AppsFlyer
On This Page
AppsFlyer is a mobile-app tracking and attribution analytics platform that helps app developers and marketers to manage, measure, and optimize their mobile user acquisition process.
Hevo uses AppsFlyer’s PULL API to replicate the raw and aggregated app performance reports from your AppsFlyer account to the Destination system. The user needs to provide the AppsFlyer API Token to connect Hevo to the AppsFlyer account.
Note: For Pipelines created from Release 2.13 onwards, Hevo supports version 2 of AppsFlyer’s API token to replicate your data.
Prerequisites
-
An active AppsFlyer account with access to at least one app exists.
-
The App ID and API token are available to authenticate Hevo on your AppsFlyer account. You must be logged in as an Admin user in AppsFlyer to obtain these credentials. Else, you can obtain them from your account administrator.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Obtaining the App ID and API Token
You require an app ID and an API token to authenticate Hevo on your AppsFlyer account. The app ID is the unique ID of the app listed in the AppsFlyer dashboard whose data you want to replicate to the Destination. You need to create an API token for the listed app.
Note: You must log in as an Admin user to perform these steps.
Step 1. Obtain the App ID
-
Log in to your AppsFlyer account. On the homepage, you can find the apps added to your account.
-
Copy the app ID of the app from which you want to fetch data. Use this ID while configuring your Hevo Pipeline.
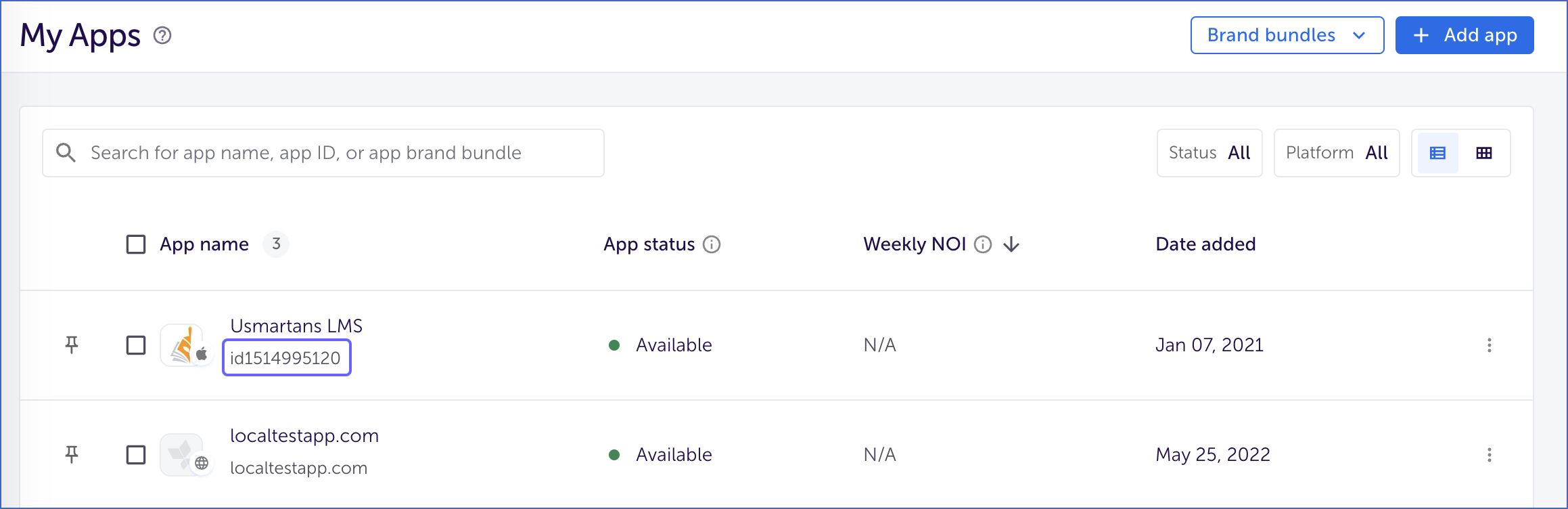
Note: The app ID for iOS apps starts with
id.
