Google Analytics 360
On This Page
Google Analytics 360 (GA 360) is a marketing analytics platform that helps you obtain actionable insights from your data. You can retrieve the GA 360 data in two forms:
-
Unsampled reports in dashboard.
-
Unsampled event level data that you can export to a Google BigQuery project using the BigQuery Export feature. For this, you must link your GA 360 account to a Google BigQuery (BigQuery) project. The data is stored in tables within datasets that reside in the BigQuery project.
Hevo uses the BigQuery API to read the data exported to BigQuery tables and replicate it to a Destination system of your choice.
Prerequisites
-
An active Google Analytics 360 (GA 360) account from which data is to be ingested exists.
-
A BigQuery project is created to load your GA 360 data.
-
BigQuery Data Viewerprivilege is granted to the Google account used to authenticate the GA 360 account. -
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Creating your BigQuery Project
You need to link your GA 360 account to the BigQuery project where you want to export the data. To create your BigQuery project, you need to have a Google Cloud project with BigQuery API enabled. To do this:
1. Create a Google Cloud project
Note: Skip this step if you want to use an existing Google Cloud project.
-
Log in to the Google Cloud Console.
-
Click the Select from (
 ) icon at the top of the page and click NEW PROJECT.
) icon at the top of the page and click NEW PROJECT.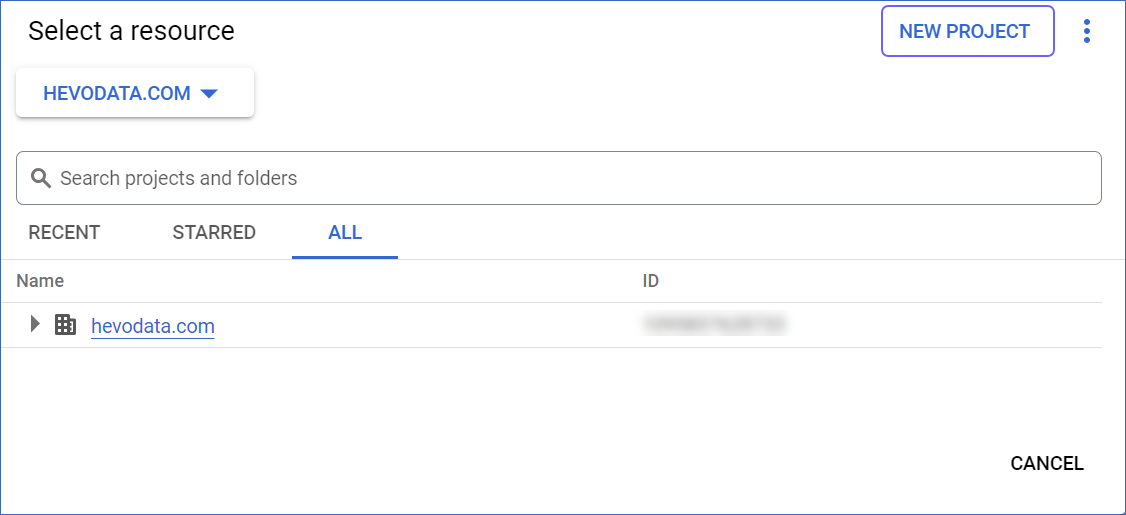
-
On the New Project page, specify the following:
-
Project name: A unique name for your project.
-
Organization: The organization to attach to your project.
-
Location: The parent organization or folder for your project.
-
-
Click CREATE.
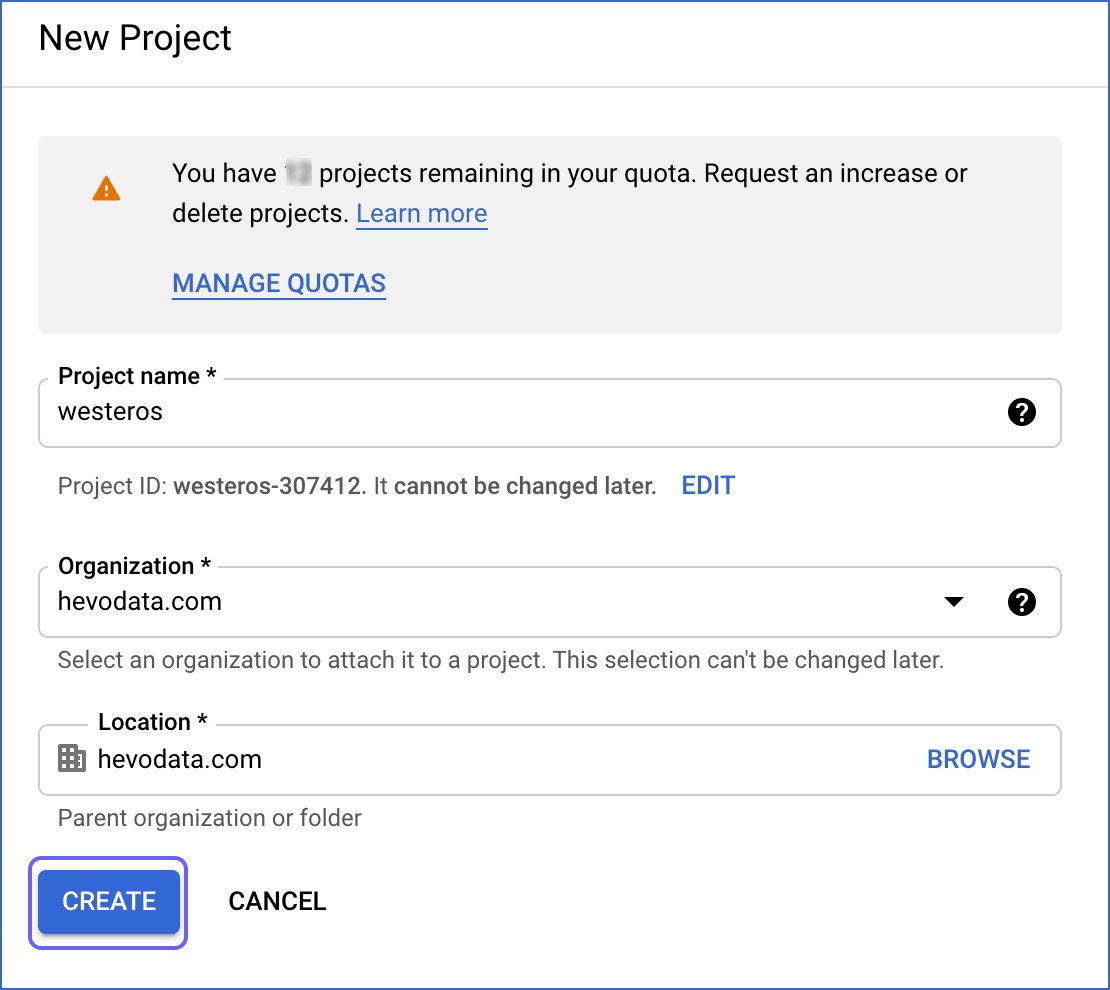
This creates a Google Cloud project.
