Intercom App
On This Page
Intercom enables you to offer near real-time engagement and support to your current and target customers through a messaging like platform. Using Hevo’s Intercom connector, you can replicate all your Intercom data to your desired Destination.
Prerequisites
-
An active Intercom account from which data is to be ingested exists.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Configuring Intercom as a Source
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
On the Select Source Type page, select Intercom.
-
On the Configure your Intercom account page, do one of the following:
-
Select a previously configured account and click CONTINUE.
-
Click + ADD INTERCOM ACCOUNT and perform the following steps to configure an account:
-
On the Intercom Welcome page, sign in to your Intercom account.
-
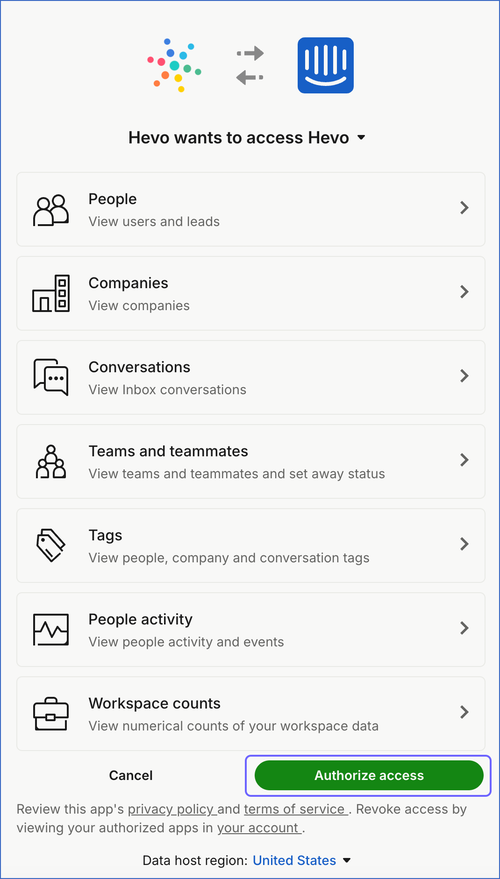
In the screen that appears, click the drop-down icon and select the workspace that you want Hevo to access. The list of workspace objects for which Hevo captures the data are displayed. You can click the expand icon for each object to see the permissions that Hevo has requested.
-
Click Authorize access to allow Hevo to access the objects.
-
-
-
On the Configure your Intercom Source page, specify a suitable Pipeline Name. The Intercom account you are logged in with is displayed.

-
Click TEST & CONTINUE.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 1 Hr | 30 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
The first run of the Pipeline replicates all existing data for the selected objects to the Destination.
-
Historical Data: In the first run of the Pipeline, Hevo ingests all the existing data for the selected objects from your Intercom App account and loads it to the Destination.
-
Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency in Full Load or Incremental mode, as applicable.
Schema and Primary Keys
Data Model
Hevo replicates data for the following objects from your Intercom account. The primary key of the Destination table is the same as that of the ingested Source object.
| Object | Description |
|---|---|
| Admin | Represents teammate accounts having access to a workspace. |
| Company | Represents organizations using the product. |
| Conversation | Represents how you communicate with users in Intercom. A conversation is created when a contact replies to an outbound message, or when one admin directly sends a message to a contact. |
| Conversation Part | Represents individual entities that make up a conversation. |
| Contact | Provides details of the contacts within Intercom and specifies whether they are a user or a lead, through the role attribute. |
| Segment | Represents a group of contacts defined by rules that you set. When a contact is updated, it is automatically added to the segment if it matches those rules. |
| Tag | Allows you to label your contacts and companies, and list them using that tag. |
| Team | Represents a group of admins in Intercom. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
The Intercom API retrieves only the latest 500
conversation partsbelonging to eachconversation. -
The Intercom API indexes timestamp fields of the Contact object, such as
created_atandupdated_at, as dates. As a result, you can search for contacts based on these timestamps only by day, and not by hour, minute, or second. For example, if you search for contacts with theupdated_atvalue greater than 1639126800, the epoch time for December 10, 2021 2:30 PM, all contacts updated from midnight of December 10, 2021 are fetched. This can mean re-ingestion of some Events, which counts towards your Events quota consumption. -
It can take a few minutes for a newly created contact to become available for searching. Therefore, the “greater than or equal to <timestamp>” condition may not always be honored, and such contacts may not be retrieved in the API response.
To avoid this scenario, Hevo uses a buffer of one hour while searching for the contacts.
-
The Intercom Scroll API allows only one connection per app to its Scroll over all companies endpoint. As Hevo uses this endpoint to go over the list of companies in an Intercom workspace and fetch data from them, it is subject to this limitation. If you have configured multiple Pipelines and they make concurrent requests to ingest data from the Company object in the same Intercom workspace, only the one that connects first to the Intercom app can successfully fetch data; the remaining Pipelines fail.
Therefore, you should restrict the number of Pipelines created for the same Intercom workspace, or, configure them such that their ingestion schedules do not overlap.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Mar-05-2024 | 2.21 | Added the ingestion frequency table in the Data Replication section. |
| Apr-10-2023 | 2.11 | Updated section, Schema and Primary Keys to link to the new ERD with support for additional fields in the Conversation object. |
| Dec-14-2022 | NA | - Added the limitation of Scroll API to the Source Considerations section. - Updated section, Configuring Intercom as a Source to reflect the latest Hevo UI. |
| Dec-09-2021 | NA | - Renamed the Limitations section to Source Considerations. - Added the Source considerations about supporting only day-based timestamp values for querying the Contacts object and using a time buffer for the search to ensure all eligible Events are ingested. |
| May-19-2021 | 1.63 | - Updated the section, Data Model to include descriptions of objects. - Added the section, Limitations. |