Data Flow in a Pipeline
On This Page
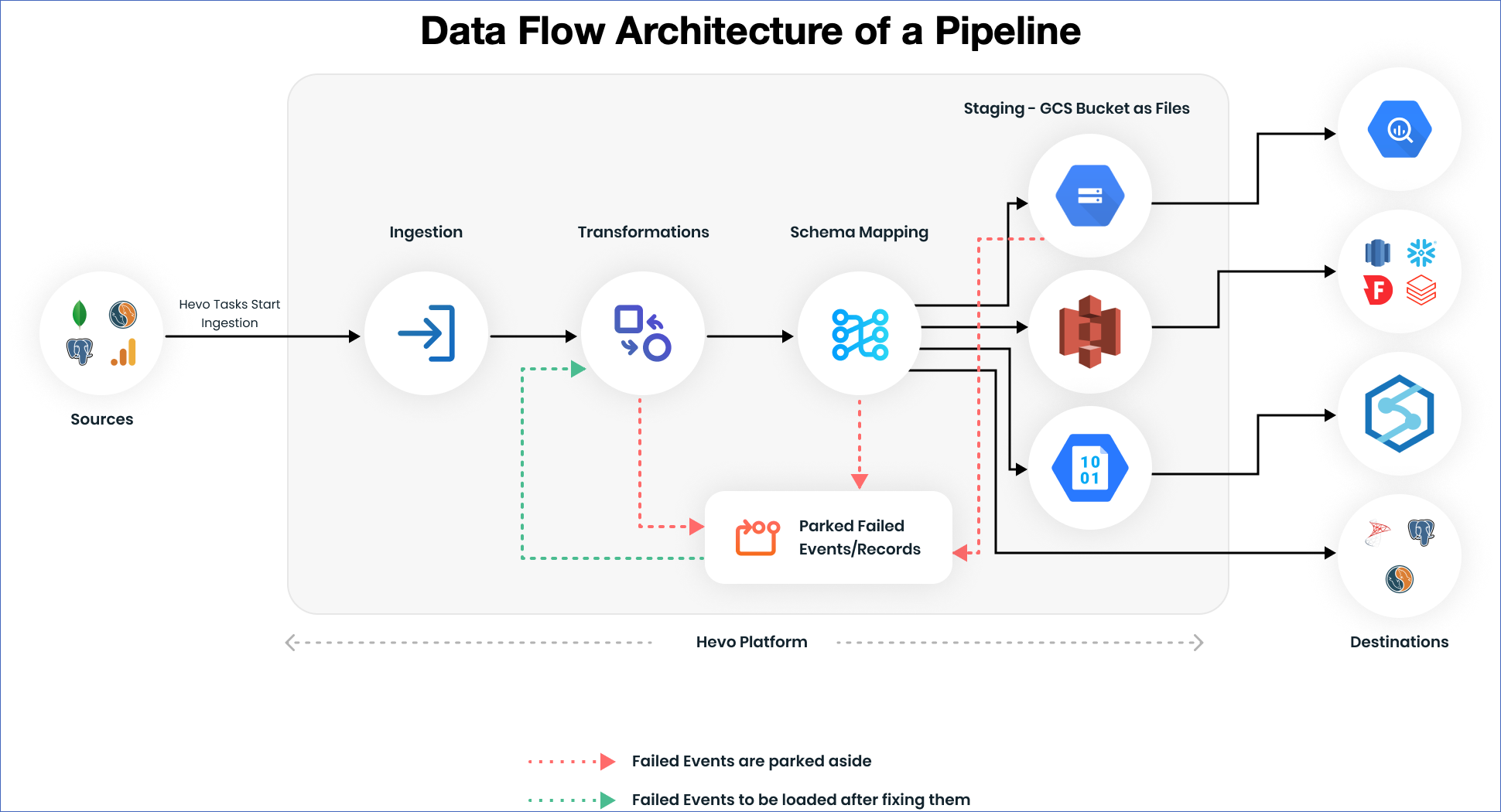
Hevo Pipelines extract data from a Source, transform or cleanse the data, and then, load it to a Destination. In this process, the data goes through the following stages:
Stage 1: Establishing a connection
Hevo initiates the replication process by establishing a connection with the Source successfully. Based on the nature of the Source, Hevo either uses REST API or appropriate drivers to establish the connection.
