Wrike
On This Page
Wrike is a cloud-based collaboration and project management tool that allows you to efficiently manage tasks and projects, and asses productivity through resource management. It enables you to plan, budget your resources, assign tasks in the projects to employees, and track progress of the tasks through completion. It also enables you to collaborate more effectively with your peers through comments, mentions, and dashboards.
You can replicate the data from your Wrike account to a Destination database or data warehouse using Hevo Pipelines. Refer to section, Data Model for the list of supported objects.
Hevo uses the Wrike API v4 to replicate the data present in your Wrike account to the desired Destination database or data warehouse for scalable analysis.
Prerequisites
-
An active Wrike account from which data is to be ingested exists.
-
The access token is available to authenticate Hevo on your Wrike account. You must be logged in as an Admin user in Wrike to obtain it. Else, you can obtain it from your account administrator.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Obtaining the Access Token
You require an access token to authenticate Hevo on your Wrike account. As the access tokens do not expire, you can either use an existing token or create one.
Note: You must log in as an Admin user to perform these steps.
To create the access token:
-
Log in to your Wrike account.
-
Click the Profile and settings icon (which has your initials) at the top of the left navigation pane, and click Apps & Integrations in the drop-down.
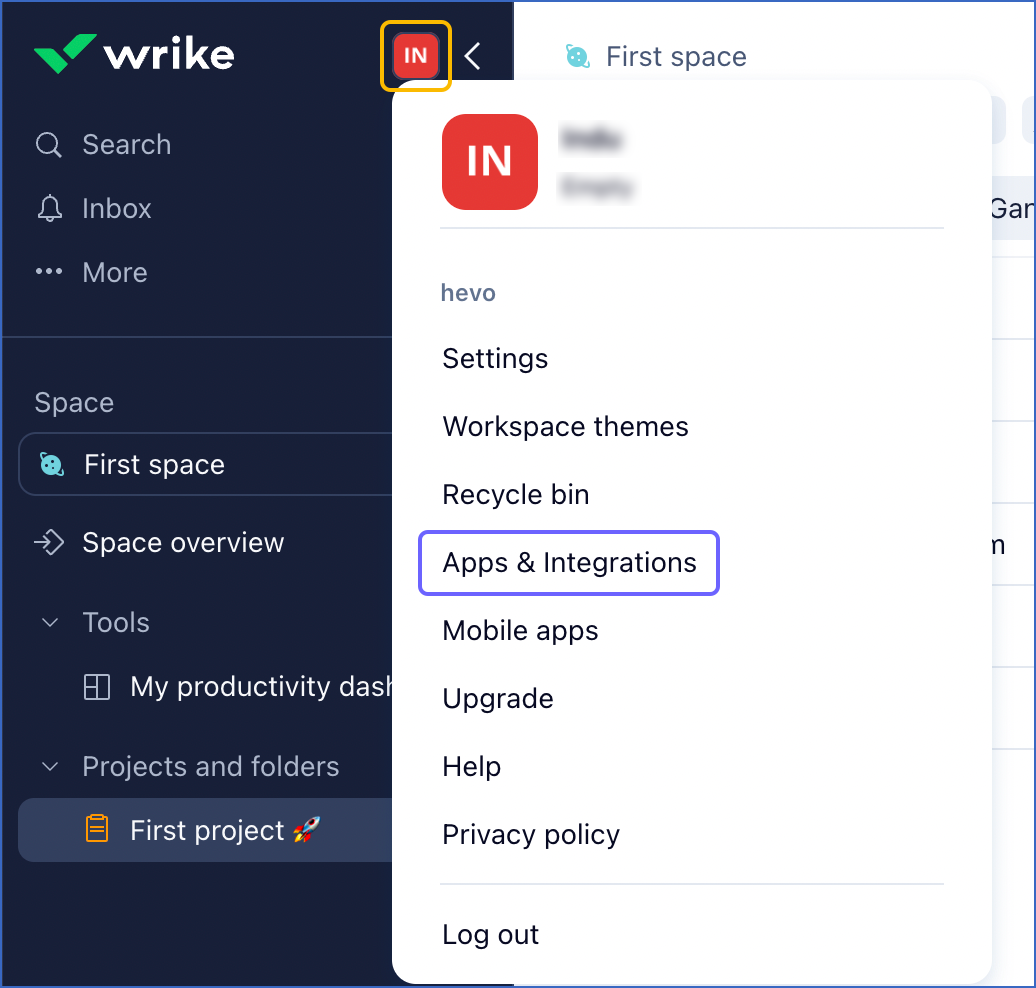
-
In the Apps & Integrations page, select the API tab.
