Twilio
On This Page
Twilio is a cloud communications platform that allows users to programmatically make and receive phone calls, and exchange text messages.
Hevo uses the Twilio REST API to replicate the data present in your Twilio account into the desired Destination database or data warehouses for scalable analysis. You must provide the Twilio API key, which is a combination of the API string identifier (SID) and the API Secret, to allow Hevo to access the Twilio data.
Prerequisites
-
An active Twilio account with privileges to create an API key.
-
The API key is available to allow Hevo to connect to your Twilio account.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Creating the Twilio API Key
You require an API key to authenticate Hevo on your Twilio account.
-
Log in to the Twilio console.
-
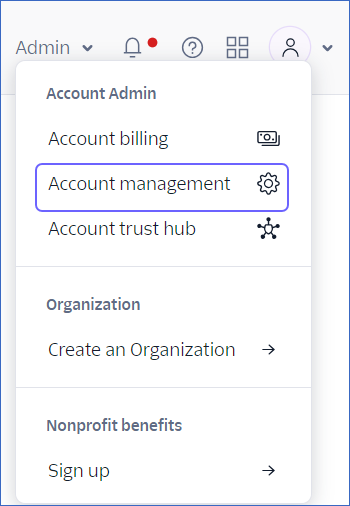
Click the Admin drop-down and select Account management.
-
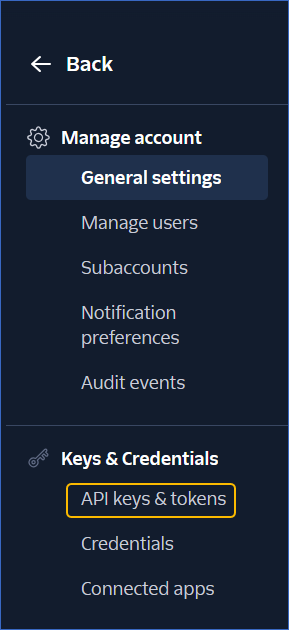
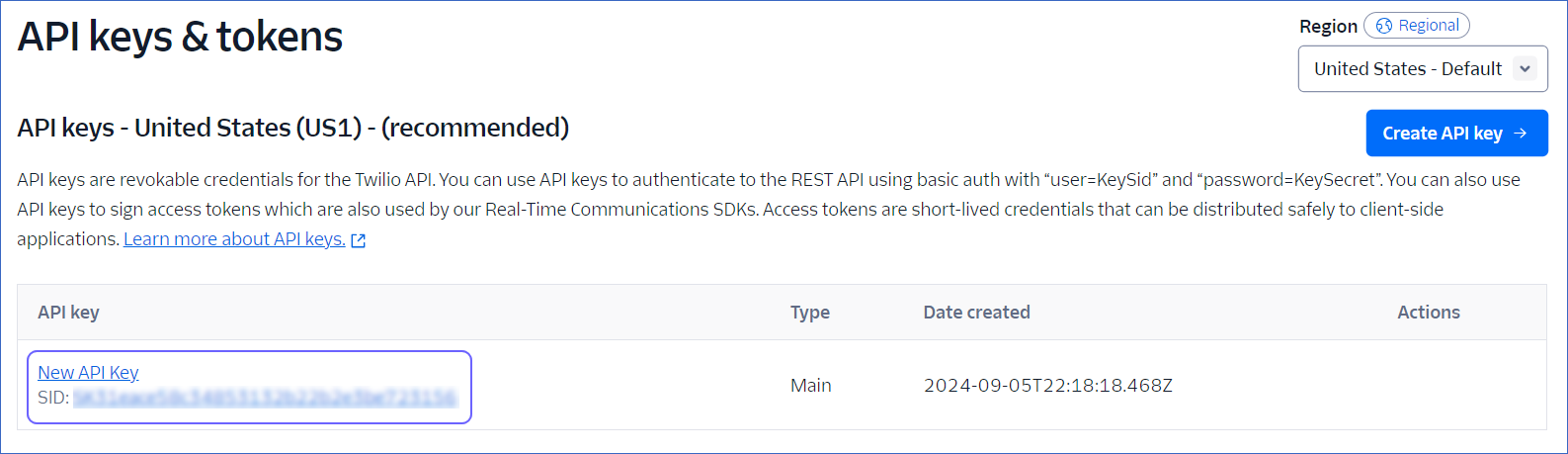
In the left navigation pane, under Keys & Credentials, click API keys & tokens.
-
On the API keys & tokens page, click Create API key.

