Front
On This Page
Front is a customer communication hub that connects all communication channels such as email, SMS, WhatsApp, social media, and live chat to your team’s inbox. Front also allows you to share knowledge and collaborate in real-time on critical customer messages to provide the best response possible.
Hevo uses Front’s Core API to replicate the data present in your Front account to the desired Destination database or data warehouse for scalable analysis.
Prerequisites
-
An active Front account from which data is to be ingested exists.
-
The API token is available to provide Hevo access to your Front account.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Obtaining the API Token
You require an API token to authenticate Hevo on your Front account. The token does not expire and can be reused for all your Pipelines. Therefore, you can use an existing token or create one.
Note: You must log in as a user with the Admin Access role to perform these steps.
To obtain the API token:
-
Log in to your Front account.
-
In the bottom left corner of the page, click the Settings (
 ) icon.
) icon.
-
In the left navigation pane, click Developers.
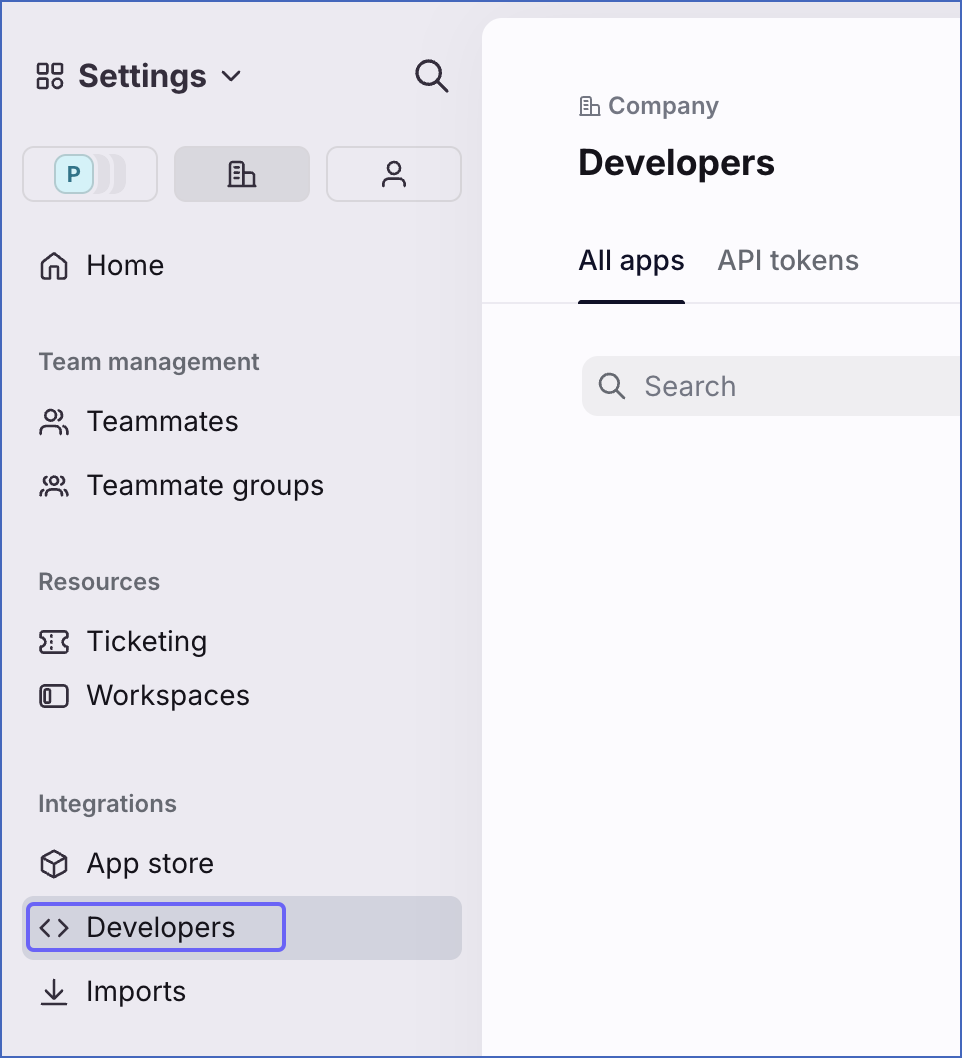
-
On the Developers page, under the API Tokens tab, do one of the following:
-
Create an API token
-
Click Create API token.
