Zendesk
On This Page
From Release 2.26, Hevo supports a new version of the Zendesk Source that uses a cursor-based pagination strategy. We recommend that you upgrade your Pipelines created before Release 1.95 to the new version by August 31, 2024, failing which the Pipelines will be paused. Refer to section, Migrating Pipelines to Upgraded Zendesk Source to know about the updates in objects and the steps to upgrade the Pipeline.
You can load the data of your Zendesk tickets and user information into the Destination of your choice using Hevo Pipelines.
Prerequisites
-
You are an Administrator in Zendesk to access your data through APIs.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Generating a Zendesk API Token
You require an API token to authenticate Hevo on your Zendesk account.
Note: You must log in as an Administrator to perform these steps.
To generate the API token:
-
Log in to your Zendesk Admin Center (https://<your sub-domain name>/admin/home).
-
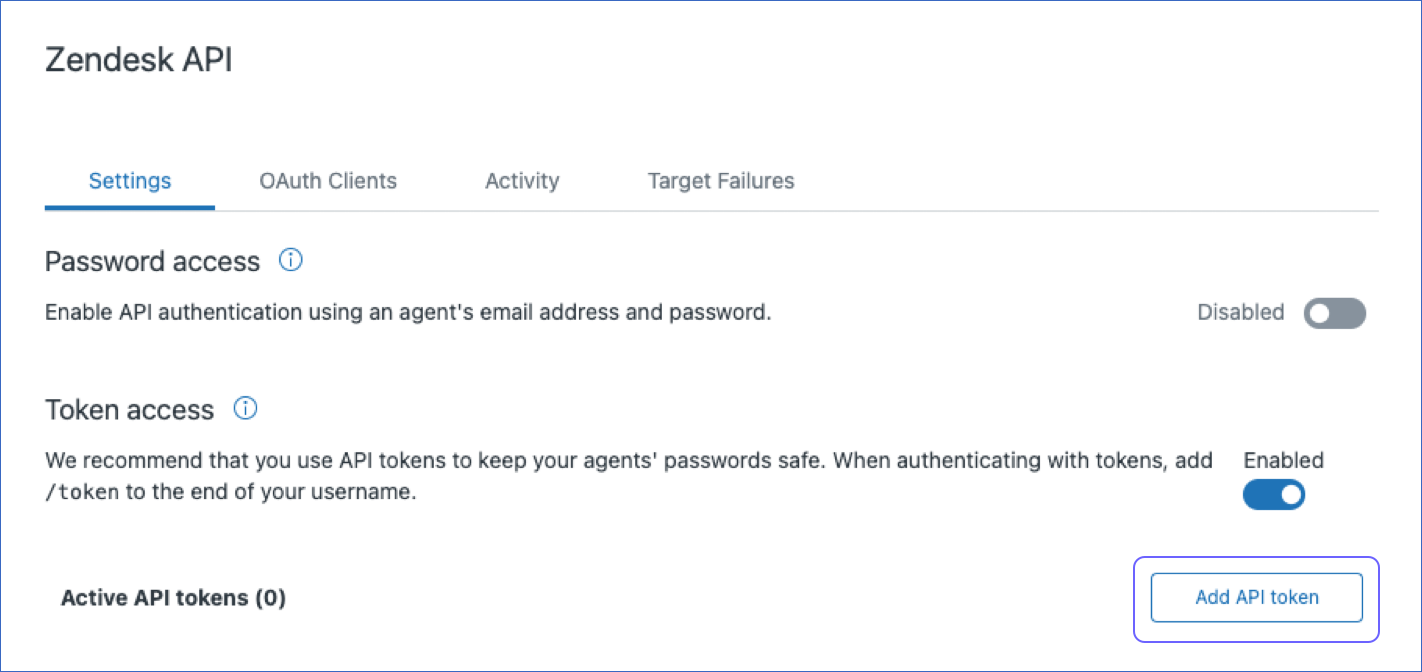
In the left navigation pane, click the Apps and integrations (
 ) icon, and select APIs > Zendesk API.
