Salesforce Marketing Cloud
On This Page
Salesforce Marketing Cloud is a marketing automation platform that enables you to create and manage marketing relationships.
SFMC uses the concept of tenants and subdomains to host the data for your projects.
-
Tenant: Depending on the tenant type, a tenant can represent the top-level enterprise account, core account, top-level agency account, or your client account.
-
Subdomain: A subdomain is created within your main domain based on the tenant type. This subdomain is then added to the Application Programming Interface (API) which creates the tenant-specific endpoints. Hevo uses these endpoints to query the data.
To enable Hevo to access data from your Salesforce Marketing Cloud environment, you need to provide the Client ID and the Client Secret to Hevo.
Prerequisites
-
An active Salesforce Marketing Cloud instance from which data is to be ingested exists.
-
The client ID and secret are created in Salesforce Marketing Cloud.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Creating the Client ID and Client Secret
Salesforce Marketing Cloud uses the concept of a package to create API integrations, install custom apps, or add custom components. You need to create an API Integration package to generate the Client ID and the Client Secret to allow Hevo to read your Salesforce Marketing Cloud data. To do this:
-
Log in to your Marketing Cloud Instance.
-
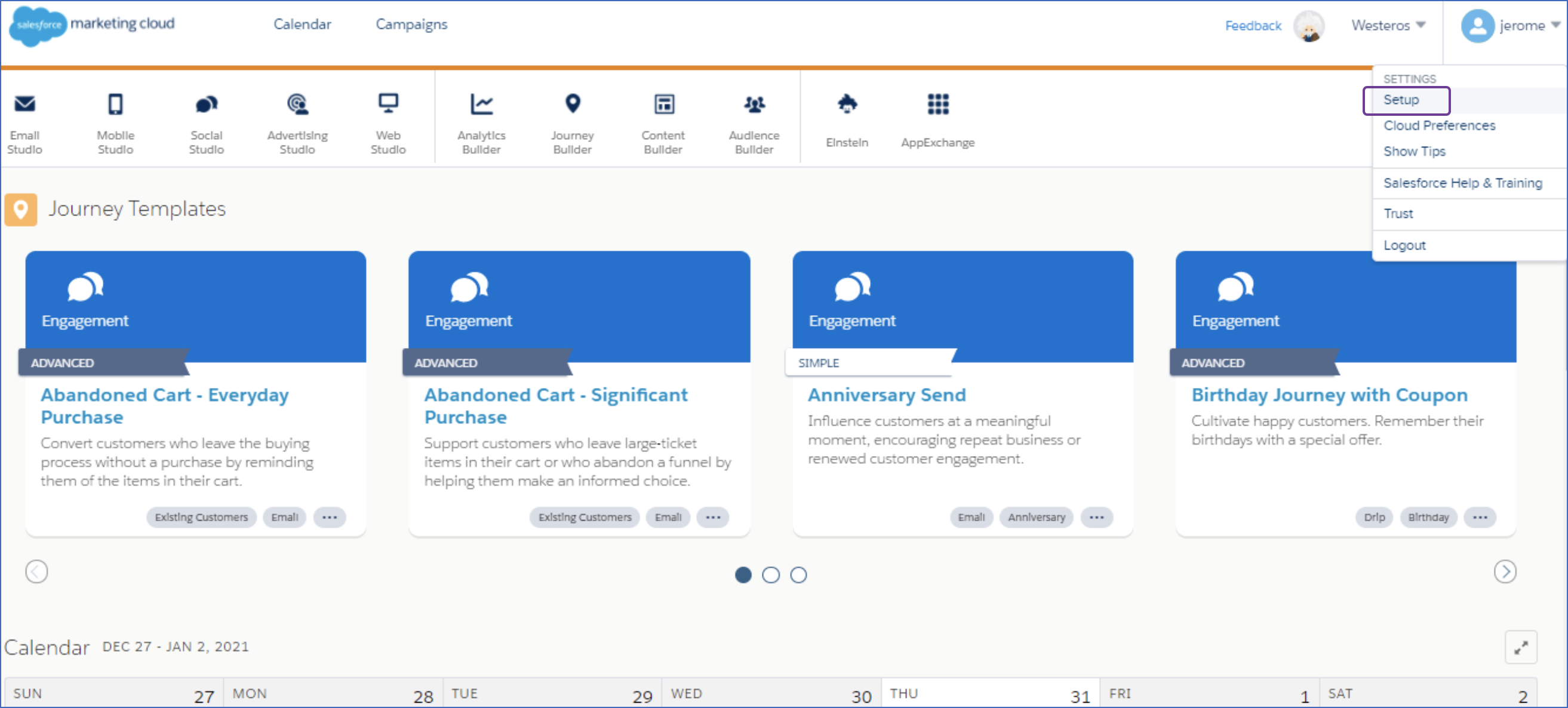
In the top right, click the drop-down next to your username, and then click Setup.