Step 2. Obtain the API Token
-
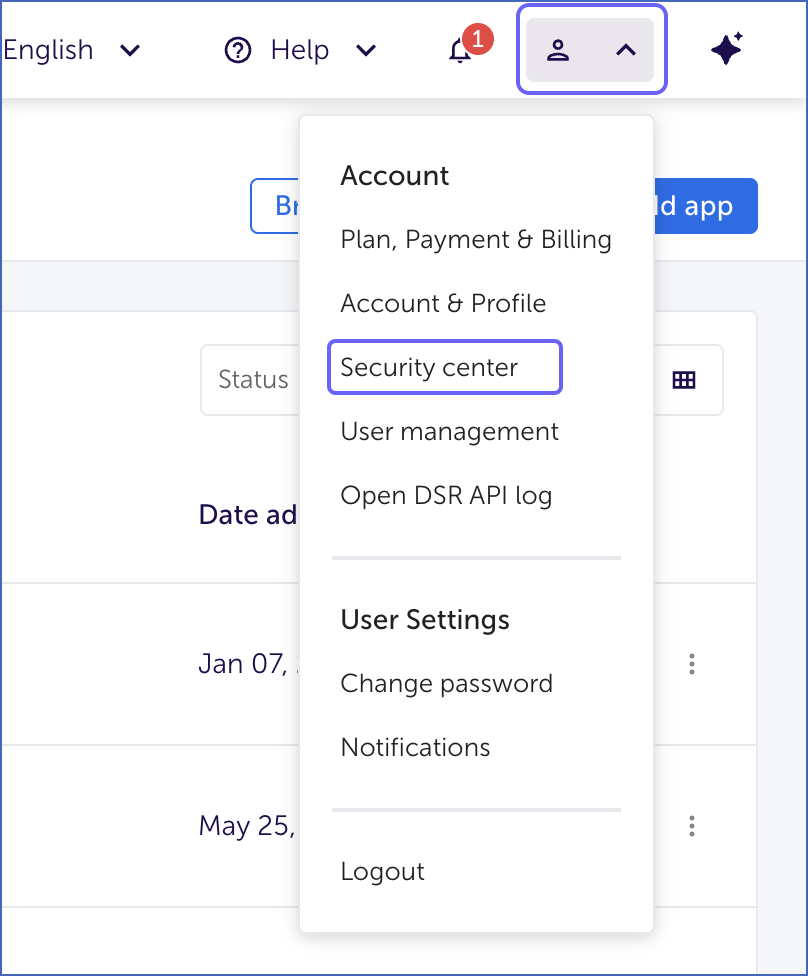
In the top right corner of the AppsFlyer homepage, click the drop-down next to your username, and click Security center.
-
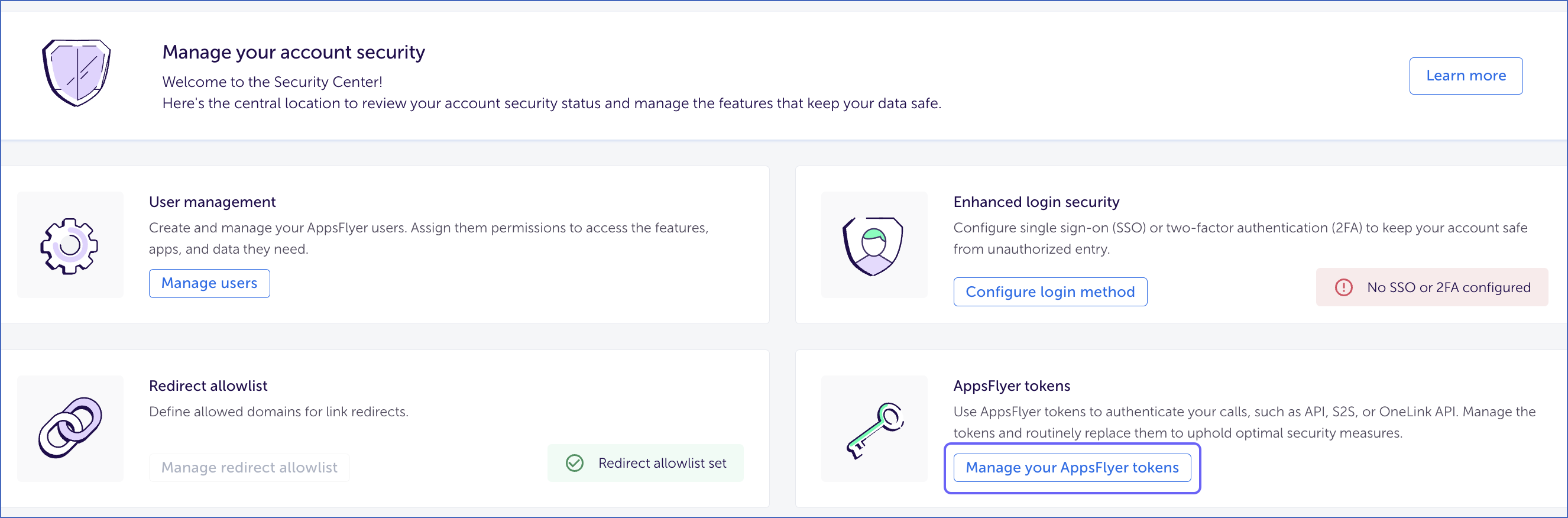
On the Manage your account security page, scroll down and click Manage your AppsFlyer tokens.