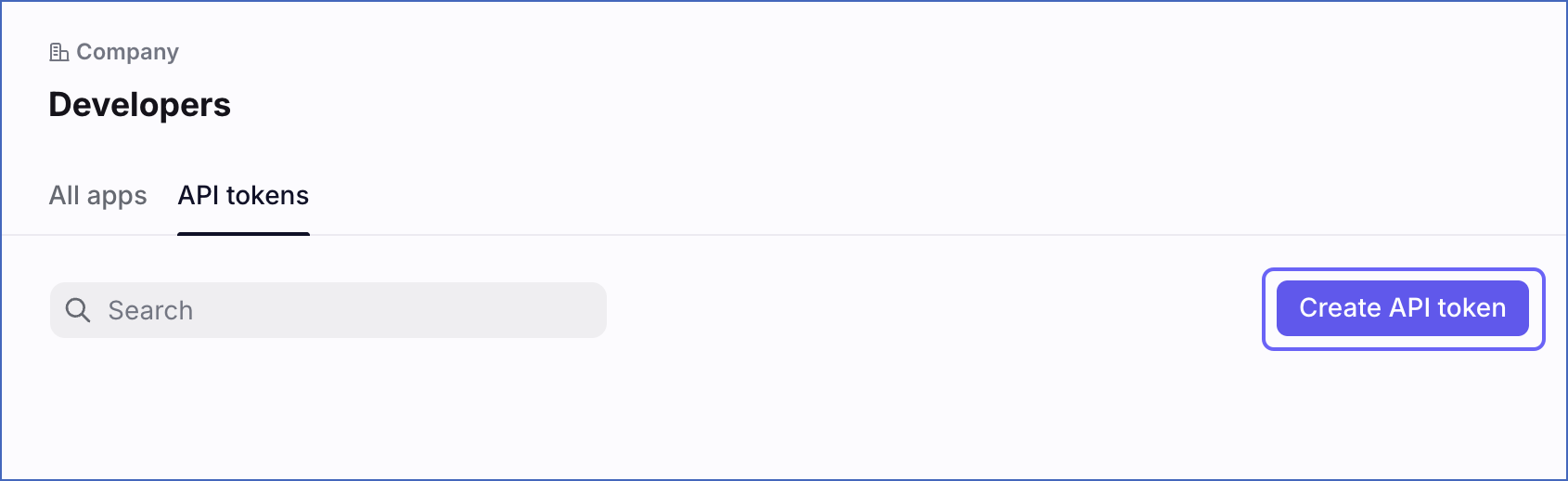
-
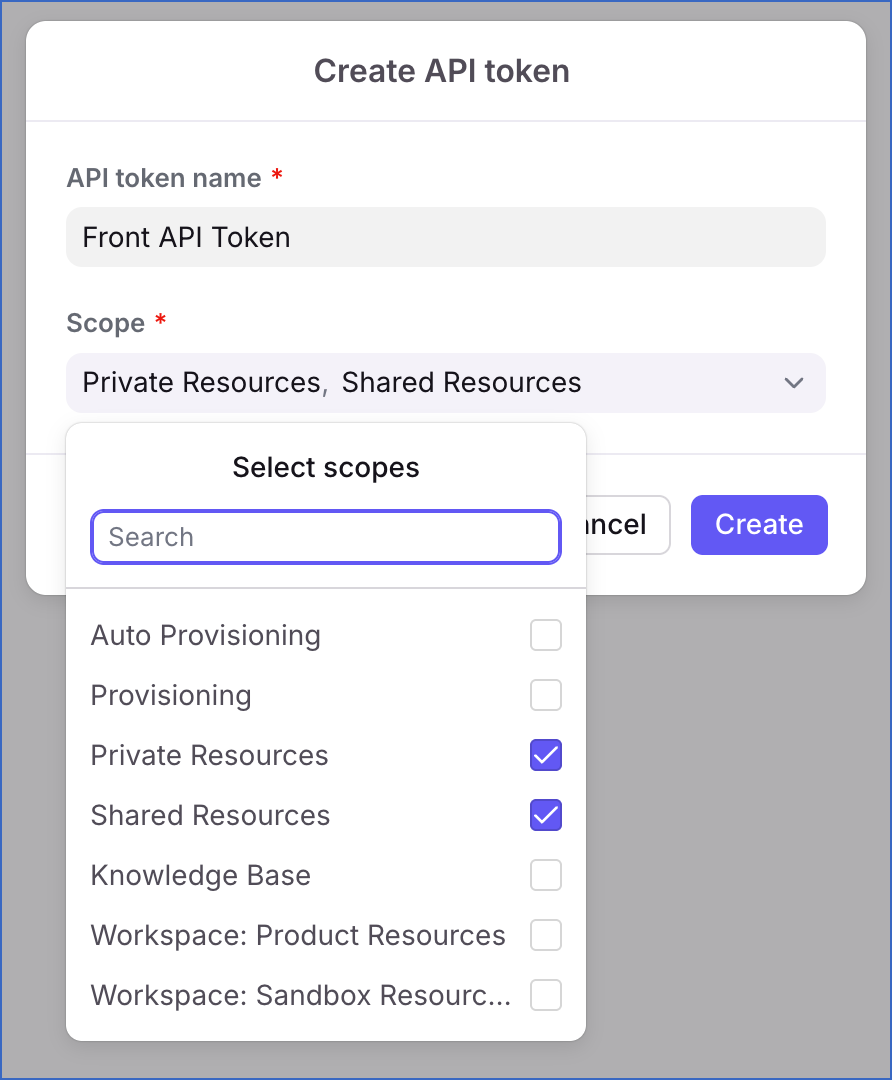
On the Create API token page, do the following:
-
In the API token name field, specify a name for the API token. For example, Front API token.
-
In the Scope field, select the following scopes:
-
Shared Resources: Provides access to team resources across all the teams in your company.
-
(Optional) Private Resources: Provides access to private resources such as inboxes, conversations, messages, rules, and tags of individual team members. If you do not provide this access, Hevo skips ingesting data from the private resources of individual team members.
Note: If you want to enable this scope for your API token, each team member must individually grant API access to their private resources. To do so, navigate to My Preferences and enable the Allow access to my individual resources via the API toggle.

-
-
Click Create.
-
-