-
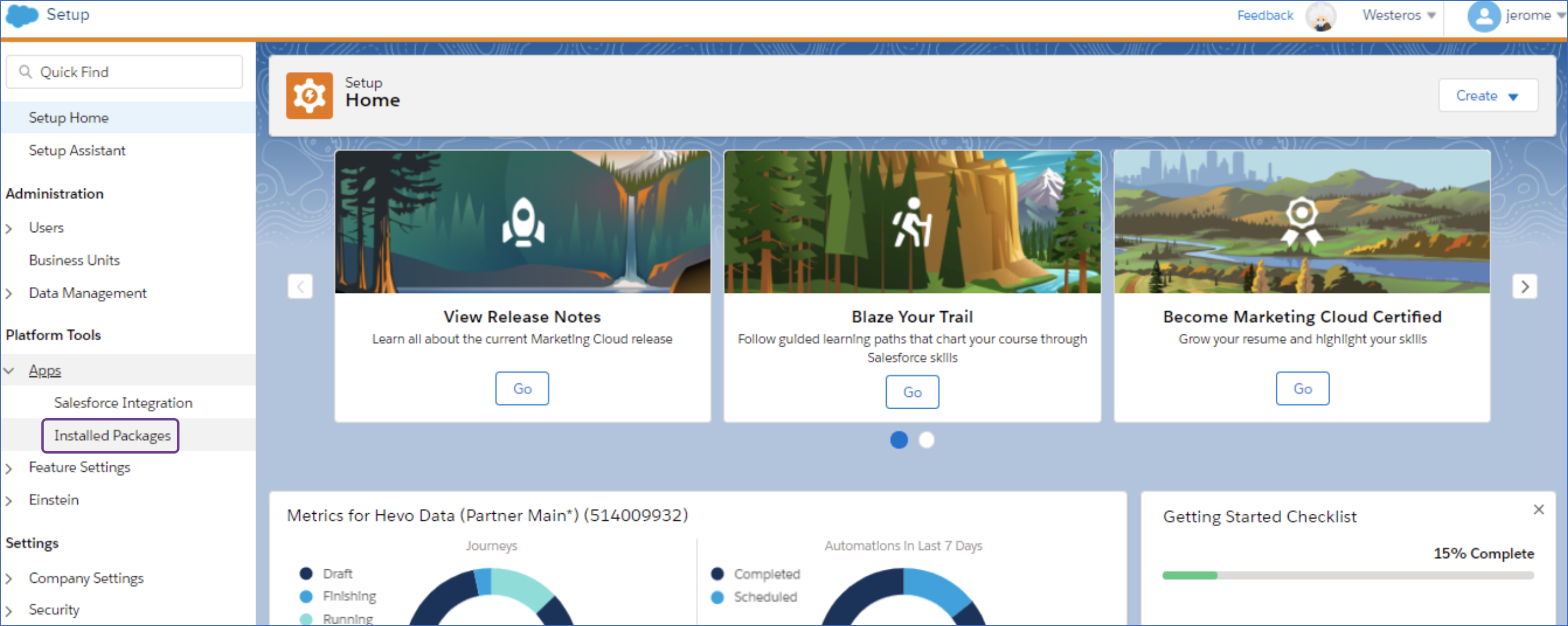
In the left navigation pane, under Platform Tools, click the Apps drop-down and then click Installed Packages.
-
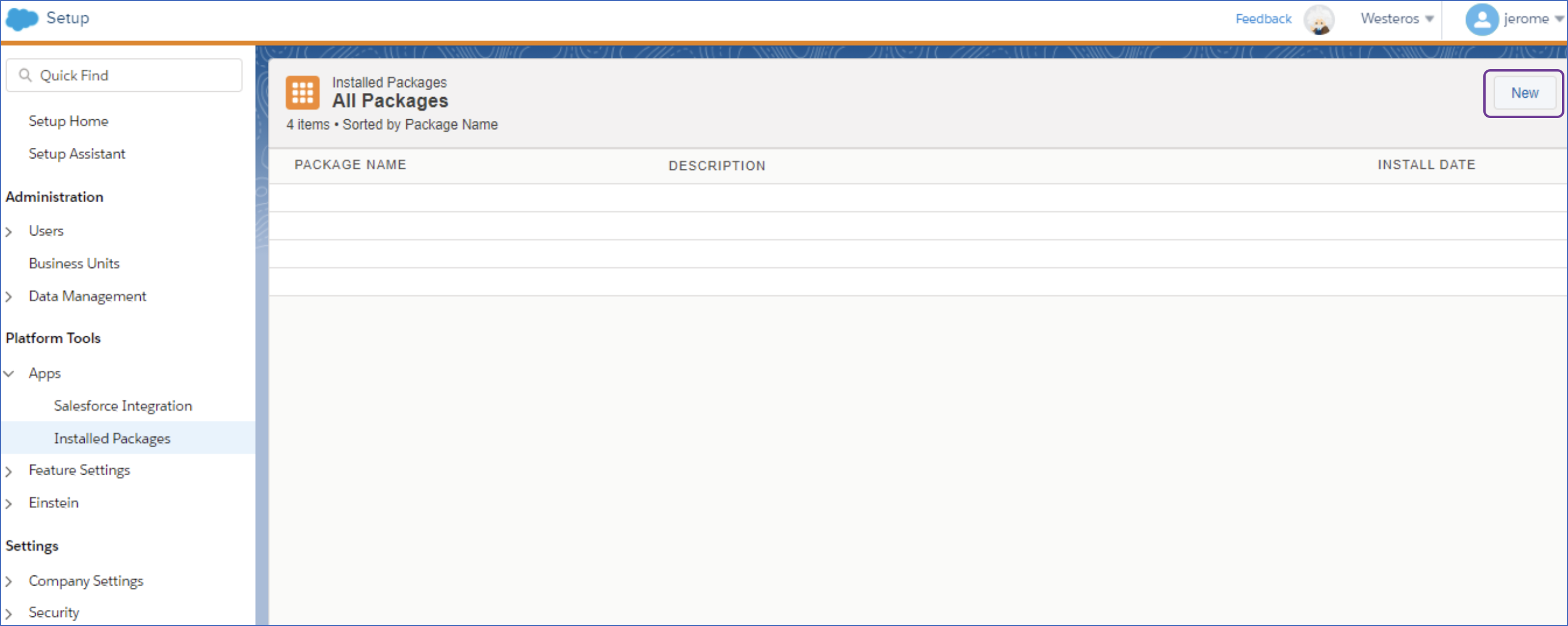
On the Installed Packages page, click New.
