Structure of Data in the Snowflake Data Warehouse
On This Page
Snowflake is a cloud data warehouse that you can use to store your enterprise data or data repository. It is a true SaaS offering, which means that you do not need to install any hardware or software to use it. Snowflake handles the management and maintenance of the warehouse. Its micro-partitioning and data clustering features help optimize query performance and table maintenance.
Snowflake Architecture
Snowflake separates data storage from the computing functions, allowing you to scale each of these independently. Its architecture consists of three distinct layers:
-
Database Storage: All the data in Snowflake is maintained in databases in an encrypted and compressed form. Each database consists of one or more schemas, which define the logical groupings of the tables and views within the database. Snowflake supports unstructured data, such as CSV, and semi-structured data, such as JSON and AVRO.
-
Query Processing: Snowflake processes queries using virtual warehouses, which are massively parallel processing (MPP) compute clusters. MPP enables faster performance and allows for quick scaling up. Each virtual warehouse comprises several compute nodes allocated by Snowflake from the cloud provider. These virtual warehouses are independent of each other and do not share compute resources, such as CPU, memory, and temporary storage. As a result, one virtual warehouse does not impact the performance of any other virtual warehouse. Virtual warehouses can be used across databases and auto-suspended when not in use.
-
Managed Services: The managed cloud services coordinate all the operations in Snowflake, such as data encryption, SQL querying, client sessions, and authentication. The queries are routed through this layer’s optimizer to the virtual warehouses. This layer also stores the metadata needed to optimize the queries or filter data.
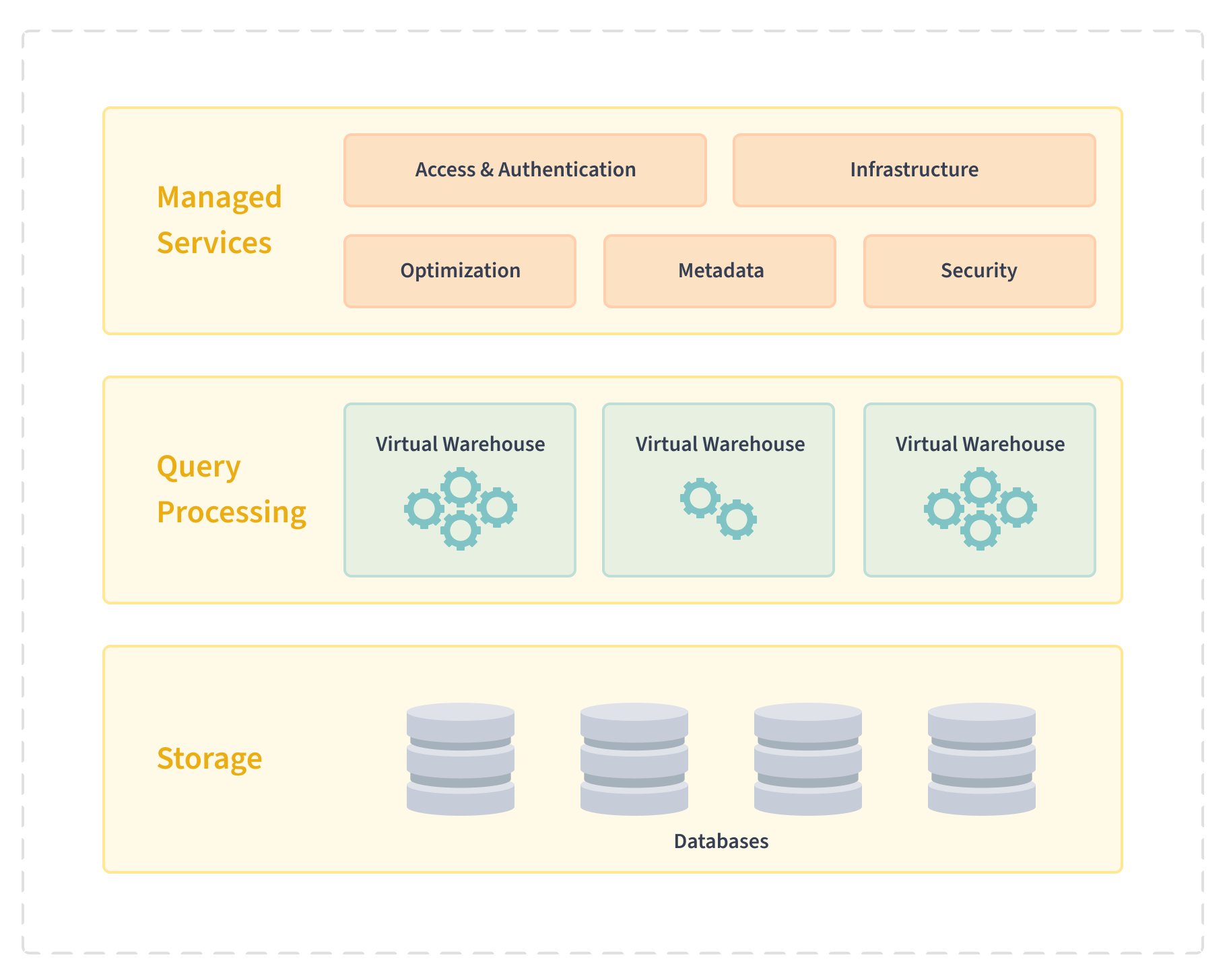
Snowflake Data Structure
Data may come into Snowflake from a variety of Sources. To support this, the Snowflake warehouse can store both structured data, such as data similar to CSV format, and semi-structured data, such as data in JSON format.