) icon, and select APIs > Zendesk API. -
From the Settings tab, enable Token access.
-
Click Add API token to generate a new API token.
-
Copy the API token and save it securely like any other password. Use this token while configuring your Hevo Pipeline. For more details, read the Zendesk documentation.
Note: If you are re-generating the API token, you must update it in the Pipeline Source settings. Read Modifying the Source and Destination Configuration for information on how to edit the Source settings in an existing Pipeline.
Configuring Zendesk as a Source
Perform the following steps to configure Zendesk as a Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
In the Select Source Type page, select Zendesk as the Source.
-
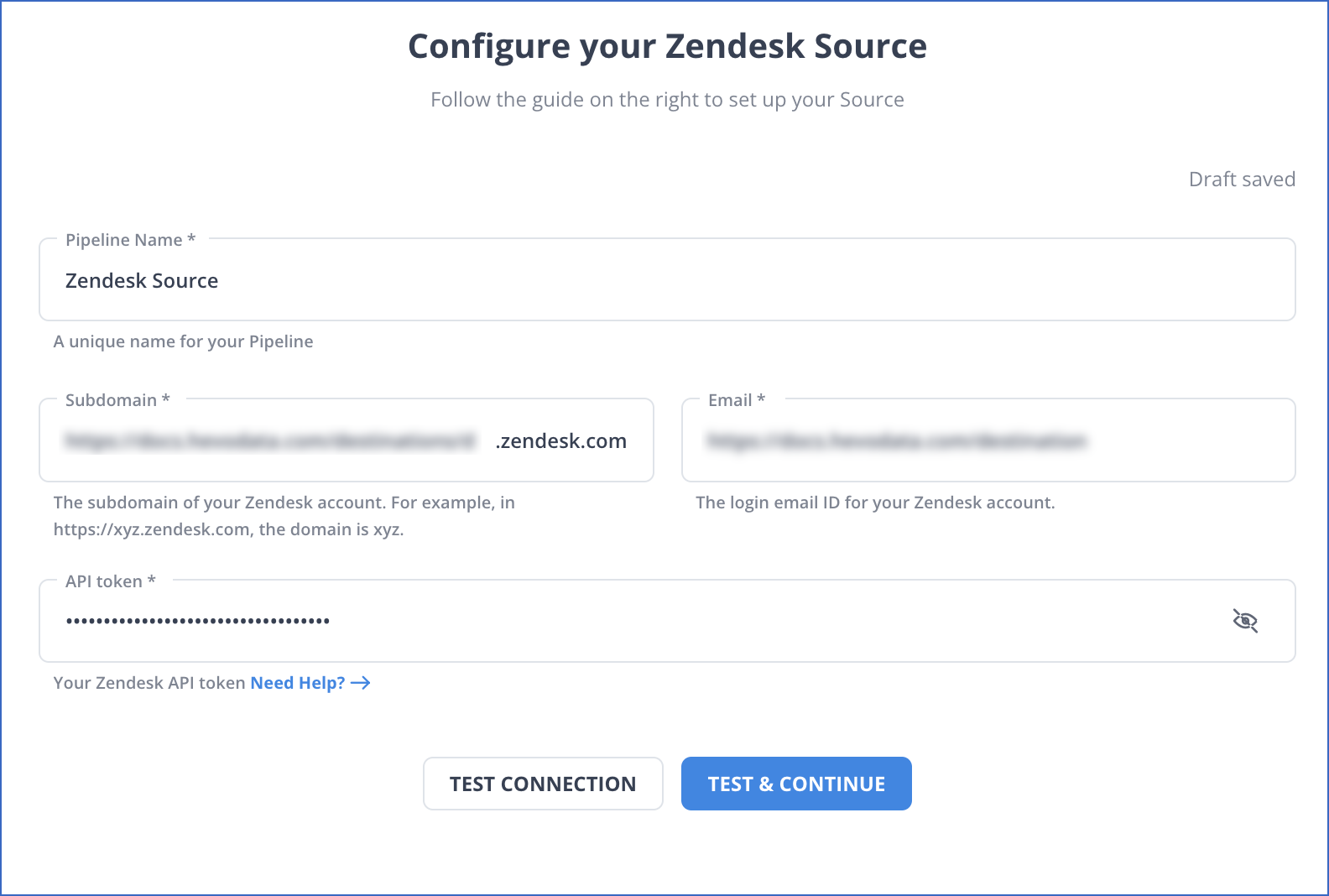
In the Configure your Zendesk Source page, provide the following information:
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Sub Domain: Your Zendesk sub-domain.
