Parsing Nested JSON Fields in Events
On This Page
To load JSON-formatted Source data to the Destination, you must select how Hevo must parse the nested fields, objects, and arrays so that these are read correctly. The parsing strategy depends upon the Destination type and is independent of the Pipeline mode or the data Source.
You can select the parsing strategy as the last step of creating your Pipeline. If only one strategy is available, it is applied by default and no selection is required, as in the case of Amazon Redshift, Aurora MySQL, MySQL, Postgres, and Snowflake Destinations.
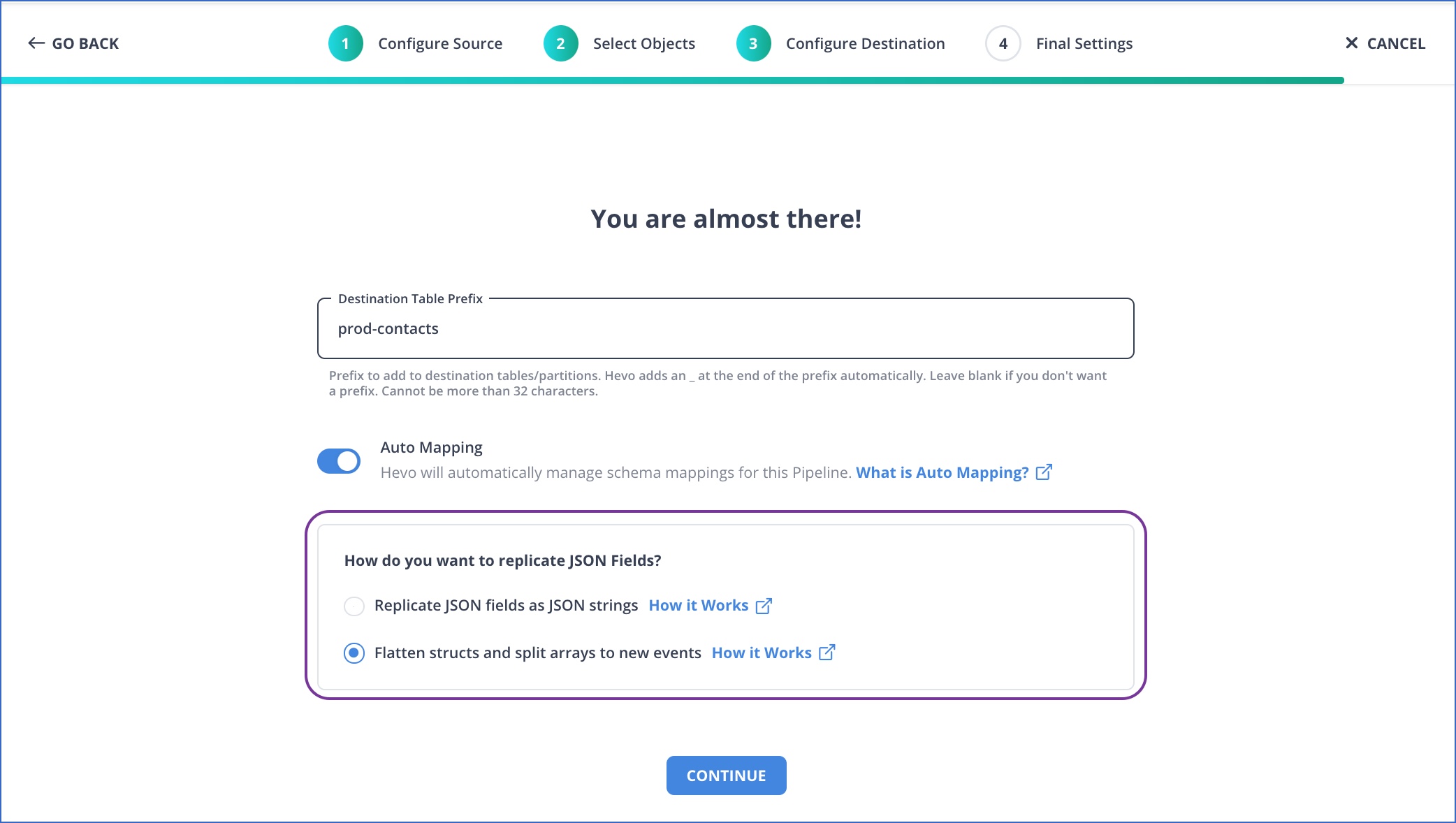
The following table lists the parsing strategies that Hevo supports for each Destination, the first option being the default one in each case:
| Destinations | Parsing Strategies |
|---|---|
| SQL Server | - Flatten structs and split arrays to new Events - Replicate JSON fields as JSON strings and array fields as strings |