When you create a Pipeline, Hevo ingests the data from your Source, saves it in CSV or JSON format on its server, and loads it to S3 buckets. The data is then copied from these buckets to Snowflake in a columnar fashion.
Once the data is loaded to your Snowflake Destination, it is deleted from these locations.

Example
Consider the following Event ingested from a webhook Source, where the metadata field is of type, string.
{
"event_name": "agents",
"properties": {
"agent_name": "James",
"agent_id": "Bond 007",
"metadata": {
"message": "This is a test message",
"rand_id": 3523
}
}
}
When Hevo writes the data to S3, this Event appears as follows:
{"agent_name": "James", "agent_id": "Bond 007", "metadata": {"message": "This is a test message", "rand_id": 3523}, "__hevo__ingested_at": ...}
Using SQL queries, Hevo loads this data to your Snowflake warehouse. Read Loading Data to a Snowflake Data Warehouse for more information.
You can verify the final data type of the fields from the Destination Workbench in Hevo. For example, in the following image, the metadata field from the Event above is loaded as a Variant data type that supports JSON data.

Snowflake Schema
The snowflake schema is a variation of the star schema and is a multi-dimensional data model, where each dimension of the star can further have a star schema of its own. The snowflake schema consists of a central fact table and a set of surrounding dimension tables that hold second-level or child data for each respective dimension or data in the fact table.
This formation normalizes or expands the dimension tables, thereby further splitting the data to remove redundancy and save storage space. However, a snowflake schema may impact query performance, as more tables need to be included in the SQL query that is executed while fetching or loading data.
