Amazon RDS SQL Server
On This Page
Amazon Relational Database Service (RDS) allows you to deploy, and scale multiple editions of MS SQL Server in minutes with cost-efficient and resizable compute capacity.
You can ingest data from your Amazon RDS SQL Server using Hevo Pipelines and replicate it to a Destination of your choice.
Prerequisites
-
The MS SQL Server version is 2008 or higher.
-
If the Pipeline Mode is Change Tracking or Table, and the Query mode is Change Tracking:
-
SELECT and VIEW CHANGE TRACKING privileges are granted to the database user.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo, to create the Pipeline.
Perform the following steps to configure your Amazon RDS SQL Server Source:
Enable Change Tracking
Note: This step is valid only for Pipelines with Change Tracking as their Pipeline Mode.
The Change Tracking mechanism captures changes made to a database. In order to enable, or disable change tracking, the database user must have the ALTER DATABASE privilege.
To enable change tracking, connect your Amazon RDS SQL Server database in your SQL Client tool, and enter these commands:
-
Enable change tracking at the database level:
ALTER DATABASE <database_name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 3 DAYS, AUTO_CLEANUP = ON)The
CHANGE_RETENTIONvalue specifies the time period for which change tracking information is retained. You can useAUTO_CLEANUPto enable or disable the cleanup task that removes old change tracking information. Read Enable Change Tracking for a Database.Note: Hevo recommends that you set the CHANGE_RETENTION value to 3 DAYS. This reduces the risk of log expiry in the case of Pipelines having a low ingestion frequency, for example, 24 hours.
-
Enable change tracking at the table and schema level:
ALTER TABLE <schema_name>.<table> ENABLE CHANGE_TRACKINGRepeat this step for each table you want to replicate using log-based incremental replication. Read Enable Change Tracking for a Table.
Note: Hevo does not support Change Data Capture (CDC) for Amazon RDS SQL Server.
Whitelist Hevo’s IP Addresses
You need to whitelist the Hevo IP addresses for your region to enable Hevo to connect to your Amazon RDS SQL Server database. To do this:
-
Open the Amazon RDS console.
-
In the left navigation pane, click Databases (or Instances if you are using an older version).
-
In the Databases section on the right, click the DB identifier of the Amazon RDS SQL Server instance.

Note: The instance does not necessarily have to be a replica as long as it whitelists Hevo’s IP address for the region.
-
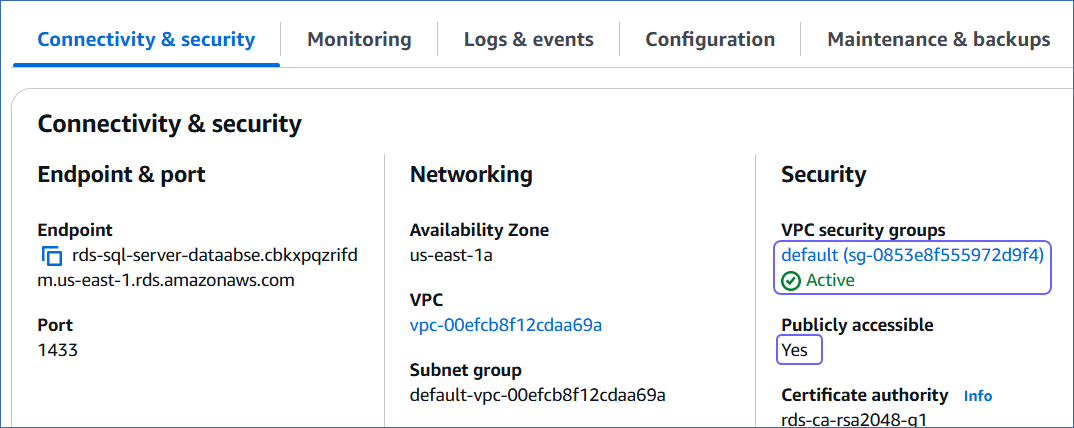
In the Connectivity & security tab, do the following:
-
Ensure Publicly accessible is set to Yes.
-
Click the link text under Security, VPC security groups.