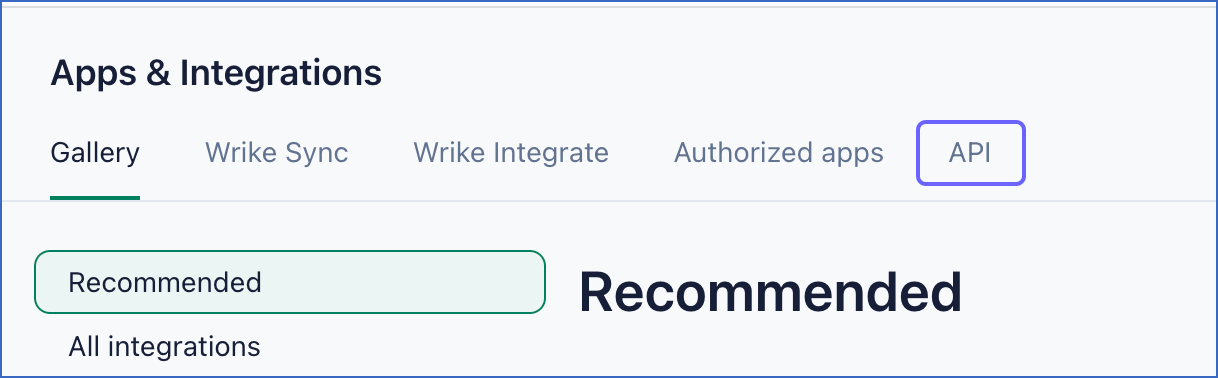
-
In the left navigation pane, click API.
-
In the API Apps page, specify an App name and click Create new. For example, HevoData in the image below.
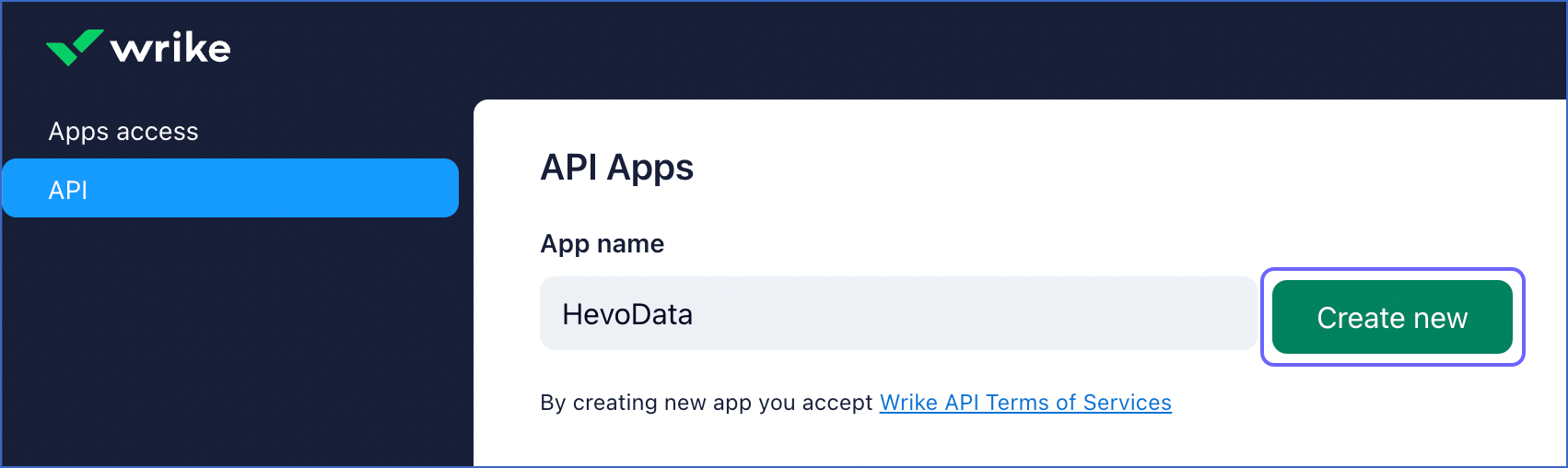
-
In the <App name> configuration page, Permanent access token section, click Create token.