-
Email: Your login email ID for Zendesk.
-
Token: The API token that you obtained from your Zendesk account.
-
-
Click TEST & CONTINUE.
-
Proceed to configuring the data ingestion and setting up the Destination.
Migrating Pipelines to Upgraded Zendesk Source
From Release 2.26, Hevo supports an improved version of the Zendesk Source that uses a cursor-based pagination strategy. As a part of this upgrade, Hevo supports the following updates made to the relevant objects:
Updates to existing objects
| Objects | Changes |
|---|---|
| Tickets | - Addition of fields action, aricall_id, batch_course, booking_status, clinic, clinician, connection_date, disconnection_date, from_email, lead_id, mirakl_thread_id, order, order_id, product_ref, referral_code, referral_date, referral_status, speciality, state, and ticket_original. - Deletion of fields account_name, account_owner, account_segmentation, approved_for_on_call, arr_impact_by_cxm, assignee_name, assisted_by, auto_solved, bank, bank_name, category_group, closure_type, competition_involved, component, conversation_closed_at, conversation_type, customer_escalated, customer_plan, customer_tier, deal_size, destination, destinations, dev_workaround, document_link, documentation, env, fix_version, identified_by, impact, intercom, intercom_tags, investigation_estimation, is_jira_associated, is_merged, is_production_pipe, Issue Resolution, Issue Summary, issue_category, issue_reason, issue_resolution, issue_type, jira_key, jira_priority, jira_status, kb_link, kb_present, merchant, oncall_priority, orderId, pipeline_number, premium_customer, proactive_ticket, product_vertical, reason_for_raising_the_ticket, reason_for_reopen, Resolution provided, resolution_type, reviewed_by, Root Cause, satisfaction_probability, scope_version, sent_for_review, server, Severity, solve_type, solved_at, sop_available, sop_location, sop_present, source, sources, ticket_category, ticket_was_escalated_to_rnd_investigation, tier, time_spent_last_update_sec, and total_time_spent_sec. |
| Ticket Metrics (child object of Tickets) | - Not available for selection from the Object Listing page as it is a child object of Tickets. If you include the Tickets object for ingestion, this object is also ingested. - Addition of fields agent_wait_time_in_minutes, first_resolution_time_in_minutes, full_resolution_time_in_minutes, on_hold_time_in_minutes, and requester_wait_time_in_minutes. - Deletion of fields agent_wait_hours, agent_wait_mins, first_reply_in_minutes, first_resolution_hours, first_resolution_mins, full_resolution_hours, full_resolution_mins, on_hold_hours, on_hold_mins, requester_wait_hours, and requester_wait_mins. |
| Users | Deletion of fields user_created_at and user_updated_at. |
Addition of new objects
| Objects |
|---|
| Addresses |
| Articles |
| Greetings |
| IVRs |
| Lines |
| Posts |
| Topics |
Refer to section, Data Model for a detailed description of these objects.
Note: Hevo ingests the new objects by default in the existing Pipelines. You can skip them from the Pipeline Detailed View, if required.
You can migrate your Pipeline to the upgraded version of the Zendesk Source by performing the following steps:
-
Click PIPELINES in the Navigation Bar.
-
Search for and click the Zendesk Pipeline that you want to upgrade.
-
In the banner displayed on the Pipeline Overview page, click UPGRADE PIPELINE.

