Generic MongoDB
On This Page
After you select Generic MongoDB as the Source for creating the Pipeline, provide the connection settings and data replication details on the Configure your MongoDB Source page.
You can connect to the MongoDB database in one of the following ways:
-
By specifying the individual connection fields such as database host, database port, username, and password.
-
By entering the connection URI to connect to your MongoDB replica set or sharded cluster.
Connection URIs are of two types:
-
DNS Seedlist: This type of connection URI has the prefix
mongodb+srv://.For example,
mongodb+srv://<Jerome>:<Hevo123>@demo.westeros.net/.The
+srvpart indicates that the hostname corresponds to a DNS SRV record. The hostnames and port values for your MongoDB database are fetched from the DNS SRV record. -
Standard Connection String: This type of connection URI has the prefix
mongodb://. This contains a comma-separated list of host:port combinations.For example,
mongodb://Jerome:Hevo123@demo1.westeros.net:21275,demo2.westeros.net:21275/.In the above example,
Jeromeis the database user,Hevo123is the password for the database user,demo1.westeros.netis the IP address or hostname of the database, and21275is the database port.
-
Prerequisites
-
The MongoDB version is 3.6 or higher, up to 8.0.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo, to create the Pipeline.
Perform the following steps to configure your Generic MongoDB Source:
Set up MongoDB Replication for OpLog and Change Streams
Note: Hevo supports data ingestion from MongoDB via OpLog and Change Streams. Change Streams internally use OpLog for replication.
To set up replication for OpLog or Change Streams, perform the following steps:
-
Modify the MongoDB server configuration: MongoDB configuration file,
mongod.conf, is generally found in/etc/directory in a Linux system. The options to configure are as follow.-
replication.replSetName: The replica set this MongoDB is part of.
-
replication.oplogSizeMB: The maximum size of the log that MongoDB will retain. We recommend setting it to 2048 MB (2 GB) to maintain adequate capacity.
-
net.bindIp: The IP this MongoDB server should listen to.
An example config will look like as follows:
net: bindIp: 0.0.0.0 replication: replSetName: "repSet0" oplogSizeMB: 2048
-
-
Configure replication through MongoDB shell: Open your Mongo shell on the replication server and run the following commands:
-
rs.initiate(): This command will initialize the replica set.
-
rs.conf(): This command will show you the replication configuration that has been set.
-
rs.status(): This command will show you the replication status.
-
Set up Permissions to Read Generic MongoDB Databases
After configuring replication for the OpLog and Change Streams, grant read privileges to the database user to allow Hevo to access the local database and any other databases you want to replicate. To do this, perform the following steps:
-
Open the MongoDB shell.
-
Connect to your replica set or sharded cluster as an admin user.
-
Do one of the following:
Note: Replace the placeholder values in the command below with your own. For example, <database_username> with hevouser.
-
Run the following commands to create a user and grant
readprivileges:use admin db.createUser({ user: "<database_username>", pwd: "<password>", roles: [ "readAnyDatabase", { role: "read", db: "local" } ] }) -
Run the following commands to grant
readprivileges to an existing user:use admin db.grantRolesToUser( "<database_username>", [ "readAnyDatabase", { role: "read", db: "local" } ] )
-
Whitelist Hevo’s IP Addresses
In order to allow Hevo to access your MongoDB databases, you must whitelist Hevo’s IP addresses.
To do this, add the IP addresses to the list of authenticated IP Addresses/CIDR of your MongoDB instance by following these simple steps.
Configure Generic MongoDB Connection Settings
Perform the following steps to configure Generic MongoDB as a Source in Hevo:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select MongoDB.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Select Pipeline Mode page, choose the mode for ingesting data from the Source. Default value: OpLog.