-
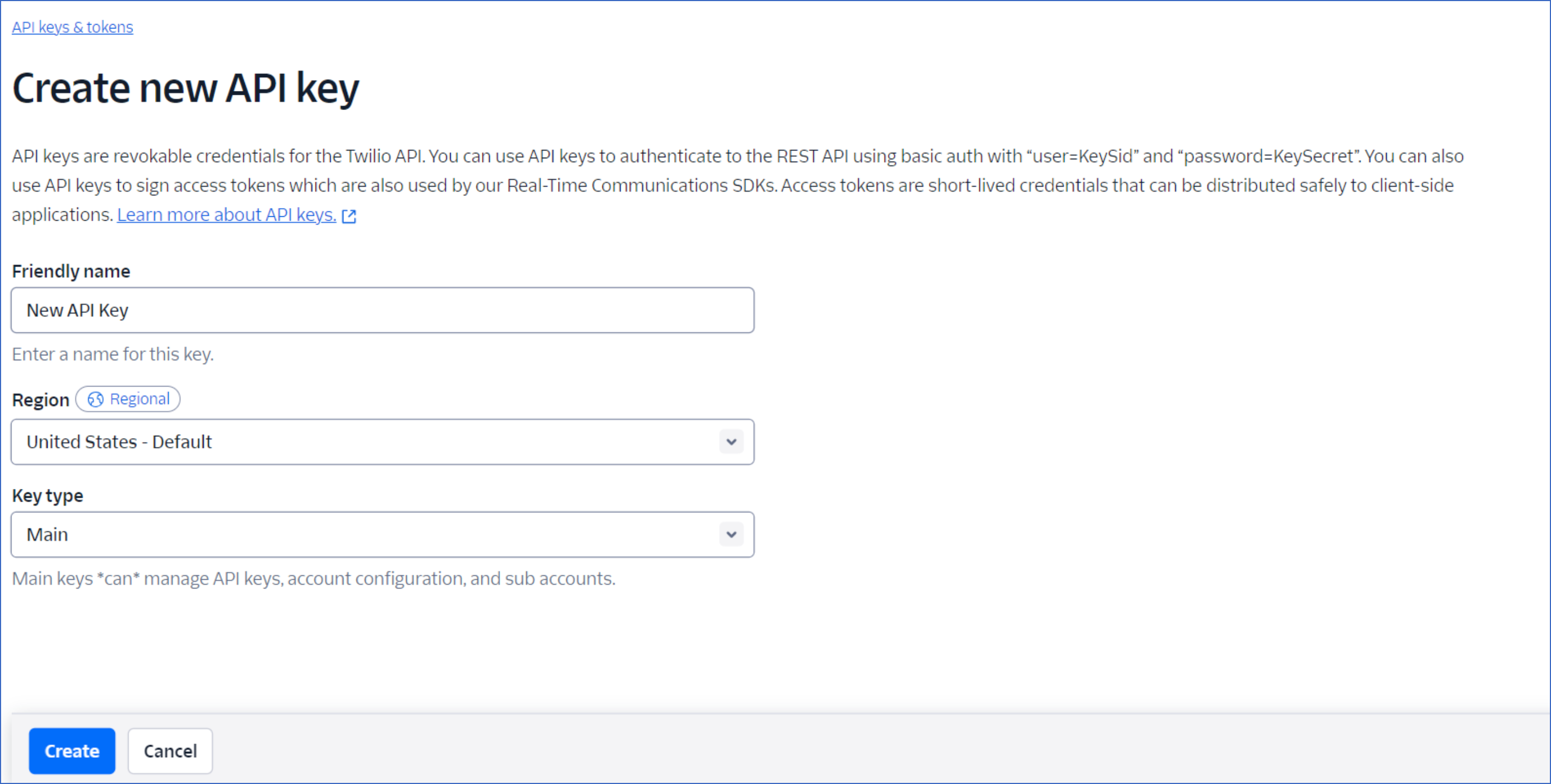
On the Create new API key page, specify the following:
-
Friendly name: A name for your API key.
-
Region: The region where your Twilio data is stored.
-
Key type: The type of API key. This can be: Standard or Main. Select Main key type to allow Hevo to access data from both your primary (main) and sub-account.
-
You must generate separate Main API Keys for each account, as the key for a main account cannot access data from a sub-account, and vice versa. Read API Key Resource to know more about the two key types.
-
You must create separate Pipelines to ingest data from your main and sub-accounts. Read Subaccounts.
-
-
-
Click Create.
