Criteo
On This Page
Effective July 11, 2025, Hevo uses API Version 2025.04 to fetch data from Criteo. To ensure uninterrupted service, your Pipelines were automatically upgraded.
The new API version has removed the following fields:
Note: Hevo no longer supports ingesting data for these fields. As a result, corresponding columns in the Destination are no longer updated.
This change applies to all new and existing Pipelines created with this Source.
Criteo is a digital marketing technology tool that specializes in delivering personalized advertising to consumers based on their online browsing behavior. It allows advertisers to deliver relevant ads to potential customers across multiple devices and channels, including desktop, mobile, social media, and email. It uses machine learning algorithms to analyze vast amounts of data and deliver targeted ads in real-time, with the aim of increasing customer engagement and driving sales for its clients.
Hevo uses Open Authorization (OAuth) to authenticate your Criteo account.
You can replicate the data from your Criteo account to a Destination database or data warehouse using Hevo Pipelines. Refer to section, Data Model for the list of supported objects.
Prerequisites
-
An active Criteo account from which data is to be ingested exists.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Configuring Criteo as a Source
Perform the following steps to configure Criteo as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Criteo.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Configure your Criteo account page, do one of the following:
-
Select a previously configured account and click Continue.
-
Click + Add Criteo Account and perform the following steps to configure an account:
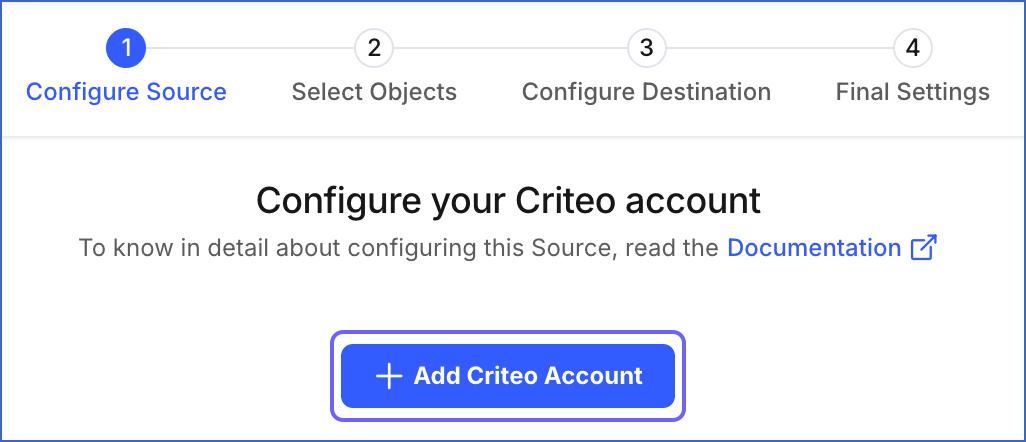
-
On the Log in to Criteo page, specify your registered Email address and click Continue.
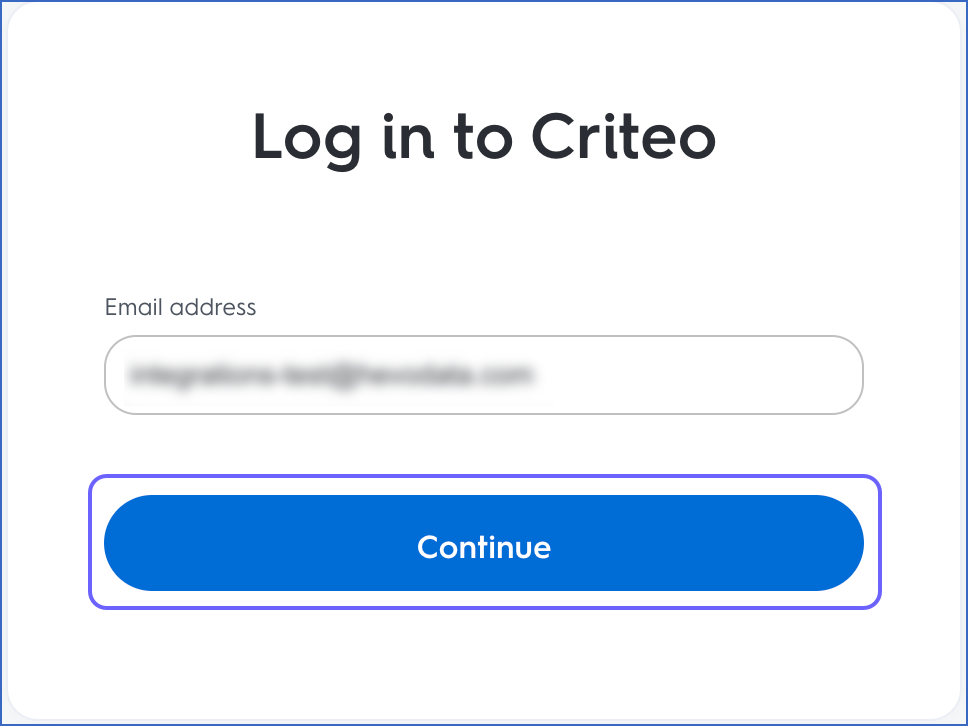
-
Specify your password and click Log in.

