LinkedIn Ads
On This Page
Effective March 9, 2026, the LinkedIn Ads integration has been upgraded to LinkedIn Marketing API version 202601. This upgrade introduces support for retrieving data from the Posts API, enabling ingestion of posts associated with LinkedIn Ads sponsored accounts.
As part of this update:
- The Posts object is now supported.
- The Video Ads object has been deprecated and replaced by the Posts object.
This upgrade was applied seamlessly and did not require downtime or configuration changes for your Pipelines. To ingest the historical data for the Posts object in an existing Pipeline, you must restart the historical load for the object.
For detailed information about the Posts object schema, refer to the Schema and Primary Keys section.
LinkedIn Ads enable you to display sponsored content in the LinkedIn feed of professionals you want to reach by way of single image ads, video ads, and carousel ads. You can target your most valuable audiences using accurate, profile-based first-party data.
You can use Hevo Pipelines to replicate data from your LinkedIn reports to the desired Destination database or data warehouses for scalable analysis.
Prerequisites
-
An active LinkedIn account with access to at least one advertiser profile exists.
-
You must be assigned one of the following user roles in your company’s LinkedIn account:
- Billing admin
- Account manager
- Campaign manager
- Creative manager
Note: You can also create a Pipeline with the Viewer user role. However, this role has limited access and cannot access data from certain objects, such as Page Stats, Follower Stats, Share Stats, and Video Ads.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Configuring LinkedIn Ads as a Source
Perform the following steps to configure LinkedIn Ads as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select LinkedIn Ads.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Configure your LinkedIn Ads Account page, do one of the following:
-
Select a previously configured account and click Continue.
-
Click + Add LinkedIn Ads Account and perform the following steps to configure an account:

-
Specify the credentials of your LinkedIn account that has access to at least one advertiser profile and click Sign In.
-
Click Allow to authorize Hevo to access your advertiser profile.
-
-
-
On the Configure your LinkedIn Ads Source page, specify the following:

-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Select Accounts: Select the advertiser profiles from which you want to replicate the reports’ data.
-
Historical Sync Duration: The duration for which you want to ingest existing data from the Source. This cannot be changed after the Pipeline is created. Default duration: 6 Months.
Note: If you select All Available Data, Hevo ingests all the data available in your LinkedIn Ads account since January 01, 1970. Refer to the section, Limitations, to know about the objects from which Hevo fetches data for a limited period.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 1 Hr | 1 Hr | 48 Hrs | 1-48 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: Hevo ingests the historical data for Ad Analytics and Stats objects on the basis of the historical sync duration selected at the time of creating the Pipeline. Refer to the section, Limitations, to know about the objects from which Hevo fetches data for a limited period.
-
Incremental Data: Once the historical load is complete, all new and updated records for the Ad Analytics and Stats object are ingested as per the ingestion frequency. The remaining objects are ingested in Full Load mode.
-
Data Refresh: Data for the last 30 days is refreshed on a rolling basis for Ad Analytics objects. Data for Stats objects is refreshed for the past two days to include attributed data for the past days.
Schema and Primary Keys
Hevo uses the following schema to upload the records to the Destination database. For a detailed view of the objects, fields, and relationships, click the ERD.
Note: Starting from Release 2.21, Hevo supports LinkedIn API version 012024, which contains new and enhanced reporting capabilities. These new capabilities include new fields such as approximate_member_reach in the Campaign and Creative tables, and conversion_method in the Conversions table.
