Azure Blob Storage
On This Page
Azure Blob Storage is a Platform-as-a-Service (PaaS) storage platform that is scalable, secure, cost-effective, and allows you to build apps, create data lakes, and analyze the data in them. It provides a tiered storage to optimally store large amounts of data. Hevo supports data replication of structured and semi-structured data for the following file formats: AVRO, CSV, JSON, TSV, and XML.
Hevo uses the Microsoft Azure Client Library For Blob Storage version 12.17.0 for connecting to the Source and ingesting the Binary Large Objects (BLOBs or blobs) from it.
Prerequisites
-
An active Azure Blob Storage account.
-
A storage account is created under your Azure Blob Storage account.
Note: An Azure Blob Storage account can contain multiple storage accounts in it.
-
A container is created under your storage account, with the folders and files that you want to ingest.
Note: A storage account can contain multiple containers in it.
-
A connection string is created with the required permissions.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Creating a Connection String
Hevo uses a connection string for authentication on your Azure Blob Storage account. You must create this string to ingest data from your Azure Blob Storage container and load it into your desired Destination. To do so:
-
Log in to your Azure Blob Storage account.
-
Under the Azure services section, click All resources.
-
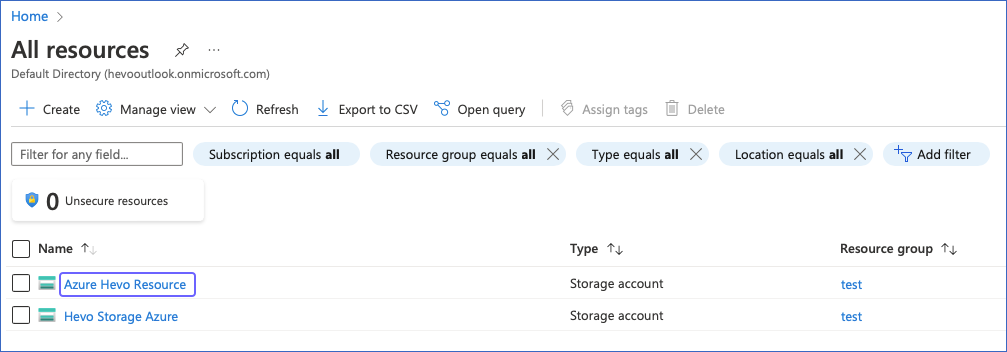
Click the storage account that contains the container that you want to use. For example, Azure Hevo Resource in the image below.
-
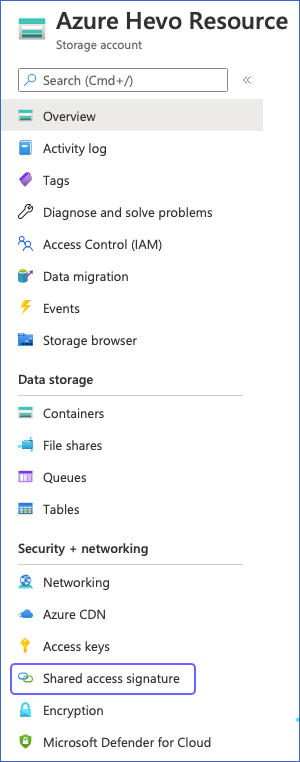
On your respective Storage account page, left navigation bar, under Security + Networking, click Shared access signature.
