Klaviyo v2
On This Page
Hevo has updated the Klaviyo v2 integration to support API Version 2026-01-15, which expands subscription consent handling and modifies the structure of certain Campaign and Message responses.
These updates introduce additional subscription channels and consent types for profiles and modify how message content and campaign configuration fields are returned by the API.
From Release 2.46 onwards, Hevo supports the updated schema and continues ingesting data into the corresponding Destination tables.
The following updates are included in this change:
Note: Related fields that start with the same name are represented using * for brevity. For a complete list of all affected objects and fields, refer to the Schema and Primary Keys section.
| Object | Changes |
|---|---|
| profile_v2 |
Added Fields: locale, subscriptions_sms_transactional_*, subscriptions_mobile_push_*, subscriptions_whatsapp_* Modified Fields: subscriptions_email_double_optin field data type changed from string to boolean. |
| campaign_v2 |
Added Fields: send_strategy_datetime, send_strategy_options_is_local, send_strategy_options_send_past_recipients_immediately, tracking_options_add_tracking_params, tracking_options_custom_tracking_params Replaced Fields: tracking_options_is_add_utm with tracking_options_add_tracking_params, tracking_options_utm_params with tracking_options_custom_tracking_params Deleted Fields: send_strategy_options_static_datetime, send_strategy_options_static_is_local, send_strategy_options_static_send_past_recipients_immediately, send_strategy_options_throttled_datetime, send_strategy_options_sto_date, send_strategy_options_throttled_throttle_percentage |
| campaign_utm_param_v2 | Added Fields: type |
| campaign_messages_v2 | Replaced Fields: content.* with definition.* |
| flow_messages_v2 | Replaced Fields: content.* with definition.*, name with definition_name |
| flow_action_v2 |
Added Fields: data Modified Fields: action_type field values updated to lowercase hyphen format |
| campaign_mobile_push_v2 | New object added |
Note:
- Historical data already ingested into your Destination tables is not affected.
- Existing Pipelines continue to run without requiring configuration changes. New columns are automatically added to the Destination tables. Columns that are deleted or replaced remain in the tables but are populated with NULL for new data.
Klaviyo is an email marketing platform that offers both email and SMS marketing automation.
You can replicate data from your Klaviyo account to the Destination database or data warehouse using Hevo Pipelines.
Prerequisites
-
An active Klaviyo account from which data is to be ingested exists.
-
The API key is available to allow Hevo to connect to your Klaviyo account.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Creating the API Key
You require an API key to authenticate Hevo on your Klaviyo account. The API key does not expire and can be reused for all your Pipelines. You can retrieve the key from your Source administrator or create one.
Note: To create API keys, you must have Owner, Admin, or Manager user role on the account.
To create the API key:
-
Log in to your Klaviyo account.
-
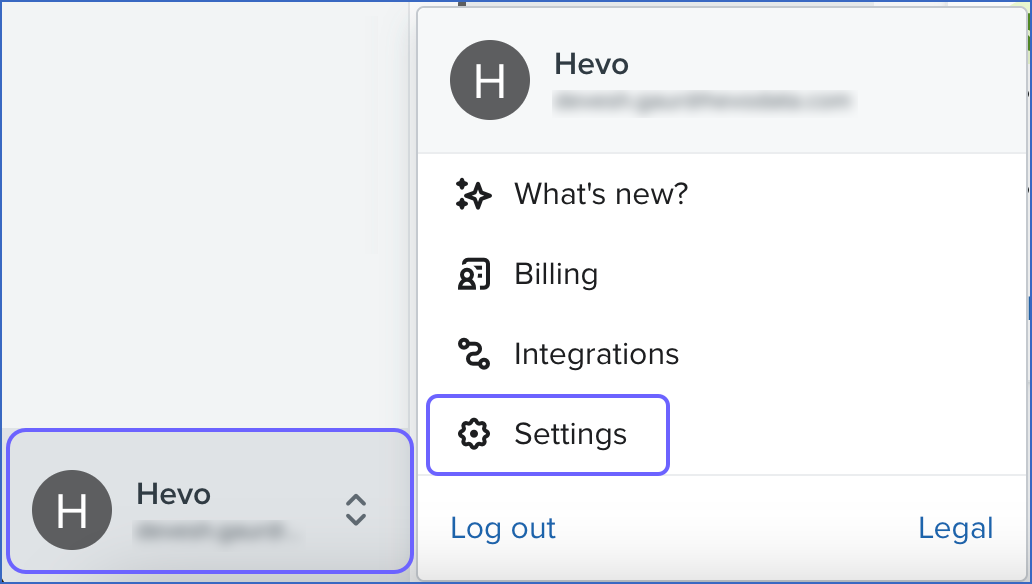
Scroll to the bottom of the left navigation pane, click the Profile icon, and then click Settings.