-
-
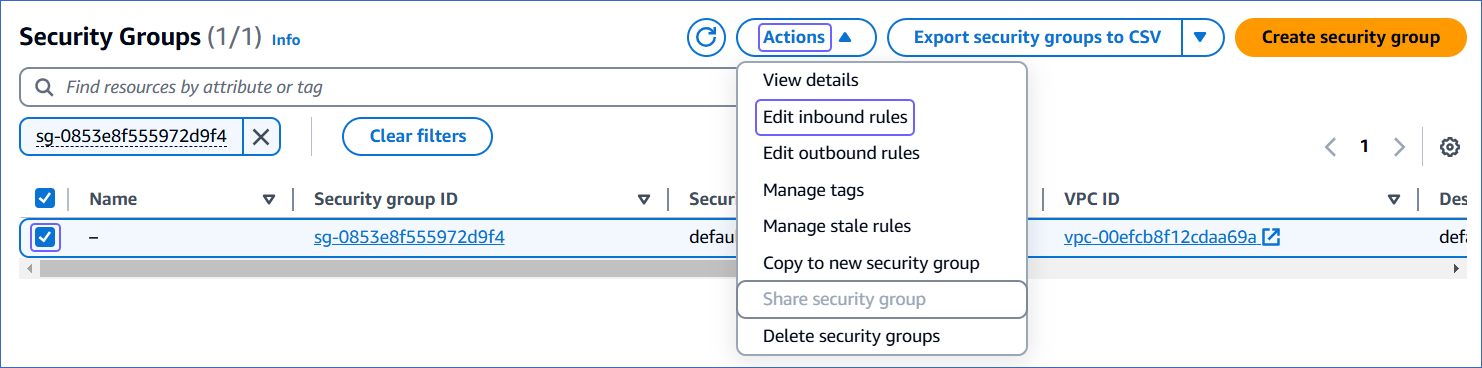
On the Security Groups page, select the check box for your Security group ID, and from the Actions drop-down, click Edit inbound rules.
-
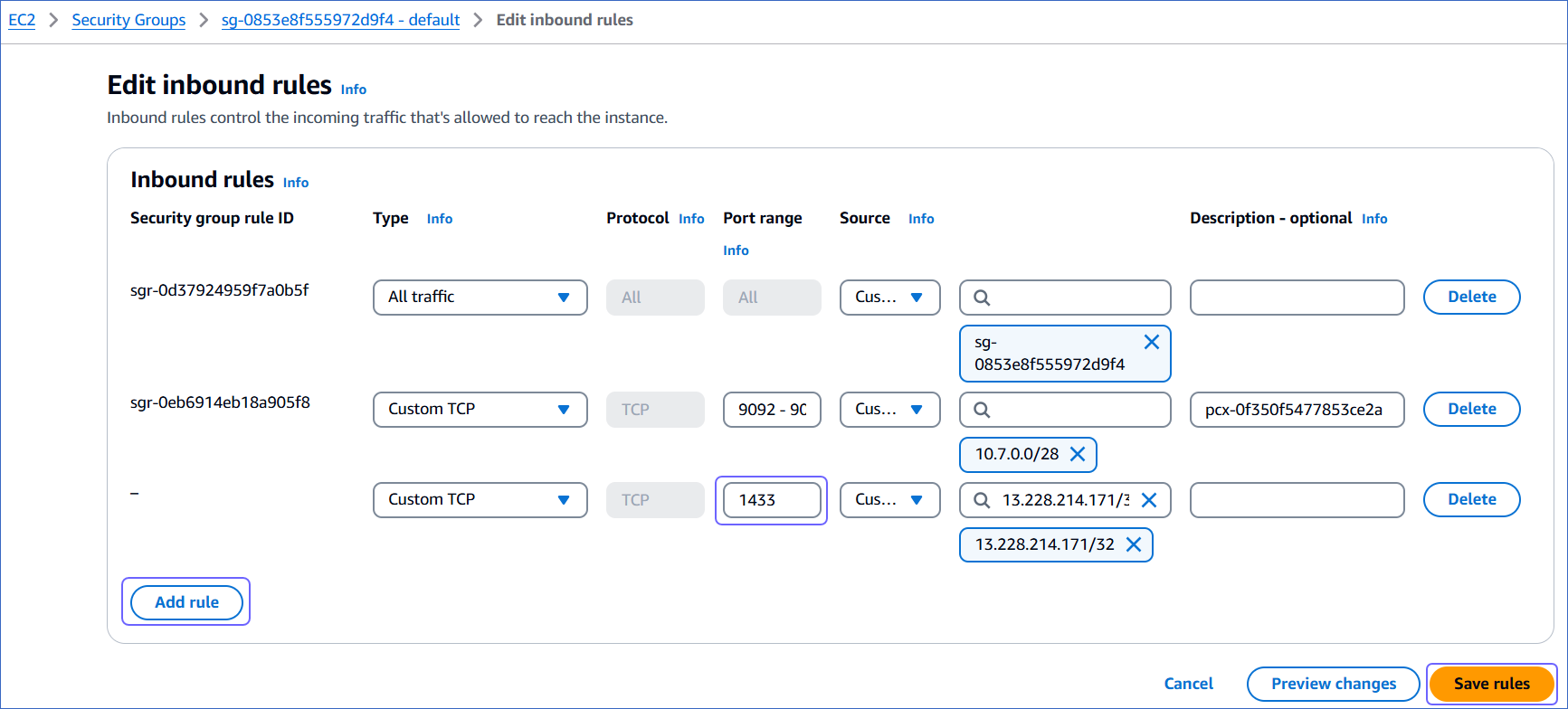
On the Edit inbound rules page:
-
Click Add rule.