-
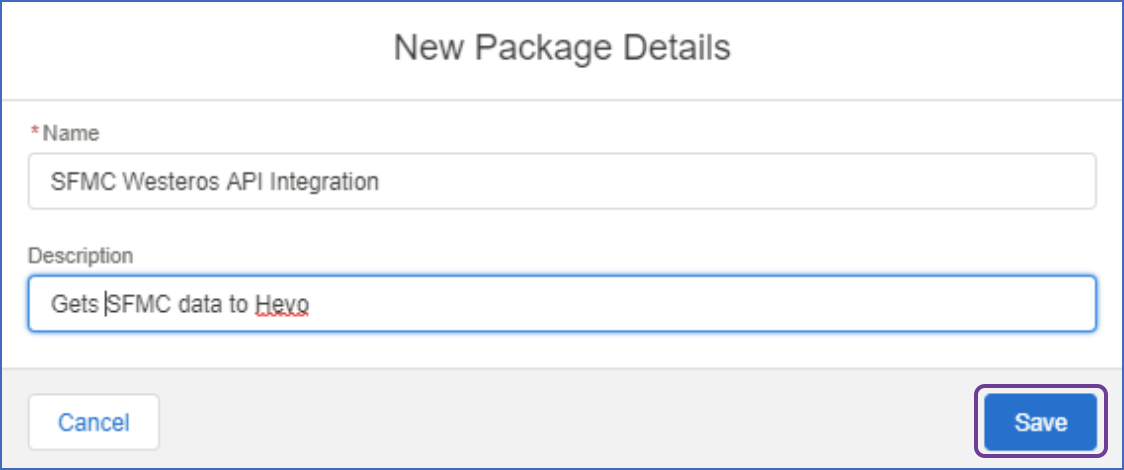
In the New Package Details window, specify the following:
-
Name: A unique name for the package.
-
Description: A brief description of the package.
-
-
Click Save.
-
In the Components section, click Add Component.
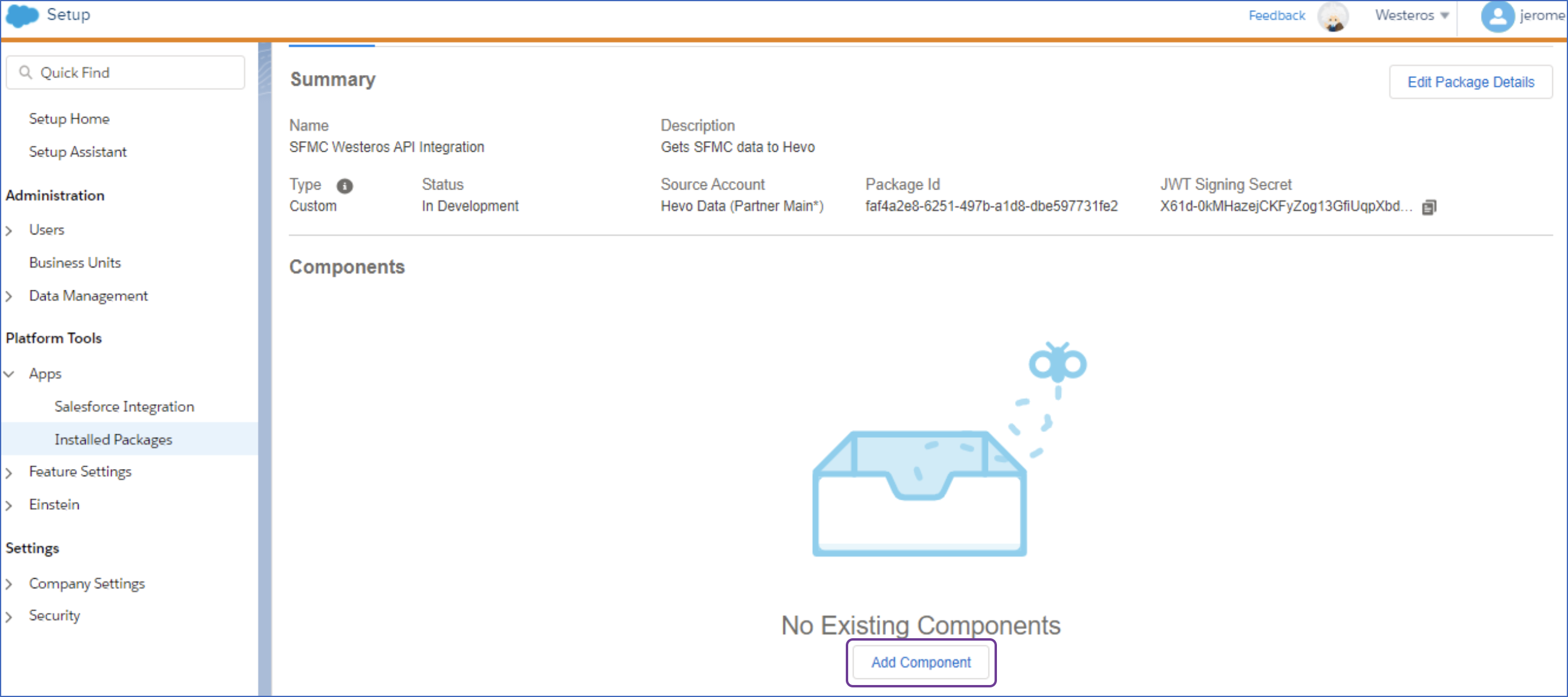
-
In the Add Component window, select API integration as the component type, and then, click Next.