2. Enable the BigQuery API
Note: Skip this step if you already have the BigQuery API enabled for your organization.
-
Log in to the Google Cloud Console.
-
In the left navigation menu, click APIs & Services, and then, click Library.
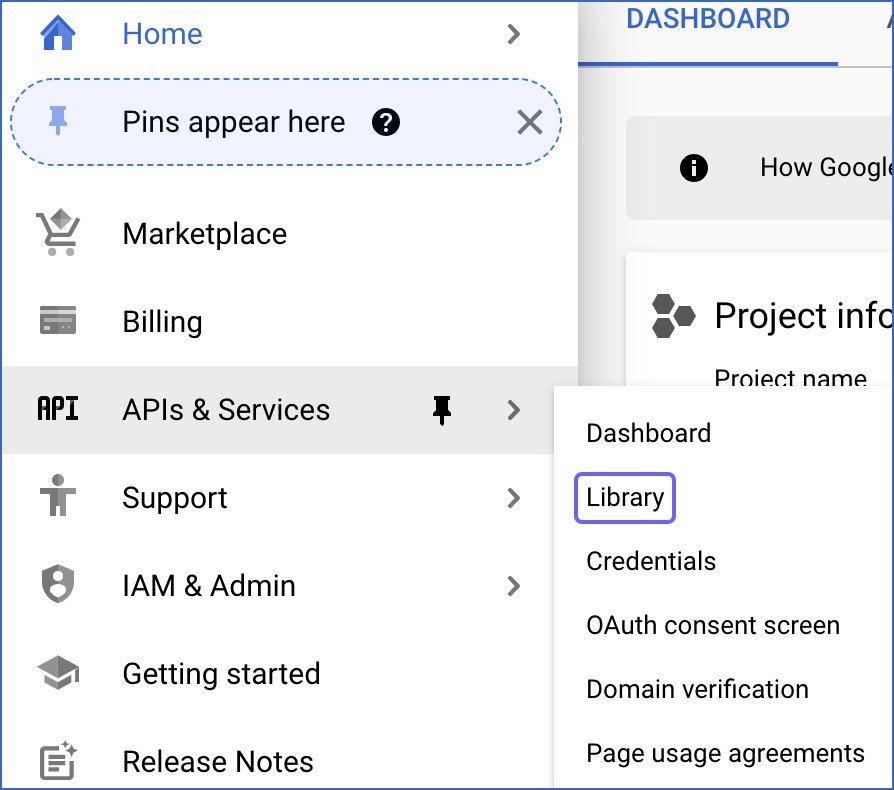
-
On the API Library page, search for BigQuery API, and then, click ENABLE.
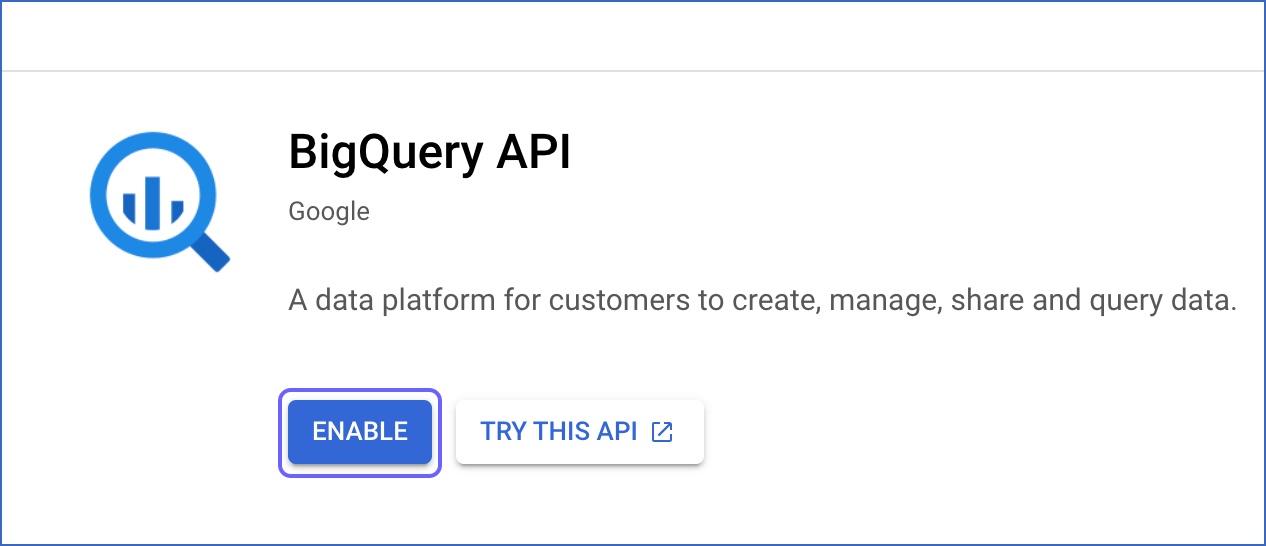
This enables your BigQuery project.
