Jira Cloud
On This Page
Jira is a project management tool from Atlassian, used for tracking tasks, issues, and bugs, and work progress of teams. Jira has two platforms: Jira Server and Jira Cloud. Each of these has various flavours, such as Jira Service Desk, Jira Software, and Jira Core. Jira Cloud is the cloud platform for Jira.
Prerequisites
-
An Atlassian Jira Cloud instance from which data is to be ingested exists.
-
READ permissions on the data to be ingested for the authenticated user.
-
The API token is available to authenticate Hevo on your Jira Cloud account.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Creating the API Token
You require an API token to authenticate Hevo on your Jira Cloud account.
Note: You must log in as a user with READ permissions to perform these steps.
Create an API token from your Atlassian account:
-
Log in to your account.
-
On the API Tokens page, click Create API token.
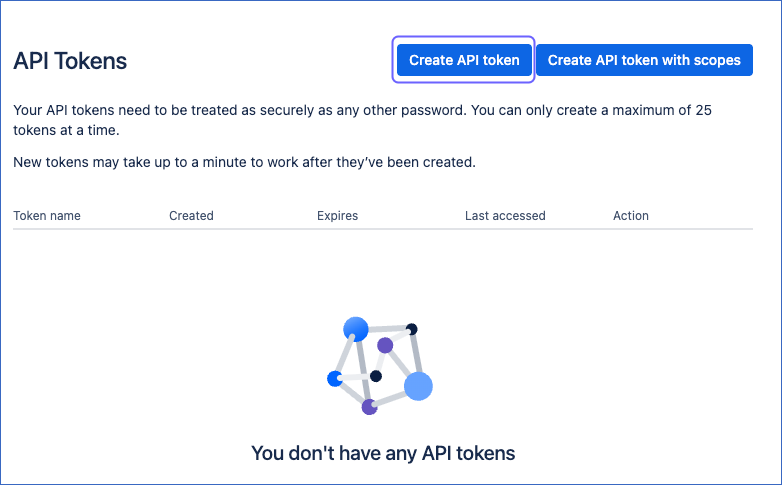
-
In the dialog that appears, specify the following:
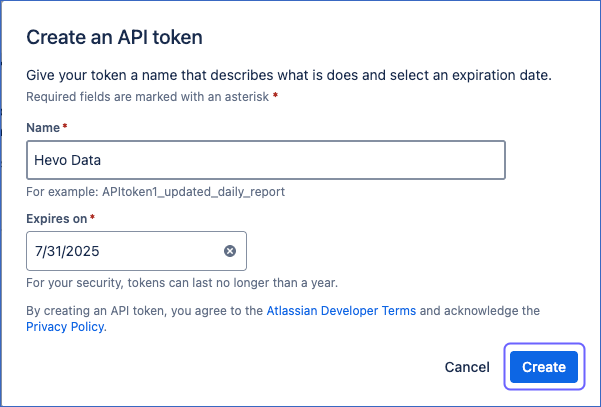
- Name: A short and easy to remember name for your API token.
- Expires on: The date on which your API token will expire.
-
Click Create.
-
Click Copy to copy the token, and save it securely like any other password. Use this token while configuring your Hevo Pipeline.

Note: For security reasons, it is not possible to view the token after closing the creation dialog. If necessary, you can create a new token.
Configuring Jira Cloud as a Source
Perform the following steps to configure Jira as a Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Jira Cloud.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Configure your Jira Cloud Source page, specify the following:

-
Pipeline Name: A unique name for your Pipeline.
-
API Token: The API token that you created in your Atlassian account. This authorizes Hevo to read data from your Jira account.
-
User Email: The email ID linked to your Jira account.
-
Site Name: Your Jira site name. Extract this from your dashboard URL. For example, if your dashboard URL is https://mycompany.atlassian.net/jira/dashboards/, your site name is mycompany.
-
Historical Sync Duration: The duration for which you want to ingest existing data from the Source. This cannot be changed after the Pipeline is created. Default duration: 3 Months.
Note: If you select All Available Data, Hevo ingests all the data available in your Jira Cloud account since January 01, 2000.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 1 Hr | 30 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data:
-
For existing Pipelines: In the first run of the Pipeline, Hevo ingests the data from the beginning of time for all the objects in your Jira Cloud account.
-
For Pipelines created after Release 1.80: You can select the Historical Sync Duration as per your requirement while creating a Pipeline. Default duration: 3 Months.
-
-
Incremental Data: Once the historical load is complete, all new and updated records for the Issue object are ingested as per the ingestion frequency. The remaining objects are ingested in Full Load mode.
Note: From Release 1.86, Hevo ingests only new and updated data for Full Load objects to optimize the quota consumption. This feature is currently available on request only. You need to contact Hevo Support to enable it for your team.
Custom frequency for Full Load objects
Hevo allows you to set the ingestion frequency for Full Load objects separately from the Pipeline ingestion frequency. You can reduce your Events quota consumption by ingesting Full Load objects at a lower frequency without affecting other objects in the Pipeline. Read Query Modes and Events Quota Consumption to know how different query modes affect your Events quota consumption.
You can identify the Full Load objects in the Pipelines Detailed View by the FL tag corresponding to their name. Alternatively, you can view only Full Load objects in your Pipeline by selecting Full Load from the Filter ( ![]() ) menu.
) menu.

