Hevo Pipeline Framework
On This Page
The Hevo Pipeline is broadly the Source, the Hevo platform, and the Destination. Read Sources and Destinations to know about the Sources and Destinations that Hevo supports. The key players that form the Hevo platform are the Connectors, the Hevo Event Stream, and the Consumers.
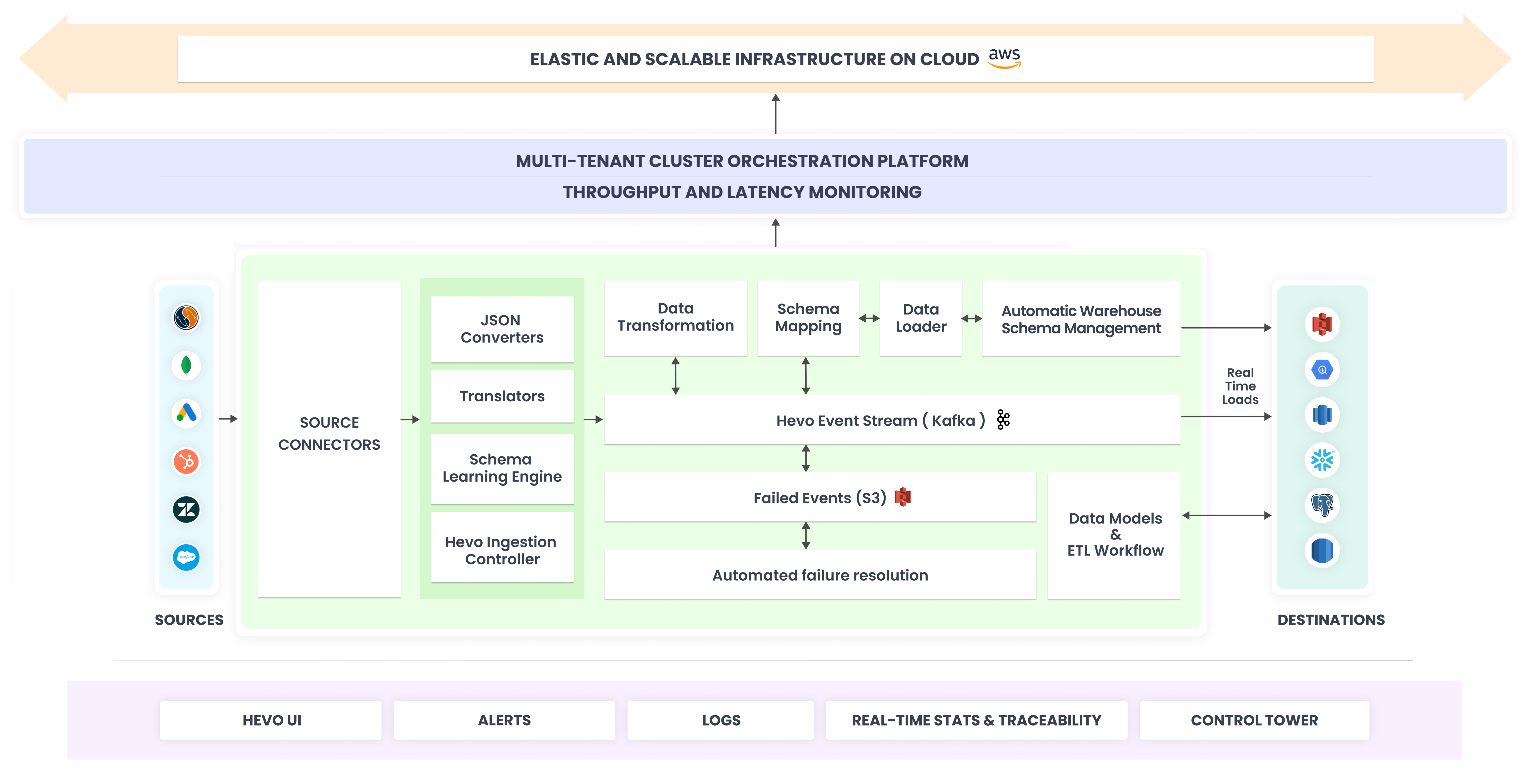
We shall understand the working of the Hevo platform in this section.
Connectors
Connectors are the systems that interact with your Source Type. The Source Type is the application or database where your data lies. For example, if your data exists in a MySQL database, then your Source Type is MySQL. The Connectors typically use the SDKs provided by the Source or are developed in-house by Hevo. However, some Connectors are a combination of the Source SDKs and in-house components.
The Connector of each Source Type identifies the objects to be ingested, polls the Source to capture data changes, and identifies when to read data from the Source. They run at a fixed frequency on worker tasks that the Pipeline scheduler creates.