-
In the Settings page, Account tab, click API keys.

-
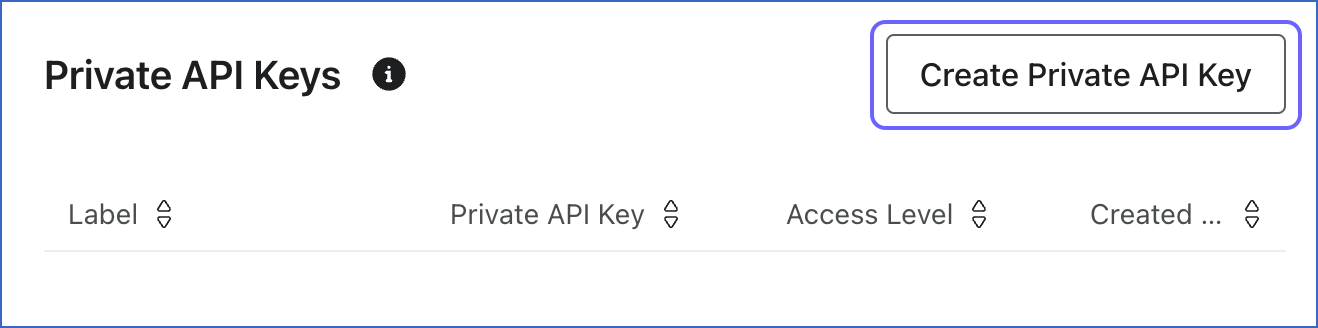
In the Private API Keys section, click Create Private API Key.
-
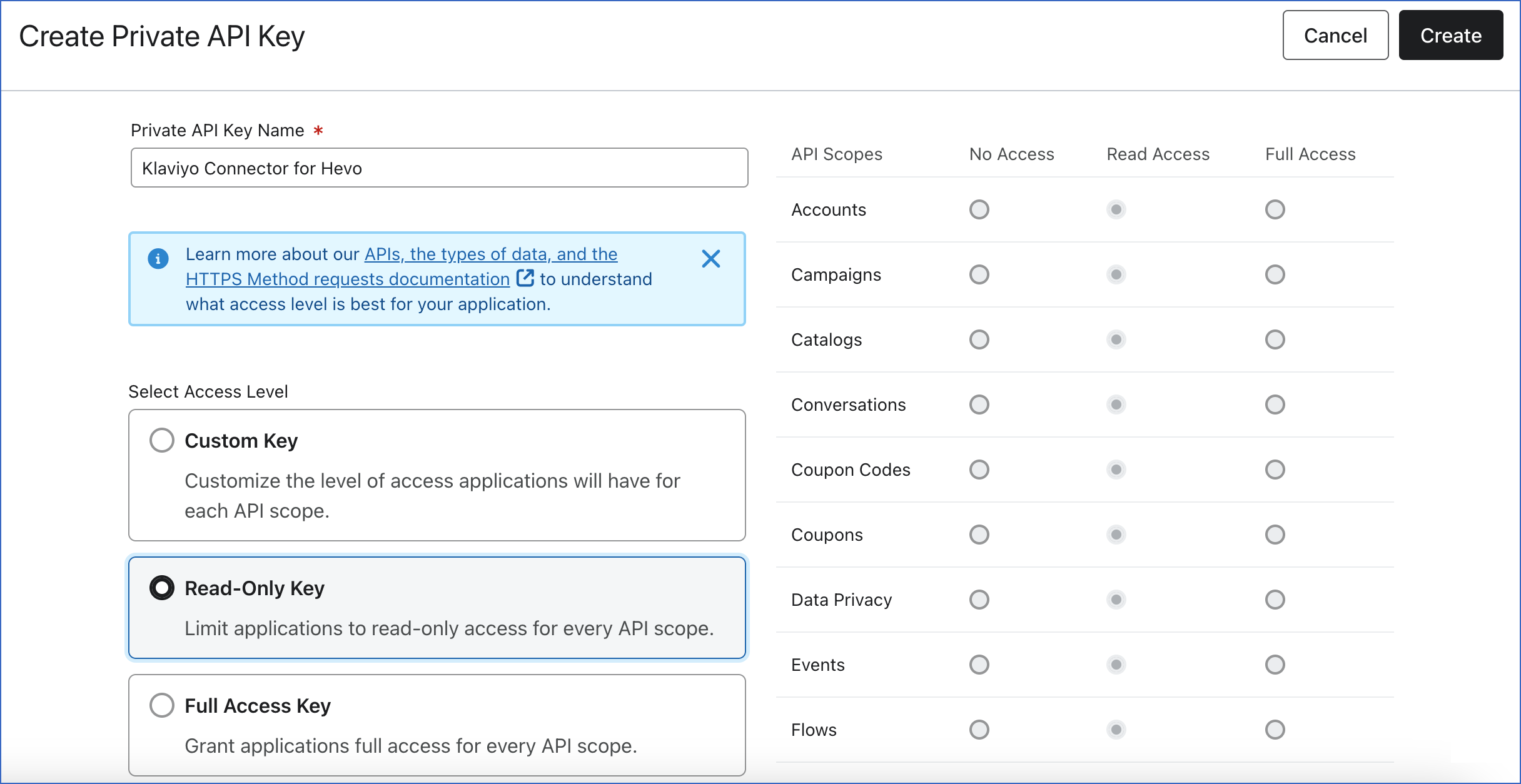
On the Create Private API Key page, do the following:
-
In the Private API Key Name field, specify a name for the API key. For example, Klaviyo Connector for Hevo.
-
In the Select Access Level section, specify one of the following:
-
Read-Only Key: This level provides read-only access for every API scope.