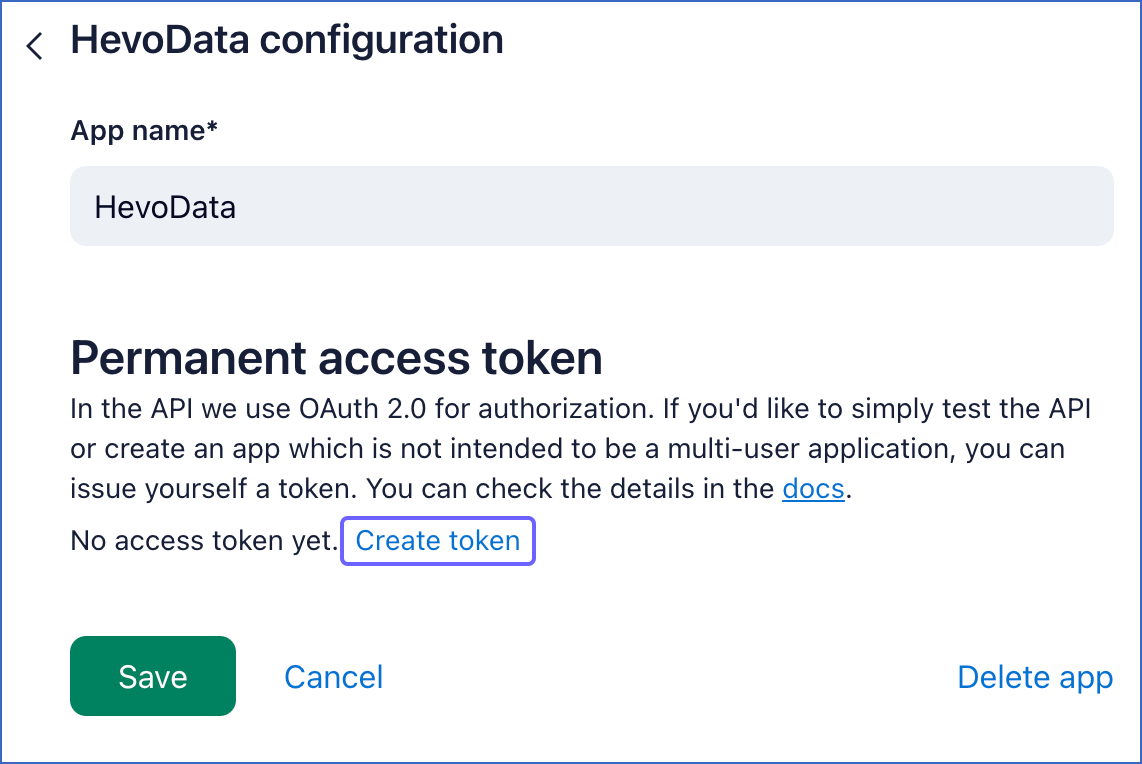
-
In the Permanent Access Token pop-up window, enter your Wrike password, and click Obtain token.
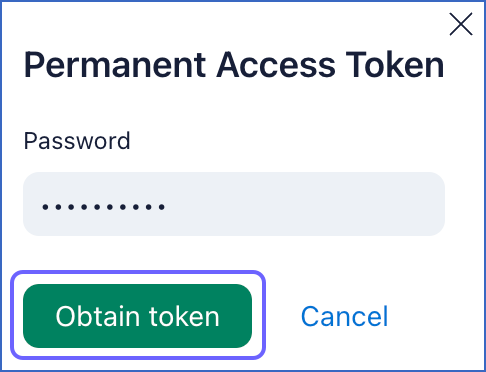
-
Click Copy token to copy your access token, and save it securely like any other password. Use this token while configuring your Hevo Pipeline.