3. Link a billing account to your BigQuery project
BigQuery charges you for the data you are storing in it. For this, it requires you to have an active billing account in your BigQuery project. A single billing account may be shared across multiple projects.
To link a billing account:
-
Log in to the Google Cloud Console.
-
In the left navigation pane, click Billing.
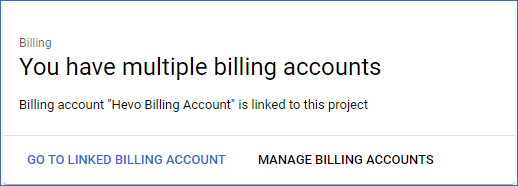
Note: If you already have a billing account linked to your BigQuery project, the following screen is prompted by the application. In such a case, skip to Linking the Google Analytics 360 account to the BigQuery Project.
-
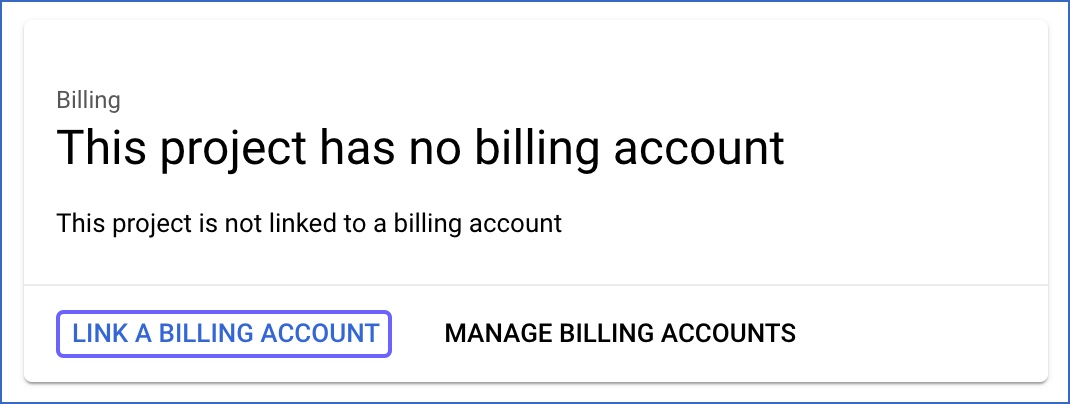
In the Billing page, click LINK A BILLING ACCOUNT.
-
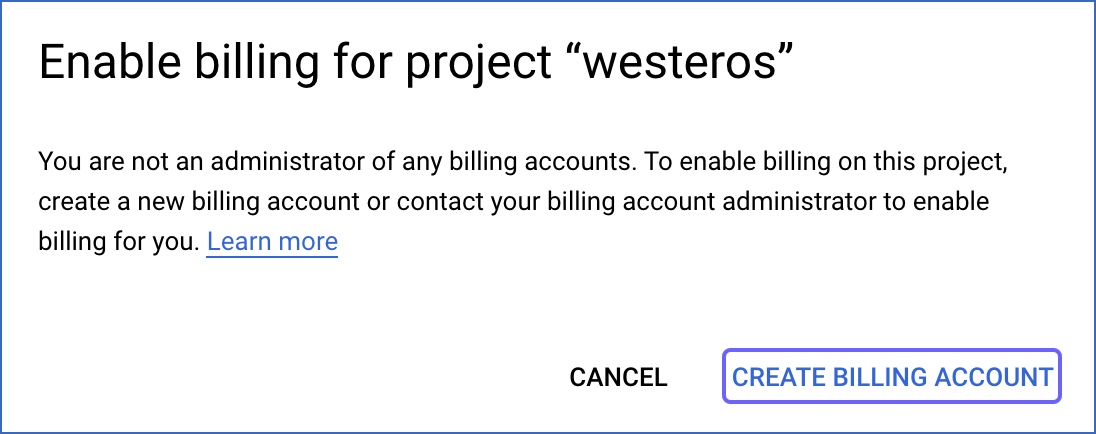
Click CREATE BILLING ACCOUNT.
-
Follow the steps in the screens, as prompted by the application, to create your billing account.
Linking the Google Analytics 360 account to the BigQuery Project
1. Add the service account to your BigQuery project
You must add the following service account as a member of the BigQuery project:
analytics-processing-dev@system.gserviceaccount.com
The service account must have Editor permission at the project level. Learn more about setting up permissions. GA 360 uses this service account to export your data to your BigQuery project.
-
Log in to the Google Cloud Console.
