Snapchat Ads
On This Page
Snapchat Ads is Snapchat’s advertising platform that enables you to retrieve statistics about the ads, ad squads, and campaigns running on Snapchat.
Hevo uses the Snapchat Marketing APIs to replicate your Snapchat Ads data into the desired Destination database or data warehouse for scalable analysis. For this, you must authorize Hevo to access data from your Snapchat Ads account.
Prerequisites
-
An active Snapchat Ads account from which the data is to be ingested.
-
A Snapchat user with Admin privileges, to access the data from the Snapchat Ads account.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Configuring Snapchat Ads as a Source
Perform the following steps to configure Snapchat Ads as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Snapchat Ads.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Configure your Snapchat Ads account page, do one of the following:
-
Select a previously configured account and click Continue.
-
Click + Add Snapchat Ads Account and perform the following steps to configure an account:

-
Sign in using your Snapchat Ads account.

-
Click Continue to authorize Hevo to access your Snapchat Ads data.

-
-
-
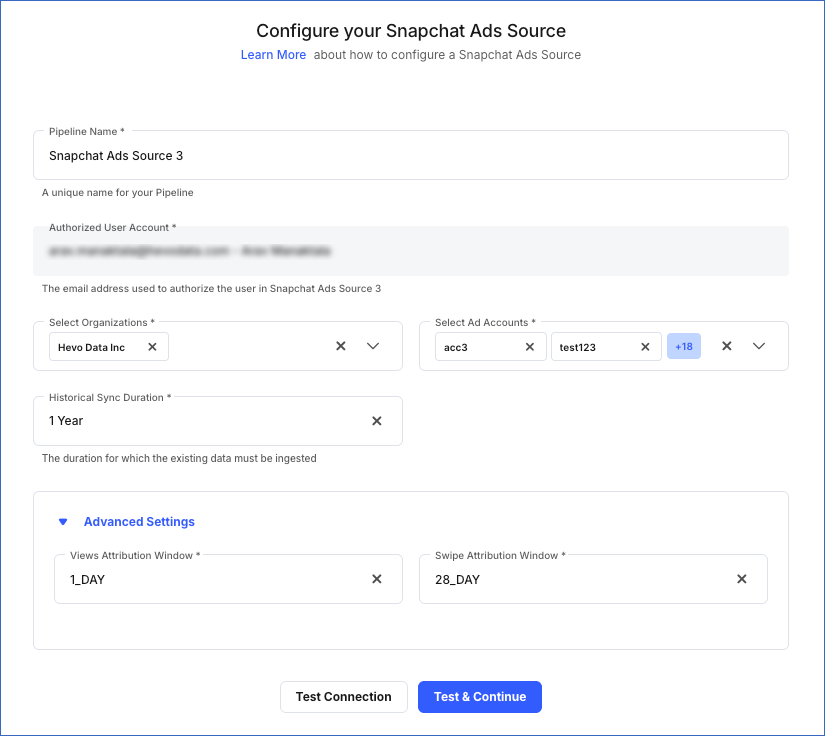
On the Configure your Snapchat Ads Source page, specify the following:
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Select Organizations: The Snapchat organization whose data you would like to ingest. You can select multiple organizations.
-
Select Ad Accounts: The Snapchat Ads account whose data you would like to ingest. You can select multiple Ad Accounts.
-
Historical Sync Duration: The duration for which you want to ingest existing data from the Source. This cannot be changed after the Pipeline is created. Default duration: 1 Year.
-
Advanced Settings:
-
Attribution Windows: The number of days between a user’s responses on an ad. You can specify either one or both of the following:
-
View Attribution Window: The number of days between a person viewing your ad and taking an action such as visiting a page. Default value: 1_Day.
-
Swipe Attribution Window: The number of days between a person swiping up on an ad and taking an action such as tapping a story tile or sharing a lens with a friend. Default value: 28_Day.
-
-
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 3 Hrs | 1 Hr | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: The first run of the Pipeline ingests historical data for the selected reports and objects on the basis of the historical sync duration specified at the time of creating the Pipeline and loads it to the Destination. Default duration: 1 Year.
-
Incremental Data: Once the historical load is complete, all new and updated records are ingested as per the ingestion frequency.
-
For objects, Hevo performs full load to capture any data changes.
-
For reports, Hevo incrementally fetches data up to the previous day (as per the Snapchat Ads account’s timezone).
-
-
Refresher Data: Daily Reports are refreshed once a day, and hourly reports are refreshed once every 6 hours. The refresher window depends on the attribution window you select. For example, if you select a 28 day window, Hevo refreshes the daily report data once a day, and the hourly report data once every 6 hours for the past 28 days.