The data ingested by the Connectors is acted upon by the following:
-
JSON Converters: The ingested data is parsed as per the JSON parsing strategy you select while configuring your Destination in Hevo.
-
Translators: The parsed data is translated to the Hevo standardized format, which is a Hevo Record or Event. The Event contains information about the Source schema, the data values, and some metadata columns that Hevo creates and uses to deduplicate the data before loading. Read Hevo-generated Metadata to know about the information contained in the metadata columns of an Event.
Note: Hevo drops an Event if its size exceeds 40 MB.
-
Schema Learning Engine: This component creates the schema to be mapped in the Destination. The schema is learned from the ingested data and the metadata information provided by the Source.
-
Hevo Ingestion Controller: The controller monitors and keeps track of the API rate limits, the offset for the next data read in the case of incremental data, and so on.
The Connector then submits the ingested data to the Event queuing and streaming system, the Hevo Event Stream.
Pipeline tasks
All activities performed by the Connectors to ingest data from a Source are achieved through background tasks. Tasks are individual units of work within a Pipeline. These are created, scheduled, processed, and monitored periodically by Hevo’s distributed task manager. The task manager constitutes:
-
A coordinator process: This process is responsible for auto-scaling the system. It monitors the tasks queue and takes necessary actions. For example, adding more workers when the number of tasks waiting to be processed exceeds a threshold value.
-
A set of workers: The worker processes are grouped into pools and each available worker picks up a task from the queue.
-
An overseer process: This process creates the necessary tasks and queues them. It also monitors the health of the worker pool.
Hevo Event Stream
The Hevo Event stream component is built on Kafka, and Events are streamed via Kafka from the Source to the Destination. All the ingested data, after it is converted to Events, is loaded to Kafka topics located on different Kafka brokers inside a Kafka cluster. Events are retained in the Kafka topics until they are consumed to be written to the Destination. The topics containing the Events are replicated on multiple brokers to make them fault-tolerant and highly available, thus preventing data loss in case of any broker failures.
The Kafka topic into which the Events are loaded depends on the Destination for the corresponding Pipeline. The topics are segregated based on:
-
The quality or eccentricity of the data being ingested.
-
The Destination type and the way the data is loaded to the Destination, whether in batches or in real-time.
All Events that are pushed to Kafka topics are processed upon by the Consumers and prepared for loading to the Destination. To protect the customers’ data and ensure privacy, Events are segregated as per the customers.
Consumers
Consumers are continuously running processes that interact with Kafka topics containing the ingested data. As a part of the consumption process, Hevo validates the Events (Validation phase), runs Transformations on them (Transformation phase), maps them to the Destination format (Schema Mapping phase), and creates sinks for them, from where the Events are loaded to the Destination (Sink or Loading phase). In the consumption process, the Consumer tasks perform the following operations on the data:
-
Transformation: The data is prepared for loading to the Destination. The data is also cleansed, filtered, enriched, or normalized based on the logic defined in the Transformation scripts, only if the user has created Transformations. Read Transformations.
-
Mapping and Promoting: The data is mapped and translated as per the Destination schema and the existing data in the Destination tables. Any data type promotion is also handled here.
-
Managing Schema: Changes that a user might make to the Destination schema is detected and synced back to Hevo. For example, if a table is deleted in the Destination, Hevo automatically detects this change. In subsequent Pipeline runs, it moves the Events meant for the deleted table to the Failed Events queue.
-
Formatting and Storing: The data is formatted as per the Destination schema and then written to files in cloud storage, which is an S3 or GCS bucket. Read Data Types.
For data warehouse Destinations, where data is loaded as per the loading frequency, data is read from the staging location in batches and loaded. In the case of database Destinations, where data is loaded in real-time, data is loaded directly from the Hevo Event Stream. However, if the loading throughput is not high enough to keep up with the ingested Event stream, data is first aggregated to files in Hevo’s S3 bucket to achieve micro-batching, and then loaded to the Destination. Read Ingestion and Loading Frequency.
Handling failed Events
In the case of failures in any phase of the consumption process, the related Events are moved to a Failed Events queue, which uses an encrypted file storage system for persistence. Here, Hevo attempts to automatically resolve the failures and load the Events to the Destination. If Hevo requires inputs to resolve the failures, for example, a correction in the Transformation script, the Events are maintained in the Failed Events queue for 7 days. To prevent any loss of data, these failures should be resolved by users within that period. Read Failed Events in a Pipeline.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jul-07-2025 | NA | Updated the note in the Connectors section about limit on Event size. |
| Jan-07-2025 | NA | Added a note in the Connectors section about a limit on the Event size. |
| Jul-17-2023 | NA | Updated the screenshot to reflect supported functionality. |
| Mar-21-2022 | NA | New document. |