-
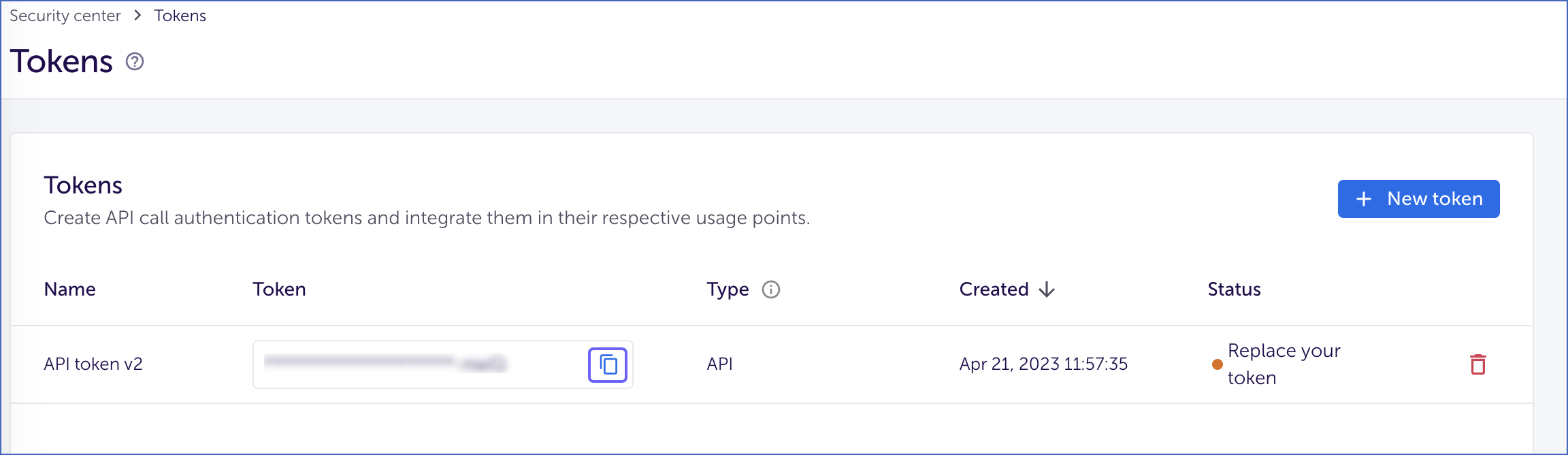
On the Tokens page, copy the API token v2 and save it securely like any other password. The API token allows Hevo to pull raw and aggregated data reports from AppsFlyer. Use this token while configuring your Hevo Pipeline.