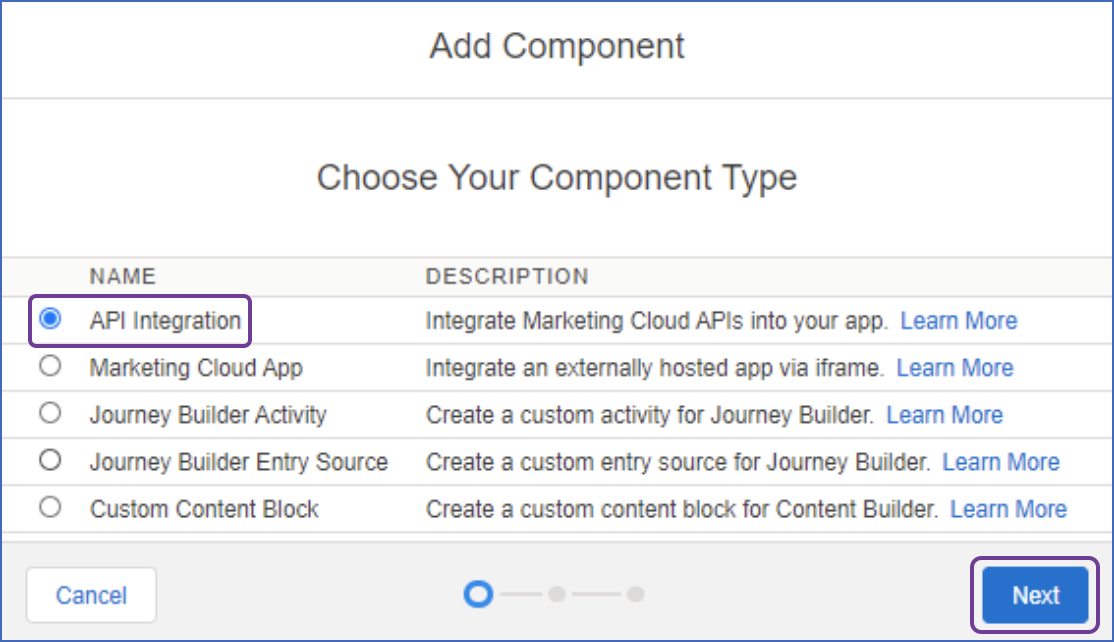
-
Select Server-to-Server as the integration type and click Next.
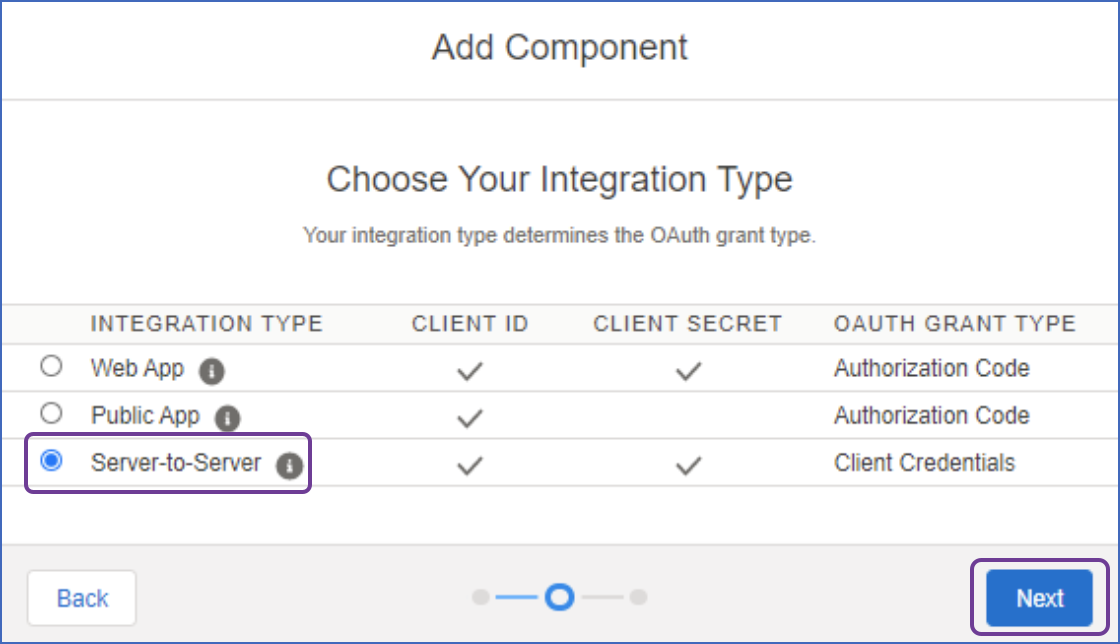
Note: A Server-to-Server integration allows server interaction without user involvement.