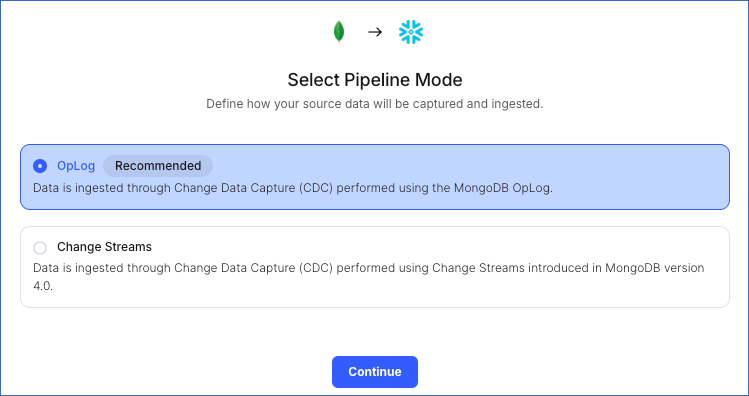
The following Pipeline modes are applicable to MongoDB Source:
-
OpLog: Data is ingested using MongoDB’s OpLog. The OpLog contains individual, transaction-level details which helps replicas sync data from the primary instance.
Note:
-
OpLogs are present in data or standalone primary instances and replicas.
-
OpLog mode is not supported for creating Pipelines with sharded clusters. To ingest data from such clusters, use Change Streams.
-
-
Change Streams: MongoDB’s Change Streams enables applications to stream real-time data changes without the complexity and risk of tailing the OpLog, for a single collection, a database, or an entire deployment. Change Streams are supported for all MongoDB configurations. However, for the clustered configuration, Change Streams works only if set up against a shard router (mongos).
By default, in both Change Streams and OpLog mode, the data is read at the mongo instance level. To read data at the database level in Change Streams mode, disable the Load All Databases option while creating the Pipeline.
-
-
Click Continue.
-
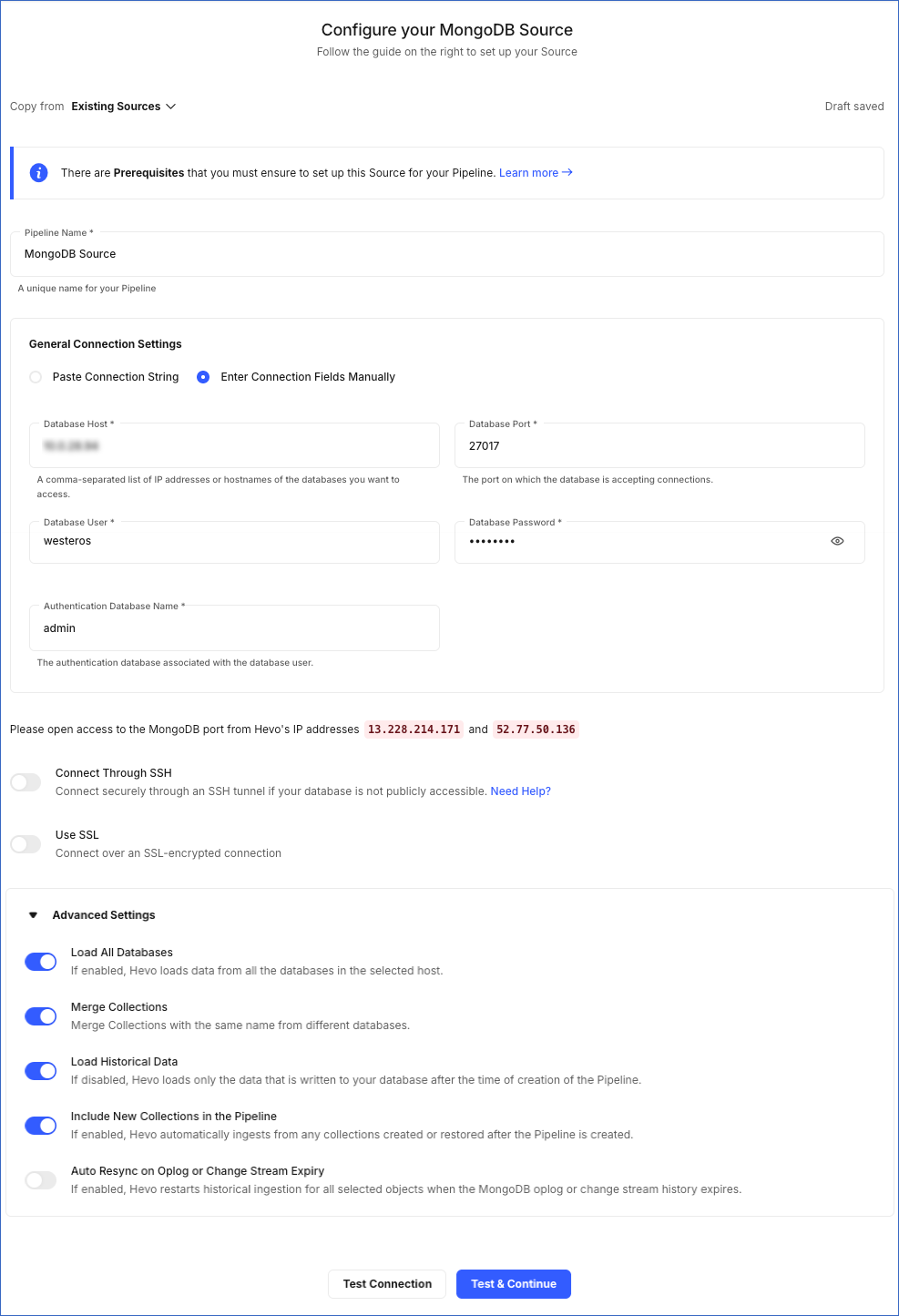
On the Configure your MongoDB Source page, specify the following:
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
General Connection Settings:
-
Paste Connection String:
-
Connection URI: The unique identifier for connecting to a MongoDB replica set or a sharded cluster.
Note: When connecting to a sharded cluster, you must enable the Use SSL option.
-
-
Enter Connection Fields Manually:
-
Database Host: IP address or hostname of the database you want to access. To specify multiple database hosts, provide a comma-separated list of all IPs or DNS names.
For example,
