Apache Kafka
On This Page
Apache Kafka is an open-source community distributed event streaming platform.
You can use Hevo Pipelines to replicate the data from your Apache Kafka Source to the Destination system.
Prerequisites
-
The bootstrap server information is available in Apache Kafka.
-
The Certificate Authority (CA) file, the client certificate, and the client key are available if Secure Sockets Layer (SSL) encryption is used.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Note: Hevo recommends using Apache Kafka version 0.10.0.1 or higher.
Perform the following steps to configure your Apache Kafka Source:
Locate the Bootstrap Server Information
To locate the bootstrap server information:
-
Open the
server.propertiesfile.Note: The location of the
server.propertiesfile varies depending on the operating system being used. Contact your server administrator if you cannot locate this file. -
Copy the entire line after
bootstrap.servers:that contains the list of bootstrap servers and ports.For example: Copy
hostname1:9092, hostname2:9092from the line below:bootstrap.servers: hostname1:9092, hostname2:9092You can use this information while configuring your Hevo Pipeline.
Configure Secure Sockets Layer (SSL) (Optional)
In the context of SSL/TLS:
-
A KeyStore is a secure collection of identity certificates and private keys. By default, the KeyStore is in Java KeyStore (.jks) format.
-
CN represents the common name of the server protected by the SSL certificate.
-
FQDN represents the most complete domain name that identifies a host or server.
Hevo requires the CA file, the client certificate, and the client key to configure Apache Kafka as a Source if SSL encryption is enabled in Hevo. To generate these files, log in to the Kafka server folder where the Kafka TrustStore and KeyStore are located and perform the following steps:
1. Generate Client Certificate and Client Key
-
Enter the following command on the Kafka server command line:
keytool -keystore {key_store_name}.jks -alias {key_store_name_alias} -keyalg RSA -validity {validity} -genkeyNote: The alias is just a shorter name for the key store. The same alias needs to be reused throughout the steps.
You need to remember the passwords for each KeyStore or TrustStore to use later.
-
Provide the answers to questions that are displayed on the interactive prompt.
For the question
What is your first and last name?, enter the CN for your certificate.Note: The Common Name (CN) must match the fully qualified domain name (FQDN) of the server to ensure that Hevo connects to the correct server. Refer to this page to find the FQDN based on the type of the server.
2. Create your Certificate Authority
Note: This step is optional if you already have a CA to sign the certificates.
A Certificate Authority (CA) is responsible for signing certificates for each server in the cluster to prevent unauthorized access.
Run the following command on the Kafka server command line to create your own certificate authority:
openssl req -new -x509 -keyout ca-key -out ca-cert -days {validity}
3. Add the Certificate Authority to a TrustStore
A TrustStore is a secure collection of CA certificates that the broker can trust.
Run the following command on the Kafka server command line to add the CA to the broker’s truststore:
keytool -keystore {broker_trust_store}.jks -alias CARoot -importcert -file ca-cert
4. Sign the certificate with the CA file
Enter the following command on the Kafka server command line to sign the certificates with the CA file:
-
Export the certificate from the KeyStore:
keytool -keystore {key_store_name}.jks -alias {key_store_name_alias} -certreq -file cert-file -
Sign the certificate with the CA:
openssl x509 -req -CA ca-cert -CAkey ca-key -in cert-file -out cert-signed -days {validity} -CAcreateserial -passin pass:{ca-password} -
Add the certificates back to the keystore:
keytool -keystore {key_store_name}.jks -alias CARoot -importcert -file ca-cert keytool -keystore {key_store_name}.jks -alias {key_store_name_alias} -importcert -file cert-signed
5. Extract the Client Certificate key from KeyStore
Before extracting the client certificate key from the KeyStore, you must convert the KeyStore file from its existing .jks format to the PKCS12 (.p12) format for interoperability.
Enter the following command in the Kafka server command line:
-
Convert the keystore from .jks format to .p12 format:
keytool -v -importkeystore -srckeystore {key_store_name}.jks -srcalias {key_store_name_alias} -destkeystore {key_store_name}.p12 -deststoretype PKCS12 -
Extract the client certificate key into a .pem file.
openssl pkcs12 -in {key_store_name}.p12 -nocerts -nodes > cert-key.pemThis is the format in which Hevo understands the certificate keys.
You can now find the following files in the Kafka server folder where the Kafka TrustStore and KeyStore are located and upload them to Hevo to configure Apache Kafka as a Source.
-
Client Certificate:
cert-signed -
Client Key:
cert-key.pem -
CA File:
ca-cert
Whitelist Hevo’s IP Addresses
You need to whitelist the Hevo IP address for your region to enable Hevo to connect to your Kafka server. To do this:
-
Open the Kafka server configuration file:
sudo nano /usr/local/etc/config/server.propertiesNote: Depending on how Kafka was installed, this file may be in a different location.
-
In the file, scroll to
listenerssection. If it does not exist, add it on a new line. -
Add the following under
listeners:<protocol>://0.0.0.0:<port>Or
<protocol>://<hevo_ip>:<port>Note: The
<protocol>can be PLAINTEXT or SSL, and theportcan be the same port used in your bootstrap server. The<hevo_ip>is the Hevo IP address for your region. If you are adding these to existing values, use comma to separate the entries. -
Save the file.