-
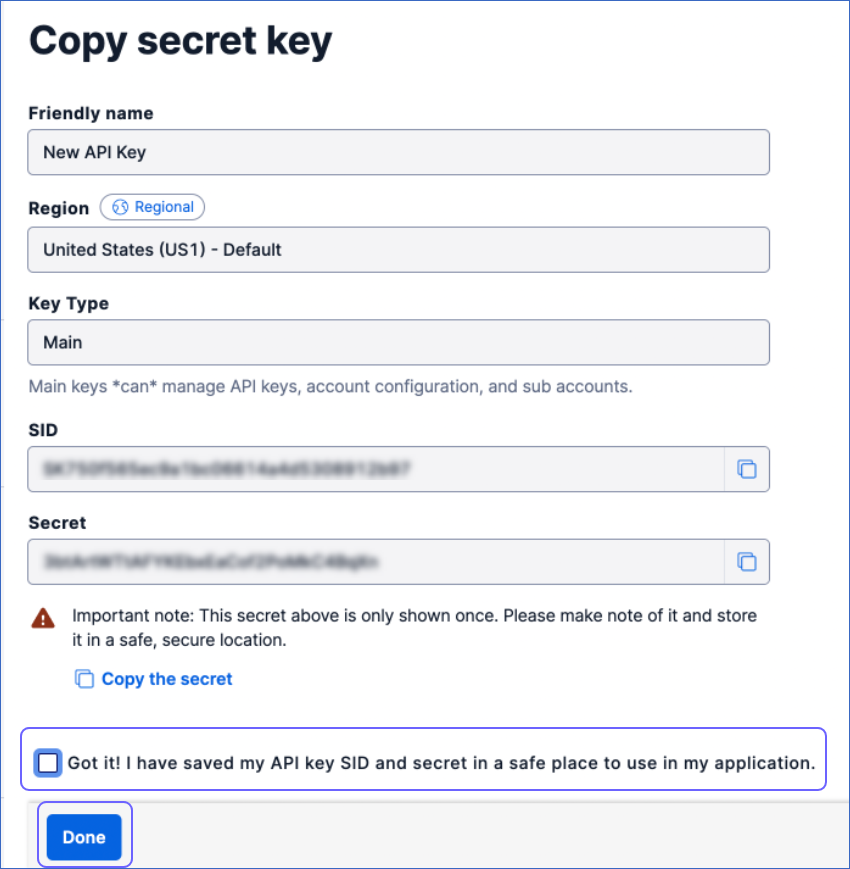
On the Copy secret key page, copy the API SID and Secret and save them securely like any other password. You can use these credentials while configuring your Hevo Pipeline.
-
Select the confirmation check box below, and click Done.
You can view the API key that you created on the API keys and tokens page.
Configuring Twilio as a Source
Perform the following steps to configure Twilio as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Twilio.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
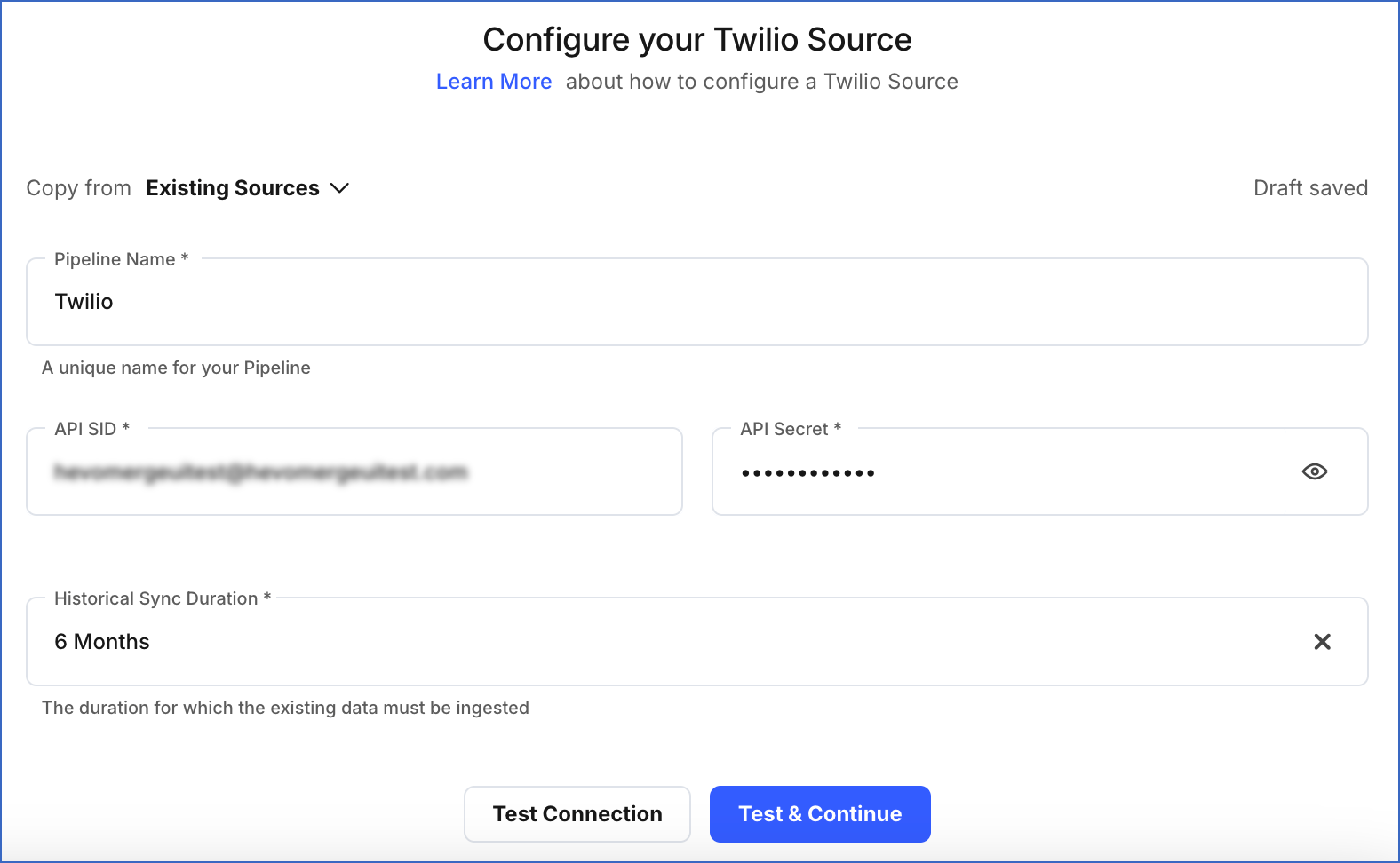
On the Configure your Twilio Source page, specify the following:
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
API SID: The string identifier (SID) for your API key.
-
API Secret: The secret for your API key, retrieved from your Twilio account.
-
Historical Sync Duration: The duration for which you want to ingest existing data from the Source. This cannot be changed after the Pipeline is created. Default duration: 6 Months.
Note: If you select All Available Data, Hevo ingests all the data available in your Twilio account since March 13, 2008.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 6 Hrs | 1 Hr | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests historical data for the Usage Records object on the basis of the historical sync duration selected at the time of creating the Pipeline and loads it to the Destination. Default duration: 6 Months.
-
Incremental Data: Once the historical load is complete, all new and updated records for the object, Usage Records are synchronized with your Destination according to the Pipeline frequency.
Schema and Primary Keys
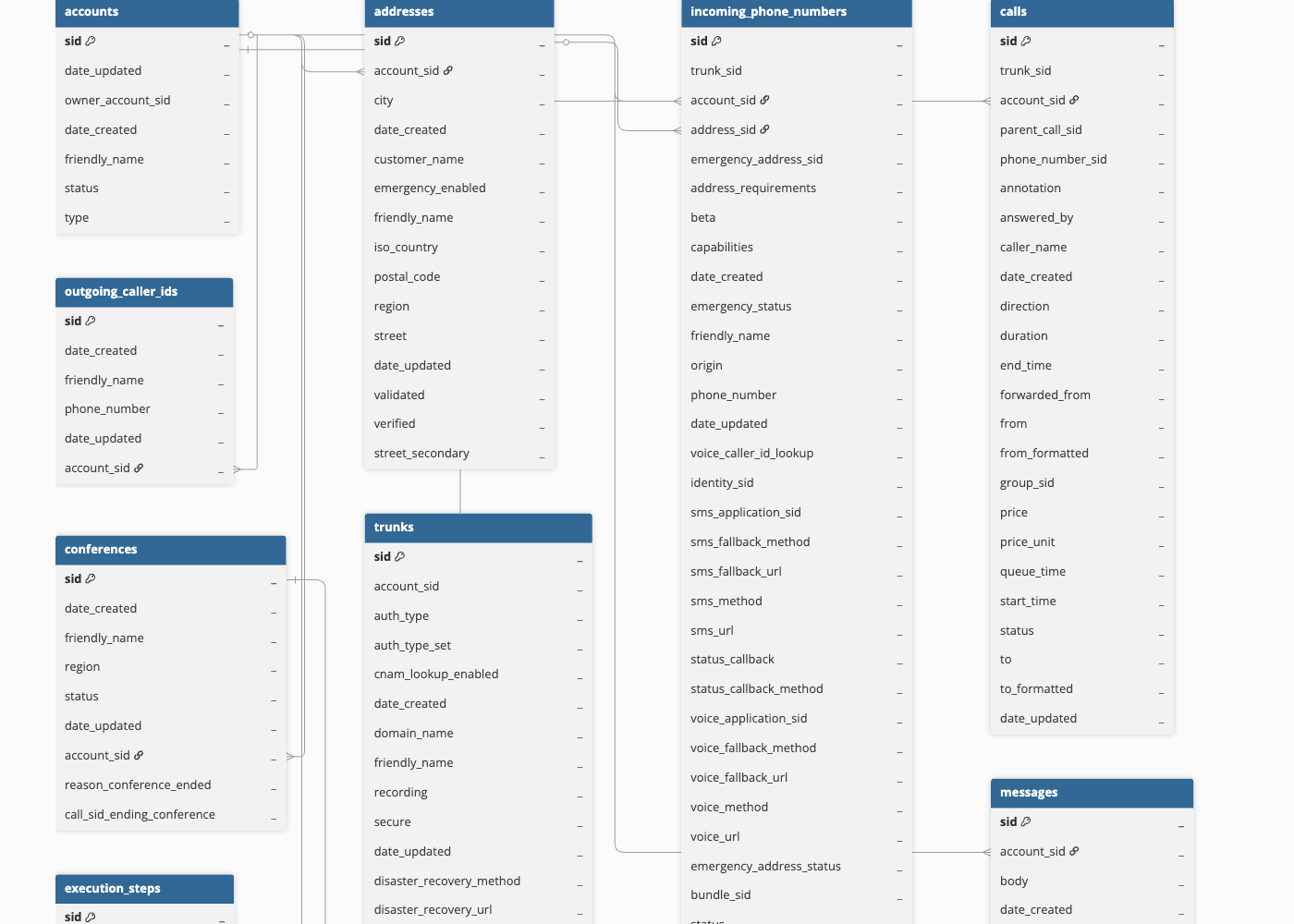