Configuring AppsFlyer as a Source
Perform the following steps to configure AppsFlyer as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select AppsFlyer.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Configure your AppsFlyer Source page, specify the following:
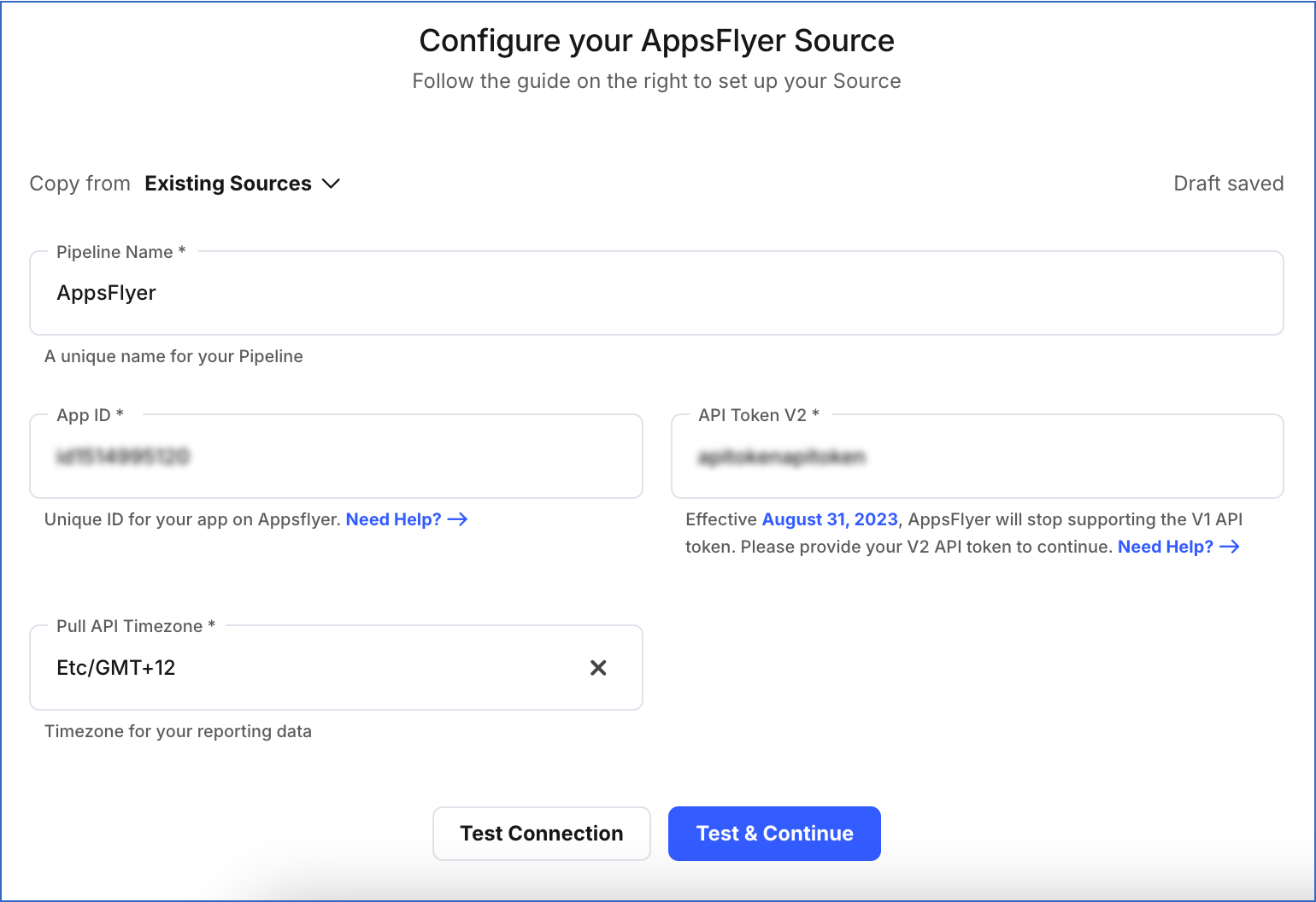
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
App ID: The unique ID of your AppsFlyer app that you obtained from your AppsFlyer account.