-
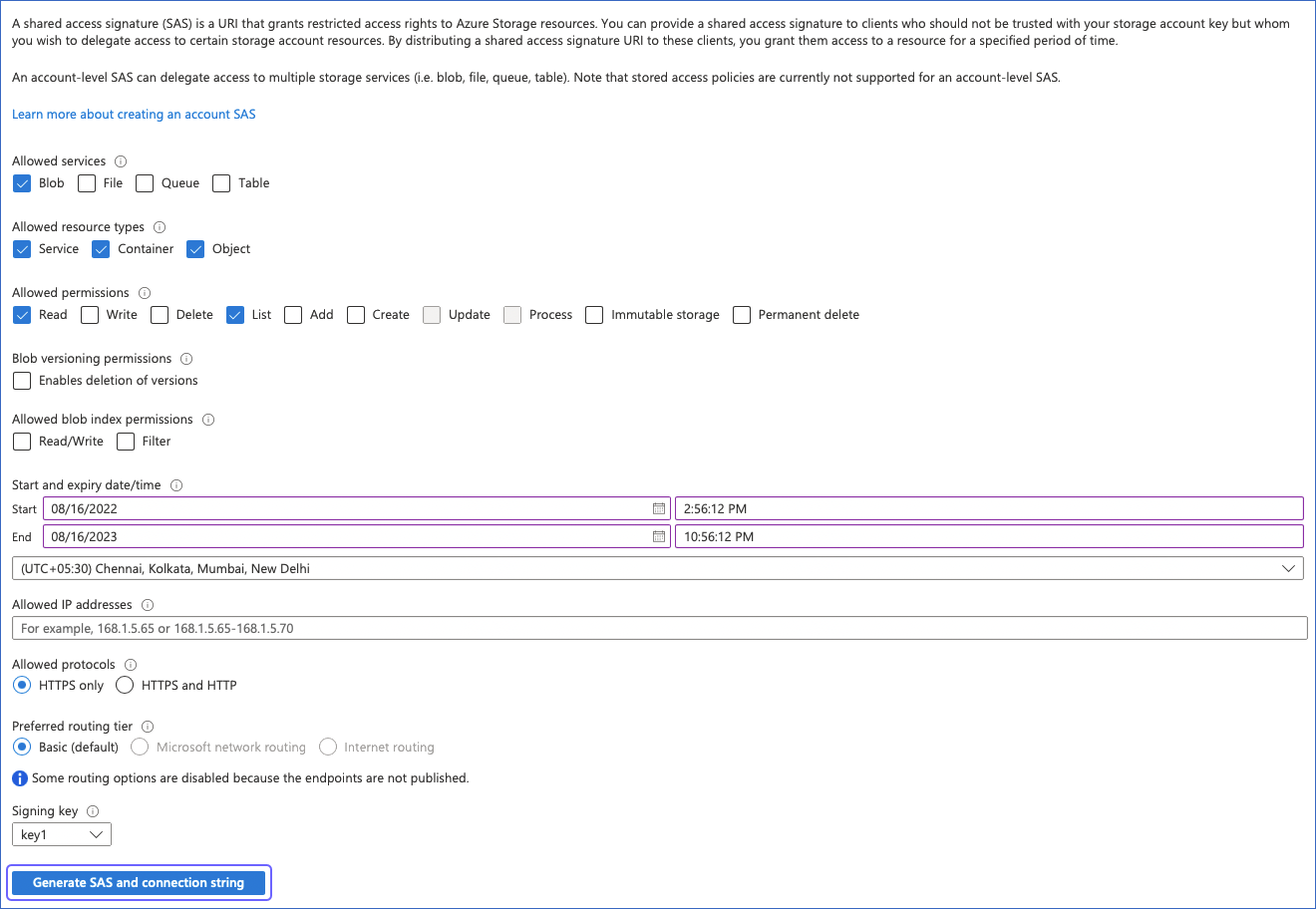
On the Shared access signature page, Hevo recommends that you do the following:
-
Under the Allowed services section, ensure that at least the Blob check box is selected.
-
Under the Allowed resource types section, select the Service, Container, and Object check boxes.
-
Under the Allowed permissions section, ensure that at least the Read and List check boxes are selected.
-
Under the Blob versioning permissions section, ensure that the Enables deletion of versions check box is deselected.
-
Under the Allowed blob index permissions section, ensure that the Read/Write and Filter check boxes are deselected.
-
Specify the Start and expiry date/time.