-
In the Port range column, enter the port of your Amazon RDS SQL Server instance. The default value is 1433.
-
In the Source column, select Custom from the drop-down and enter Hevo’s IP addresses for your region.
-
Click Save rules.
-
Create a User and Grant Privileges
1. Create a user (optional)
Note: Skip this step if you are using an existing database user.
To create a database user, log in to your Amazon RDS SQL Server instance as a masteruser in your SQL Client tool, and enter these commands:
Note: Replace the placeholder values in the commands below with your own. For example, <username> with hevo.
-
Select a database:
USE <database_name>; -
Create a database user:
CREATE LOGIN <username> WITH PASSWORD = '<password>'; CREATE USER <username> for login <username>;
2. Grant privileges to the user
The database user specified in the Hevo Pipeline must have the following global privileges:
-
SELECT -
VIEW CHANGE TRACKING(If ingestion Mode is Change Tracking)
To assign these privileges, log in to your Amazon RDS SQL Server instance as a masteruser in your SQL Client tool and enter the following commands:
Note: Replace the placeholder values in the commands below with your own. For example, <username> with hevo.
-
Grant
SELECTprivilege at the database level:GRANT SELECT ON DATABASE::<database> TO <username>; -
Grant
SELECTprivilege at the schema level:GRANT SELECT ON SCHEMA::<schema_name> TO <username>; -
If the ingestion mode is Change Tracking, grant the
VIEW CHANGE TRACKINGprivilege at the schema or table level:-
For schema level:
GRANT VIEW CHANGE TRACKING ON SCHEMA::<schema_name> TO <username>; -
For table level:
GRANT VIEW CHANGE TRACKING ON OBJECT::<schema_name>.<table_name> TO <username>;
-
Specify Amazon RDS SQL Server Connection Settings
Perform the following steps to configure Amazon RDS SQL Server as a Source in Hevo:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
On the Select Source Type page, select Amazon RDS SQL Server.
-
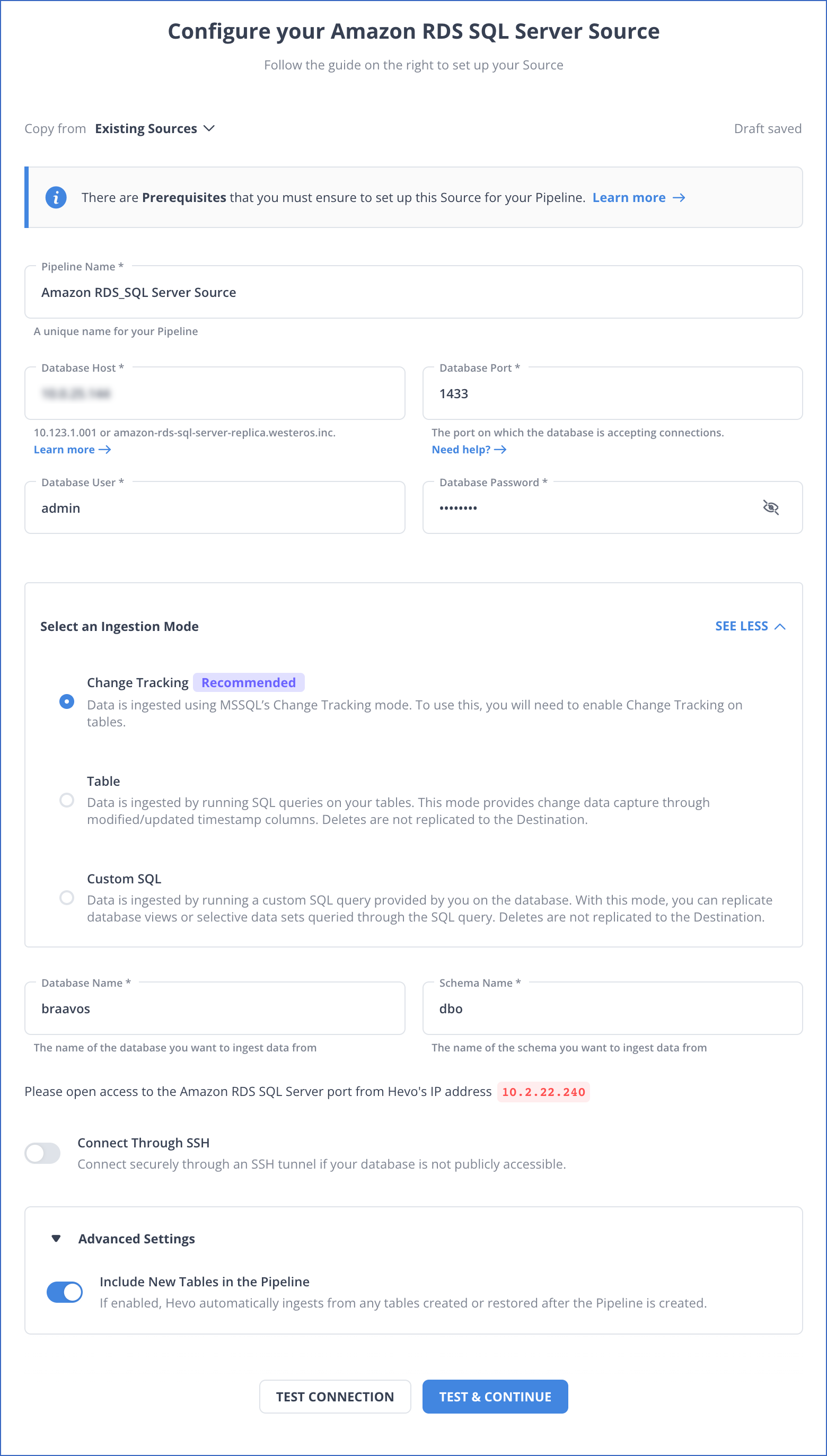
On the Configure your Amazon RDS SQL Server Source page, specify the following:
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Database Host: SQL Server host’s IP address or DNS.
The following table lists a few examples of SQL Server hosts:
Variant Host Amazon RDS SQL Server ms-sql-server-1.xxxxx.rds.amazonaws.com Azure MS SQL mssql.database.windows.net Generic MS SQL 10.123.10.001 or mssql.westeros.inc Google Cloud SQL Server 35.220.150.0 Note: For URL-based hostnames, exclude the http:// or https:// part. For example, if the hostname URL is https://mssql.database.windows.net, enter mssql.database.windows.net.