| Amazon Redshift | - Replicate JSON fields to JSON column - Replicate JSON fields as JSON strings and array fields as strings |
| PostgreSQL, Snowflake | - Replicate JSON fields to JSON column |
| Aurora MySQL, MySQL | - Replicate JSON fields to JSON columns - Replicate JSON fields as JSON strings and array fields as strings |
| Google BigQuery | Two of the following are displayed based on the Source Type: - Replicate JSON structure as is, while collapsing arrays into strings - Replicate JSON structure as is, while collapsing nested arrays into strings - Replicate JSON fields as JSON strings and array fields as strings |
| Azure Synapse Analytics, Databricks | - Replicate JSON fields as JSON strings and array fields as strings |
Example
Consider a sample orgs object that contains multiple fields, child objects, and arrays in different nesting orders. Its format in different Sources is illustrated below. The example explores how this data is replicated based on the parsing strategy that is selected.
Sample Data Structure 1
The following is the orgs object as it appears in MongoDB:
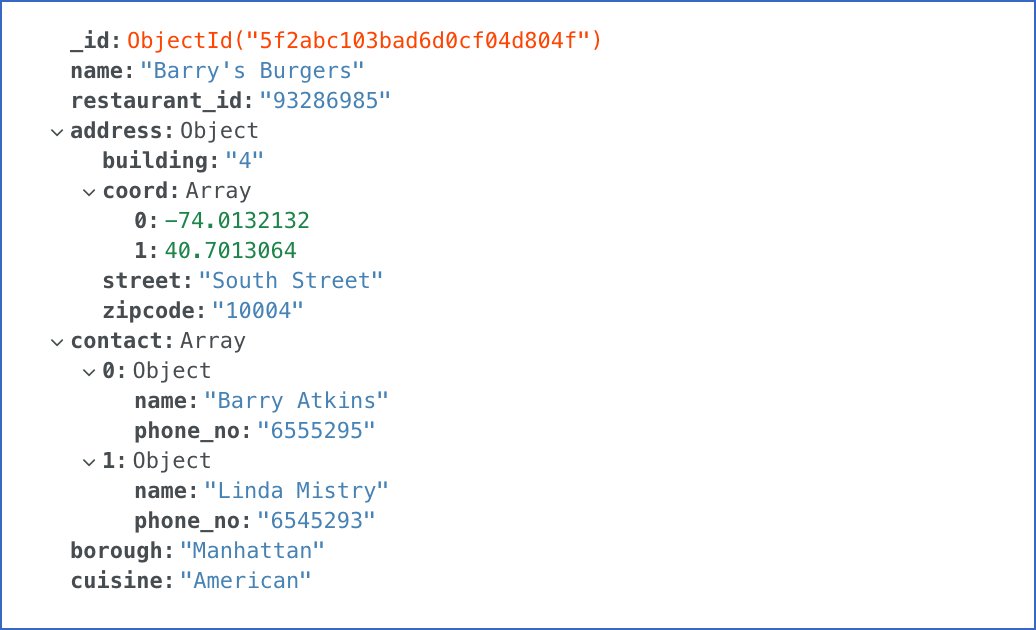
Sample Data Structure 2
The following is the orgs object as it appears in Sources such as MySQL and PostgreSQL:

The following sections help you understand how the replicated data appears in the Destination based on the different parsing strategies:
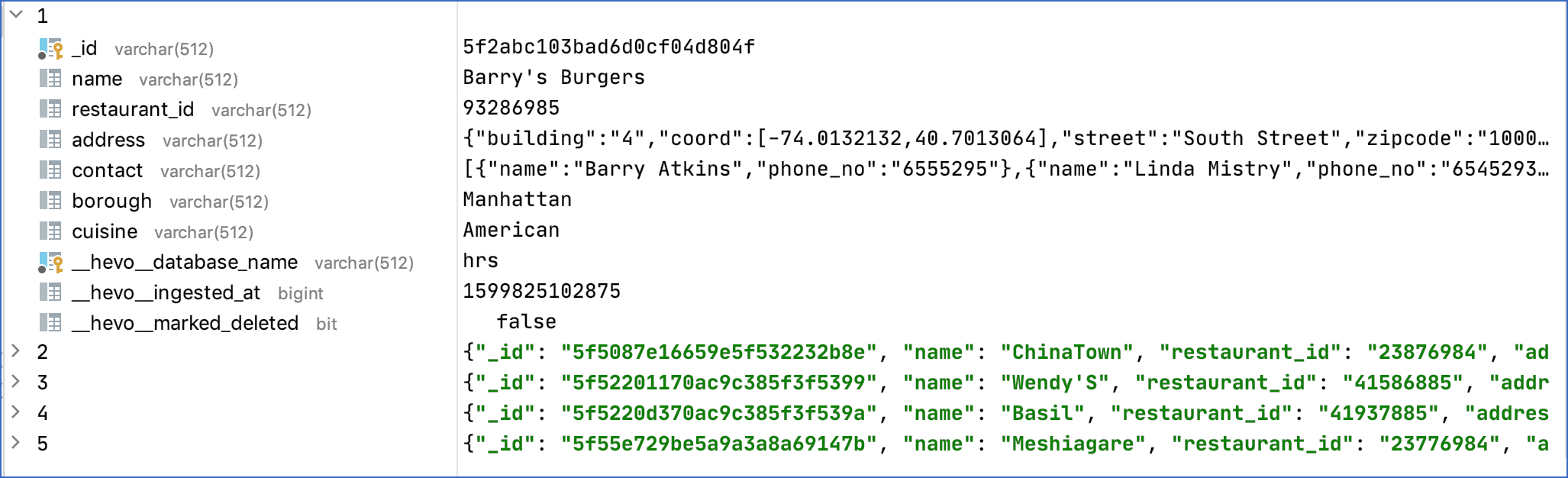
Strategy: Replicate JSON fields as JSON strings and array fields as strings
In this strategy, nested JSON fields are collapsed and serialized as a JSON string of type varchar.
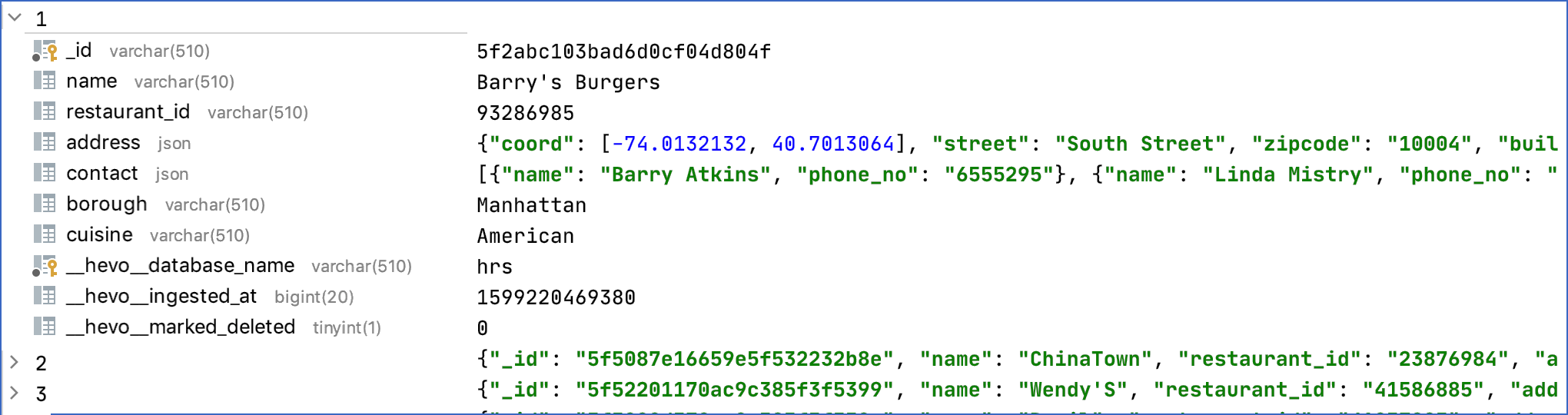
In the current example, the address object, which contains several fields and an array, is collapsed into a single JSON string in the Destination table. Same behaviour can be observed for the contact array, where the name and phone_no fields are collapsed into a single JSON string.