Custom frequency for Full Load objects
Hevo allows you to set the ingestion frequency for Full Load objects separately from the Pipeline ingestion frequency. You can reduce your Events quota consumption by ingesting Full Load objects at a lower frequency without affecting other objects in the Pipeline. Read Query Modes and Events Quota Consumption to know how different query modes affect your Events quota consumption.
You can identify the Full Load objects in the Pipelines Detailed View by the FL tag corresponding to their name. Alternatively, you can view only Full Load objects in your Pipeline by selecting Full Load from the Filter ( ![]() ) menu.
) menu.

Perform the following steps to set a custom ingestion frequency for Full Load objects:
-
In the Pipelines Detailed View, click the More (
 ) icon to open the Pipeline’s Action menu and click Change Schedule.
) icon to open the Pipeline’s Action menu and click Change Schedule.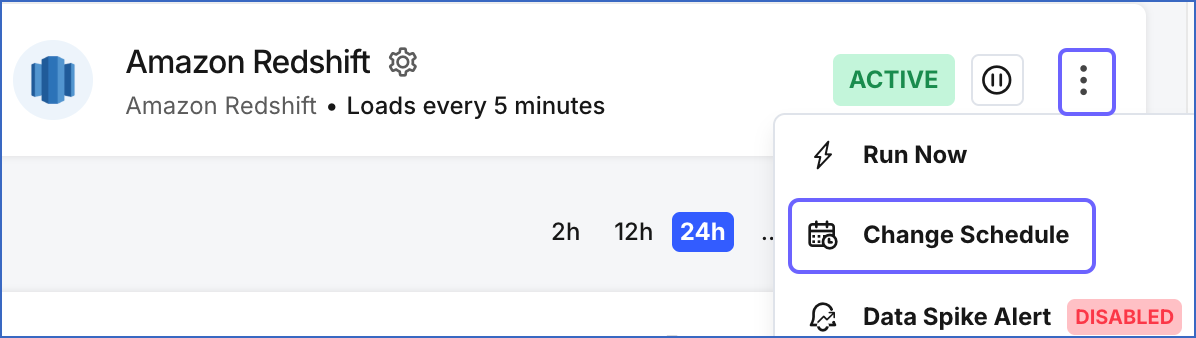
-
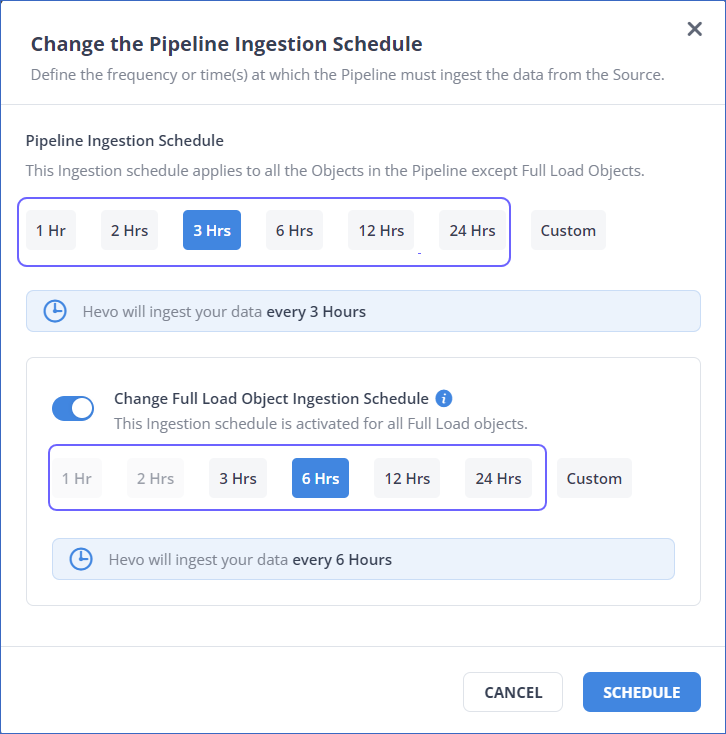
In the Change the Pipeline Ingestion Schedule pop-up window, enable the Enable Full Load Object Ingestion Schedule option.

Note:
- For custom frequency, this option is available only when Run at fixed interval is selected.
- If your Pipeline ingests data from Full Load objects on an independent schedule, manual actions such as Run Now and Restart Object are automatically deferred to the next ingestion schedule. To run any of these actions immediately, turn off the Full Load Object Ingestion Schedule option, trigger the required action, and then re-enable the schedule.