-
Database Port: The port on which your SQL Server is listening for connections. Default value: 1433.
-
Database User: The read-only user who has the permissions to read tables in your database.
-
Database Password: The password for the read-only user.
-
Select an Ingestion Mode: The desired mode by which you want to ingest data from the Source. You can expand this section by clicking SEE MORE to view the list of ingestion modes to choose from. Default value: Change Tracking. The available ingestion modes are Change Tracking, Table, and Custom SQL.

Depending on the ingestion mode you select, you must configure the objects to be replicated. Refer to section, Object and Query Mode Settings for the steps to do this.
Note: For Custom SQL ingestion mode, all Events loaded to the Destination are billable.
-
Database Name: The database that you wish to replicate.
-
Schema Name: The schema that holds the tables to be replicated. Default value: dbo.
-
Connect through SSH: Enable this option to connect to Hevo using an SSH tunnel, instead of directly connecting your SQL Server database host to Hevo. This provides an additional level of security to your database by not exposing your SQL Server setup to the public. Read Connecting Through SSH. To set up an SSH tunnel for your SQL Server database hosted on Amazon Web Services (AWS), read Configuring an SSH Tunnel.
If this option is disabled, you must whitelist Hevo’s IP addresses. Refer to the content for your SQL Server variant for steps to do this.
-
Advanced Settings:
-
Include New Tables in the Pipeline: Applicable for all ingestion modes except Custom SQL. If enabled, Hevo automatically ingests data from tables created after the Pipeline has been built. If disabled, the new tables are listed in the Pipeline Detailed View in Skipped state, and you can manually include the ones you want and load their historical data. You can include these objects post-Pipeline creation to ingest data.
You can change this setting later.
-
-
-
Click TEST CONNECTION. This button is enabled once you specify all the mandatory fields. Hevo’s underlying connectivity checker validates the connection settings you provide.
-
Click TEST & CONTINUE to proceed for setting up the Destination. This button is enabled once you specify all the mandatory fields.