-
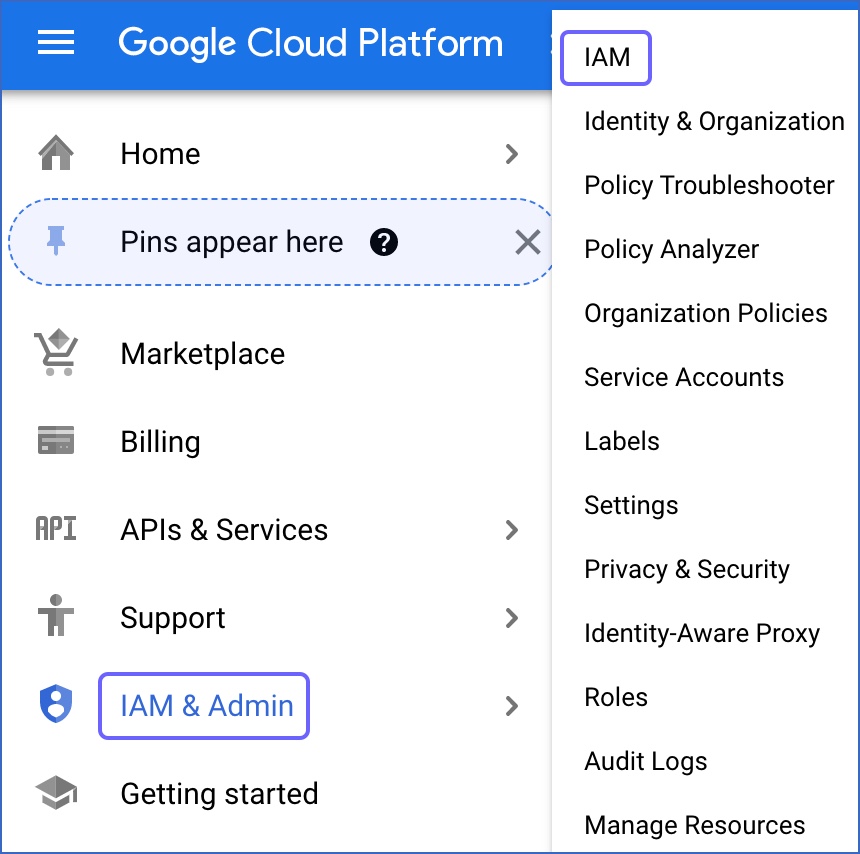
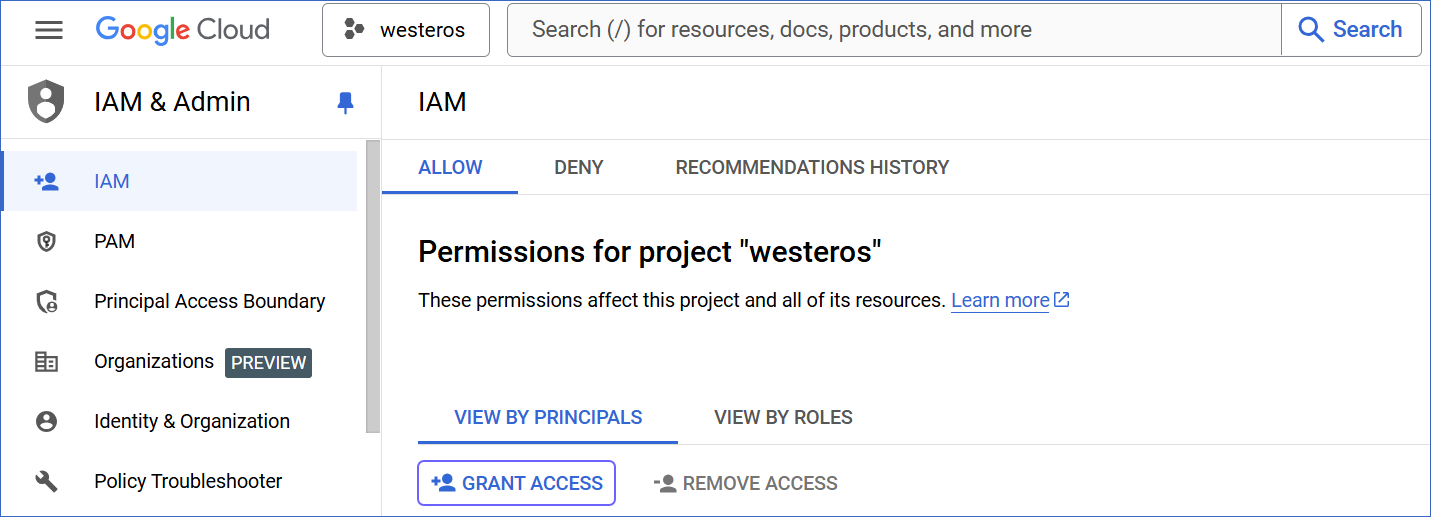
In the left navigation pane, click IAM & Admin, and then click IAM.
-
On the IAM page, under the VIEW BY PRINCIPALS tab, click GRANT ACCESS.