Hevo uses the following schema to upload the records in the Destination. For a detailed view of the objects, fields, and relationships, click the ERD.
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
Note: All objects other than Usage Records are Full Load objects.
| Object | Description |
|---|---|
| Accounts | Contains the details about your Twilio account and sub-accounts. These details are stored according to the API SID and API Secret provided by the user. It is the topmost entity and acts as a parent for all the other objects. |
| Addresses | Contains your and your customer’s physical location within a country. |
| Calls | Contains the list of incoming and outgoing calls made to all the phone numbers available for an account. |
| Conferences | Contains the details about conferences in your Twilio account. |
| Conversation Services | Contains the details about conversations in your Twilio account. It also contains the child objects, Conversations, Conversation Roles, and Conversation Users. |
| Conversations | Contains the list of the current participants in a conversation, and the messages that they have sent amongst each other. |
| Conversation Users | Contains the details about all the users in a conversation. Users are participants in a conversation with privileges such as the ability to edit and delete messages. |
| Conversation Roles | Contains the details about the roles that participants have been assigned in a conversation. This determines what they are able to do within a particular conversation, such as invite participants to be members of the conversation, post messages, and remove other participants from the conversation. |
| Flows | Contains the individual workflows that you create. Workflows control how tasks are prioritized and arranged into queues, and how they should move across queues over time. |