Note: You must specify the expiry date/time to a later date to prevent reauthorization of your Hevo Pipeline with Azure Blob Storage as the Source.
-
Click Generate SAS and connection string.
-
-
Copy the connection string. This string is visible only once, so you must copy and store it in a secure location like any other password.

You have successfully created your connection string. Use this string for creating Hevo Pipelines.
Obtain the Container Name
Perform the following steps to retrieve the container name:
-
Log in to your Azure Blob Storage account, and in the Search bar, type storage account.
-
From the search results, under Services, click Storage accounts.
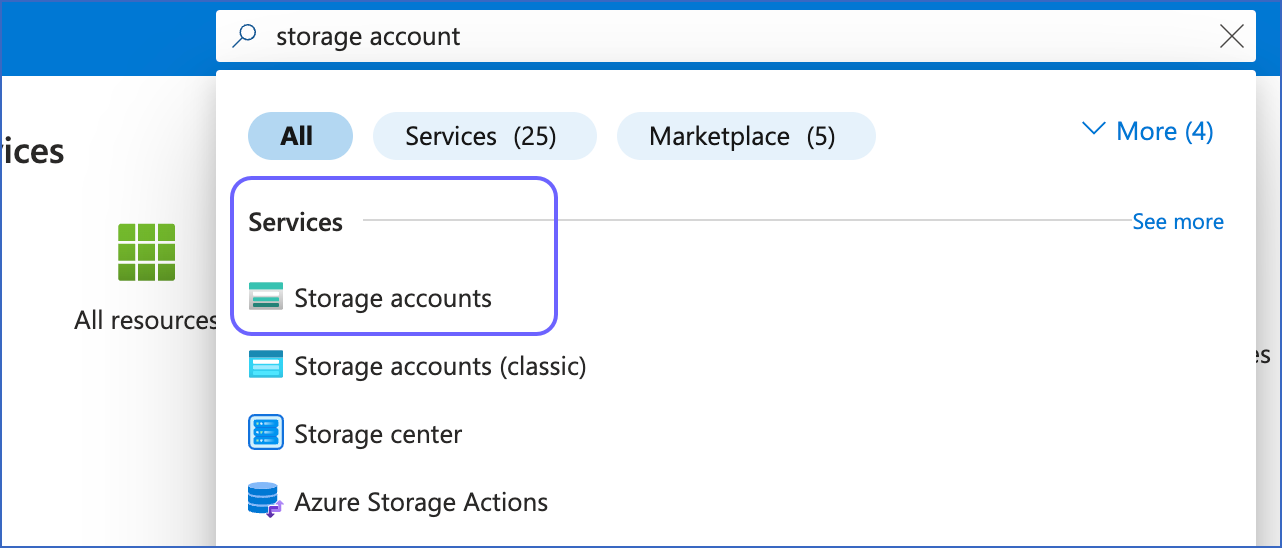
-
On the Storage accounts page, click on your storage account name. For example, hevodocstorage1.