-
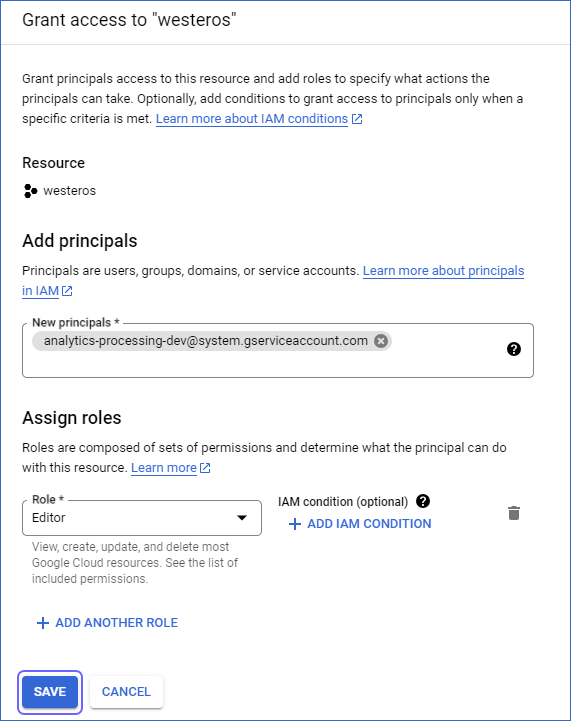
On the Grant access to <your project name> slide-in page, specify the following:
-
Add principals: analytics-processing-dev@system.gserviceaccount.com
-
Assign roles: Editor
-
-
Click Save.
2. Link your Google Analytics 360 account to your BigQuery project
-
Login to your GA 360 account with
Editoraccess to modify permissions for the Analytics property andOwneraccess to manage the BigQuery project.Click here to check your role in the BigQuery project you want to link. If you are not an
Owner, contact your project owner to perform the following steps. -
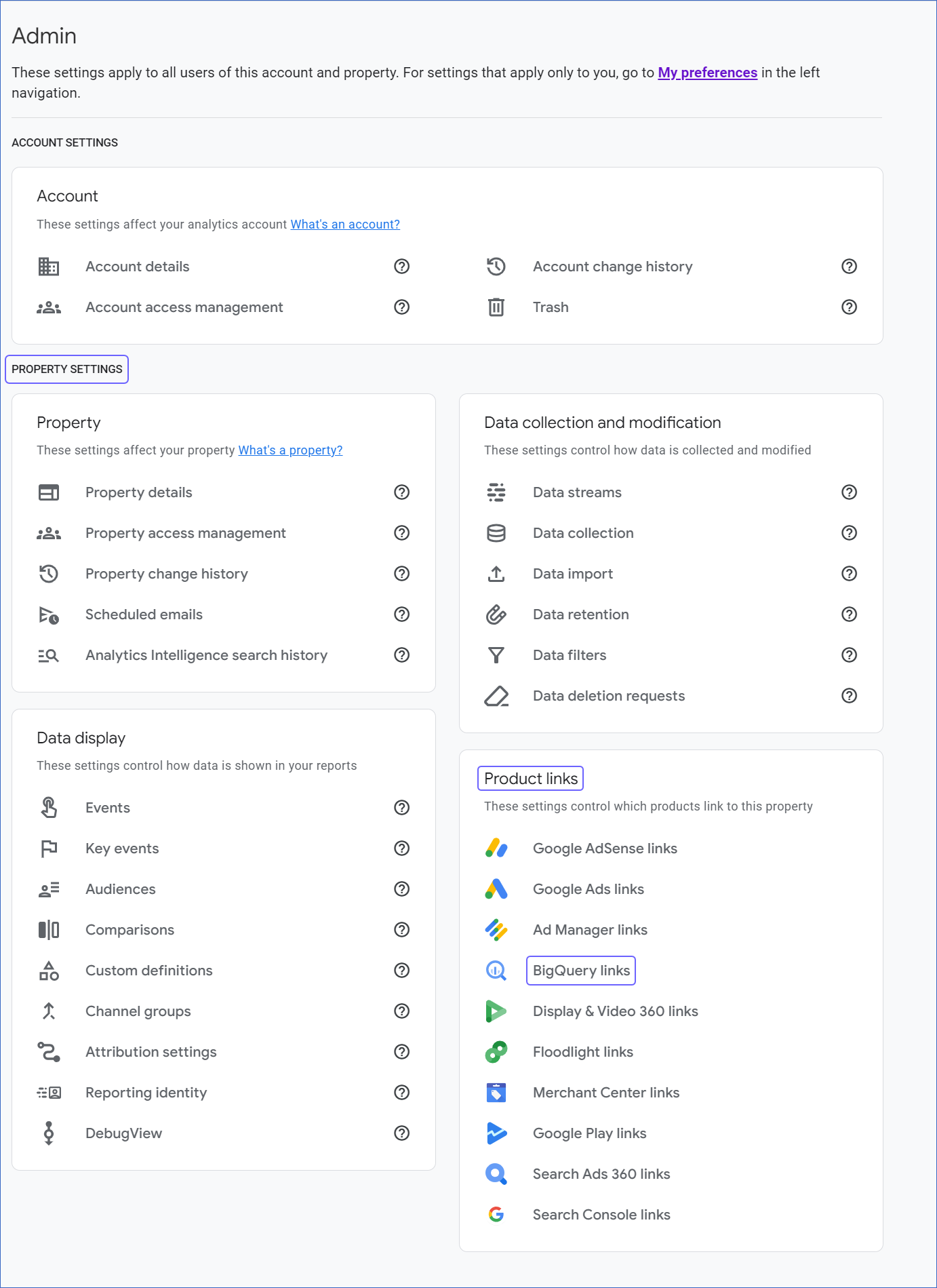
In the left navigation pane, click Admin.
-
On the Admin page, in the PROPERTY SETTINGS section, under Product links, click BigQuery links.