Example: Star schema
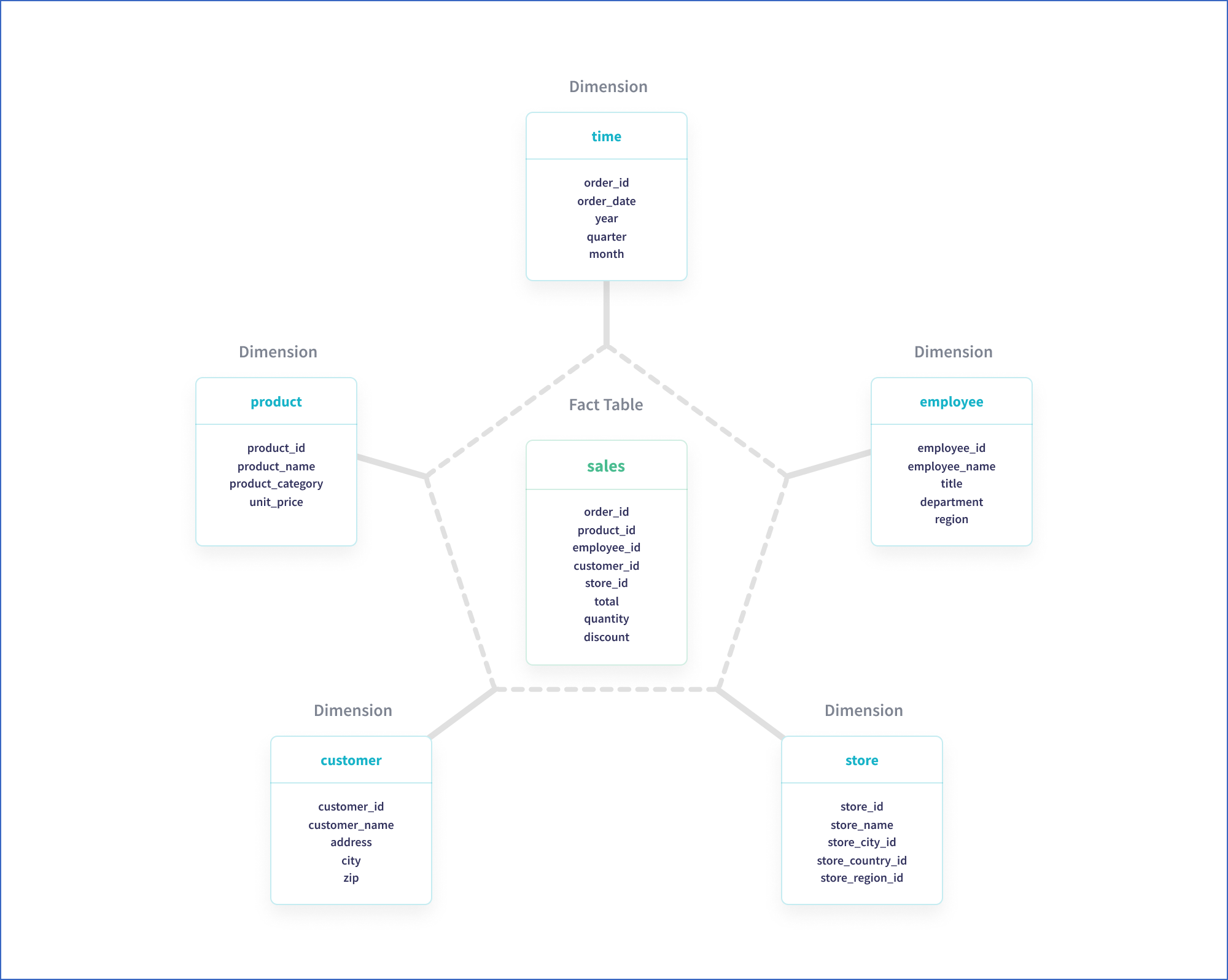
In the star schema above, the sales fact table holds key information about the sale. The details of each information item become a separate dimension table, such as time, product, and customer.
Example: Snowflake schema
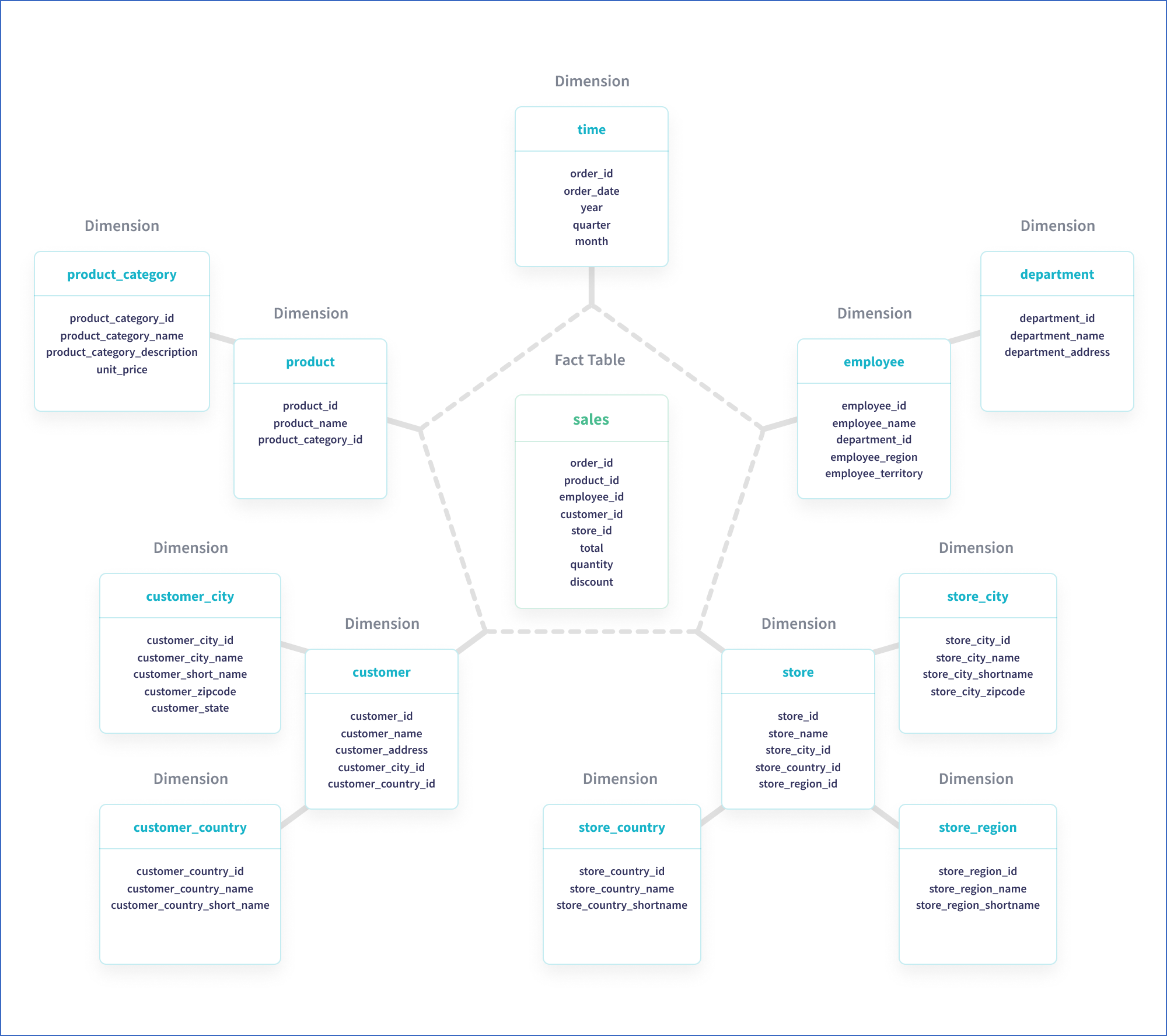
In the image above, each dimension table, such as customer and store, is further expanded to break down the information into its simplest form.
Micro-partitioning
The data in Snowflake is stored in database tables in compressed form, logically structured as collections of columns and rows. Snowflake automatically groups the rows into micro-partitions of 50–500 MB of data. Snowflake is column-based and horizontally partitioned, meaning a row of data is stored in the same micro-partition.
A very large table may comprise millions of micro-partitions or even hundreds of millions. Data is placed into micro-partitions based on the order in which it is inserted or loaded. The queries can use the micro-partition metadata to determine which partitions are relevant for a query and scan only those partitions. In addition to this, Snowflake further limits the scanning of a partition to only the columns filtered in a query.
Snowflake identifies the rows related to a query using the metadata it maintains about the rows stored in the micro-partitions.
Clustering
Snowflake automatically uses clustering to order and sort the data within a micro-partition. With clustering, the data stored in the tables is ordered on a subset of some of the columns that can be used to co-locate data. Snowflake collects clustering metadata for each micro-partition created during data load. This metadata is then leveraged to avoid unnecessary scanning of micro-partitions.