Stage 2: Ingestion
Tasks to ingest the data are created for each Source object. This stage is referred to as Ingestion. In the case of databases with log-based replication, such as MySQL and PostgreSQL, a task is created to sync the historical load and another task to Capture Data Change (CDC). Read Types of Data Synchronization to understand how Hevo performs this task. From here, data is streamed across other stages discussed below. You can adjust the ingestion rate by adjusting the ingestion frequency from the UI, based on the Source.
Stage 3: Transformations
You can transform the data that is streaming before loading it to the Destination. You can write Python scripts or use drag-and-drop Transformation blocks to do the same. After the Transformation script is deployed, every Event (Row) that gets ingested goes through the Transformation. Read Transformations.
Stage 4: Schema mapping
Hevo ingests your data from Sources, applies Transformations on it, and brings it to the Schema Mapper. In the Schema Mapper, you can define how the data is mapped in the Destination. You can map the tables and columns, omit columns, or skip loading the data to a table in the Destination. Hevo can automatically create and manage all these mappings for you if you enable Auto Mapping for a Pipeline. Based on the configurations applied in this stage, the data from the Source is mapped to the data in the Destination.
Stage 5: Staging data in intermediate storage locations
In the case of JDBC Destinations, such as MySQL, PostgreSQL, and MS SQL Server, the data is directly loaded to the Destination tables from the Schema Mapper phase.
For data warehouse Destinations, once the data is mapped, it is stored in a temporary staging area as CSV or JSON files. This staging area is a GCS bucket in the case of Google BigQuery Destinations, an AWS S3 bucket in the case of data warehouse Destinations, such as AWS Redshift, Snowflake, and Databricks, and an Azure Blob Storage container in the case of Azure Synapse Analytics Destinations. Once the data is loaded to the Destination tables from the staging area, it is cleared or deleted from the staging area.
Stage 6: Loading data
-
Loading to AWS Redshift, Snowflake, and Databricks: Data is loaded to Redshift, Databricks, or Snowflake from the S3 bucket in batches. Data is deduplicated using the value of the primary key and copied to an intermediate S3 staging table from where it is loaded to the Destination table. Read Loading Data to a Data Warehouse for details about how data is loaded to the Destination tables from an S3 bucket.
-
Loading to Google BigQuery: Data is loaded to BigQuery from the GCS bucket in batches. Data is deduplicated and loaded to an intermediate BigQuery staging table before loading it to the Destination table. The Merge SQL statement is used, which handles all three operations of deletions, insertions, and updates through a single query. This makes the operation faster and atomic, and you have a consistent view of the data. Read Loading Data to a Google BigQuery Data Warehouse for details about how data is loaded to BigQuery tables from a GCS bucket.
-
Loading to PostgreSQL, MS SQL Server, MySQL: Data is replicated from the Schema Mapper based on the primary keys defined in the Destination table. Here, data is not staged in S3/GCS buckets and is bulk inserted directly to the Destination. As part of loading the data, deduplication is done to ensure that unique records are replicated and duplicates are dropped. This deduplication is done using the value of the primary key. It is recommended not to use these databases as a Destination if the volume of data is high, as they do not perform well while ingesting a huge volume of data. Read Loading Data in a Database Destination for details about how data is loaded to the database.
-
Loading to Azure Synapse Analytics: Data is loaded to the Azure Synapse Analytics data warehouse from Azure Blob Storage (ABS) in batches. Data is deduplicated using a primary key and copied to an intermediate ABS container, from where it is loaded to the Destination table. Read Loading Data to a Data Warehouse for details about how data is loaded to the Destination tables from an ABS container.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Mar-10-2023 | NA | - Renamed the subsections, Stage 5: Staging in GCS/S3 bucket to Stage 5: Staging data in intermediate storage locations and Stage 6: Loading to Stage 6: Loading data, - Added information for Azure Synapse Analytics to Stage 5 and Stage 6. |
| Jul-27-2022 | NA | Updated the content in Stage 5: Staging in GCS/S3 bucket for clarity and coherence. |
| Mar-21-2022 | NA | New document. |