-
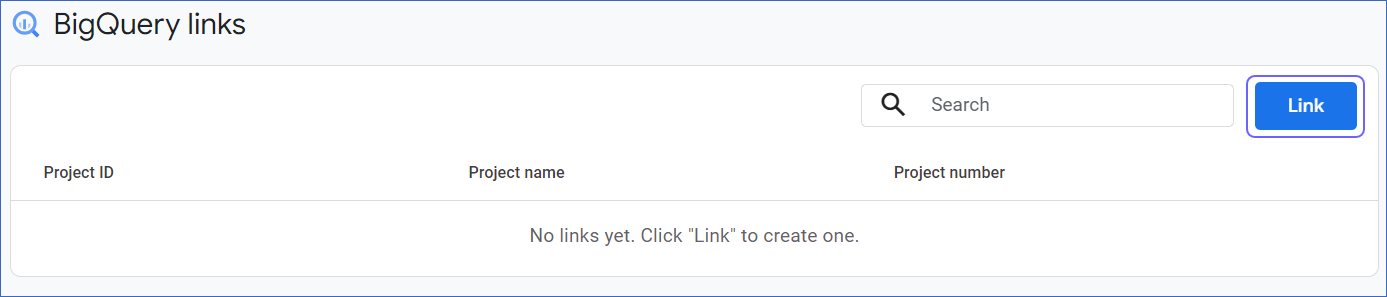
Click Link.
-
On the Create a link with BigQuery slide-in page, click Choose a BigQuery project.
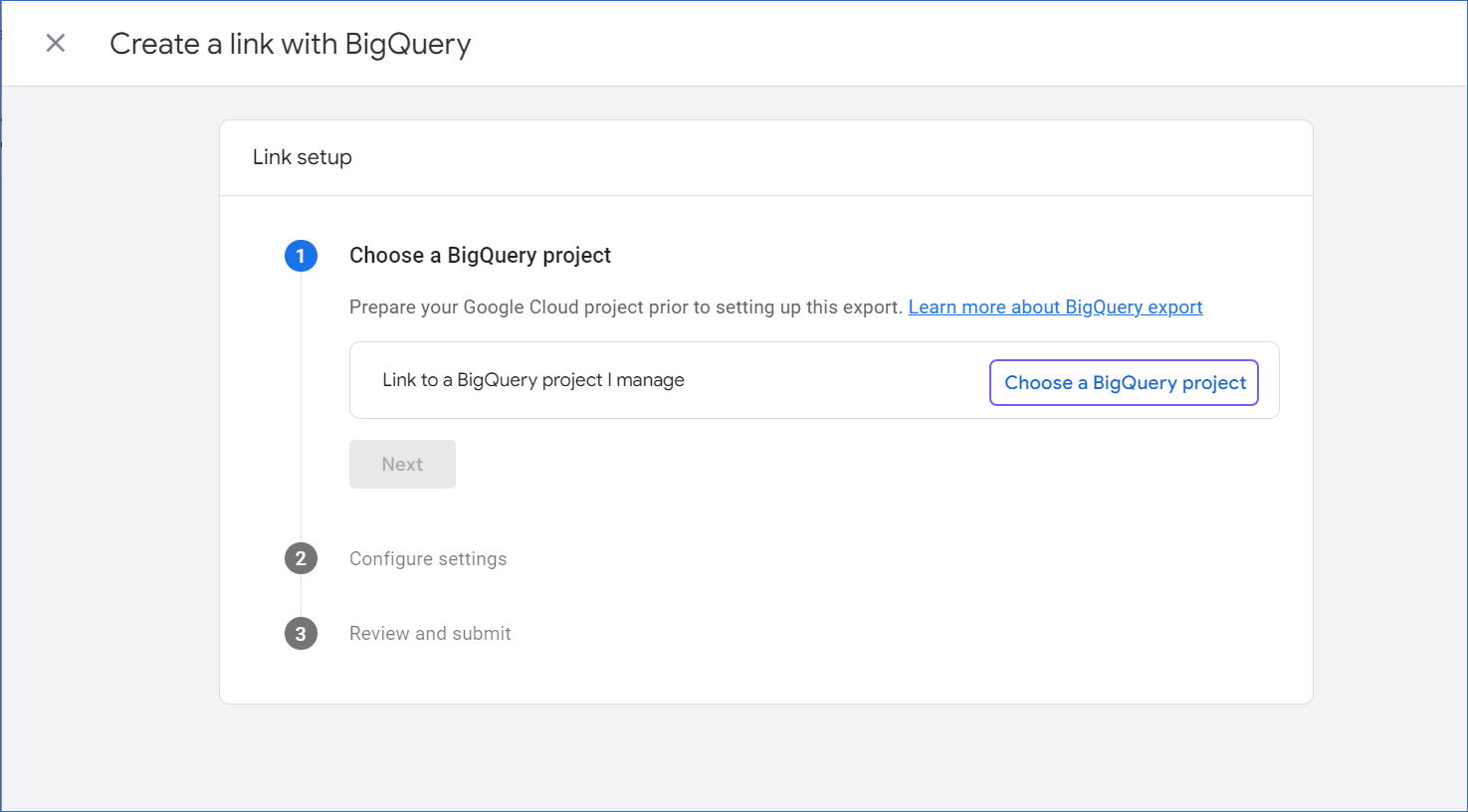
-
Select the checkbox next to the project you want to link and then click Confirm.

-
Click Next to configure the Event data and User data in the Configure settings section.
-
Click Next to review your specified configuration settings and click Submit.
Once you link your GA 360 account to your BigQuery project, you must refresh the Configure your Google Analytics 360 Source page in Hevo to reflect the updated project and dataset IDs.
Note: BigQuery tables take 24 hours to display the data when you set up your BigQuery Export for the first time.
Configuring Google Analytics 360 as a Source
Perform the following steps to configure GA 360 as a Source in Hevo:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
On the Select Source Type page, select Google Analytics 360.