-
Select the Read check box to grant
read-onlypermission for the following objects:Email, OTT, Push, SMS, Social, Web, Documents and Images, Saved Content, Journeys, and List and Subscribers.
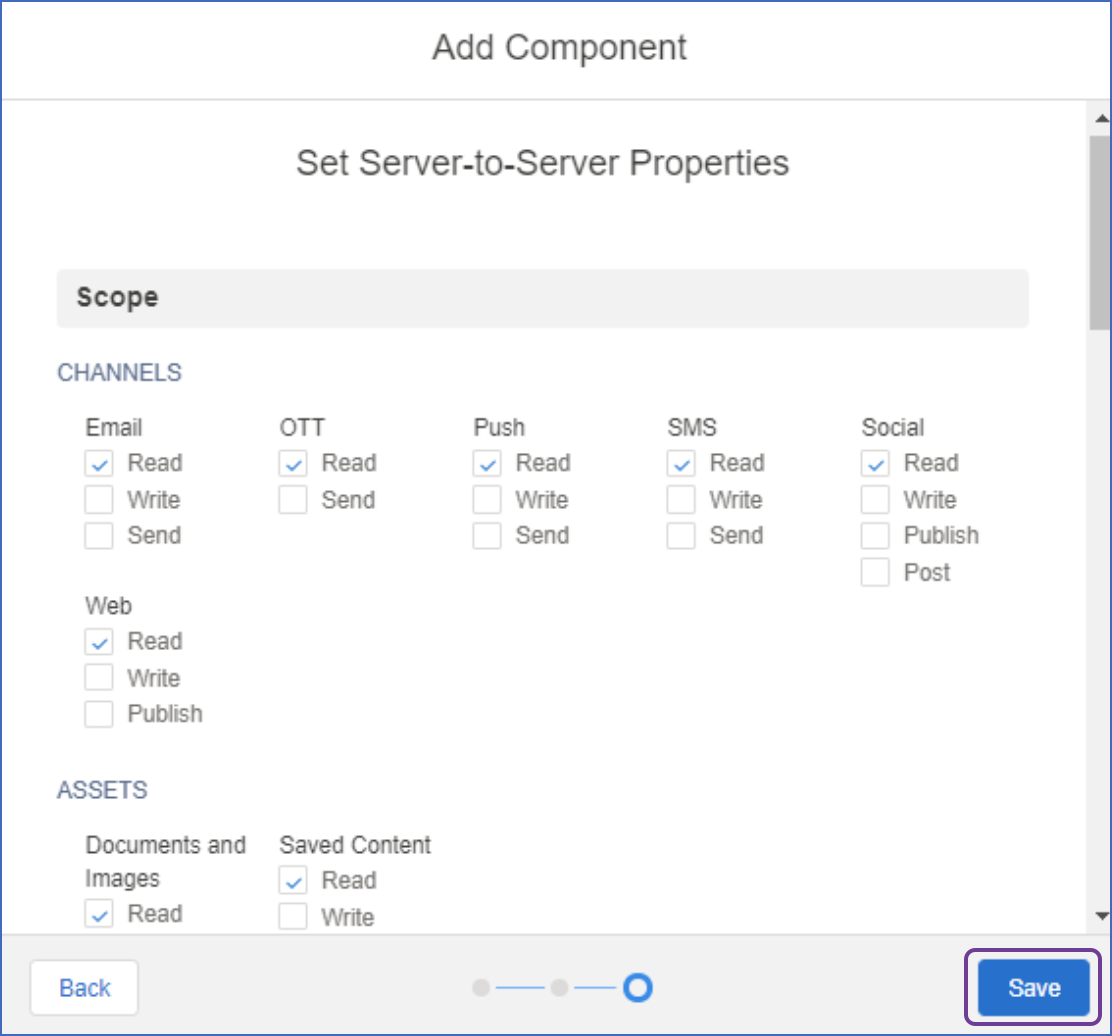
-
Click Save.
-
In the Components, API Integrations section, copy the Client Id and Client Secret and save them securely like any other password.