-
In the confirmation dialog, click YES, UPGRADE PIPELINE.
You have successfully upgraded the Pipeline.

After the Pipeline upgrade, Hevo restarts the historical load for the following objects if they were Active and their historical load was either completed or in progress in the existing Pipeline:
-
Tickets
-
Ticket Events
-
Organizations
-
Users
-
Satisfaction Ratings
-
Calls
-
Legs
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 12 Hrs | 5 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 12 Hrs | 30 Mins | 24 Hrs | 1-24 |
-
Historical Data: In the first run of the Pipeline, Hevo ingests the data of the past one year for all the selected objects in your Zendesk account. From Release 1.76 onwards, for all existing and new Pipelines, Hevo ingests your historical data using the Recent Data First approach. This enables you to have quicker access to the most recent data.
-
Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency in Full Load or Incremental mode, as mentioned in the table below.
Custom frequency for Full Load objects
Hevo allows you to set the ingestion frequency for Full Load objects separately from the Pipeline ingestion frequency. You can reduce your Events quota consumption by ingesting Full Load objects at a lower frequency without affecting other objects in the Pipeline. Read Query Modes and Events Quota Consumption to know how different query modes affect your Events quota consumption.
You can identify the Full Load objects in the Pipelines Detailed View by the FL tag corresponding to their name. Alternatively, you can view only Full Load objects in your Pipeline by selecting Full Load from the Filter ( ![]() ) menu.
) menu.

Perform the following steps to set a custom ingestion frequency for Full Load objects:
-
In the Pipelines Detailed View, click the More (
 ) icon to open the Pipeline’s Action menu and click Change Schedule.
) icon to open the Pipeline’s Action menu and click Change Schedule.
-
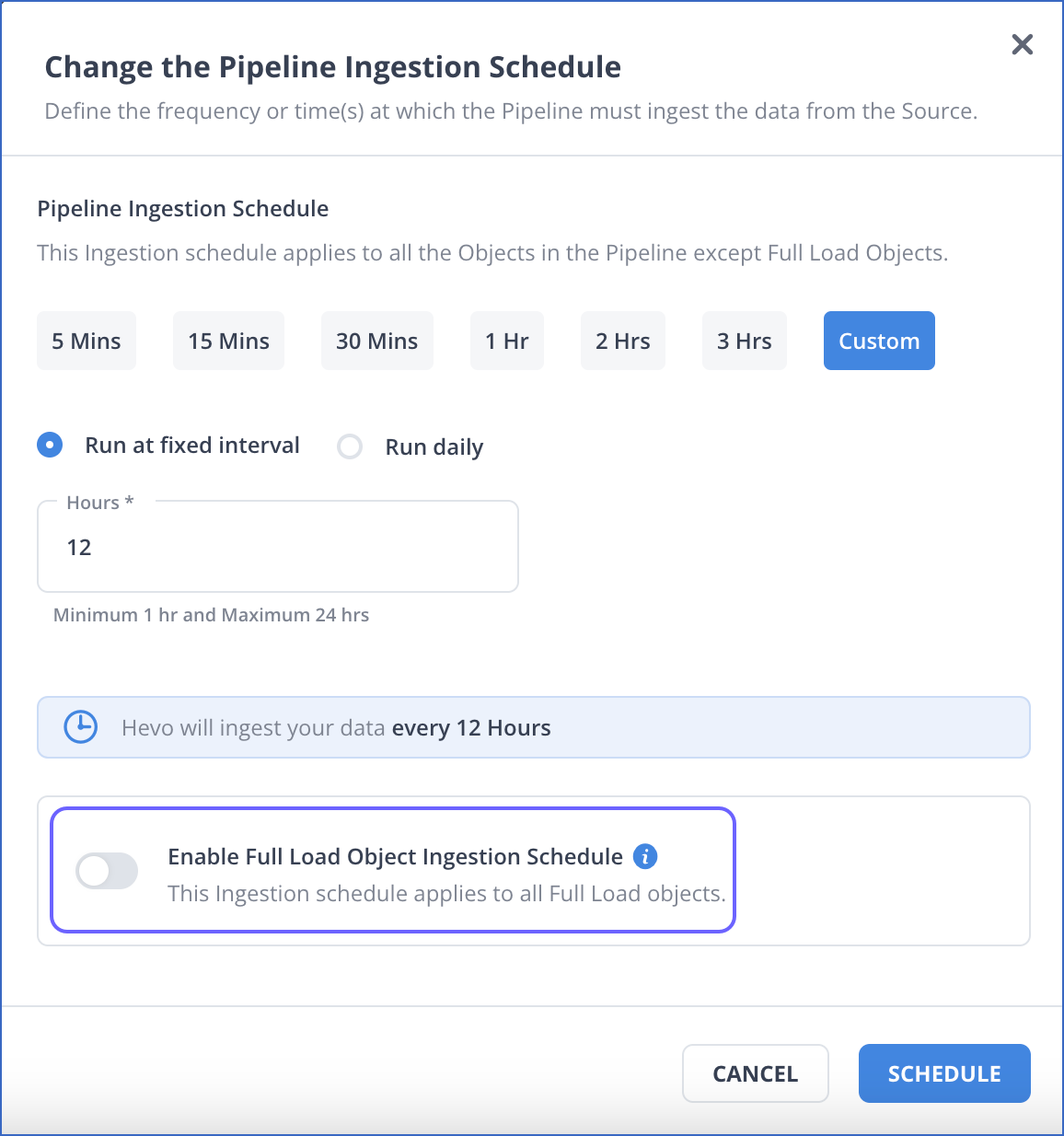
In the Change the Pipeline Ingestion Schedule pop-up window, enable the Enable Full Load Object Ingestion Schedule option.
Note:
- For custom frequency, this option is available only when Run at fixed interval is selected.
- If your Pipeline ingests data from Full Load objects on an independent schedule, manual actions such as Run Now and Restart Object are automatically deferred to the next ingestion schedule. To run any of these actions immediately, turn off the Full Load Object Ingestion Schedule option, trigger the required action, and then re-enable the schedule.
-
Select the ingestion frequency for the Full Load objects as per your requirements. You can select Custom and define the ingestion frequency by specifying an integer value in hours.
Note: Full Load objects can be ingested at a frequency more than or equal to the Pipeline’s ingestion frequency.

-
Click SCHEDULE.
The updated schedule is applied immediately.
Data Model
Hevo supports the Zendesk Support, Talk, and Help Centre APIs for fetching data for various objects.
Using the Zendesk Support API, the following tables (objects) are created in the Destination when you run the Pipeline:
| Objects | Mode | Description |
|---|---|---|
| Brands | Full Load | Contains details of the customer-facing identities (URLs) of your company. |
| Custom Roles | Full Load | Contains details of the custom roles created for your Support agents and the access that these roles have. For example, you can create a role Contributor and assign it to agents who can make only internal comments on a ticket. |
| Groups | Full Load | Contains details of the groups into which your agents and tickets can be organized. |
| Group Memberships | Full Load | Contains details of the groups to which an agent is linked. |
| Organizations | Incremental | Contains details of the organizations into which your customers are segregated, to route tickets created by them for better support. |
| Organization Memberships | Full Load | Contains details of the organization of which your user(s) is a member. |
| Satisfaction Ratings | Incremental | Contains details of the feedback given by your customers about their experience with your Support team by rating their solved tickets. |
| Schedules | Full Load | Contains details of the schedules that you have created to indicate your Support team’s availability. |
| SLA Policies | Full Load | Contains details of the service level agreement between you and your customers that specifies performance measures for support. For example, the SLA for urgent tickets could be to respond within 10 minutes and resolve or mitigate the ticket within 2 hours. |
| Tickets | Incremental | Contains details of the communication between your customers and your Support agents. |
| Ticket Events | Incremental | Contains details such as response times, agent work times, and requester wait times. |
| Ticket Fields | Full Load | Contains details of the ticket, such as requester or assignee. |
| Ticket Forms | Full Load | Contains details of the collection of ticket fields that are visible to the Support agent as well as the end-user. |
| Users | Incremental | Contains details of your Zendesk Support users based on their type: - End Users: Your customers who request support using tickets. - Agents: Your Zendesk Support agents who resolve customer tickets. - Administrators: Your Zendesk Support agents with administrative abilities. |
Using the Zendesk Talk API, the following tables (objects) are created in the Destination when you run the Pipeline:
| Objects | Mode | Description |
|---|---|---|
| Addresses | Full Load | Contains details of addresses associated with a profile. They are often used to verify a business while purchasing Talk phone numbers in certain countries to meet regulatory requirements. |
| Calls | Incremental | Contains details of the calls received or made to/from your Talk number. |
| Greetings | Full Load | Contains details of the recorded messages used to greet customers when they contact support via phone or chat. These can be either default Zendesk greetings or custom ones. |
| IVRs | Full Load | Contains details of the keypad tones or voice commands used to direct customers to an agent or department, provide recorded responses to FAQs, and deflect calls from users by switching interactions to text. These tones and commands are part of Zendesk’s Interactive Voice Response (IVR) automated phone system. |