-
Custom Key: This level provides the selected access only for the specified API scopes. If you select this option, you must provide Read Access for the following API scopes:
-
Campaigns
-
Events
-
Flows
-
List
-
Metrics
-
Profiles
-
Segments
-
Templates
-
-
-
Click Create.
-
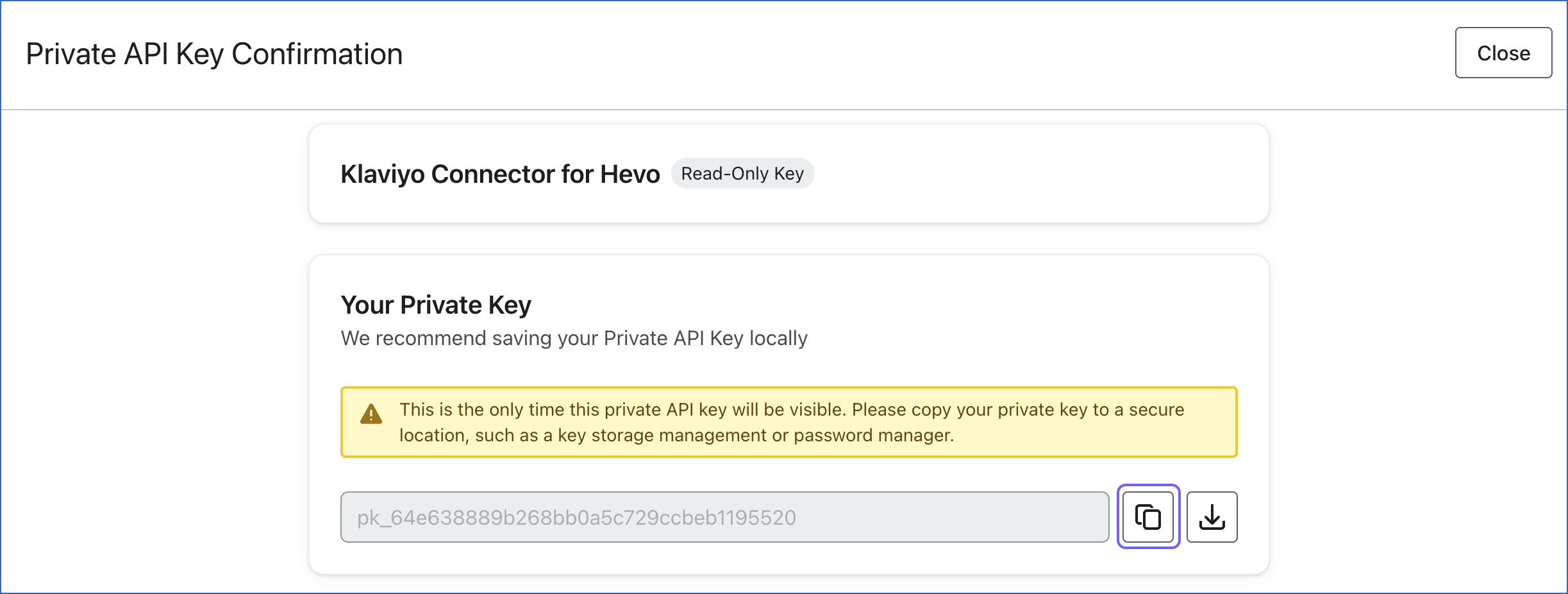
On the Private API Key Confirmation page, click the copy icon to copy the key, and save it securely like any other password. Use this key while configuring your Hevo Pipeline.