Object and Query Mode Settings
Once you have specified the Source connection settings in Step 4 above, do one of the following:
-
For Pipelines configured with the Change Tracking ingestion mode:
-
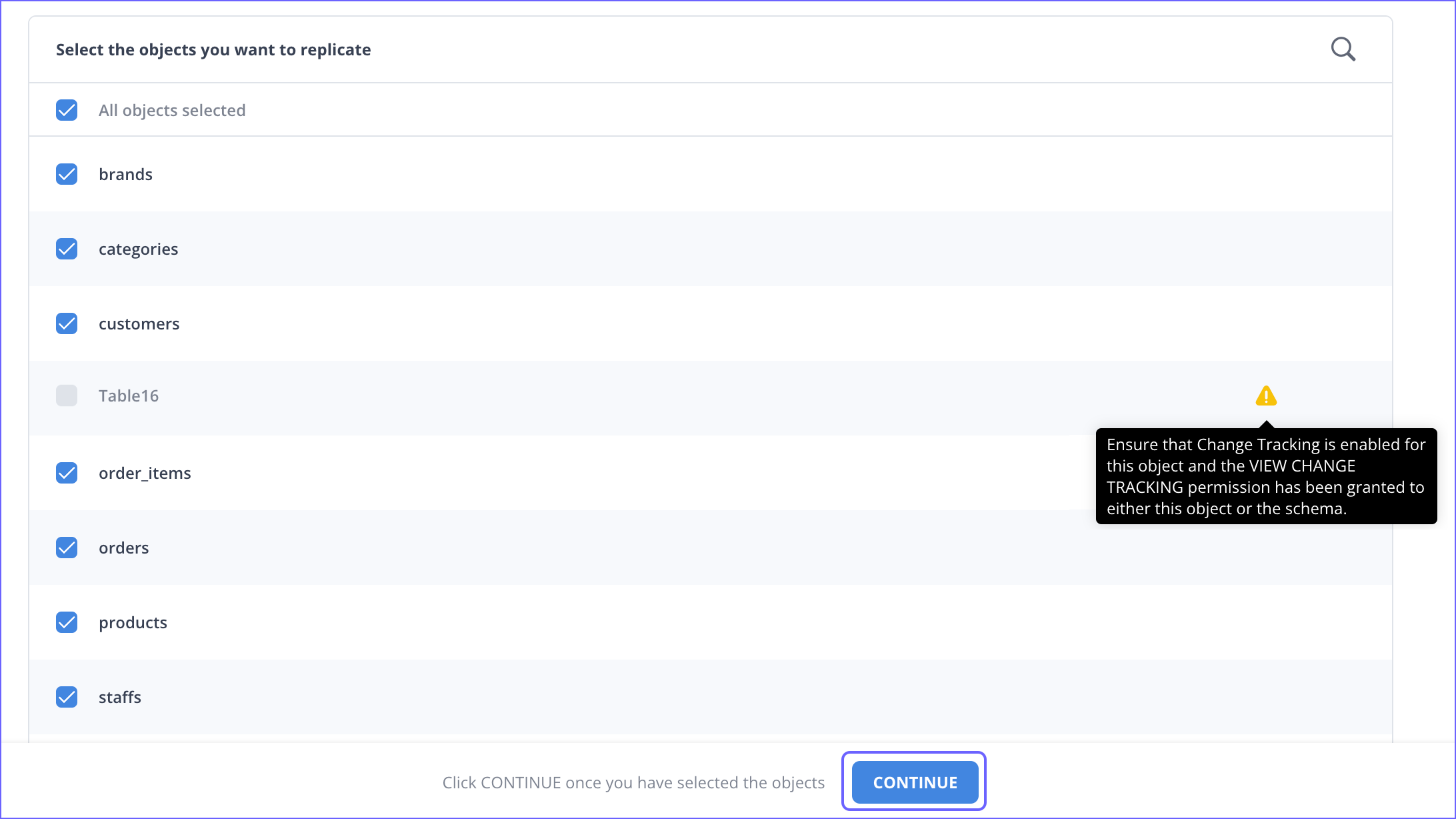
On the Select Objects page, select the objects you want to replicate.
-
Click CONTINUE. This button is enabled once you select at least one object for which Change Tracking is enabled.
Note:
-
Each object represents a table in your database.
-
You must enable Change Tracking for the objects you want to ingest data from. If disabled, Hevo adds these objects to your Pipeline in the SKIPPED state.
-
For customers signing up after Release 2.19, Hevo automatically uses the Unique Incrementing Append Only (UIAO) query mode for the objects that contain a unique column. For the others, it ingests data using the Full Load query mode.
-
-
-
For Pipelines configured with the Table ingestion mode:
-
On the Select Objects page, select the objects you want to replicate and click CONTINUE.