-
On the Configure your Bigquery Account linked to Google Analytics 360 page, do one of the following:
-
Select a previously configured account and click CONTINUE.
-
Click + ADD BIGQUERY ACCOUNT and perform the following steps to configure an account:
-
Select your linked Google account with
BigQuery DataViewerprivilege. -
Click Allow to provide Hevo
readaccess to your analytics data.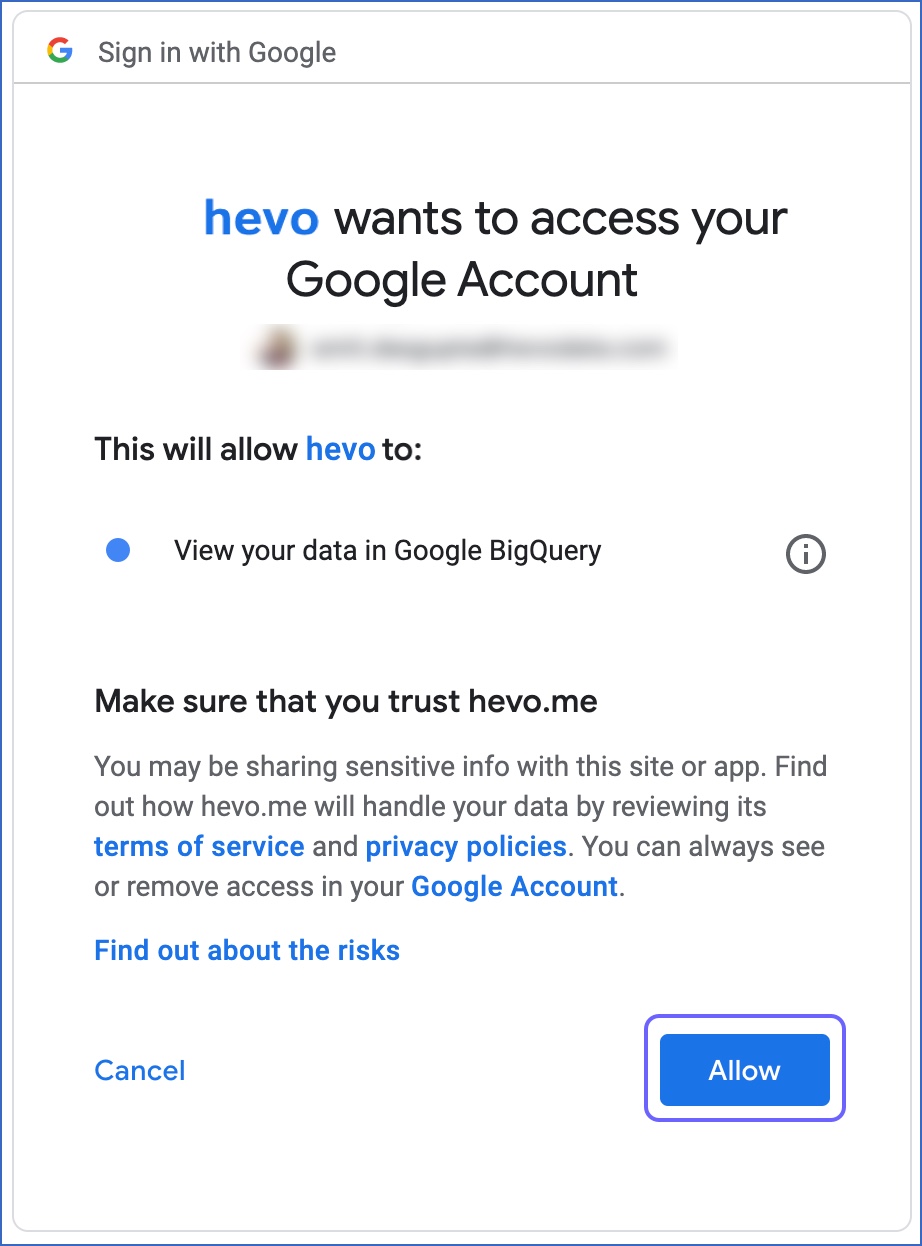
-
-
-
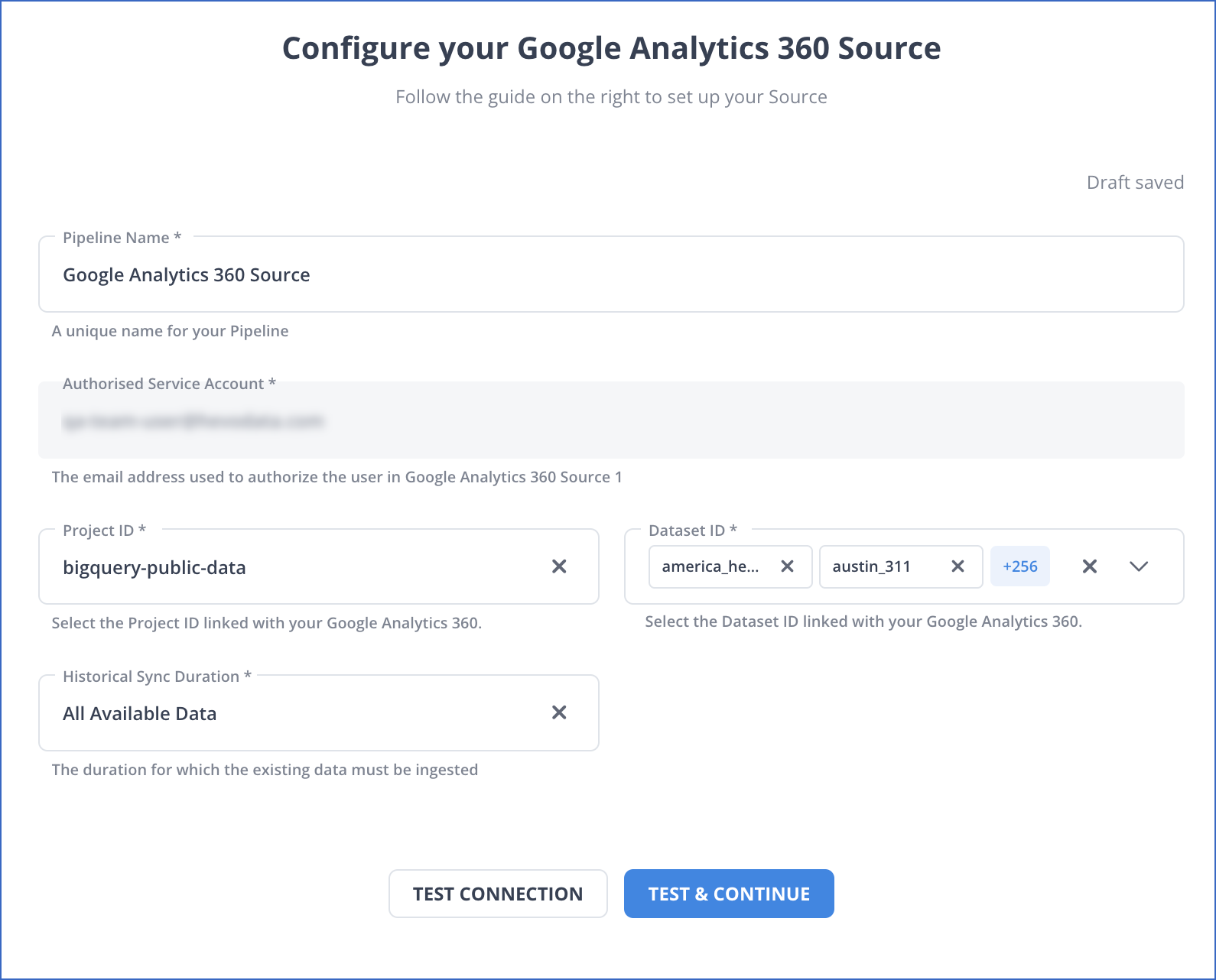
On the Configure your Google Analytics 360 Source page, specify the following:
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Project ID: The ID of your BigQuery project linked to the GA 360 account.
Note: If you are linking your GA 360 account to your BigQuery project for the first time, you must refresh this page in Hevo to reflect the updated project IDs.
-
Dataset ID: Name of the dataset which contains your Google Analytics 360 data. Once your GA 360 account is linked to your BigQuery project, the dataset ID becomes available for selection in the drop-down. If you do not find your dataset ID listed in the drop-down, contact Hevo Support.
Notes:
-
You can select multiple dataset IDs from the drop-down.
-
By default, Hevo loads a maximum of 500 dataset ID in the Dataset ID drop-down.
-
GA 360 refers to the dataset as View.
-
-
Historical Sync Duration: The duration for which you want to ingest the existing data from the Source. Default duration: All Available Data.
Note: If you select All Available Data, Hevo ingests all the data available in your Google Analytics 360 account since January 01, 2016.
-
-
Click TEST & CONTINUE.
-
Proceed to set up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 1 Hr | 15 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: The first run of the Pipeline ingests historical data for the selected objects on the basis of the historical sync duration specified at the time of creating the Pipeline and loads it to the Destination.
-
Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency in Full Load or Incremental mode, as applicable.
Your GA 360 data is stored in the following tables in BigQuery:
-
