FTP / SFTP
On This Page
You can load data from files in an FTP location into your Destination database or data warehouse using Hevo Pipelines.
Hevo automatically unzips any Gzipped files on ingestion. Further, files are re-ingested if updated, as it is not possible to identify individual changes.
As of Release 1.66, __hevo_source_modified_at is uploaded to the Destination as a metadata field. For existing Pipelines that have this field:
-
If this field is displayed in the Schema Mapper, you must ignore it and not try to map it to a Destination table column, else the Pipeline displays an error.
-
Hevo automatically loads this information in the
__hevo_source_modified_atcolumn, which is already present in the Destination table.
You can, however, continue to use __hevo_source_modified_at to create transformations using the function event.getSourceModifiedAt(). Read Metadata Column __hevo_source_modified_at.
Existing Pipelines that do not have this field are not impacted.
Configuring FTP/SFTP as a Source
Perform the following steps to configure FTP/SFTP as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select FTP/SFTP.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Configure your FTP/SFTP Source page, specify the following:

-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Type: The network protocol for ingesting files. For example, FTP (File Transfer Protocol).
-
Host: The IP address or the DNS for your network protocol location.
-
Port: The port on which your network protocol server is listening for connections. Default value: 21.
-
User: The user ID for logging in to the network protocol server.
-
Password: The password of the user logging in to the network protocol server.
Note: This field is optional if you selected Type as SFTP above. However, you must add the public key displayed on the UI to the
.ssh/authorized\_keysfile on your SFTP server. -
Path Prefix: The prefix of the path for the directory that contains your data. By default, the files are listed from the root of the directory.
-
File Format: The format of the data file in the Source. Hevo supports the CSV, JSON, TSV, and XML file formats to ingest data.
Note: You can select only one file format at a time. If your Source data is in a different format, you can export the data to either of the supported formats and then ingest the files.
Based on the format you select, you must specify some additional settings:
-
Field Delimiter: The character on which the fields in each line are separated. For example,
\tor,.This field is visible only for CSV data.
-
Treat first row as column headers: If enabled, Hevo identifies the first row in your CSV file and uses it as a column header rather than an Event.
If disabled, and if your Source data file does not contain column headers, Hevo automatically creates them during ingestion. Default setting: Enabled. Refer to section, Example.
This field is visible only for CSV data.
-
Create Events from child nodes: If enabled, Hevo loads each node present under the root node in the XML file as a separate Event.
If disabled, Hevo combines and loads all nodes present in the XML file as a single Event.
This field is visible only for XML data.
-
-
Include compressed files: If enabled, Hevo also ingests the compressed files of the selected file format from the folders. Hevo supports the tar.gz and zip compression types only.
If disabled, Hevo does not ingest any compressed files present in the selected folders.
This field is visible for all supported data formats.
-
Create Event Types from folders: If enabled, Hevo ingests each subfolder as a separate Event Type. By default, data from all selected folders is ingested. However, if you do not want Hevo to ingest data from certain folders, you can skip them from the Pipeline Overview page.
Note: Files lying at the prefix path (and not in a subdirectory) are ignored.
If disabled, Hevo merges the subfolders into their parent folders and ingests them as one Event Type. Default setting: Disabled.
This field is visible for all supported data formats.
-
Connect Through SSH: Enable this option to connect to Hevo using an SSH tunnel, instead of directly connecting your network protocol host to Hevo. This provides an additional level of security to your database by not exposing your network protocol setup to the public. Read Connecting Through SSH.
If this option is disabled, you must whitelist Hevo’s IP addresses to allow Hevo to connect to your network protocol host.
-
Convert date/time format fields to timestamp: If enabled, Hevo converts the date/time format within the files of selected folders to a timestamp. For example, the date/time format 07/11/2022, 12:39:23 converts into timestamp 1667804963.
If disabled, Hevo ingests the datetime fields in the original format.