Click Copy to copy the API token displayed in the API token field and save it securely like any other password.

-
-
Use an existing API token
-
From the list of existing API tokens, click the token that you want to use.
-
Click Copy to copy the API token displayed in the API token field, and save it securely like any other password.

Use this token while configuring your Hevo Pipeline.
-
-
Configuring Front as a Source
Perform the following steps to configure Front as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Front.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Configure your Front Source page, specify the following:
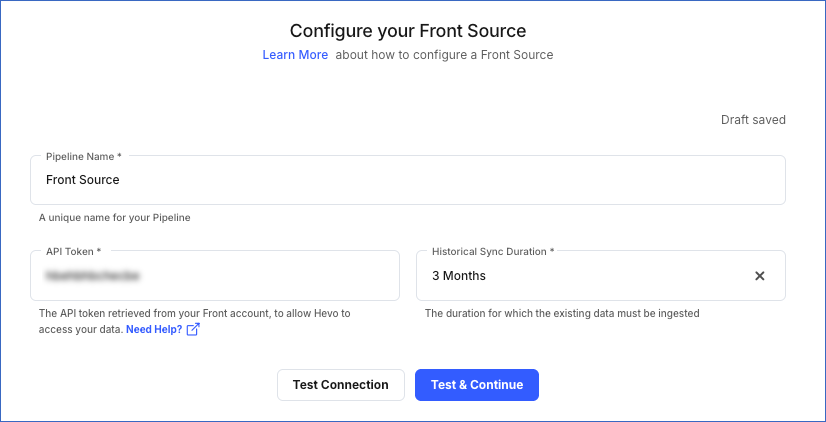
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
API Token: The API token that you obtained from your Front account.
-
Historical Sync Duration: The duration for which you want to ingest existing data from the Source. This cannot be changed after the Pipeline is created. Default duration: 3 Months.