ga_sessions_YYYYMMDD: This table is generated at the end of the day. Once the table is generated, the data in this table is not modified. Hevo reads this table only once.
-
ga_sessions_intraday_YYYYMMDD: This table is generated multiple times a day and is deleted the next day after the
ga_sessions_YYYYMMDDtable is generated for the previous day. The data in this table changes throughout the day. Hevo ingests data once an hour by default. You can configure this frequency using the Change Schedule option in the Pipeline Summary Bar.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination system:
Note: _hevo_id is a primary key generated by hashing date, visitor_id, visit_id, visit_start_time.
Data Model
Depending on the selected parsing strategy, there can be one or more objects in the Destination system.
The following table lists the two important objects that are critical to GA 360’s functioning:
| Objects | Description |
|---|---|
| ga_sessions | Contains the session-level data. |
| hits/ ga_session_hits | Contains the hit-level data depending on the parsing strategy. |
The schema of the table is generated based on the Destination and the selected parsing strategy.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Limitations
-
Hevo does not support GA 360 MCF (Multi-Channel Funnel) Reports.
-
Hevo does not load an Event into the Destination table if its size exceeds 128 MB, which may lead to discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each row in your Source objects contains less than 100 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Dec-23-2024 | NA | Updated sections, Creating your BigQuery Project and Linking the Google Analytics 360 account to the BigQuery Project as per the latest Google Analytics 360 and Google Cloud Console UI. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Apr-04-2023 | NA | Updated section, Configuring Google Analytics 360 as a Source to update the information about historical sync duration. |
| Dec-07-2022 | NA | Updated section, Data Replication to reorganize the content for better understanding and coherence. |
| Oct-25-2021 | NA | Added the Pipeline frequency information in the Data Replication section. |
| Mar-23-2021 | 1.59 | New document. |