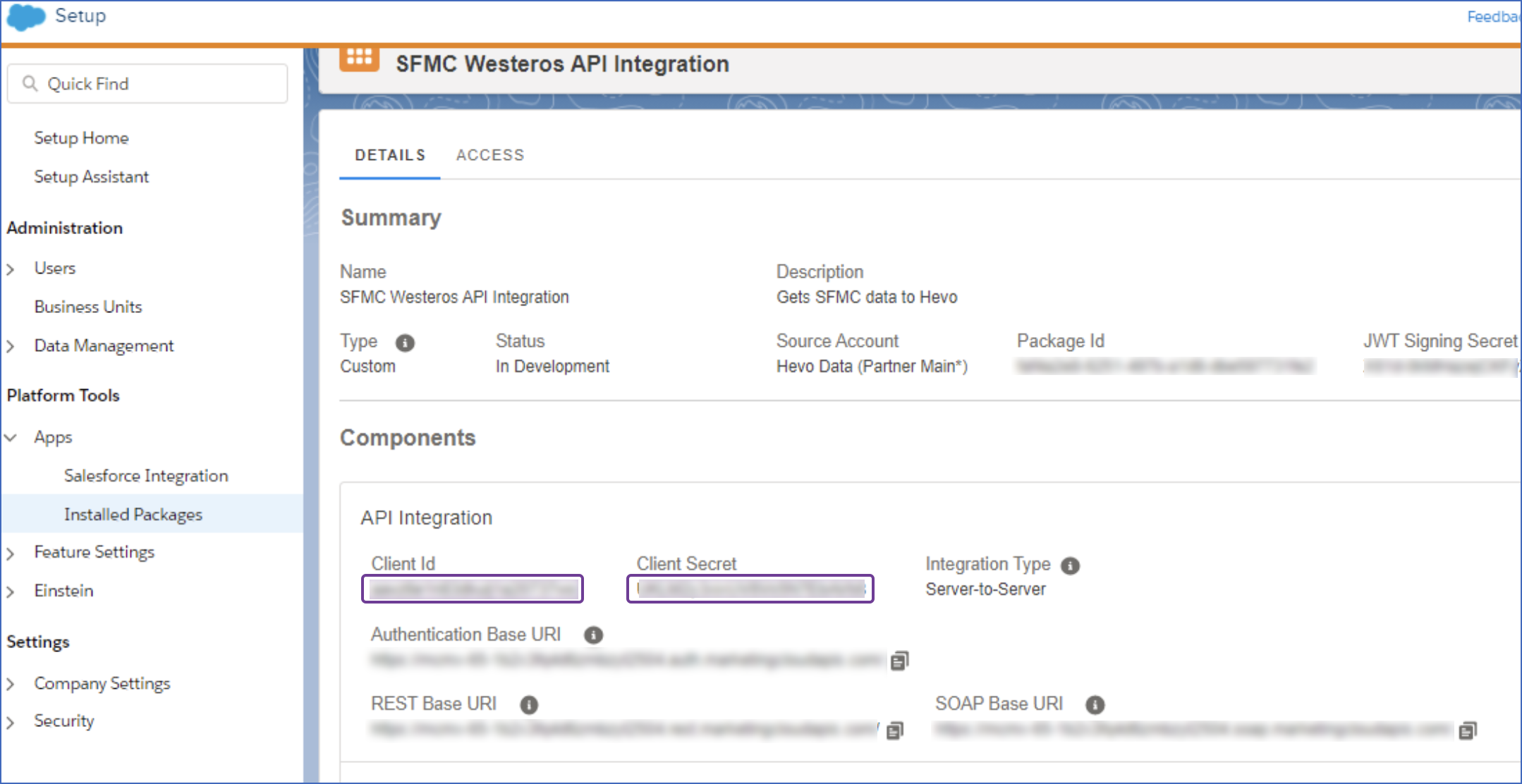
You can use these credentials while configuring your Hevo Pipeline.
Locating the Subdomain
-
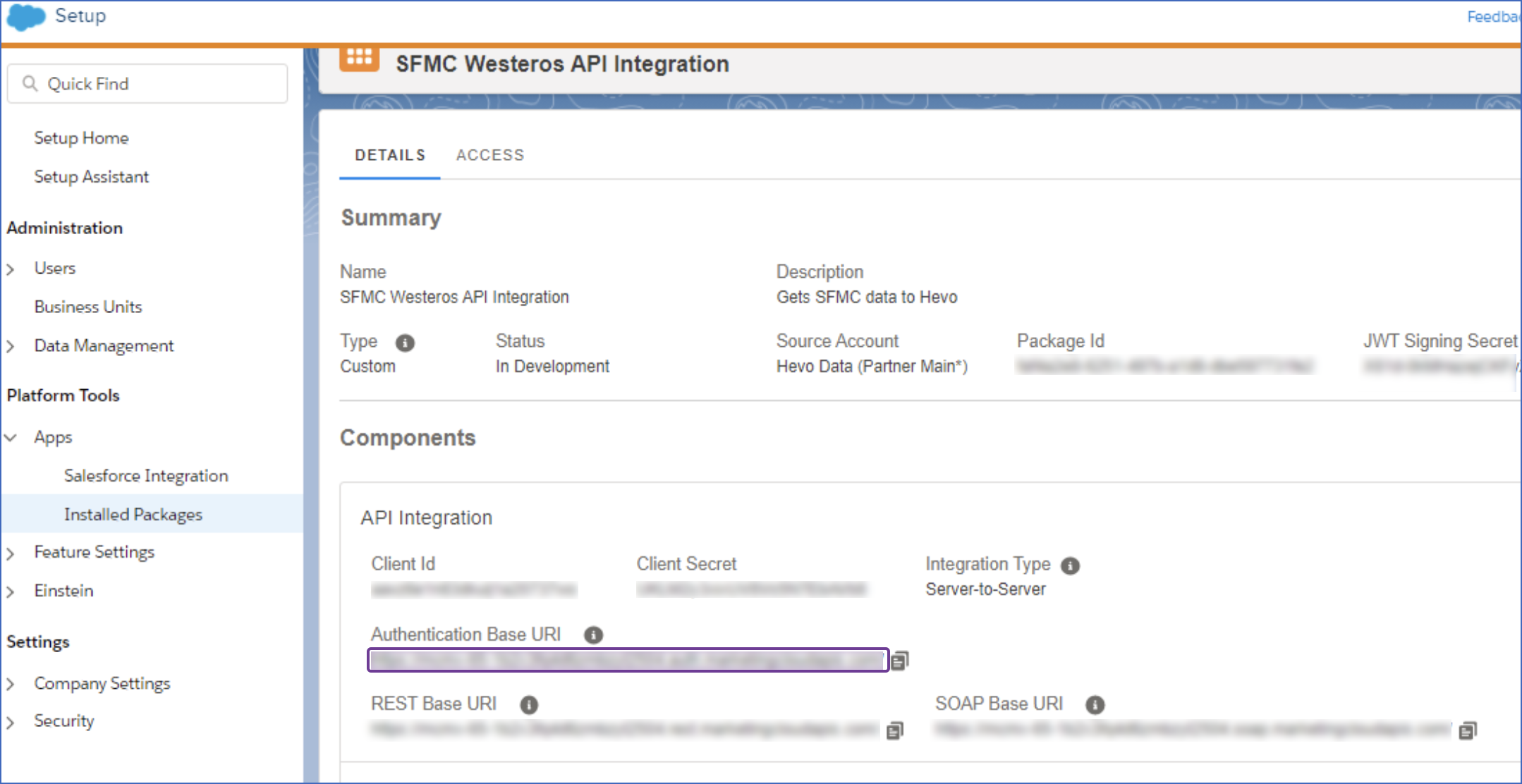
In the Components, API Integrations section, under Authentication Base URI, copy the subdomain URI and save it securely like any other password. Use this URI while configuring your Hevo Pipeline.
Configuring Salesforce Marketing Cloud as a Source