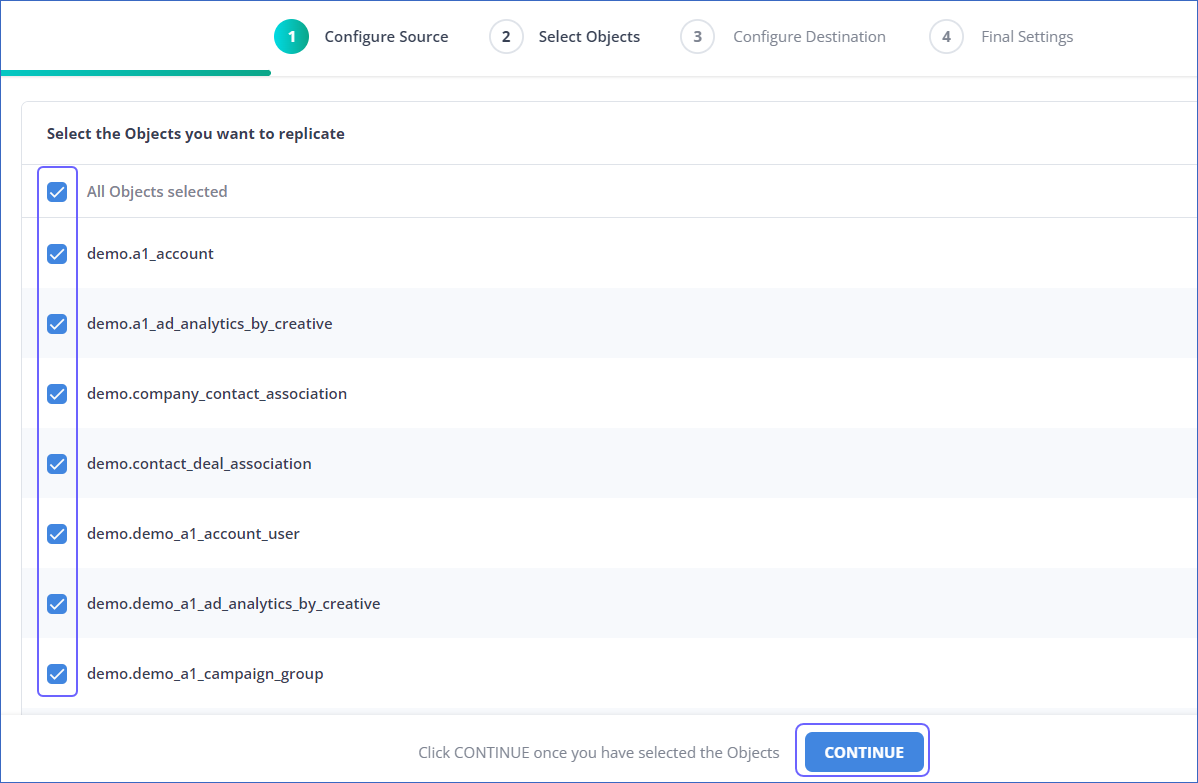
Note: Each object represents a table in your database.
-
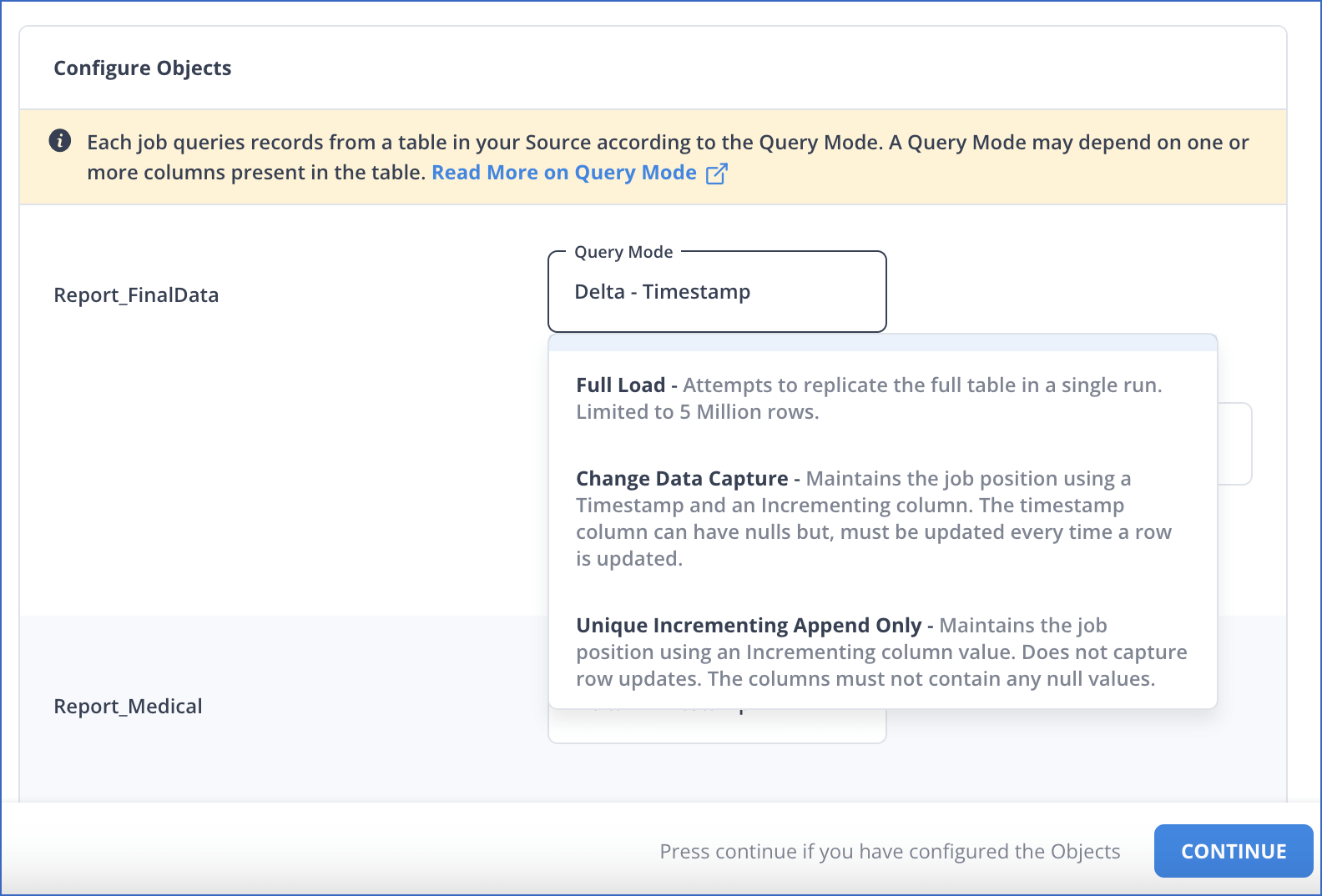
On the Configure Objects page, specify the query mode you want to use for each selected object.
-
-
For Pipelines configured with the Custom SQL ingestion mode:
-
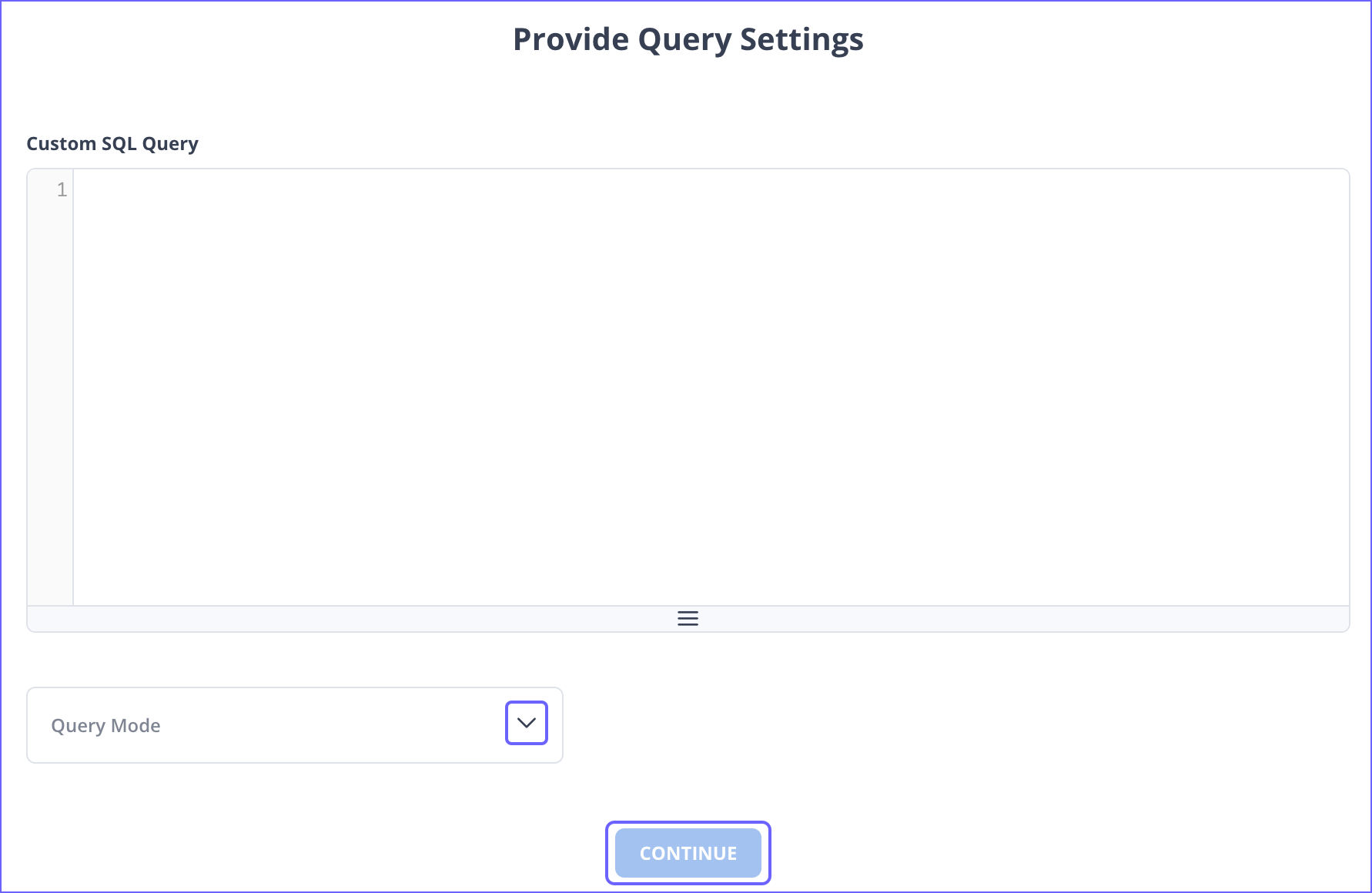
On the Provide Query Settings page, enter the custom SQL query to fetch data from the Source.
-
In the Query Mode drop-down, select the query mode, and click CONTINUE.
-
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 15 Mins | 5 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3 but not 1.5 or 1.75.
- Historical Data: In the first run of the Pipeline, Hevo ingests all available data for the selected objects from your Source database.
- Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Limitations
-
Hevo does not support Change Data Capture (CDC) for Amazon RDS SQL Server.
-
Hevo does not support data replication from temporary tables and views.
-