-
Configuring Klaviyo v2 as a Source
Perform the following steps to configure Klaviyo v2 as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Klaviyo v2.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Configure your Klaviyo v2 Source page, specify the following:

-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Private API Key: The API key that you obtained from your Klaviyo account.
-
Historical Sync Duration: The duration for which you want to ingest existing data from the Source. This cannot be changed after the Pipeline is created. Default duration: 3 Months.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 6 Hrs | 1 Hr | 48 Hrs | 1-48 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: The first run of the Pipeline ingests historical data for the selected objects on the basis of the historical sync duration specified at the time of creating the Pipeline and loads it to the Destination. Default duration: 3 months.
-
Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency in Full Load or Incremental mode, as mentioned in the table below.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination. For a detailed view of the objects, fields, and relationships, click the ERD.
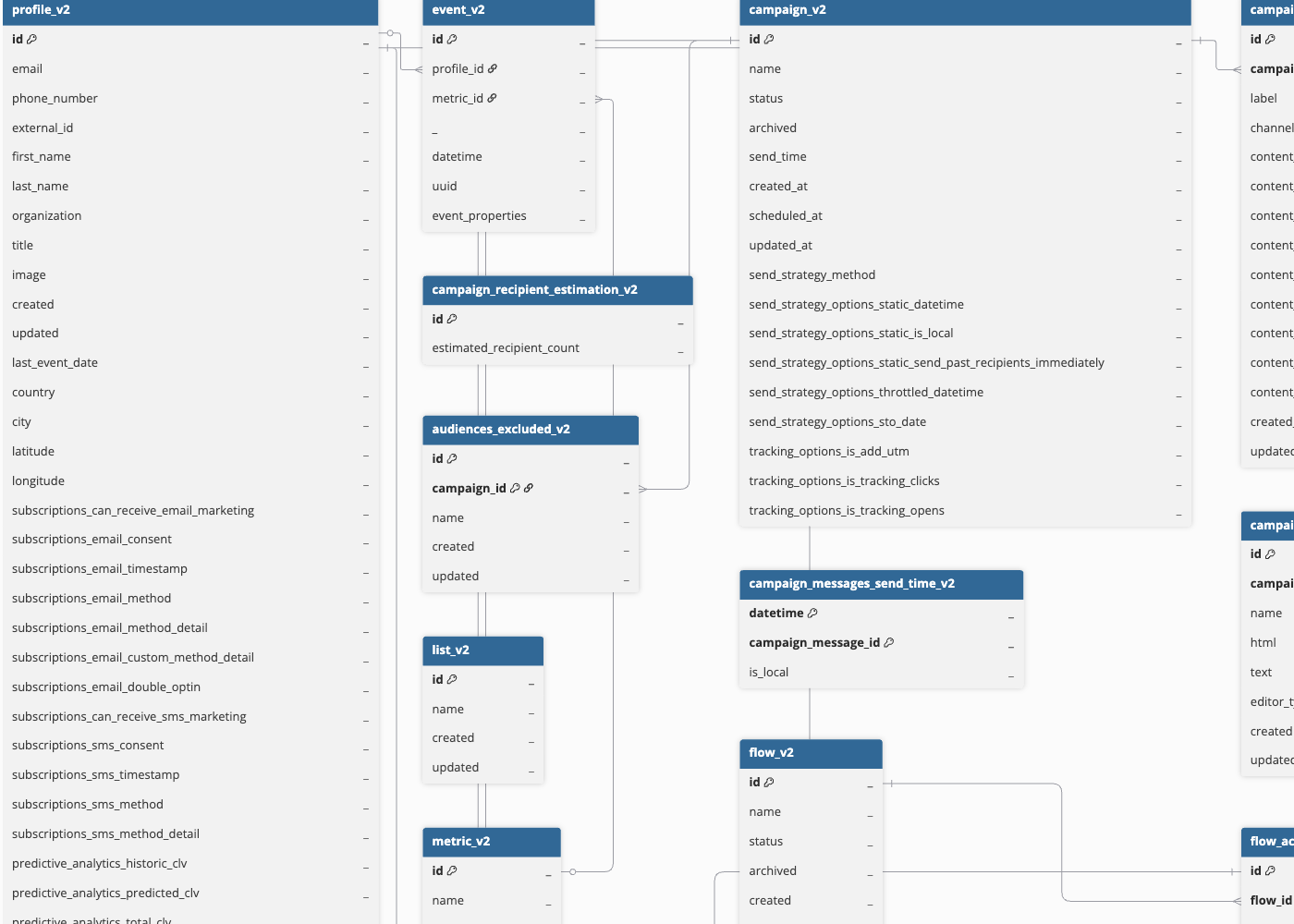
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
| Object | Mode | Description |
|---|---|---|
| profile_v2 | Incremental | Contains details of the contacts stored in your Klaviyo account, which includes a profile identifier such as the email or phone number and additional information such as the first name, last name, and location. |
| event_v2 | Incremental | Contains details of the actions taken by the profiles in your Klaviyo account. These actions are represented as timestamped records. |
| metric_v2 | Full Load | Contains details of the categories to which the events captured on your Klaviyo account belong. Metrics are the groupings for events of the same name. For example, all events called Placed Order will be grouped under the Placed Order metric. |
| list_v2 | Incremental | Contains details of the static lists into which the profiles in your Klaviyo account are organized. A profile may be assigned to multiple lists or may not belong to any list. |
| segment_v2 | Incremental | Contains details of the dynamic segments into which the profiles in your Klaviyo account are organized. A profile is added or removed from segments based on whether it meets the criteria defined for each segment. |
| profile_list_v2 | Incremental | Contains details of the lists that a profile in your Klaviyo account is part of. |
| profile_segment_v2 | Incremental | Contains details of the segments that a profile in your Klaviyo account is part of. |
| flow_v2 | Incremental | Contains details of all the automated sequences defined within your Klaviyo account. These sequences, referred to as flows, consist of automated actions such as sending pre-configured emails or SMS messages, triggered by specific user actions. |