This field is visible for all supported data formats.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 5 Mins | 5 Mins | 3 Hrs | NA |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Example: Automatic Column Header Creation for CSV Tables
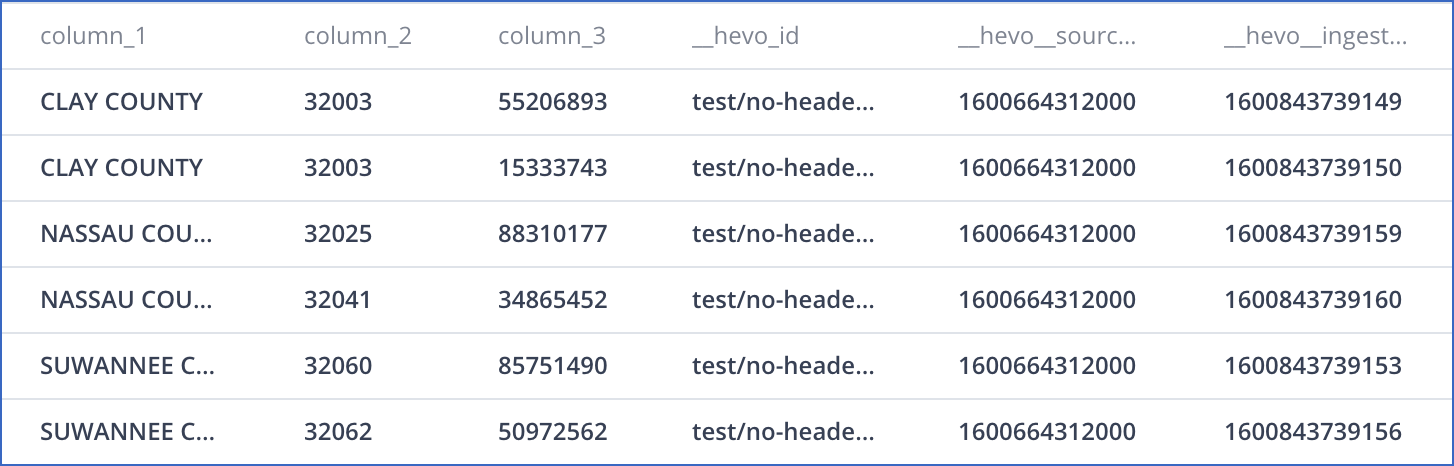
Consider the following data in CSV format, which has no column headers.
CLAY COUNTY,32003,11973623
CLAY COUNTY,32003,46448094
CLAY COUNTY,32003,55206893
CLAY COUNTY,32003,15333743
SUWANNEE COUNTY,32060,85751490
SUWANNEE COUNTY,32062,50972562
ST JOHNS COUNTY,846636,32033,
NASSAU COUNTY,32025,88310177
NASSAU COUNTY,32041,34865452
If you disable the Treat first row as column headers option, Hevo auto-generates the column headers, as seen in the schema map here:

The record in the Destination appears as follows:
Limitations
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
-
If you initially configure the Source to ingest data from a specific path prefix, such as a folder or directory path, and later update it to a different prefix, Hevo treats the new prefix as a separate data root. This triggers a new historical load for all files under the updated path, even if those files were previously ingested through the earlier configuration.
To avoid duplicate ingestion, you can skip the historical load and configure the child folders to resume from a specific point using the Change Position option. Any data ingested using the Change Position action is billable.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-06-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring FTP/SFTP as a Source as per the latest UI. |
| Jul-30-2025 | NA | Added information about skipping Event Types to the Create Event Types from folders option in the Configuring FTP/SFTP as a Source section. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jun-02-2025 | NA | Updated section, Limitations to add a point about new historical loads when changing the path prefix. |
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Sep-21-2023 | NA | Updated section, Configuring FTP/SFTP as a Source for better clarity. |
| Nov-08-2022 | NA | Updated section, Configuring FTP/SFTP as a Source to add information about the Convert date/time format fields to timestamp option. |
| Sep-21-2022 | NA | Added a note in section, Configuring FTP / SFTP as a Source. |
| Apr-11-2022 | 1.86 | Updated section, Configuring FTP/SFTP as a Source to reflect support for TSV file format. |
| Mar-21-2022 | 1.85 | Removed section, Limitations as Hevo now supports UTF-16 encoding format for CSV files. |
| Oct-25-2021 | NA | Added the section, Data Replication. |
| Jun-28-2021 | 1.66 | Updated the page overview with information about __hevo_source_modified_at being uploaded as a metadata field from Release 1.66 onwards. |
| Feb-22-2021 | NA | Added the limitation about Hevo not supporting UTF-16 encoding format for CSV data. |