-
Select the ingestion frequency for the Full Load objects as per your requirements. You can select Custom and define the ingestion frequency by specifying an integer value in hours.
Note: Full Load objects can be ingested at a frequency more than or equal to the Pipeline’s ingestion frequency.

-
Click Schedule.
The updated schedule is applied immediately.
Note: The following image displays the frequencies suggested by Hevo for teams created before Release 2.21:
Handling Deleted Objects
Snapchat Ads APIs allow performing a soft delete of records. For the deleted records, Hevo sets the deleted column to True in the ingested data and the Destination.
Hevo tracks the deleted Events through the metadata column, deleted and replicates that information for the following objects:
| Object Name | Event Type Tracked |
|---|---|
| ADS | updated |
| AD SQUADS | deleted |
| CAMPAIGNS | deleted |
Note: As Hevo also replicates the deleted data, you might see more Events in your Destination than in the Source.
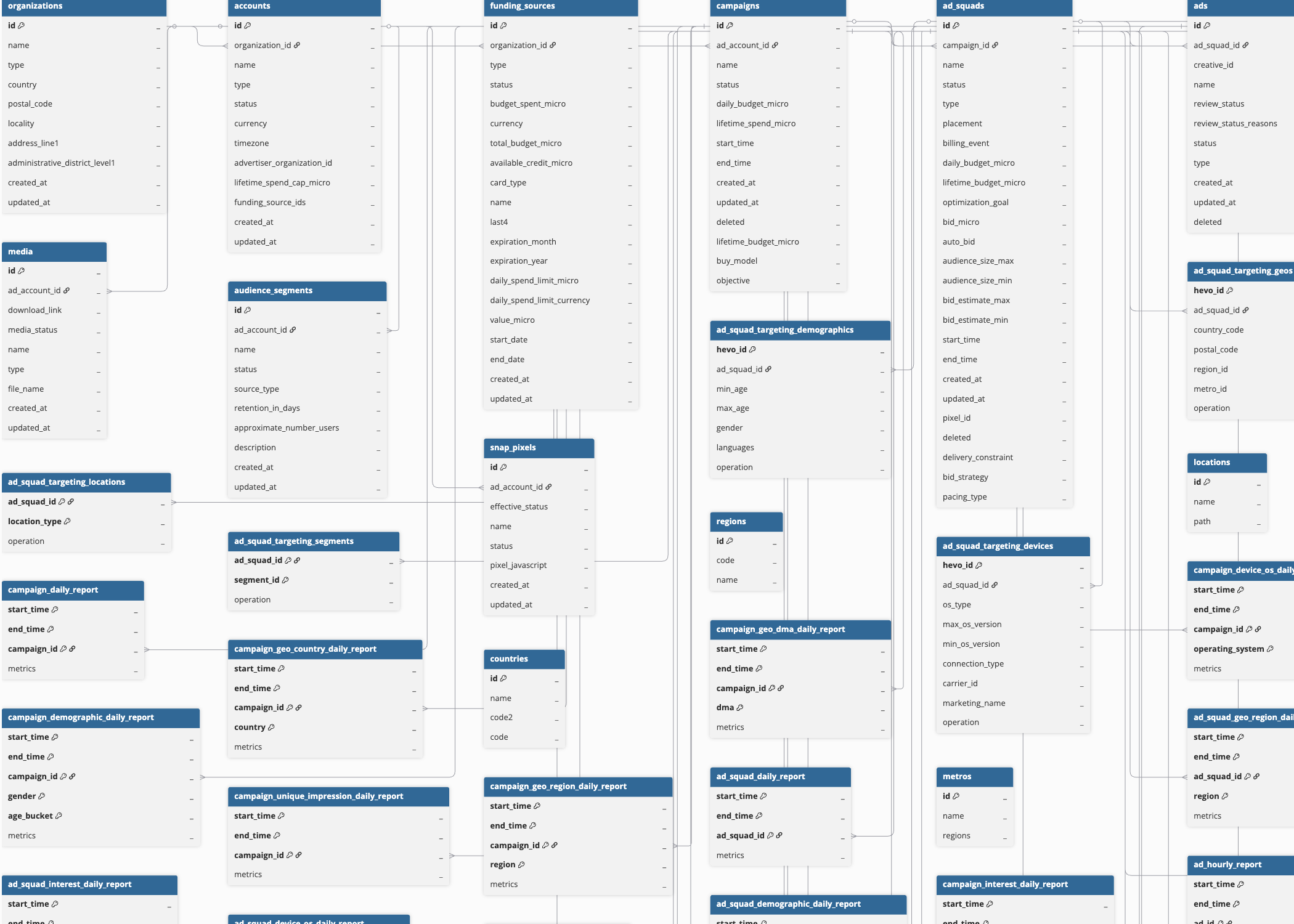
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination. For a detailed view of the objects, fields, and relationships, click the ERD.