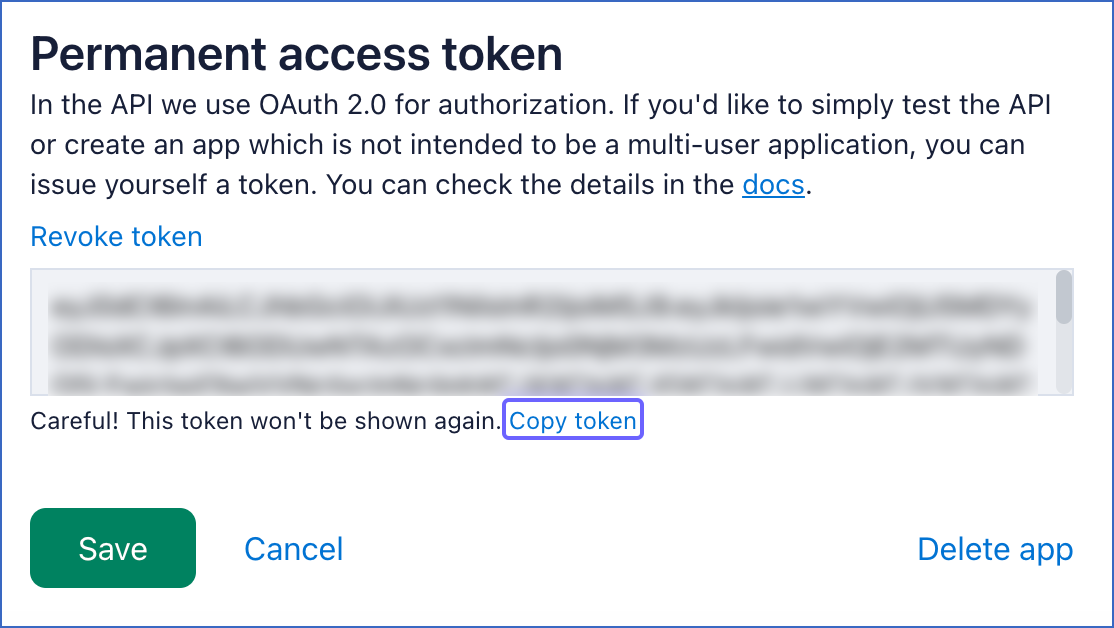
-
Click Save.
Configuring Wrike as a Source
Perform the following steps to configure Wrike as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Wrike.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Configure your Wrike Source page, specify the following:
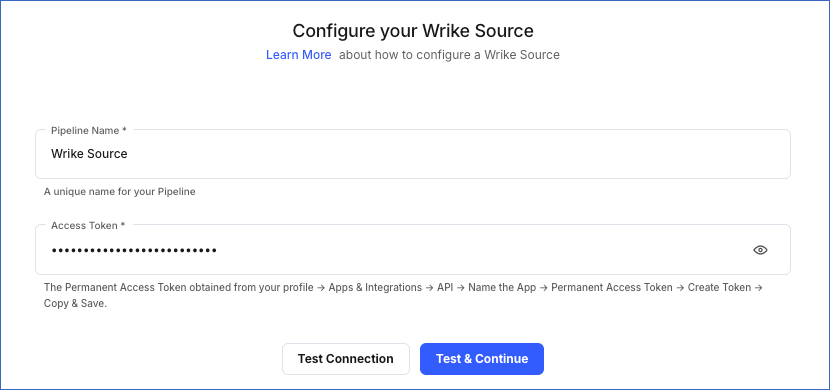
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Access Token: The access token that you obtained from your Wrike account.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 1 Hr | 1 Hr | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
Hevo ingests all the objects in Full Load mode in each run of the Pipeline.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination database. For a detailed view of the objects, fields, and relationships, click the ERD.
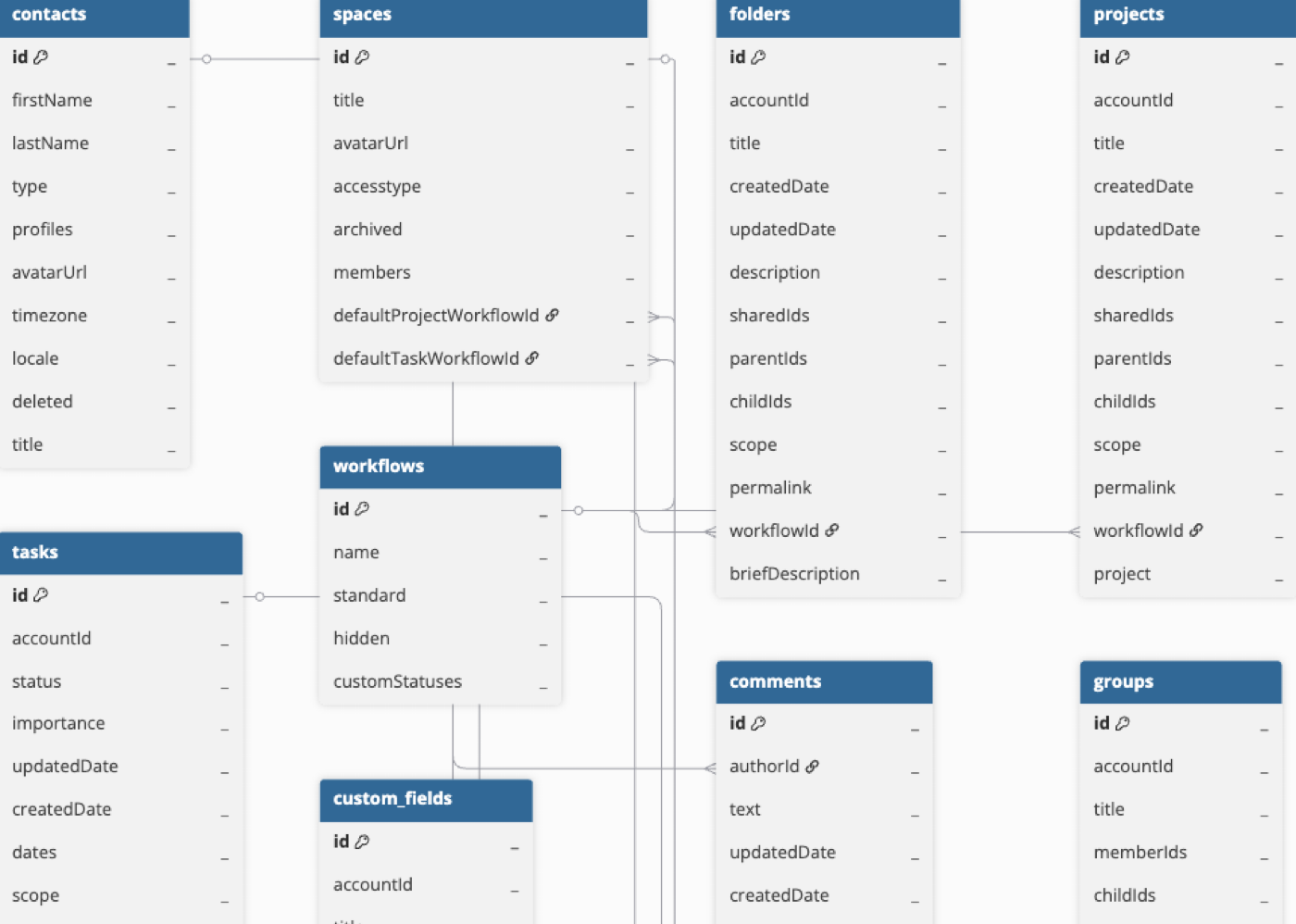
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
| Object | Description |
|---|---|
| Approvals | Contains details of the review process of the tasks assigned to users. |
| Blueprints | Contains details of the template for creating tasks, folders, and projects. |
| Comments | Contains details of the notes attached to tasks, folders, and projects, to add additional information. |
| Contacts | Contains details of the users associated with your Wrike account. |
| Custom Fields | Contains details of the customized fields created by the user to capture additional data. |
| Custom Item Types | Contains details of the customized tasks and projects created to cater to the specific needs of the team or organization. |
| Folders | Contains details of the containers used to organize tasks in your Wrike account. |
| Groups | Contains details of the user groups in your Wrike account. |
| Projects | Contains details of the entities used to organize, manage, and track status of tasks in Wrike. |