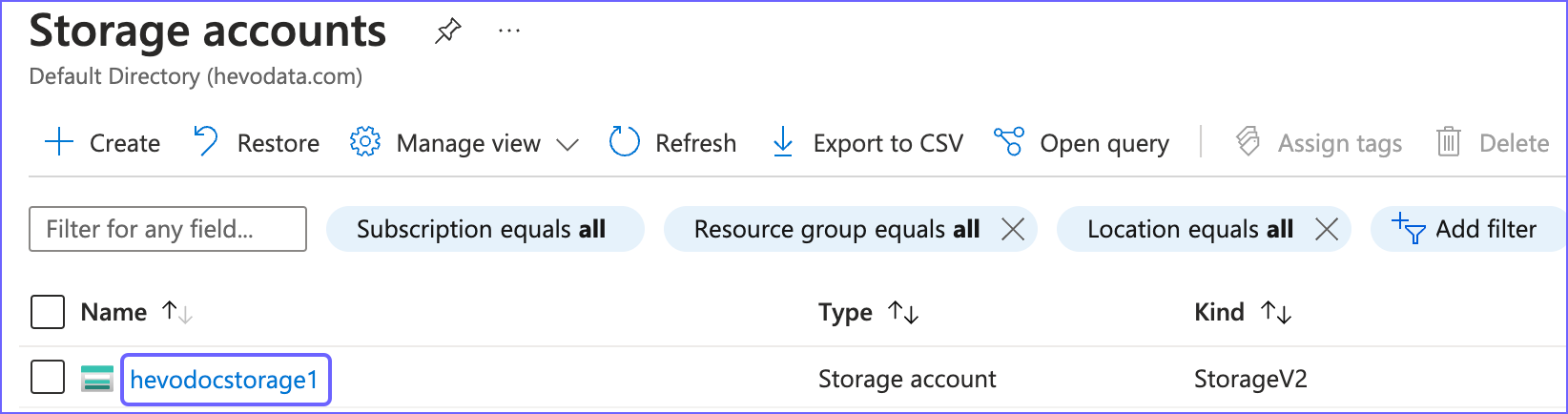
-
In the left navigation pane, under Data Storage, click Containers.
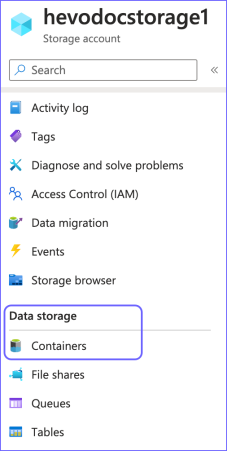
-
On the Containers page, from the Name column, copy the required value. For example, hevodemocontainer. Use this value while configuring your Hevo Pipeline.
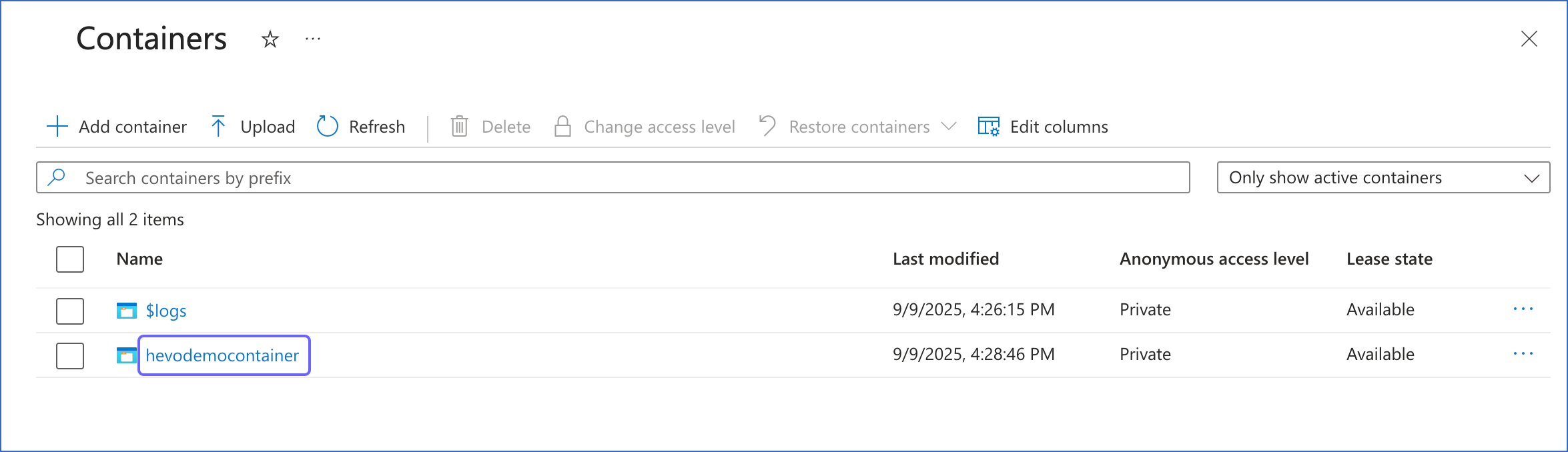
Configuring Azure Blob Storage as a Source