Data Model
Hevo fetches both objects and reports from your specified ad account. Reports provide metrics around your users, their interaction related details, and the performance of your Ads.
Objects
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
| Object | Description |
|---|---|
| Account | Contains the details of the Snapchat Ads account. |
| Ads | Contains information required to display an ad per ads squad. |
| Ad Squads | Contains information of ad squads associated with an ad campaign. |
| Audience Segments | Contains the list of created audience segments. |
| Campaigns | Contains the details of the ad campaigns per ad account. |
| Creatives | Contains the details of creatives owned by an ad account. |
| Funding Sources | Contains information about the configured funding sources responsible to pay for the ad activity within an ad account of an organization. |
| Media | Contains details of media assets uploaded to the ad account. |
| Organizations | Contains the organization details of the user associated with the Snapchat Ads account. |
| Snap Pixels | Contains the details of Snap Pixels associated with the Snapchat Ads account. |
Reports
The following reports are replicated as tables in the Destination when you run the Pipeline:
Ad Reports
The Ad reports include the following reports:
-
AD_HOURLY_REPORT
-
AD_DAILY_REPORT
-
AD_GEO_COUNTRY_DAILY_REPORT
-
AD_GEO_REGION_DAILY_REPORT
-
AD_GEO_DMA_DAILY_REPORT
-
AD_INTEREST_DAILY_REPORT
-
AD_DEVICE_OS_DAILY_REPORT
-
AD_DEVICE_MAKE_DAILY_REPORT
-
AD_DEMOGRAPHIC_DAILY_REPORT
-
AD_UNIQUE_IMPRESSION_DAILY_REPORT
Ad Squad Reports
The Ad Squad reports include the following reports:
-
AD_SQUAD_HOURLY_REPORT
-
AD_SQUAD_DAILY_REPORT
-
AD_SQUAD_GEO_COUNTRY_DAILY_REPORT
-
AD_SQUAD_GEO_REGION_DAILY_REPORT
-
AD_SQUAD_GEO_DMA_DAILY_REPORT
-
AD_SQUAD_DEVICE_OS_DAILY_REPORT
-
AD_SQUAD_DEVICE_MAKE_DAILY_REPORT
-
AD_SQUAD_DEMOGRAPHIC_DAILY_REPORT
-
AD_SQUAD_UNIQUE_IMPRESSION_DAILY_REPORT
Campaign Reports
The Campaign reports include the following reports:
-
CAMPAIGN_DAILY_REPORT
-
CAMPAIGN_HOURLY_REPORT
-
CAMPAIGN_GEO_COUNTRY_DAILY_REPORT
-
CAMPAIGN_GEO_REGION_DAILY_REPORT
-
CAMPAIGN_GEO_DMA_DAILY_REPORT
-
CAMPAIGN_INTEREST_DAILY_REPORT
-
CAMPAIGN_DEVICE_OS_DAILY_REPORT
-
CAMPAIGN_DEVICE_MAKE_DAILY_REPORT
-
CAMPAIGN_DEMOGRAPHIC_DAILY_REPORT
-
CAMPAIGN_UNIQUE_IMPRESSION_DAILY_REPORT
Limitations
- Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Apr-28-2026 | NA | Updated section, Configuring Snapchat Ads as a Source to mention that the historical sync duration cannot be changed after the Pipeline is created. |
| Nov-07-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring Snapchat Ads as a Source as per the latest UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| May-22-2025 | NA | Updated section, Custom frequency for Full Load objects to add a note about the behavior of manual ingestion actions. |
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Nov-05-2024 | NA | Updated sub-section, Custom frequency for Full Load objects as per the latest Hevo UI. |
| Mar-05-2024 | 2.21 | - Updated the ingestion frequency table in the Data Replication section. - Updated the Custom frequency for Full Load objects section with suggested frequencies for teams before and after Release 2.21. |
| Dec-07-2022 | NA | Updated section, Data Replication to reorganize the content for better understanding and coherence. |
| Sep-21-2022 | 1.98 | Added section, Custom frequency for Full Load objects to inform users about the option to change ingestion frequency for Full Load objects. |
| May-10-2022 | 1.88 | New document. |