Note: If you select All Available Data, Hevo ingests all the data available in your Front account since January 01, 1970.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 5 Mins | 5 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: The first run of the Pipeline ingests historical data for the selected reports on the basis of the historical sync duration specified at the time of creating the Pipeline and loads it to the Destination. Historical load parallelization is applicable for this Source. Default duration: 3 Months
-
Incremental Data: Once the historical load is complete, all new and updated records are synchronized with your Destination as per the ingestion frequency.
Note: While replicating the Conversations object, if required permissions are not enabled on any inbox, Hevo skips that inbox and proceeds to the next accessible inbox to ingest data. If you want to ingest data from a skipped inbox, you can assign permissions on it and restart ingestion for the object.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination database. For a detailed view of the objects, fields, and relationships, click the ERD.
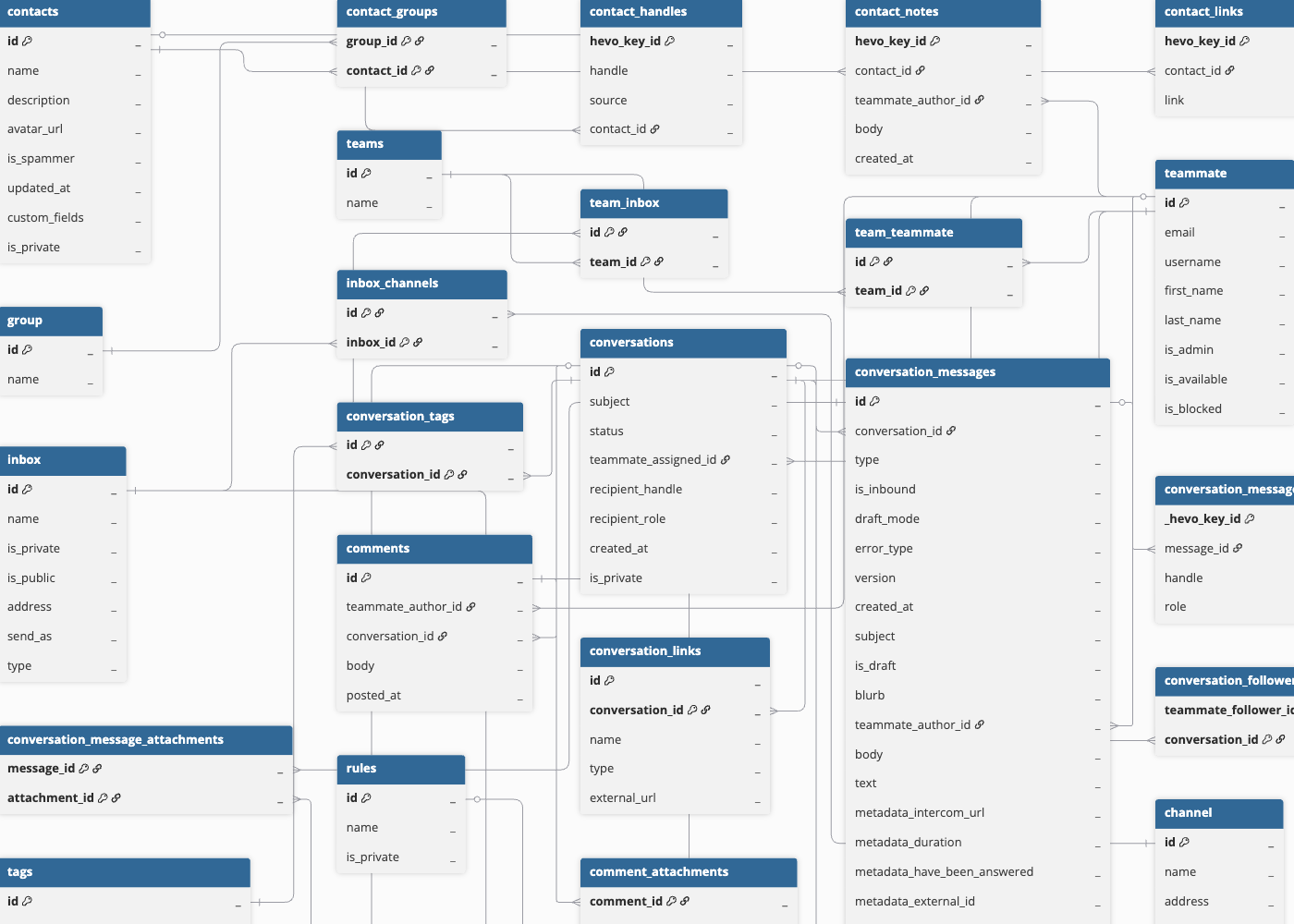
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
| Object | Description |
|---|---|
| Attachments | Contains the files attached in a conversation. |
| Channel | Contains the details about the channels in your Front account. A channel is a resource which can send and receive messages. |
| Comments | Contains the list of comments in your Front account. A comment is a private message written by a teammate, visible only to the other teammates. |
| Comment Mentions | Contains the details of the teammates mentioned in a comment. |
| Contacts | Contains the details of a person or entity with whom you have communicated. |
| Contact Groups | Contains the details of the groups a contact belongs to. |
| Contact Handles | Contains the details of the handles used to reach the contact. |
| Contact Notes | Contains the notes added to a contact. |
| Contact Links | Contains the list of all the links associated with a contact. |
| Conversations | Contains the details about conversations. A conversation is a unique thread of messages. |
| Conversation Tags | Contains the tags used in a conversation. |
| Conversation Links | Contains the links used in conversation. |
| Conversation Followers | Contains the details of the teammates following a conversation. |
| Conversation Inboxes | Contains the inbox where a conversation resides. |
| Conversation Messages | Contains the messages in a conversation. |
| Conversation Message Attachments | Contains the attachments present in the messages of a conversation. |
| Conversation Message Recipient | Contains the details of a recipient of the message in a conversation. |
| Groups | Contains the list of groups that a contact belongs to. |
| Inbox | Contains the details of an inbox. An inbox is a container of messages. |