Configure Apache Kafka Connection Settings
Perform the following steps to configure Apache Kafka as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Kafka.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Configure your Kafka Source page, specify the following:
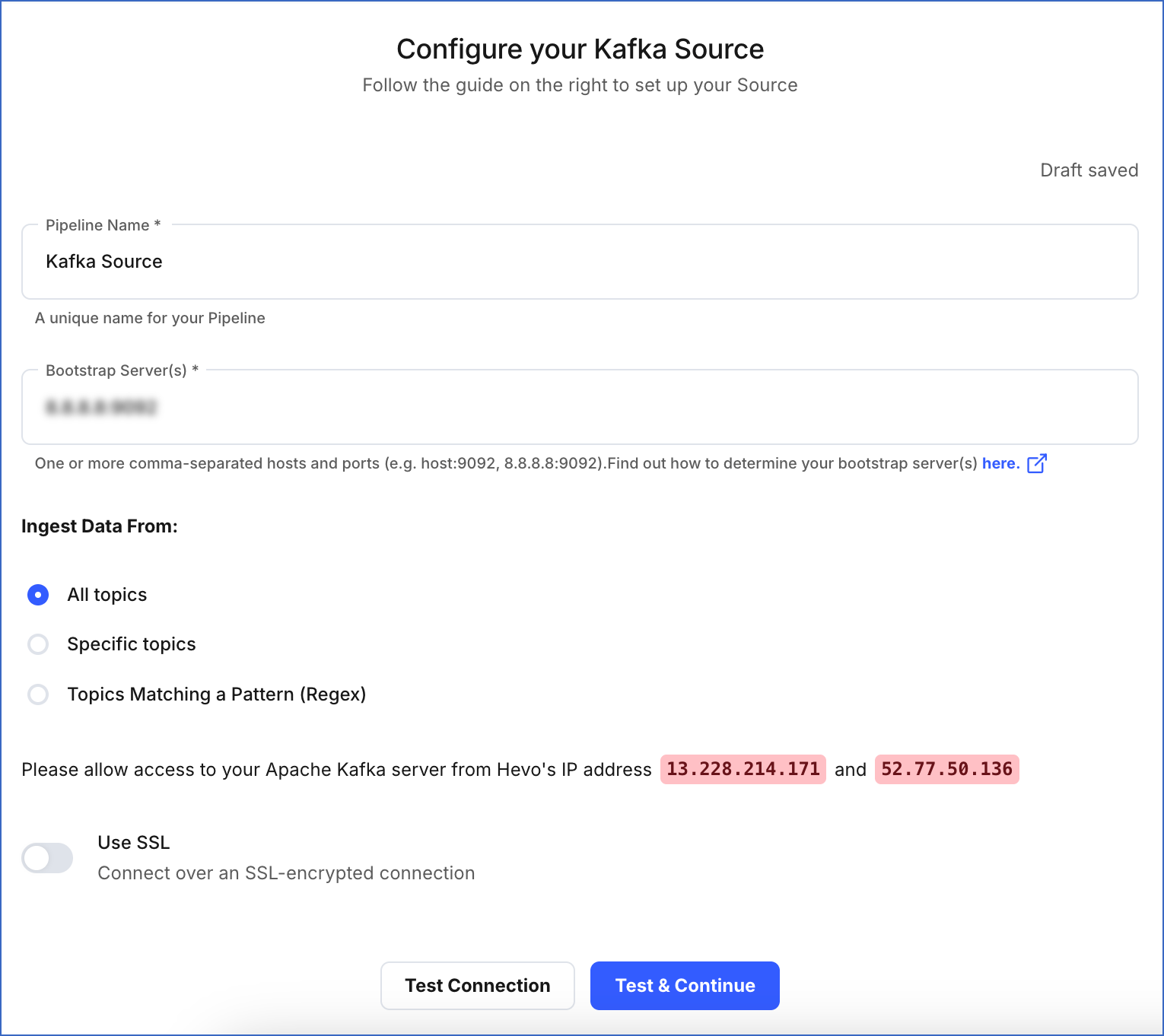
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Bootstrap Server(s): The bootstrap server(s) extracted from Apache Kafka.
-
Ingest Data From
-
All Topics: Select this option to ingest data from all topics. Any new topics that are created are automatically included.
-
Specific Topics: Select this option to manually specify a comma-separated list of topics. New topics are not automatically added in this option.
-
Topics Matching a Pattern (Regex): Select this option to specify a Regular Expression (regex) to match and select the topic names. This option also fetches data for new topics that match the pattern dynamically. You can test your regex patterns here.
-
-
Use SSL: Enable this option to use an SSL-encrypted connection. Specify the following:
-
CA File: The file containing the SSL server certificate authority (CA).
-
Load all CA Certificates: If selected, Hevo loads all CA certificates (up to 50) from the uploaded CA file, else it loads only the first certificate.
Note: Select this check box if you have more than one certificate in your CA file.
-
-
Client Certificate: The client public key certificate file.
-
Client Key: The client private key file.
-
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 5 Mins | 5 Mins | 1 Hr | NA |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
- Incremental Data: Once the Pipeline is created, all new and updated records are synchronized with your Destination as per the ingestion frequency.
If you restart an object via the Pipeline UI, Hevo ingests all the data available at that time in the Source.
For records that are structured as a list of records, Hevo ingests each record as an individual record. Each child record contains a common field called ref_id which is used to indicate a common parent record.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Limitations
-
Hevo only supports SSL/TLS-encrypted and plain text data in Apache Kafka.
-
Hevo only supports JSON data format in Apache Kafka.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-11-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configure Apache Kafka Connection Settings as per the latest UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-18-2024 | 2.21.2 | Updated section, Configure Apache Kafka Connection Settings to add information about the Load all CA certificates option. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Dec-07-2022 | NA | Updated section, Data Replication to reorganize the content for better understanding and coherence. |
| Sep-19-2022 | NA | Added section, Data Replication. |