Perform the following steps to configure Azure Blob Storage as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Azure Blob Storage.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
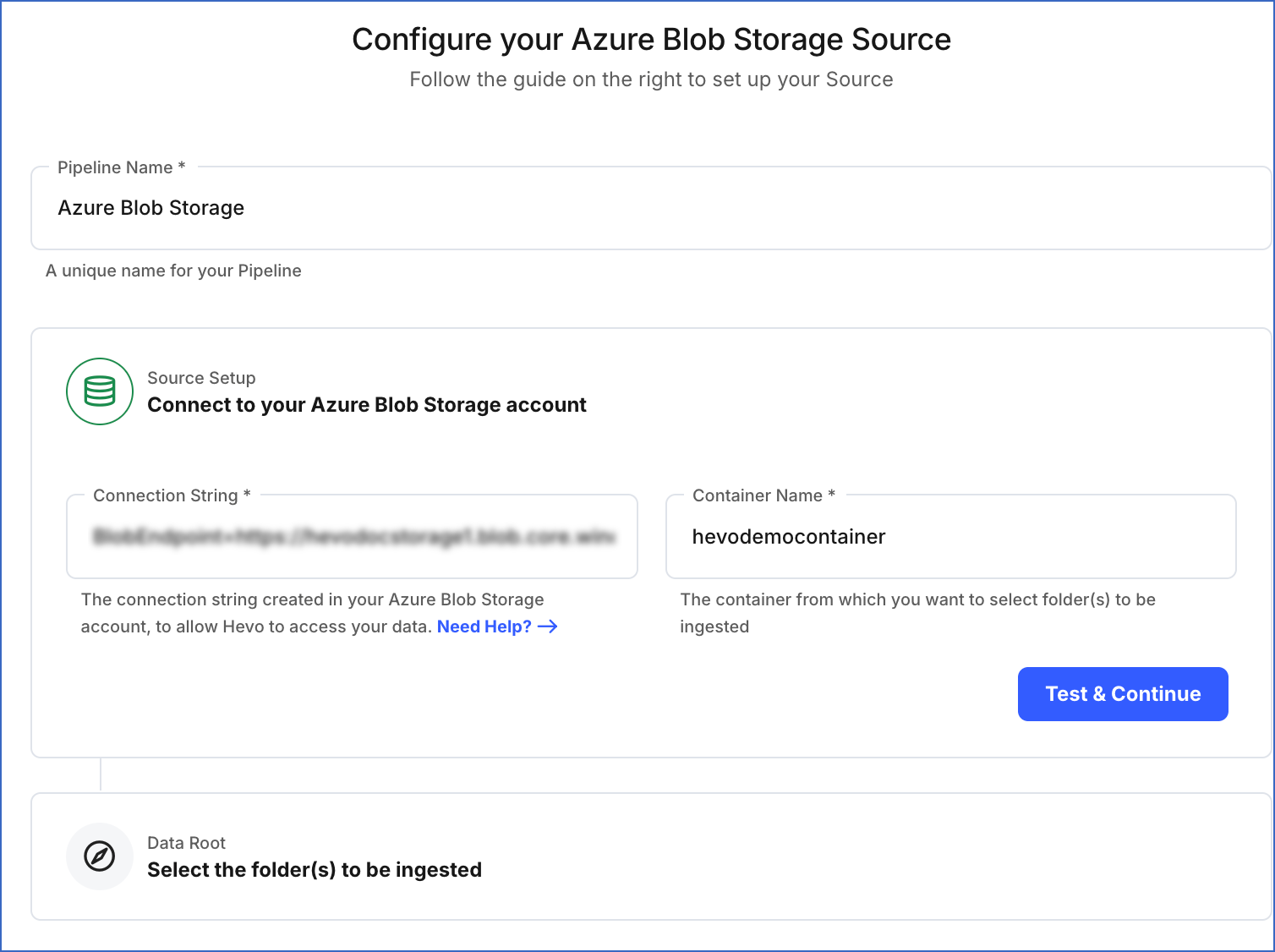
On the Configure your Azure Blob Storage Source page, specify the following:
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Source Setup: The credentials needed to allow Hevo to access your data.