cluster0-shard-00-00.example.com, cluster0-shard-00-01.example.com, cluster0-shard-00-02.example.comis an example of a sharded cluster. Hevo always connects to a secondary instance.Note:
-
For URL-based hostnames, exclude the protocol part, for example,
mongodb://ormongodb+srv://. -
When connecting to a sharded cluster, you must enable the Use SSL option.
-
-
Database User: The authenticated user who has the permissions to read collections in your database. Read Set up permissions to read generic MongoDB databases.
-
Database Password: The password for the database user.
-
Database Port: The port on which your MongoDB server listens for connections. Default value: 27017.
-
-
-
Authentication Database Name: The database that stores the user’s information. The user name and password entered in the preceding steps are validated against this database. Default: admin.
-
Connect through SSH: Enable this option to connect to Hevo using an SSH tunnel, instead of directly connecting your MongoDB database host to Hevo. This provides an additional level of security to your MongoDB database by not exposing your MongoDB setup to the public. Read Connecting Through SSH.
If this option is disabled, you must whitelist Hevo’s IP addresses to allow Hevo to connect to your MongoDB host.
-
Use SSL: Enable this toggle option if you have enabled SSL at the MongoDB server end.
Note: You must enable this option if the Connection URI or Database Host field contains the hostname of a sharded cluster.
-
Advanced Settings:
-
Load All Databases: If enabled, Hevo fetches data from all the databases you have access to on the specified database host(s).
If disabled, Hevo fetches the list of all the databases you have access to on the specified database host(s). From this list, you must select the databases you want to fetch data from.