Perform the following steps to set a custom ingestion frequency for Full Load objects:
-
In the Pipelines Detailed View, click the More (
 ) icon to open the Pipeline’s Action menu and click Change Schedule.
) icon to open the Pipeline’s Action menu and click Change Schedule.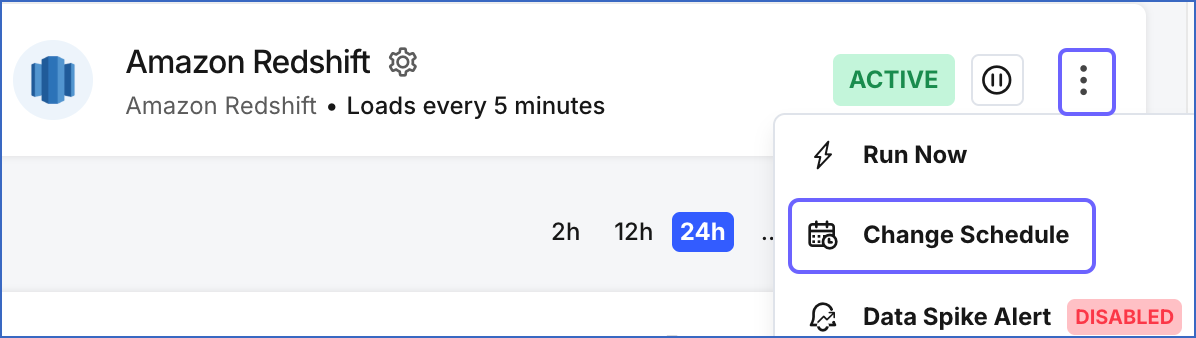
-
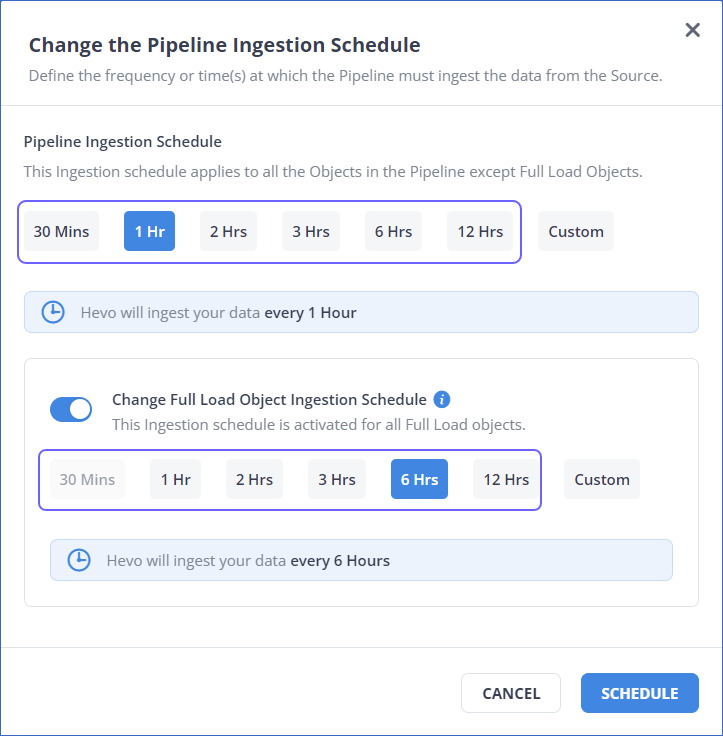
In the Change the Pipeline Ingestion Schedule pop-up window, enable the Enable Full Load Object Ingestion Schedule option.

Note:
- For custom frequency, this option is available only when Run at fixed interval is selected.
- If your Pipeline ingests data from Full Load objects on an independent schedule, manual actions such as Run Now and Restart Object are automatically deferred to the next ingestion schedule. To run any of these actions immediately, turn off the Full Load Object Ingestion Schedule option, trigger the required action, and then re-enable the schedule.
-
Select the ingestion frequency for the Full Load objects as per your requirements. You can select Custom and define the ingestion frequency by specifying an integer value in hours.
Note: Full Load objects can be ingested at a frequency more than or equal to the Pipeline’s ingestion frequency.