Perform the following steps to connect to your Azure Blob Storage account:
-
Specify the following:
-
Connection String: The connection string that you created in your Azure Blob Storage account.
-
Container Name: The container from which you want to ingest files and folders.
-
-
Click Test & Continue.
-
-
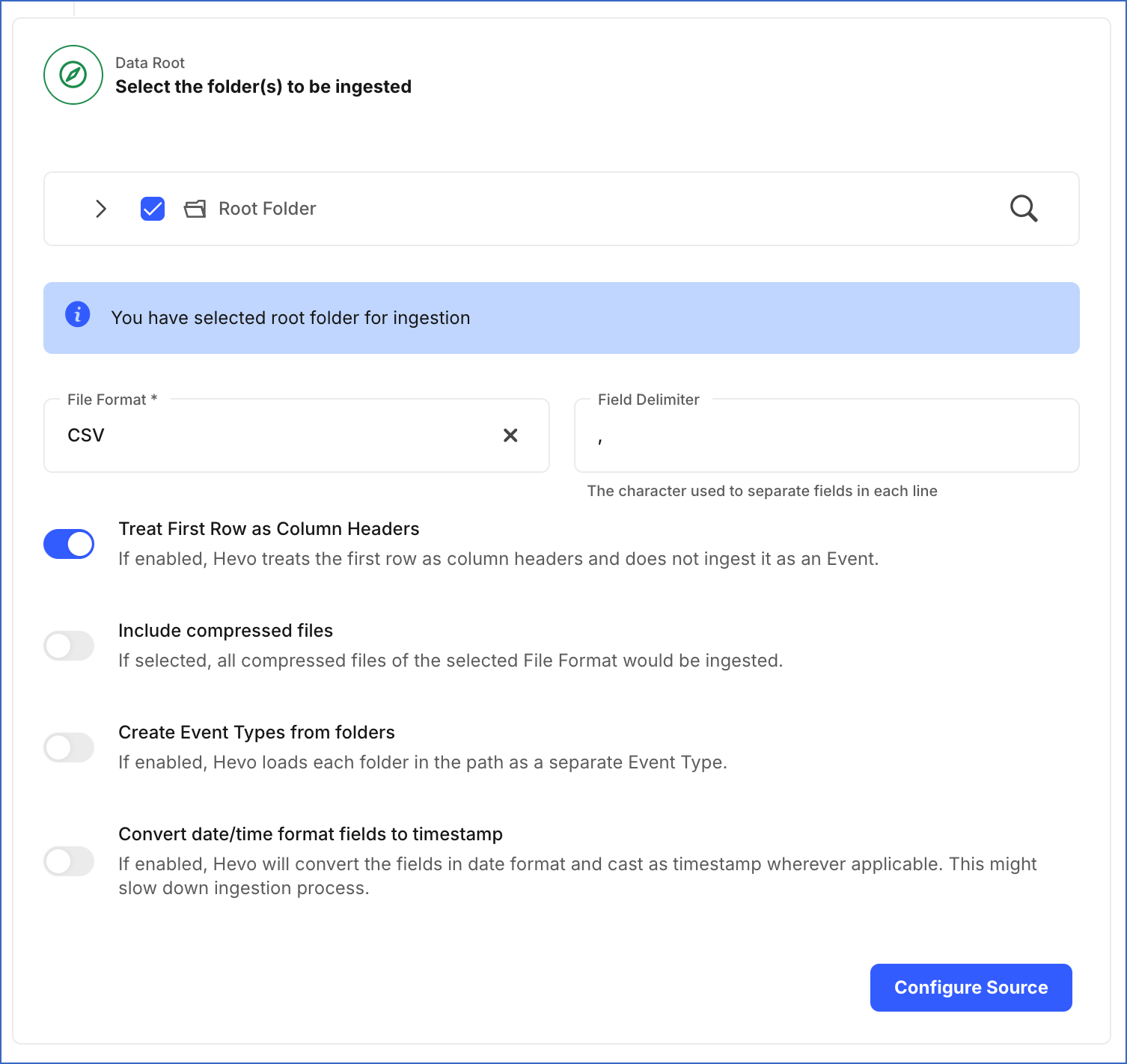
Data Root: The directory path of your Azure Blob Storage container that you specified above.