| Incoming Phone Numbers | Contains the phone numbers provisioned from Twilio and ported or hosted to Twilio. |
| Messages | Contains the details about an inbound or outbound message. |
| Outgoing Caller IDs | Contains the list of an account’s verified phone numbers. An Outgoing Caller ID represents a single verified number that may be used as a caller ID for making outgoing calls. |
| Trunks | Contains the details of Session Initiation Protocol (SIP) Trunks in your Twilio account. SIP Trunks are used to create cloud-based solutions for providing IP-based communications. |
| Usage Records | Contains the details about the actions, such as calls made and messages exchanged, by your Twilio account during any time period and by any usage category. This information makes it easy to build reporting and analytics tools for your application. |
Limitations
- Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Apr-28-2026 | NA | Updated section, Configuring Twilio as a Source to mention that the historical sync duration cannot be changed after the Pipeline is created. |
| Nov-06-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring Twilio as a Source as per the latest UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-31-2025 | NA | Added information about sub-accounts in Creating the Twilio API Key section |
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Nov-05-2024 | NA | Updated section, Creating the Twilio API Key as per the latest Twilio UI. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Apr-04-2023 | NA | Updated section, Configuring Twilio as a Source to update the information about historical sync duration. |
| May-24-2022 | 1.89 | New document. |