| Spaces | Contains the list of all the top-level groups created within the organization in Wrike to organize the teams and projects. For example, a Marketing space used by the marketing team to manage all their projects. |
| Tasks | Contains the list of different operations performed within projects in Wrike. |
| Timelogs | Contains details of the time entries added for tasks and subtasks in the projects, folders, or spaces. |
| Timelog Categories | Contains details of the categories in which users have added time entries to tasks, either manually or through the time tracker. |
| Workflows | Contains details of the standard and custom statuses created by the team admin to track the progress of tasks and projects through their lifecycle. |
| Work Schedules | Contains details of the working and non-working days for different teams in the organization. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
Pagination: An API call for each Wrike object fetches one page with up to 1000 records for Tasks and 100 records for other objects.
-
Rate Limit: Wrike imposes a limit of 100 API calls per minute per access token. If the limit is exceeded, Hevo defers the ingestion till the limits reset.
Limitations
-
Hevo currently does not support deletes. Therefore, any data deleted in the Source may continue to exist in the Destination.
-
You cannot specify a duration for loading the historical data. Hevo loads the entire data present in your Wrike account.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-12-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring Wrike as a Source as per the latest UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Oct-03-2023 | NA | Updated the section, Obtaining the Access Token as per the latest Wrike UI. |
| Jan-23-2023 | 2.06 | New document. |