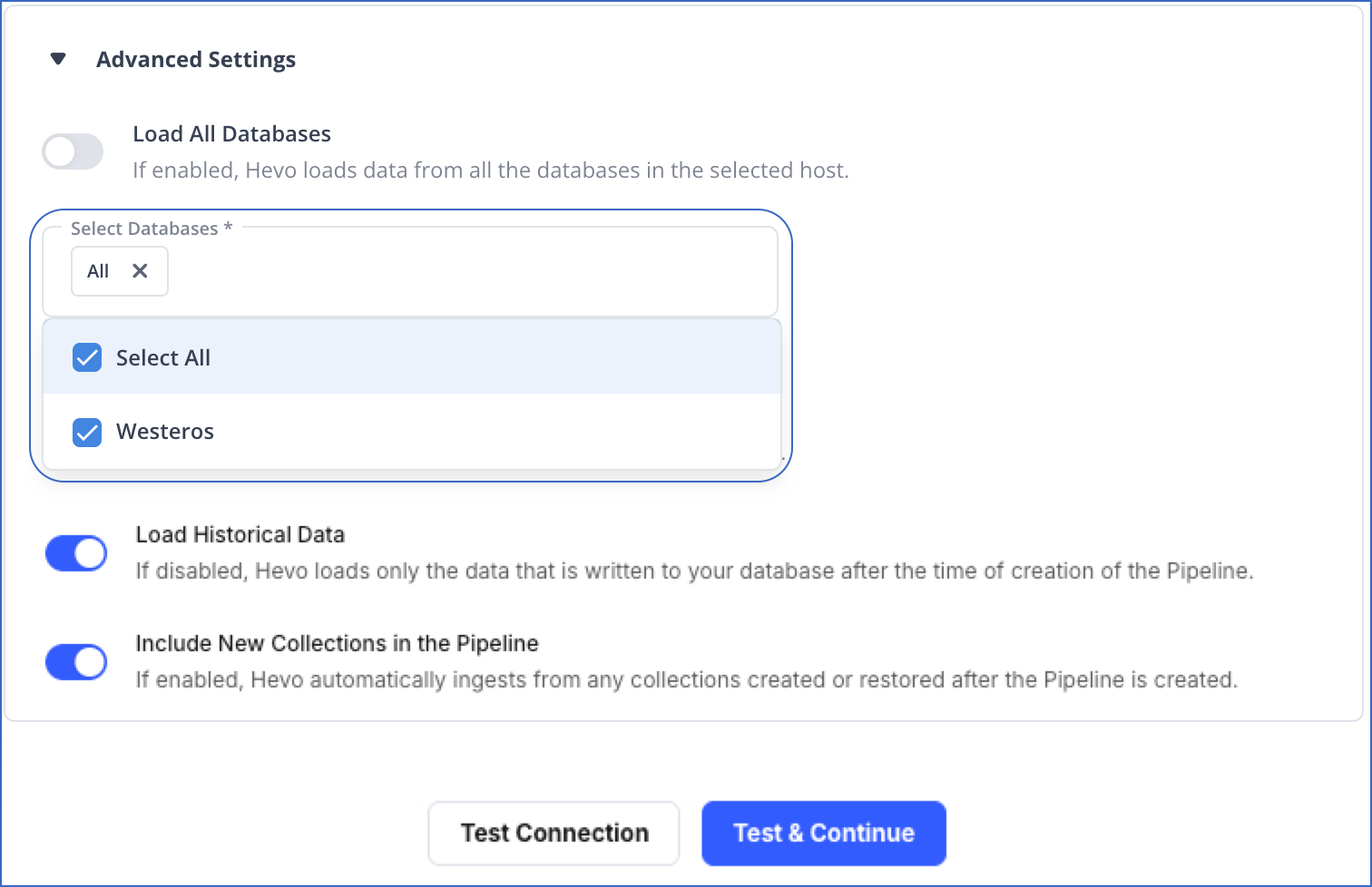
Warning! Once the Pipeline is created, if you drop any of these databases from your MongoDB Source, the Pipeline will fail.
-
Merge Collections: If enabled, collections with the same name across different databases are merged into a single Destination table. If disabled, separate tables are created and prefixed with the respective database name. Read Example - Merge Collections Feature.
-
Load Historical Data: If disabled, Hevo loads only the data that was written in your database after the time of the creation of the Pipeline. If enabled, the entire table data is fetched during the first run of the Pipeline.