Sample Destination Record
Strategy: Replicate JSON structure as is while collapsing nested arrays into strings
In this parsing strategy, the JSON structure of the Source data is maintained except for nested arrays, which are collapsed into JSON strings. Any nested arrays of arrays or a mix of data types in the array items are collapsed into a JSON string. Read Working with Arrays.
This strategy is used only in case of Google BigQuery Destinations, as it offers specialized support for JSON and also enforces the need for a well-defined schema for the fields within a record.
Sample Destination Record
As seen in the image below, the Source JSON format is retained for all the fields and well-defined arrays.

Now, suppose the following record is added to the Source data:

Here, the contact array within the address object has differing counts of phone numbers. Such non-uniform arrays are collapsed into a JSON string, as shown below.

Strategy: Replicate JSON structure as is while collapsing arrays into strings
In this parsing strategy, the JSON structure of the Source data is maintained except for arrays, which are collapsed into JSON strings.
This strategy is used only in the case of Google BigQuery Destination with the following specific Sources:
-
MySQL: Generic MySQL, Amazon RDS MySQL, Amazon Aurora MySQL, Azure MySQL, Google Cloud MySQL, Oracle MySQL, TokuDb MySQL
-
MariaDB: Generic MariaDB, Amazon RDS MariaDB, Azure MariaDB
-
Oracle: Generic Oracle, Amazon RDS Oracle
-
PostgreSQL: Generic PostgreSQL, Aws Aurora PostgreSQL, Amazon RDS PostgreSQL, Google Cloud PostgreSQL, Azure PostgreSQL, Heroku PostgreSQL
-
MS SQL: Generic MS SQL, Amazon RDS MS SQL, Azure MS SQL, Google Cloud SQL Server
-
MongoDB: Generic MongoDB, MongoDB Atlas
-
Amazon DynamoDB
Sample Destination Record
For the Sample Data Structure 1 above, the Source JSON format is retained at the Destination for all the fields and well-defined arrays.

Strategy: Flatten structs and split arrays to new Events
Each JSON object or array is ingested as a separate Event Type, and a new table is created for it in the Destination. The child Event carries the property __hevo_ref_id, representing the identifier of the parent object. In addition, the parent object name is prefixed to the Event name. In this structure, each key:value pair holds only one value.
Note: In case the Source table does not have a primary key, then this strategy is not used but the parsing defaults to the Collapse strategy. This is done because there is no primary key to reference in the new Event Types.
The following image illustrates the tables that are created in the Destination for the orgs Event Type and its child arrays:

-
In the
flat_orgstable:-
Each field of the
orgsobject is parsed as a separate Event in a flat JSON format. -
The fields within the
addressobject are converted to separate Events, and the parent field name is prefixed to each Event’s name, for example,address.street. Here, the_idfield, which is the same as the primary key of the parent field, maps the child to the parent. -
The
coordarray within theaddressobject, and thecontactarray are not seen here, as these are converted into new Event Types.
-
-
In the
flat_orgs_address_coordtable created for thecoordarray:-
The
__hevo_ref_idis mapped to the primary key (__hevo_ref_idfield) of thecontactobject in the Source. -
The sequence of the array items is maintained using the
__hevo_array_index. -
The combination of
__hevo_array_indexand_idbecomes the primary key of the Event.
-
-
Similarly, a separate table
flat_orgs_contactis created for thecontactarray within theaddressobject.