-
Click Schedule.
The updated schedule is applied immediately.
Note: The following image displays the frequencies suggested by Hevo for teams created before Release 2.21:
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination. For a detailed view of the objects, fields, and relationships, click the ERD.

Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline.
| Table Name | Description |
|---|---|
| board | Displays issues from one or more projects, allowing you to view, manage, and report work in progress. This table includes only the boards that the user has permission to view. |
| board_issue | IDs of all issues within a given board ID, which the user has permission to view. Note: Epic issues do not belongs to the scrum boards. |
| board_project | All the projects, ordered by name, that are associated with a given board ID. If you do not have permission to view the board, no project is loaded. |
| component | All components in a project. |
| issue | All work-related information relating to a unit of work. This includes the description of the work to be done, its duration, type, assignee, and importance. Note: The custom fields created in an issue have the prefix custom_ in the field name. |
| issue_changelog | A paginated list of all change logs for an issue, starting from the oldest. This also includes the meta data related to the changes. |
| issue_comment | All comments logged by users for an issue. |
| issue_component | The mapping between issues and project components. This is a custom table generated by Hevo to maintain data sanity. |
| issue_fix_version | The mapping between issues and project versions. This is a custom table generated by Hevo to maintain data sanity. |
| issue_label | All the labels assigned to an issue. |
| issue_link | All the relational information between two issues. |
| issue_link_type | The definitions of all relations that exist between two issues. Note: The issue linking option must be enabled. |
| issue_subtask | All the subtasks related to a particular issue ID. |
| issue_type | All issue types, such as bug, task, or story. |
| issue_version | The mapping between issues and project versions. This is a custom table generated by Hevo to maintain data sanity |
| issue_watcher | The users who are watching the developments for an issue. Note: The Allow users to watch issues option must be enabled. |
| issue_worklog | The work logs for an issue, starting from the oldest work log or from the work log started on or after a date and time. Whenever an issue is updated, the work log object related to it is ingested from the beginning of time. Note: Time tracking must be enabled in Jira for this data to be fetched. |
| priority | The list of all priorities that are assigned to an issue. |
| project | The collection of issues that share a common project lead. |
| project_category | The list of all project categories. |
| resolution | The list of all resolution values that are assigned to an issue. |
| status | The list of all statuses associated with workflows. |
| status_category | The list of all status categories. Each status belongs to a status category. |
| sprint | All sprints associated with a given board ID. This includes only sprints that the user has permission to view. Note: Hevo automatically ingests data only from Scrum board type. To ingest data from Simple and Kanban board types, contact Hevo Support. |
| user | The list of all (active and inactive) users. |
| version | All versions in a project. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
Jira’s REST APIs do not support identifying deleted issues due to which Hevo is unable to update the Events for deleted issues and they continue to remain in your Destination table. As a result, you see more Events in the Destination than in the Source.
Limitations
-
Only Jira Core and Jira Software are currently supported.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Apr-28-2026 | NA | Updated section, Configuring Jira Cloud as a Source to mention that the historical sync duration cannot be changed after the Pipeline is created. |
| Nov-07-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring Jira Cloud as a Source as per the latest UI. |
| Jul-08-2025 | NA | Updated section, Creating the API Token as per the latest Jira Cloud UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| May-22-2025 | NA | Updated section, Custom frequency for Full Load objects to add a note about the behavior of manual ingestion actions. |
| Mar-10-2025 | 2.33.3 | - Updated the Limitations section to remove the limitation on the Sprint object. - Added a note in the Data Model section to indicate support for ingesting Simple and Kanban board types in the Sprint object. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Nov-25-2024 | NA | Updated section, Limitations to add a limitation on data ingestion for the Sprint object. |
| Nov-05-2024 | NA | Updated sub-section, Custom frequency for Full Load objects as per the latest Hevo UI. |
| Mar-05-2024 | 2.21 | - Added the ingestion frequency table in the Data Replication section. - Updated the Custom frequency for Full Load objects section with suggested frequencies for teams before and after Release 2.21. |
| Feb-20-2023 | NA | Updated section, Configuring Jira Cloud as a Source to update the information about historical sync duration. |
| Sep-21-2022 | 1.98 | Added section, Custom frequency for Full Load objects to inform users about the option to change ingestion frequency for Full Load objects. |
| Jul-27-2022 | NA | Updated Note in section, Data Replication. |
| May-10-2022 | NA | Provided additional detail to extract the site name in the Configuring Jira Cloud as a Source section. |
| Apr-11-2022 | 1.86 | - Added a note in section, Data Replication to inform about optimized quota consumption for Full Load objects. - Added the Source Considerations section to reflect Jira’s REST APIs limitation. |
| Jan-24-2022 | 1.80 | Added information about configurable historical sync duration in the Data Replication section. |