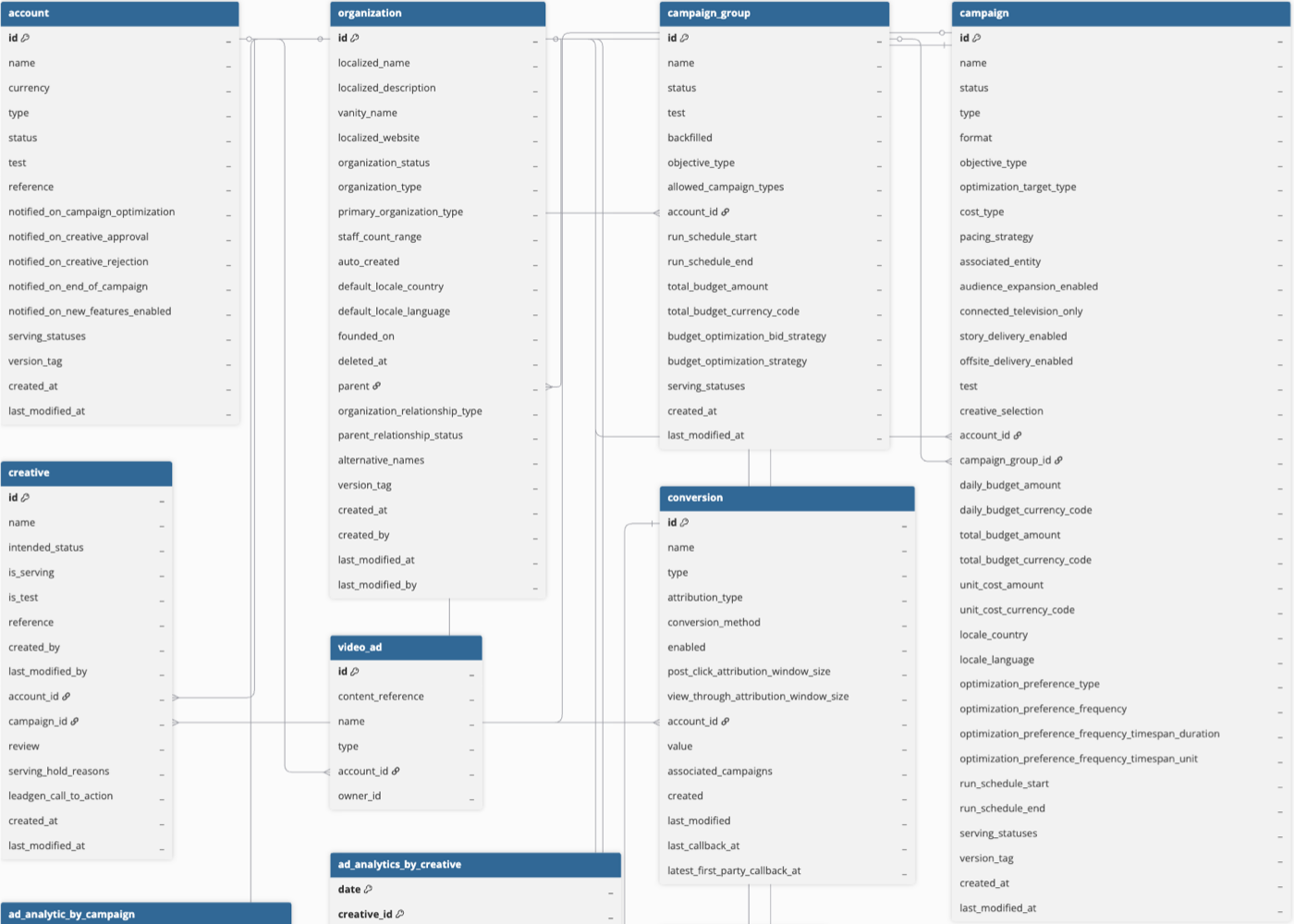
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
| Object | Description |
|---|---|
| Account | Contains details of the advertising campaigns created and managed for your company. |
| Account User | Contains details of the account members who have access to the ad account in LinkedIn Campaign Manager, along with their roles. |
| Campaigns | Contains details of the criteria used to achieve an advertising objective. |
| Campaign Group | Contains details of the campaigns associated with the LinkedIn Ads account, along with their budget, criteria, and other settings. |
| Creatives | Contains details of the content, such as images, text, and videos, required for displaying an ad on the LinkedIn platform. Note: - Hevo does not store the original content details, such as the raw text or images, associated with the ad. - For Pipelines created from June 19, 2023 onwards, Hevo uses the versioned Creatives API instead of the unversioned adCreativesV2 API to ingest data from this object. |
| Conversions | Contains details of the performance of the ongoing ad campaigns within your LinkedIn Ads account, along with their corresponding conversion metrics. |
| Ad Analytics by Campaign | Contains details of the analytics, such as views, conversions, and clicks for ad campaigns, aggregated on a daily basis. |
| Ad Analytics by Creative | Contains details of the analytics, such as views, conversions, and clicks for ad creatives, aggregated on a daily basis. |
| Page Stats | Contains details of the view and click statistics related to your company’s LinkedIn page(s). |
| Posts | Contains details of posts associated with LinkedIn Ads sponsored accounts. The data includes information such as author, post content, visibility settings, lifecycle state, publish timestamps, and associated media. |
| Follower Stats | Contains details of the statistics associated to the followers on your company’s LinkedIn page(s). |
| Share Stats | Contains details of the statistics associated to sharing on your company’s LinkedIn page(s). It might include shares made by other pages, visitors, or the company itself. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Limitations
-
LinkedIn restricts the amount of data that can be fetched from certain objects. As a result, with the All Available Data option, Hevo ingests historical data for a limited period from them. The following table lists the time and the affected objects:
Time Objects Up to six months - Ad Analytics by Campaign
- Ad Analytics by CreativeUp to one year - Page Stats
- Follower Stats
- View Stats -
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Apr-28-2026 | NA | Updated section, Configuring LinkedIn Ads as a Source to mention that the historical sync duration cannot be changed after the Pipeline is created. |
| Mar-09-2026 | 2.46 | Updated the warning container in the overview section and the Data Model to add information about the LinkedIn Ads Posts object. |
| Nov-07-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring LinkedIn Ads as a Source as per the latest UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jun-23-2025 | NA | Updated section, Prerequisites to add information about access roles. |
| Apr-11-2025 | 2.35 | - Added a warning container in page overview to mention about API upgrade. - Updated Schema and Primary Keys as per API version 202503. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Sep-22-2023 | NA | Removed the banner from the top of the page about migration to versioned APIs. |
| Jul-25-2023 | NA | Updated section, Data Model for better clarity. |
| Jun-19-2023 | 2.14 | - Added a banner at the top of the page to mention about migration to versioned APIs. - Updated section, Data Model to add information about versioned APIs. |
| Feb-20-2023 | NA | Updated section, Configuring LinkedIn Ads as a Source to update the information about historical sync duration. |
| Jul-11-2022 | NA | Updated the ERD table in the Schema and Primary Keys section. |
| Oct-25-2021 | NA | Added the Pipeline frequency information in the Data Replication section. |
| Jul-26-2021 | NA | Added a note in the Overview section about Hevo providing a fully-managed Google BigQuery Destination for Pipelines created with this Source. |