Recurly
On This Page
Recurly is a subscription management and billing platform that enables you to manage your customers’ billing and payment processes. It gives you more visibility into your subscription business, thus allowing you to optimize your subscription growth strategy and reduce involuntary churn.
Hevo uses the Recurly API to ingest data from your Recurly account and load it to the desired Destination database or data warehouse for scalable analysis.
Prerequisites
-
An active Recurly account with Admin permissions. Read Roles and Permissions for information on granting admin privileges to a user.
-
The Recurly private API key is available to allow Hevo to connect to your Recurly account.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Obtaining the API Key
You require an API key to authenticate Hevo on your Recurly account.
Note: You must log in as a user with Admin permissions to perform these steps.
To obtain an API key:
-
Log in to your Recurly account.
-
In the left navigation pane, click Integrations, and then click API Credentials.
-
On the API Credentials page, do one of the following:
-
Create an API key
-
Click Add Private API Key.

-
On the Add Private API Key page, API Key Information section, specify the following:
-
KEY NAME: A unique name for your API key.
-
Read-Only: An option to grant third-party applications, such as Hevo, Read-Only permission to your Recurly data.

-
-
Click Save Changes. You can view the API key that you created on the API Credentials page.
-
Copy the API key displayed in the PRIVATE API KEY field and save it securely like any other password.