| flow_action_v2 | Incremental | Contains details of the actions triggered when a flow’s conditions are met. For example, in a flow defined for abandoned carts, a flow action can be to send an email reminding individuals to complete their purchase. |
| flow_messages_v2 | Incremental | Contains details of the messages sent as part of a flow action. |
| campaign_v2 | Full load | Contains details of the scheduled messages sent to a target audience, which is defined as a list or segment in Klaviyo. For example, a sale announcement through SMS. The details of a campaign include its type, status, and the schedule for sending emails. |
| campaign_mobile_push_v2 | Incremental | Contains details of the mobile notification sent to users who opted in to receive push notifications on their devices, inlcuding the notification status, scheduling details, and associated messages for a campaign. |
| campaign_utm_param_v2 | Full load | Contains details of the tracking parameters, such as clicks and opens, for a campaign. |
| audience_included_v2 | Full load | Contains details of the profiles subscribed to a campaign. |
| audience_excluded_v2 | Full load | Contains details of the profiles that are not subscribed to a campaign |
| campaign_messages_v2 | Full load | Contains details of all the messages that belong to a campaign. |
| campaign_message_template_v2 | Full load | Contains details of the template used by a campaign message. |
| campaign_message_send_time_v2 | Full load | Contains details of the date and time when the messages for a campaign are sent. |
| campaign_recipient_estimation_v2 | Full load | Contains details of the count of recipients who are expected to receive the campaign. |
Note: The Change Position option is available only for the incremental objects, event_v2, flow_v2, profile_v2, list_v2, and segment_v2.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Limitations
-
If an existing profile is added to a new list or segment, this information is not captured during the incremental load. Hence, although
profile_list_v2andprofile_segment_v2are incremental objects, Hevo syncs the historical data for these objects once a week to capture such information. -
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Apr-28-2026 | NA | Updated section, Configuring Klaviyo V2 as a Source to mention that the historical sync duration cannot be changed after the Pipeline is created. |
| Mar-09-2026 | 2.46 | Updated the warning container in the overview section and the Data Model to add information about the Klaviyo v2 API upgrade. |
| Nov-07-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring Klaviyo v2 as a Source as per the latest UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| May-06-2024 | 2.23.1 | New document. |