse type.
| DynamoDB Data Type | Warehouse Data Type |
|---|---|
| String | VARCHAR |
| Binary | Bytes |
| Number | Decimal/Long |
| STRINGSET | JSON |
| NUMBERSET | JSON |
| BINARYSET | JSON |
| Map | JSON |
| List | JSON |
| Boolean | Boolean |
| NULL | - |
Limitations
-
On every Pipeline run, Hevo ingests the entire data present in the Dynamo DB data streams that you are using for ingestion. Data streams can store data for a maximum of 24 hrs. So, depending on your Pipeline frequency, some events might get re-ingested in the Pipeline and consume your Events quota. Read Pipeline Frequency to know how it affects your Events quota consumption.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Apr-28-2025 | NA | Updated sections, Obtain Amazon DynamoDB Credentials, Enable Streams, and Retrieve the AWS Region as per the latest Amazon DynamoDB UI. |
| Apr-21-2025 | NA | Updated the Create an IAM policy sub-section to revise the IAM policy JSON and reflect the latest Amazon DynamoDB UI. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Oct-29-2024 | NA | Updated sections, Enable Streams and Retrieve the AWS Region as per the latest Amazon DynamoDB UI. |
| May-27-2024 | 2.23.4 | Added the Data Replication section. |
| Apr-25-2023 | 2.12 | - Added section, Obtain Amazon DynamoDB Credentials. - Renamed and updated section, (Optional) Obtain your Access Key ID and Secret Access Key to Create access credentials. - Updated section, Configure Amazon DynamoDB Connection Settings to add information about connecting to Amazon DynamoDB database using IAM role. |
| Nov-08-2022 | NA | Added section, Limitations. |
| Oct-17-2022 | 1.99 | Updated section, Configure Amazon DynamoDB Connection Settings to add information about deferment of data ingestion if required permissions are not granted. |
| Oct-04-2021 | 1.73 | - Updated the section, Prerequisites to inform users about setting the value of the StreamViewType parameter to NEW_AND_OLD_IMAGES. - Updated the section, Enable Streams to reflect the latest changes in the DynamoDB console. |
| Aug-8-2021 | NA | Added a note in the Source Considerations section about Hevo deferring data ingestion in Pipelines created with this Source. |
| Jul-12-2021 | 1.67 | Added the field Include New Tables in the Pipeline under Source configuration settings. |
| Feb-22-2021 | 1.57 | Added sections: - Create the AWS Access Key and the AWS Secret Key - Retrieve the AWS Region |