-
API Token: The API token that you obtained from your AppsFlyer account.
-
Pull API Timezone: The timezone in which you want to receive the data.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 30 Mins | 5 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests the data of the past 90 days for the selected objects in your AppsFlyer account. You can use the Change Position option for an object to load data older or recent than 90 days.
Refer to the following table to know about the maximum number of days for which AppsFlyer provides historical data for each object:
Object API Limit for Historical Data (Days) daily_report 60 geo_by_date_acquisition_report 60 geo_by_date_retargeting_report 60 in-app_events_report 31 in-app_events_retargeting_report 31 installs_report 60 organic_installations_report 60 organic_in_app_events_report 31 partners_by_date_report 60 partners_report 100 uninstalls_report 60 Note: You are not charged for the Events that are loaded or reloaded after the change of position.
-
Incremental Data: Once the historical data ingestion is complete, every subsequent run of the Pipeline fetches new and updated data for the reports.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination. For a detailed view of the objects, fields, and relationships, click the ERD.
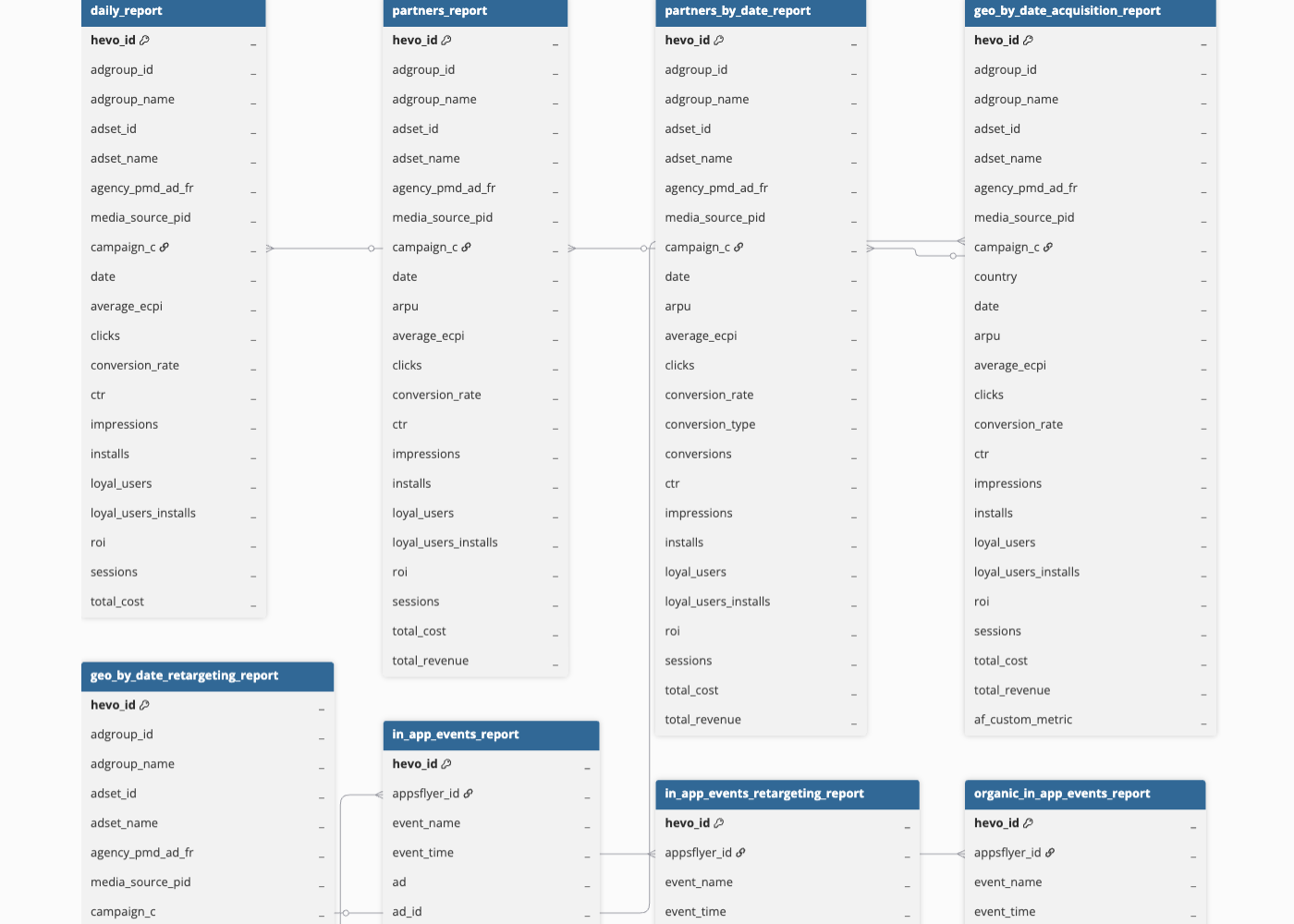
Data Model
Hevo uses the following data model to ingest data from your AppsFlyer account:
| Object | Report Type | Description |
|---|---|---|
| daily_report | Aggregated | Contains details of clicks and impressions grouped by Date. |
| geo_by_date_acquisition_report | Aggregated | Contains an acquisition report grouped by date, country, agency, media source, and campaign. To view examples, see this. |
| geo_by_date_retargeting_report. | Aggregated | Contains retargeting report grouped by date, country, agency, media source, and campaign. To view examples, see this. |
| in-app_events_report | Raw | Contains report of in-app events as per the user’s action. |
| in-app_events_retargeting_report | Raw | Contains the data of the media sources attributed to the conversion. |
| installs_report | Raw | Contains report of the event generated when the app is opened for the first time. |