-
Click Approve.

-
-
-
On the Configure your Criteo Source page, specify the following:
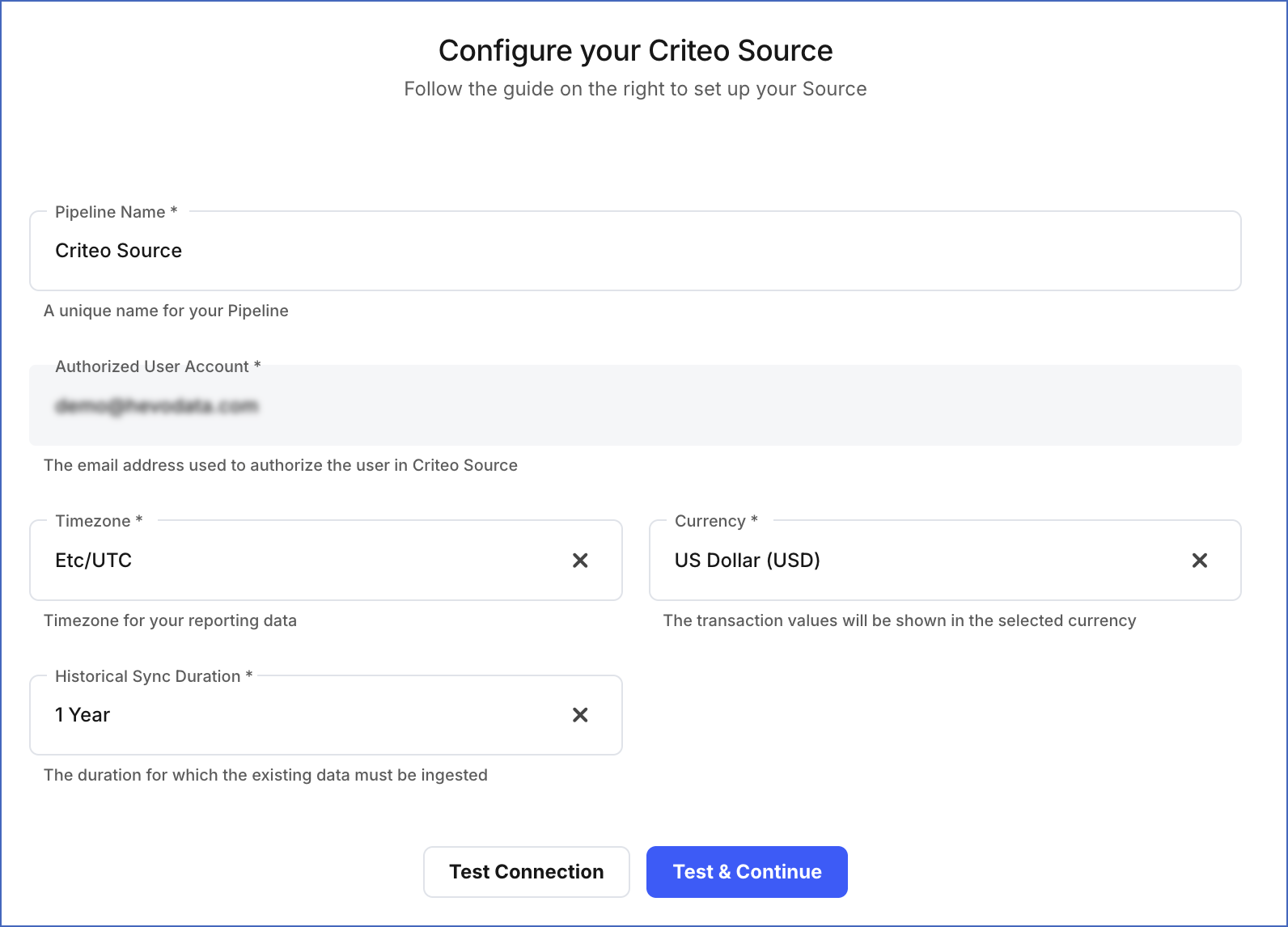
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Timezone: The timezone as per which the Ad set Transaction Report data must be replicated. Default timezone: UTC.
-
Currency: The currency in which the transaction values in the Ad set Transaction Report must be replicated. Default currency: USD.
-
Historical Sync Duration: The duration for which you want to ingest existing data from the Source. This cannot be changed after the Pipeline is created. Default duration: 1 Year.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 3 Hrs | 30 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: Hevo ingests the historical data for the
campaign_reportobject on the basis of the historical sync duration selected at the time of creating the Pipeline. -
Incremental Data: Once the historical data ingestion is complete, every subsequent run of the Pipeline fetches the entire data for the objects. In case of the
campaign_reportobject though, only the new and modified data is ingested. -
Refresher Data: All reporting data for the
campaign_reportobject is refreshed on a rolling basis to update any conversions attributed to clicks for the past 30 days.