Hevo does not load an Event into the Destination table if its size exceeds 128 MB, which may lead to discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each row in your Source objects contains less than 100 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Apr-29-2024 | NA | Updated section, Specify Amazon RDS SQL Server Connection Settings to include more detailed steps. |
| Mar-05-2024 | 2.21 | Added the Data Replication section. |
| Feb-27-2024 | NA | Updated sections, Create a user and Grant privileges to the user as per the latest Hevo functionality. |
| Jan-15-2024 | NA | Updated section, Limitations to add information about Hevo not supporting data replication from certain tables. |
| Jan-10-2024 | 2.19 | - Updated section, Enable Change Tracking to add a note about log retention duration. - Updated section, Object and Query Mode Settings as per the latest Hevo functionality. |
| Nov-03-2023 | NA | Added section, Object and Query Mode Settings. |
| Apr-21-2023 | NA | Updated section, Specify Amazon RDS SQL Server Connection Settings to add a note to inform users that all loaded Events are billable for Custom SQL mode-based Pipelines. |
| Mar-09-2023 | 2.09 | Updated section, Specify Amazon RDS SQL Server Connection Settings to mention about SEE MORE in the Select an Ingestion Mode section. |
| Dec-07-2022 | 2.03 | Updated section, Specify Amazon RDS SQL Server Connection Settings to mention about including skipped objects post-Pipeline creation. |
| Dec-07-2022 | 2.03 | Updated section, Specify Amazon RDS SQL Server Connection Settings to mention about the connectivity checker. |
| Apr-21-2022 | 1.86 | Updated section, Specify Amazon RDS SQL Server Connection Settings. |
| Feb-07-2022 | 1.81 | Updated section, Whitelist Hevo’s IP Address to remove details about Outbound rules as they are not required. |
| Jan-03-2022 | 1.79 | Updated the description of the Include New Tables in the Pipeline advance setting in the Specify Amazon RDS SQL Server Connection Settings section. |
| Sep-08-2021 | NA | Updated the second list item under Prerequisites and corrected the numbering of sections. |
| Jul-26-2021 | 1.68 | Added a note for the SQL Server Host field. |
| Jul-12-2021 | NA | Added section, Specify Amazon RDS SQL Server Connection Settings. |
| Mar-09-2021 | 1.58 | Replaced references to Logical Replication with Change Tracking as Change Tracking is a distinct Ingestion mode for SQL Server Source types. |
| Feb-22-2021 | 1.57 | Added section Create a User and Grant Privileges. |