| organic_installations_report | Raw | Contains installation reports of the app, such as, the time of installation, type of device, operating system, region, city, and country. |
| organic_in_app_events_report | Raw | Contains details of actions performed by users. |
| partners_by_date_report | Aggregated | Contains partner data grouped by date, agency, media source, and campaign. View examples here. |
| partners_report | Aggregated | Contains partner data grouped by date, agency, media source, and campaign. View examples here. |
| uninstalls_report | Raw | Contains uninstallation reports of the app, such as, time of uninstallation, type of device, operating system, region, city, and country. |
Note: __hevo_id, which represents a unique ID for the Source data, is derived by hashing the Source data’s primary key columns.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Limitations
-
Hevo does not support raw reports of
Ad revenueandRetargetingfetched from AppsFlyer. -
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-07-2025 | NA | - Updated the document as per the latest Hevo UI. - Removed section, Migrating from AppsFlyer API V1 Token to V2. |
| Sep-18-2025 | NA | Updated section, Configuring AppsFlyer as a Source as per the latest UI. |
| Sep-16-2025 | NA | Updated section, Obtaining the App ID and API Token as per the latest AppsFlyer UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Jun-05-2023 | 2.13 | Updated the content to add information about API V2 token. |
| Jan-10-2023 | 2.05 | Updated section, Data Replication to mention about custom ingestion frequency. |
| Dec-07-2022 | NA | Updated section, Data Replication to reorganize the content for better understanding and coherence. |
| Mar-17-2022 | NA | Removed the Pipeline frequency table from the Data Replication section as you cannot configure the Pipeline frequency from the UI. |
| Mar-07-2022 | NA | - Updated the steps under the Obtaining the App ID and the API Token section, to reflect the latest AppsFlyer UI. - Updated the Pipeline Frequency table and added information about historical data in the Data Replication section. |
| Oct-25-2021 | NA | Added the Pipeline frequency information in the Data Replication section. |