-
-
Use an existing API key
Note: You can use either the default API key, which is available in all accounts, or an API key that was previously created in your account.
-
Click the View (
 ) icon next to the API key that you want to use.
) icon next to the API key that you want to use.
-
Copy the API key and save it securely like any other password. Use this key while configuring your Hevo Pipeline.
-
-
Configuring Recurly as a Source
Perform the following steps to configure Recurly as the Source in your Pipeline:
-
Click PIPELINES in the Asset Palette.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
On the Select Source Type page, select Recurly.
-
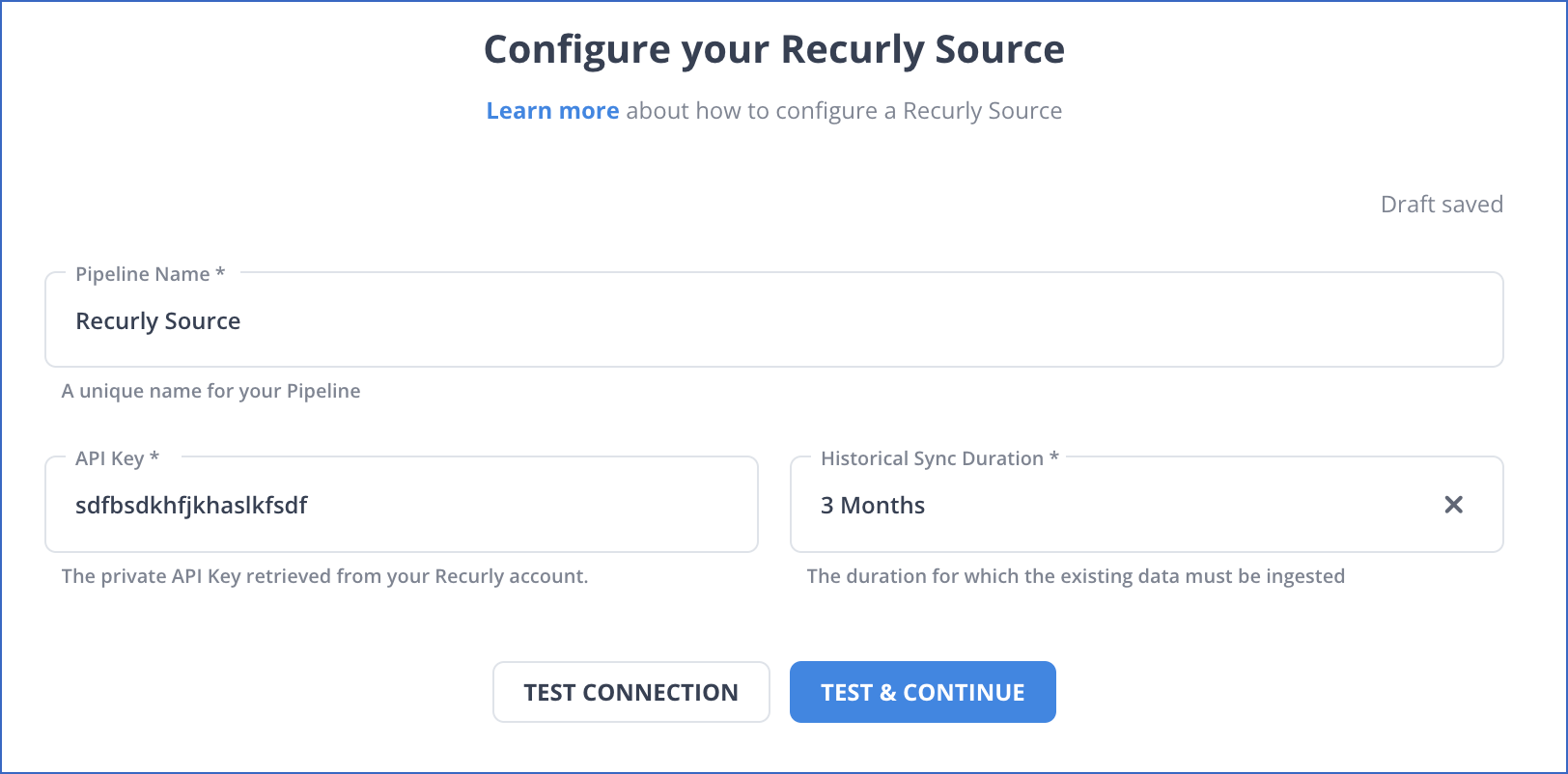
On the Configure your Recurly Source page, specify the following:
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
API Key: The private API key that you created in your Recurly account.
-
EU Environment (only visible to users in the Europe region of Hevo): Enable this if your Recurly account is in the European Union (EU) region. Read Data Hosting in Recurly to know about all the regions that Recurly supports.
-
Historical Sync Duration: The duration for which you want to ingest the existing data from the Source. Default duration: 3 Months.
-
-
Click TEST & CONTINUE.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 3 Hrs | 15 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests the historical data for all the objects using the Recent Data First approach. The data is ingested on the basis of the historical sync duration selected at the time of creating the Pipeline and loaded to the Destination. Default duration: 3 Months.
-
Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency in Full Load or Incremental mode, as applicable.
Schema and Primary Keys
Hevo uses the following schema to upload the records to the Destination database:
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
| Object | Description |
|---|---|
| Account | Contains the details of all your customers. |
| Account Acquisition | Contains the details of an account’s acquisition data, such as the marketing channel and campaign through which the account was acquired. |
| Add on | Contains the details of all the add-ons associated with a subscription plan. An add-on is a charge billed through each billing period in addition to a subscription’s base charge. |
| Coupon | Contains the details of the coupons available for the customers on your site. |
| Credit Payment | Contains the details of the credit payments made to the customers. |
| Invoice | Contains the details of the invoices of all the billing events in your Recurly account. |
| Item | Contains the details about the items available for purchase by the customers. Item is the term used to refer to all your physical, digital, or service-oriented offerings collectively in Recurly. |
| Line Item | Contains the details about line items. Line items are the charges and credits on your customer’s invoices. |
| Measured Unit | Contains the details about the measured units of a site. Measured units provide a display name for the quantity of a usage-based add-on. For example, Gigabytes (GB) for an add-on offering additional data. |
| Plan | Contains the details about all the plans available for your customers. |
| Shipping Method | Contains the details of the methods used to ship products to customers. |
| Subscription | Contains the details of subscriptions of a customer. Subscriptions are created when your customers subscribe to one of the plans. |
| Transaction | Contains the details about the transactions made by the customers. Transactions refer to the process of sending the purchasing information to your payment gateway. The purchasing information includes the customer’s billing information and the amount of money to be charged, voided, or refunded. |
Limitations
- Hevo does not load an Event into the Destination table if its size exceeds 128 MB, which may lead to discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each row in your Source objects contains less than 100 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Oct-03-2023 | NA | Updated the section, Obtaining the API Key as per the latest Recurly UI. |
| Sep-05-2022 | NA | Updated section, Data Replication to reorganize the content for better understanding and coherence. |
| Jun-09-2022 | 1.90 | New document. |