Perform the following steps to configure Salesforce Marketing Cloud as a Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + CREATE PIPELINE in the Pipelines List View.
-
On the Select Source Type page, select Salesforce Marketing Cloud.
-
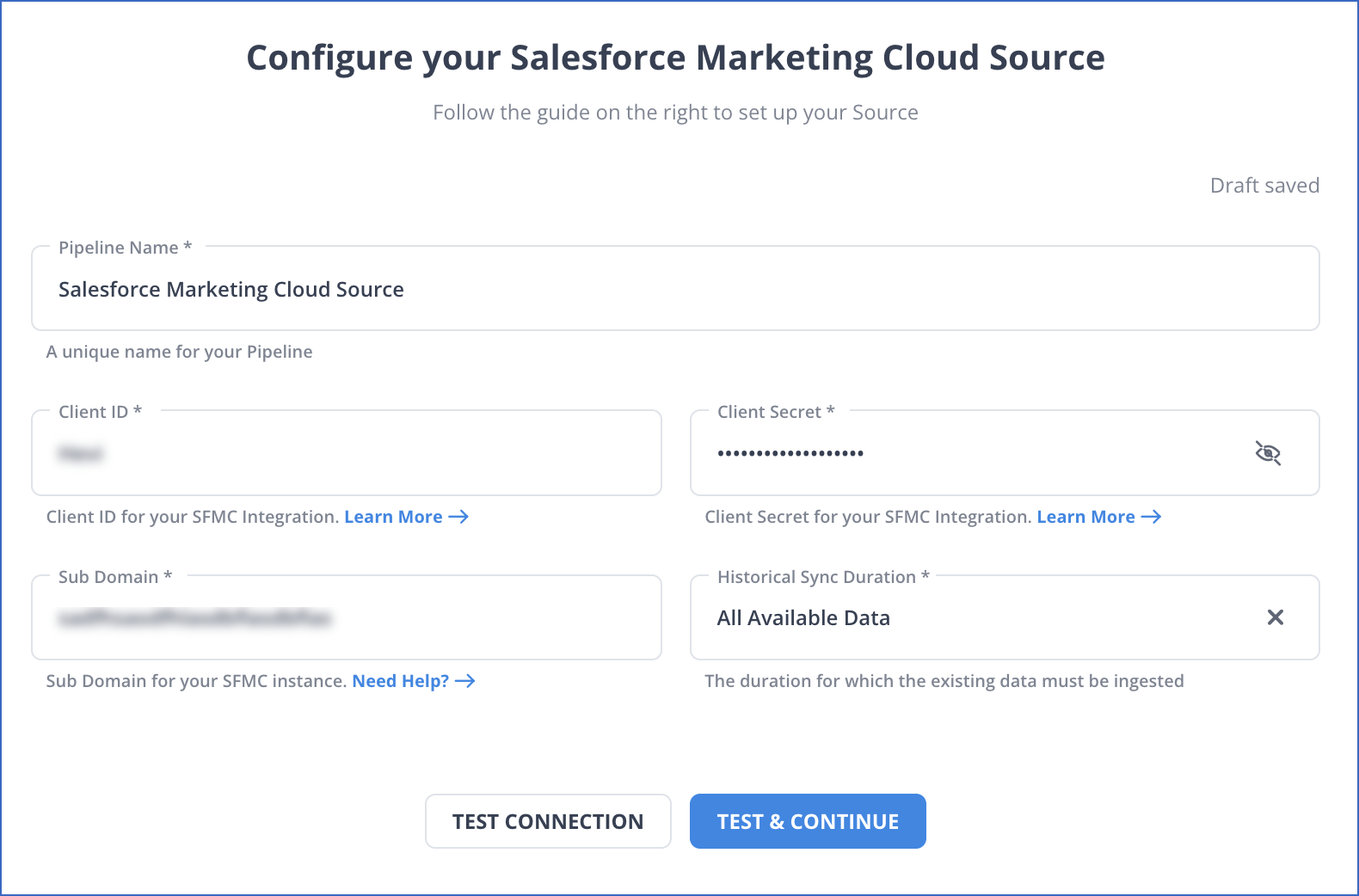
On the Configure your Salesforce Marketing Cloud Source page, specify the following:
-
Pipeline Name: A unique name for your Pipeline.