You can also define your own cluster keys to keep the frequently accessed data in the same micro-partition for faster retrieval or if your queries run slower than usual. However, manually assigned cluster keys override Snowflake’s natural clustering for that table, and Snowflake needs to use additional compute resources to reclassify the data. This action incurs a cost for you in the form of Snowflake credits. These credits are used to pay for the consumption of resources on Snowflake. Read Understanding Virtual Warehouse, Storage, and Cloud Services Usage for more information.
Note: If you have mapped your Source Event Type to a clustered table, Hevo displays a CK tag next to the columns based on which your Destination table is clustered.
![]()
Caching of Query Results
The Snowflake architecture includes caching at various levels to help speed up the queries you run on the data in your Snowflake Destination and minimize the costs. For example, Snowflake holds the results of any query run in the warehouse for 24 hours. So, suppose the same query is rerun by you or another user within your account. In such a case, the results are returned from the cache, provided the underlying data has not changed.
Caching is especially beneficial for analysis work where you do not need to rerun complex queries to access previous data or when you want to compare the query results before and after a change.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Apr-21-2025 | NA | Updated the Clustering section to clarify how Hevo tags the columns that form the cluster key in Snowflake tables. |
| Sep-19-2023 | NA | Updated the page to improve readability. |
| Jul-04-2022 | NA | New document. |