Perform the following steps to select the folder(s) and the data format which you want to ingest using Hevo:
-
Select the folders to be ingested: The folder(s) from which you want to ingest data. By default, the folder(s) are listed from the root of the container. You can either select the Root Folder to ingest data for all folder(s) and files in your specified container, or the specific folder(s) to ingest data from those folder(s). On selecting a folder, Hevo automatically selects and ingests data for all its subfolder(s) and files.
-
File Format: The format of the data file in the Source. Hevo supports the AVRO, CSV, JSON, TSV, and XML file formats to ingest data.
Note: You can select only one file format at a time. If your Source data is in a different format, you can export the data to either of the supported formats, and then ingest the files.
Based on the format you select, you must specify some additional settings:
-
CSV:
-
Field Delimiter: The character on which fields in each line are separated. For example,
\t, or,. -
Treat First Row As Column Headers: If enabled, Hevo identifies the first row in your CSV file and uses it as a column header rather than an Event. If disabled, Hevo automatically creates the column headers during ingestion. Default setting: Enabled. Refer to section, Example.
-
Create Event Types from folders: If enabled, Hevo ingests each subfolder as a separate Event Type. By default, data from all selected folders is ingested. However, if you do not want Hevo to ingest data from certain folders, you can skip them from the Pipeline Overview page.
If disabled, Hevo merges the subfolders into their parent folders, and ingests them as one Event Type. Default setting: Disabled.
-
Convert date/time format fields to timestamp: Enable this option if you want to convert the date/time format within the files of selected folders to timestamp. For example, the date/time format 07/11/2022, 12:39:23 converts to timestamp 1667804963.
-
-
JSON, TSV, XML:
-
Create Event Types from folders: If enabled, Hevo ingests each subfolder as a separate Event Type. By default, data from all selected folders is ingested. However, if you do not want Hevo to ingest data from certain folders, you can skip them from the Pipeline Overview page.
If disabled, Hevo merges the subfolders into their parent folders, and ingests them as one Event Type. Default setting: Disabled.
-
Convert date/time format fields to timestamp: Enable this option if you want to convert the date/time format within the files of selected folders to timestamp. For example, the date/time format 07/11/2022, 12:39:23 converts to timestamp 1667804963.
-
-
-
Click Configure Source.