Sample Destination Record
The following image displays a sample of the replicated data for the flat_orgs object:
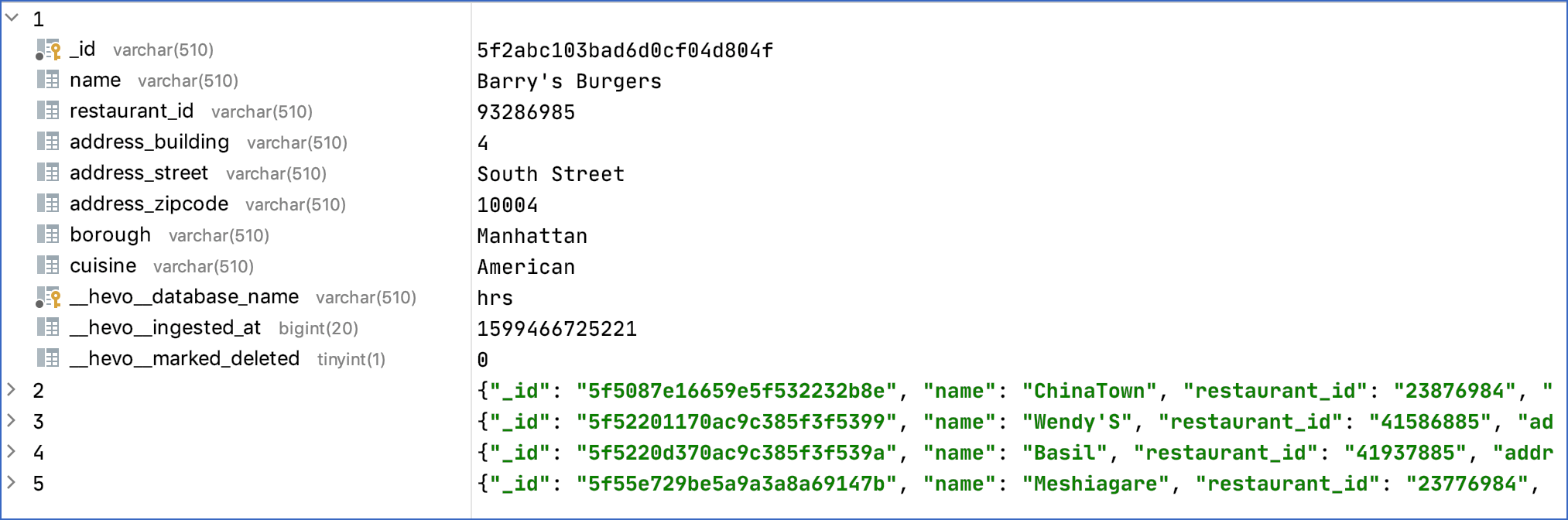
The following image displays a sample of the replicated data for the flat_orgs_contact object:

Strategy: Replicate JSON fields to JSON columns
While this format appears similar to the Replicate JSON Fields as JSON Strings parsing strategy, additional metadata is maintained by the system to differentiate the JSON and String data. This metadata is useful while writing the data to appropriate columns (optimized) in the tables of the Destination warehouse where both JSON and String data types are supported.
Sample Destination Record
As seen in the image below, the address and contact objects are replicated as separate JSONs.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Mar-10-2023 | NA | Updated the parsing strategies table in the page overview to add Azure Synapse Analytics. |
| Jun-27-2022 | NA | - Updated the parsing strategies table in the page overview to add the parsing strategies available for Amazon Redshift. |
| Apr-25-2022 | NA | - Renamed replication strategy, Replicate JSON fields as JSON strings to Replicate JSON fields as JSON strings and array fields as strings - Updated the parsing strategies table in the page overview to modify the parsing strategy for Aurora MySQL, MySQL, and Google BigQuery. |
| Oct-25-2021 | 1.74 | Updated the parsing strategies table in the page overview to modify the parsing strategy for Amazon Redshift. |
| Sep-20-2021 | NA | Removed S3 from parsing strategies table as Hevo does not support S3 as a Destination. |
| Aug-09-2021 | 1.69 | - Added section Strategy: Replicate JSON structure as is while collapsing arrays into strings. - Updated the parsing strategy table in the overview section. |
| Mar-09-2021 | 1.58 | - Updated the page overview and the parsing strategies table to indicate that only native parsing strategy is supported for the Aurora MySQL, MySQL, Postgres, and Snowflake Destinations. - Included the screenshot where you can specify the parsing strategy. |