| Inbox Channels | Contains the details of all the channels in an inbox. |
| Rules | Contains the details of the rules in your account. A rule is a set of conditions that triggers automatic actions when they are met. |
| Rule Actions | Contains the list of actions performed by a rule. |
| Shifts | Contains the details of a shift. A shift represents an interval of time repeated over one or more days in a week. |
| Tags | Contains the details about the tags used in your conversations. A tag is a label that is used to classify conversations. |
| Team | Contains the list of teams in your company. Team is a Full Load object. |
| Teammate | Contains the details of your teammates. A teammate is a Front user, a member of your company |
| Teammate Shifts | Contains information about the shifts of your teammates. |
| Team Inbox | Contains all the inboxes belonging to a team. |
| Team Teammate | Contains the details of all the teammates in a team. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Limitations
Hevo treats a parent and its child objects differently. This section lists the parent objects along with their child objects, and the differences in how you can manage these objects.
| Parent Objects | Child Objects |
|---|---|
| Contacts | - Contact Notes |
| Conversations | - Messages - Rules - Tags - Shifts - Comments - Comment Mentions - Inbox - Inbox Channels - Conversation Followers - Teammates |
-
If you skip a parent object, its child objects are also skipped.
-
If you skip a parent object, it is marked as skipped, but its child objects are still shown as active.
-
You only have the option to skip or include child objects, whereas for parent objects, you have additional options such as changing the offset, restarting the object, or running it now.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Apr-28-2026 | NA | Updated section, Configuring Front as a Source to mention that the historical sync duration cannot be changed after the Pipeline is created. |
| Nov-12-2025 | NA | Updated the document as per the latest Hevo UI. |
| Oct-30-2025 | NA | Updated section, Obtaining the API Token as per the latest Front UI. |
| Sep-18-2025 | NA | Updated section, Configuring Front as a Source as per the latest UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| May-23-2024 | NA | Updated section, Obtaining the API Token to reflect the latest Front UI. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Apr-04-2023 | NA | Updated section, Configuring Front as a Source to update the information about historical sync duration. |
| Oct-17-2022 | NA | Updated section,Data Replication to add information about historical load parallelization for quicker access to historical data. |
| Sep-05-2022 | NA | Updated section, Data Replication to reorganize the content for better understanding and coherence. |
| May-24-2022 | 1.89 | New document. |