| Legs | Incremental | Contains details of the interaction between your agent and customer during a call, or any action the system took on the call. |
| Lines | Full Load | Contains details of the available phone numbers and virtual phone lines in your Zendesk account. |
Using the Zendesk Help Center API, the following tables (objects) are created in the Destination when you run the Pipeline:
| Objects | Mode | Description |
|---|---|---|
| Articles | Incremental | Contains details of the content items such as help topics or technical notes included in sections. |
| Posts | Full Load | Contains details of the content, such as posts, post comments, or article comments, shared by a user with the community. |
| Topics | Full Load | Contains details of a collection of community posts on a subject or theme. |
Limitations
- Hevo does not load an Event into the Destination table if its size exceeds 128 MB, which may lead to discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each row in your Source objects contains less than 100 MB of data.
See Also
- Metrics and attributes for Zendesk Talk
- Zendesk Incremental Export API
- Zendesk Talk Incremental Export API
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| May-22-2025 | NA | Updated section, Custom frequency for Full Load objects to add a note about the behavior of manual ingestion actions. |
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Jul-29-2024 | 2.26 | - Added section, Migrating Pipelines to Upgraded Zendesk Source. - Updated section, Data Model to add information about new objects. |
| Jul-15-2024 | 2.25.2 | Updated section, Data Replication to change the default ingestion frequency to 12 Hrs. |
| Mar-05-2024 | 2.21 | - Updated the ingestion frequency table in the Data Replication section. - Updated the Custom frequency for Full Load objects section with suggested frequencies for teams before and after Release 2.21. |
| Nov-28-2023 | 2.18 | Added section, Custom frequency for Full Load objects to inform users about the option to change ingestion frequency for Full Load objects. |
| Dec-14-2022 | NA | Updated section, Configuring Zendesk as a Source to reflect the latest Hevo UI. |
| Dec-07-2022 | NA | Updated section, Data Replication to reorganize the content for better understanding and coherence. |
| Jul-12-2022 | NA | Updated section, Data Model to segregate objects according to the API they belong to. |
| May-10-2022 | NA | Updated the steps to generate the Zendesk API Token. |
| Feb-07-2022 | 1.81 | - Organized content for clarity and coherence. - Added section, Data Model and included the Zendesk Voice objects, calls, and legs that are supported from Release 1.81 onwards. |
| Jan-07-2022 | 1.76 | Added information about reverse historical load in the Data Replication section. |
| Oct-25-2021 | 1.74 | - Updated the Data Replication section with information about the list of objects that Hevo fetches and the historical and incremental data load. - Added the Pipeline frequency information in the Data Replication section. |