-
-
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 1 Hr | 5 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Example: Automatic Column Header Creation for CSV Tables
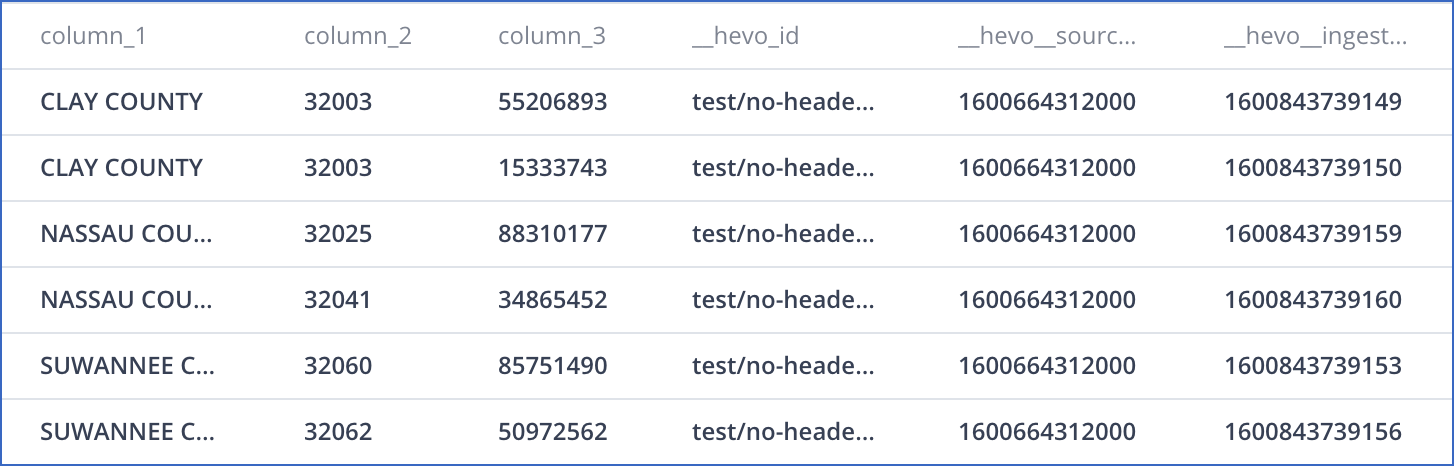
Consider the following data in CSV format, which has no column headers.
CLAY COUNTY,32003,11973623
CLAY COUNTY,32003,46448094
CLAY COUNTY,32003,55206893
CLAY COUNTY,32003,15333743
SUWANNEE COUNTY,32060,85751490
SUWANNEE COUNTY,32062,50972562
ST JOHNS COUNTY,846636,32033
NASSAU COUNTY,32025,88310177
NASSAU COUNTY,32041,34865452
If you disable the Treat First Row As Column Headers option, Hevo auto-generates the column headers, as shown in the schema mapper below:

The record in the Destination appears as follows:
Limitations
-
Hevo currently does not support deletes. Therefore, any data deleted in the Source may continue to exist in the Destination.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
-
Hevo currently supports only the ISO 8859-1 character set. If the file name or content includes unsupported characters, such as emojis or special symbols, the Pipeline may fail. If your file uses a different character set, contact Hevo Support.
-
If you initially select a parent folder for ingestion and later reconfigure the Source to select specific child folders within it, Hevo treats each newly selected child folder as a separate ingestion path. This triggers a new historical load for those folders, even if their data was previously ingested through the parent folder.
To avoid duplicate ingestion, you can skip the historical load and configure the child folders to resume from a specific point using the Change Position option. Any data ingested using the Change Position action is billable.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-12-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring Azure Blob Storage as a Source as per the latest UI. |
| Sep-12-2025 | NA | Updated section, Obtain the Container Name to update screenshots as per latest Azure UI. |
| Jul-30-2025 | NA | Added information about skipping Event Types to the Create Event Types from folders option in the Configuring Azure Blob Storage as a Source section. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jun-02-2025 | NA | Updated section, Limitations to add a point about new historical loads when selecting child folders for ingestion. |
| May-08-2025 | NA | Updated section, Limitations to add a point about Hevo supporting only ISO-8859-1 encoding format. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Oct-03-2023 | NA | Added section, Obtain the Container Name. |
| Nov-08-2022 | NA | Updated section, Configuring Azure Blob Storage as a Source to add information about the Convert date/time format fields to timestamp option. |
| Sep-21-2022 | NA | Updated a note in section, Configuring Azure Blob Storage as a Source. |
| Aug-24-2022 | 1.96 | New document. |