Note: The time taken to fetch historical data depends on how many days are selected at the time of creating a Pipeline. Hence, Hevo defaults this period to one year before today, and if required you may customize it to any date, with the earliest being January 01, 2010.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination database. For a detailed view of the objects, fields, and relationships, click the ERD.
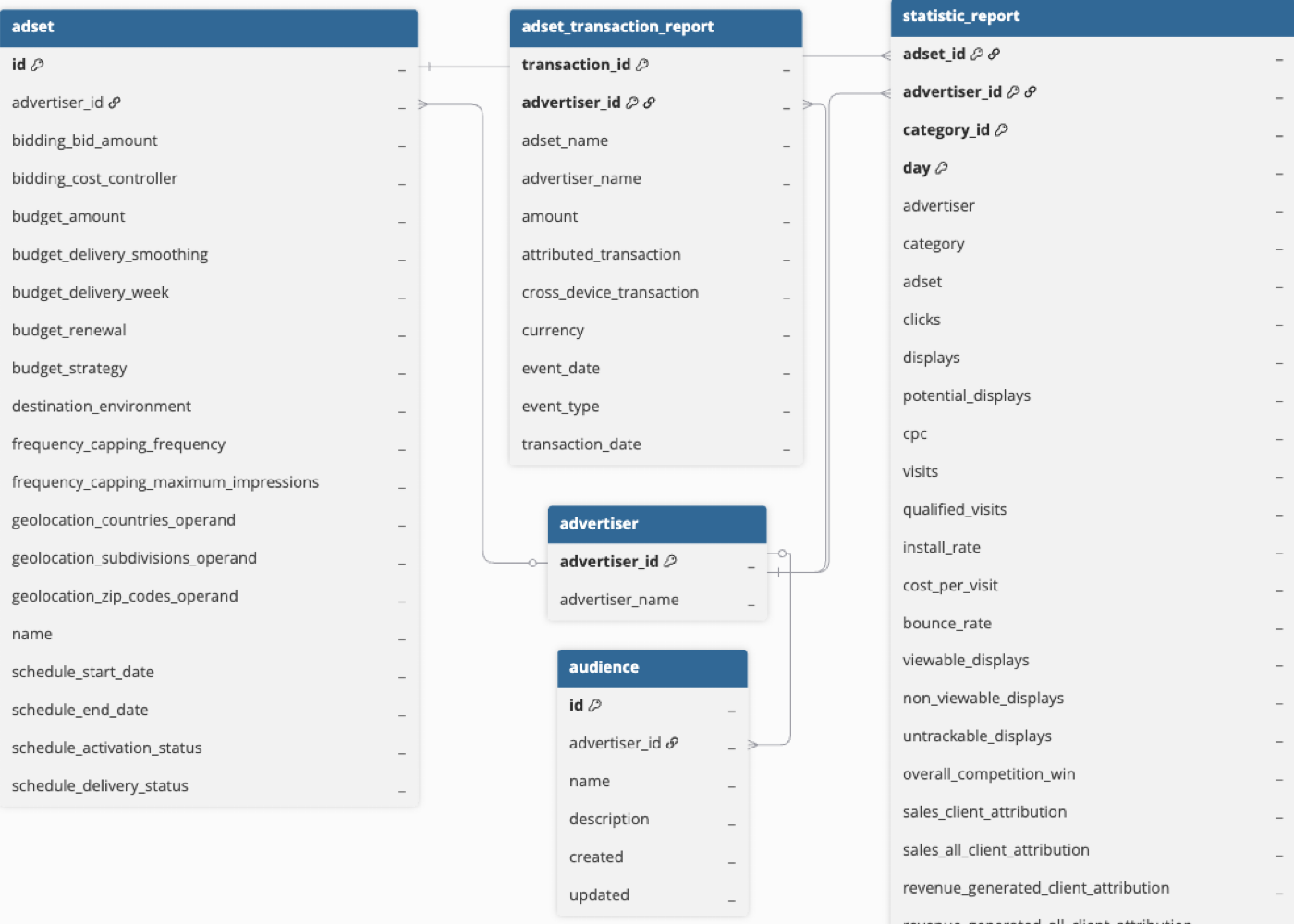
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
| Object | Description |
|---|---|
| Advertiser | Contains the list of specific advertisers for your user. (Advertiser Portfolio). |
| Ad set | Contains the complete list of ad sets (earlier called campaigns) for an advertiser, along with activity and bid statuses. |
| Ad set Transaction Report | Contains report data of transactions within a given time period, transactions associated with select or all advertisers in your portfolio, or specific transaction IDs. |
| Audience | Stores the contact lists, which are used for your advertising campaigns, including details such as name, description, and information about when the list was created or last modified. |
| Statistics Report | Contains day-level data related to your ad sets’ (campaign) performance. The report returns all possible metrics supported by Criteo across the Advertiser, Category, and Ad set dimensions for each day. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Limitations
- Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Apr-28-2026 | NA | Updated section, Configuring Criteo as a Source to mention that the historical sync duration cannot be changed after the Pipeline is created. |
| Nov-12-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring Criteo as a Source as per the latest UI. |
| Jul-14-2025 | 2.38 | - Added a warning in the Overview section to highlight the version upgrade. - Updated the Schema and Primary Keys section to remove fields deprecated in the new API version. - Revised the Data Model section to update the description of the Audience object. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Apr-10-2023 | 2.11 | - Updated sections, Prerequisites and Configure Criteo as a Source to add information regarding the latest changes in the workflow. - Removed section, Retrieving the Client ID and Client Secret. |
| Feb-20-2023 | NA | Updated section, Configuring Criteo as a Source to update the information about historical sync duration. |
| Oct-25-2021 | NA | Added the Pipeline frequency information in the Data Replication section. |
| Jul-22-2021 | NA | - Updated the content for all the sections. - Revised the data model and schema to reflect the latest objects supported and deprecated by Criteo as of June 15, 2021. - Added a note in the Overview section about Hevo providing a fully-managed Google BigQuery Destination for Pipelines created with this Source. |