-
Include New Tables in the Pipeline: If enabled, Hevo automatically ingests data from tables created in the Source after the Pipeline has been built. These may include completely new tables or previously deleted tables that have been re-created in the Source. All data for these tables is ingested using database logs, making it incremental.
If disabled, new and re-created tables are not ingested automatically. They are added in SKIPPED state in the objects list, on the Pipeline Overview page. You can update their status to INCLUDED to ingest data.
You can change this setting later.
-
Auto Resync on Oplog or Change Stream Expiry: If enabled, Hevo automatically restarts the historical load for all active objects when the Oplog or Change Stream expires. If disabled, Hevo displays an alert and requires manual intervention to resume. For more information on the OpLog expiry, read OpLog Alerts.
-
-
-
Click Test Connection. This button is enabled once you specify all the mandatory fields. Hevo’s underlying connectivity checker validates the connection settings you provide.
-
Click Test & Continue to proceed for setting up the Destination. This button is enabled once you specify all the mandatory fields.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 5 Mins | 5 Mins | 1 Hr | NA |
| After Release 2.21 | 30 Mins | 30 Mins | 12 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3 but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests all available data for the selected objects from your Source database.
-
Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Limitations
-
Hevo does not support configuring a standalone instance of MongoDB without a replica.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Feb-23-2026 | 2.46 | Updated section, Configure Generic MongoDB Connection Settings to add information about the option to automatically restart historical load after oplog expiry. |
| Feb-16-2026 | 2.46 | Updated sections, Configure Generic MongoDB Connection Settings to add a note about using change streams for sharded clusters and Set up Permissions to Read Generic MongoDB Databases to add commands for granting read privileges to existing users. |
| Nov-07-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configure Generic MongoDB Connection Settings as per the latest UI. |
| Aug-13-2025 | NA | Updated the Prerequisites section to add information about the minimum supported version of MongoDB. |
| Aug-1-2025 | NA | Added clarification that data ingested from new and re-created tables is billable. |
| Jul-10-2025 | NA | Updated the Prerequisites section to add information about the maximum supported version of MongoDB. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Nov-05-2024 | NA | Updated section, Configure Generic MongoDB Connection Settings as per the latest Hevo UI. |
| Oct-09-2024 | NA | Updated sections, Prerequisites and Set up Permissions to Read Generic MongoDB Databases to reflect that Hevo only supports MongoDB version 3.4 and higher. |
| Apr-29-2024 | NA | Updated section, Configure Generic MongoDB Connection Settings to include more detailed steps. |
| Mar-05-2024 | 2.21 | Added the Data Replication section. |
| Feb-02-2024 | NA | Updated section, Configure Generic MongoDB Connection Settings to add information about sharded clusters. |
| Mar-16-2023 | NA | Added a warning in the Advance Settings in section, Configure Generic MongoDB Connection Settings about dropping databases from the Source after the Pipeline is created. |
| Mar-09-2023 | 2.09 | Updated section, Configure Generic MongoDB Connection Settings to mention about SEE MORE in the Select an Ingestion Mode section. |
| Dec-19-2022 | 2.04 | Updated section, Configure Generic MongoDB Connection Settings to add information that you must specify all fields to create a Pipeline. |
| Dec-07-2022 | 2.03 | Updated section, Configure Generic MongoDB Connection Settings to mention about the connectivity checker. |
| Jul-12-2022 | 1.92 | Updated section, Configure Generic MongoDB Connection Settings to include information about the drop-down to select databases in the Load All Databases option. |
| Apr-21-2022 | 1.86 | Updated section, Configure Generic MongoDB Connection Settings. |
| Jul-12-2021 | 1.67 | Added the field Include New Tables in the Pipeline under Source configuration settings. |
| Jun-28-2021 | 1.66 | - Updated the page overview section. - Updated the section Set up Permissions to Read Generic MongoDB Databases to include latest commands. - Updated the section Configure Generic MongoDB Connection Settings to include the option to connect to the MongoDB database using connection string. - Added section, Limitations. |