-
Client ID: The API token created in Salesforce Marketing Cloud to enable Hevo to read data from your account.
-
Client Secret: The API Secret Key for your API token.
-
Sub Domain: A domain name within your main domain based on the tenant type. It is a 28 character string that begins with
mc. Read Locating the Subdomain -
Historical Sync Duration: The duration for which you want to ingest the existing data from the Source. Default duration: All Available Data.
Note: If you select All Available Data, Hevo ingests all the data available in your Salesforce Marketing Cloud account since January 01, 2013.
-
-
Click TEST & CONTINUE.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 3 Hrs | 3 Hrs | 24 Hrs | 3-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: The first run of the Pipeline ingests historical data for the selected objects on the basis of the historical sync duration specified at the time of creating the Pipeline and loads it to the Destination. Default duration: All Available Data.
-
Incremental Data: Once the historical load is complete, new and updated records for all objects except Campaign, Campaign Asset, Journey, Activity, Email, and Outcome are ingested as per the ingestion frequency.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination:
Data Model
Hevo uses the following data model to ingest data from your Salesforce Marketing Cloud account:
| Object | Description |
|---|---|
| activity | An activity can be a message, a decision, an update, or a combination of these elements that makes a journey. Read journey object below. |
| campaign | Contains information about a campaign. |
| campaign_asset | Contains the list of assets associated with a campaign. |
| Contains the content of the email sent to the subscriber(s). | |
| event(sent), event(bounce), event(open), event(click) | Contains information about an event when an email is sent, bounced, opened, or clicked. |
| journey | Contains the customer lifecycle interaction events. A journey has a goal and an exit which enables you to estimate the efficiency of your campaigns. |
| link | Contains the link attached in the email sent to the subscriber(s). |
| link_send | Contains details about the link attached in the email sent. |
| list | Contains the list of subscribers. |
| list_subscriber | Contains the subscribers for a list or the lists for a subscriber. A subscriber can belong to multiple lists and vice versa. |
| outcome | Contains information about the outcome of an activity. |
| send | Contains information about the time you send an email or an SMS to the subscriber(s). |
| subscriber | Contains information about the person who has subscribed to an email. |
| triggered_send | Contains information about the first time an event is triggered. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
The earliest date from which the data is fetched is 1st Jan, 2013.
-
By default, all available historical data is synchronized.
-
In Salesforce Marketing Cloud, whenever an object changes, its ModifiedDate timestamp field gets updated. Hevo uses this field to identify Events for incremental ingestion. However, the UniqueClicks and UniqueOpens fields in the Send object do not trigger an update to the ModifiedDate, even when their values change. As a result, this object is not picked up during the incremental load, leading to a data mismatch.
As a workaround, you can use the OpenEvent and ClickEvent objects to retrieve the data for UniqueOpens and UniqueClicks based on the ModifiedDate. This is done using the SendID field which acts as a unique identifier for a specific event in the Send object, for example 12345.
To retrieve the count of UniqueOpens for the SendID 12345, query the OpenEvent object:
SELECT COUNT(DISTINCT subscriber_key) FROM open_event WHERE send_id = '12345'Similarly, to retrieve the count of UniqueClicks for the same SendID, query the ClickEvent object:
SELECT COUNT(DISTINCT subscriber_key) FROM click_event WHERE send_id = '12345'
Limitations
-
Hevo currently supports limited Salesforce Marketing Cloud objects. To view the total list of objects available in Salesforce Marketing Cloud, see this.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Dec-23-2024 | NA | Updated the Source Considerations section to specify behavior of Send object. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Feb-20-2023 | NA | Updated section, Configuring Salesforce Marketing Cloud as a Source to update the information about historical sync duration. |
| Dec-07-2022 | NA | Updated section, Data Replication to reorganize the content for better understanding and coherence. |
| Oct-25-2021 | NA | Added the Pipeline frequency information in the Data Replication section. |
| Jul-26-2021 | NA | Added a note in the Overview section about Hevo providing a fully-managed Google BigQuery Destination for Pipelines created with this Source. |
| Feb-22-2021 | NA | Updated the Limitations section to specify support for limited SFMC objects. |