Google BigQuery
On This Page
Google BigQuery is a fully-managed, server-less data warehouse that supports Structured Query Language (SQL) to derive meaningful insights from the data. Read BigQuery documentation for more information.
With Hevo Activate, you can configure Google BigQuery as a Warehouse to load data to your desired Target CRM application.
Organization of Data in BigQuery
Google BigQuery is hosted on Google’s Cloud Platform (GCP). GCP uses projects to organize resources. An organization can have multiple projects associated with it. Each project has a set of users, a set of APIs, and a billing account. Once you enable your BigQuery API, you can store your data in BigQuery tables. BigQuery organizes the data tables into units called datasets. These datasets are in turn stored in your GCP project.
Note: If your dataset’s location is other than US, the regional or multi-regional Cloud Storage bucket must be in the same region as the dataset. You can read more about this here.
To optimize the SQL queries you run on the BigQuery data warehouse, you can use partitioning or clustering the Source fields. To know when to use clustering over partitioning and vice versa, read this.
Permissions
To ingest data from your BigQuery account, Hevo needs the permissions to:
-
View and manage your data in Google BigQuery.
-
Manage your data in Google Cloud Storage (GCS).
These permissions must be assigned to the account you use to authenticate Hevo on BigQuery. Read Google Account Authentication Methods for more information.
Note: The files written to GCS are deleted after seven days to free up your storage.
User Authentication
You can connect to the BigQuery Warehouse via User accounts (OAuth) or Service accounts. One service account can be mapped to your entire team. Read Creating a Google service account to know how to set up a service account if you do not already have one.
Prerequisites
-
The authenticating user has BigQuery Admin and Storage Admin roles for the Google BigQuery project. These roles are irrespective of having Owner or Admin roles within the project. Read Google Account Authentication Methods for steps to configure these roles.
-
An active Billing account is associated with your BigQuery project.
Perform the following steps to configure your BigQuery data warehouse:
Assign User Permissions
Read Google Account Authentication Methods to assign the required roles and permissions to the account and allow Hevo to access data from it.
Add Billing Details to your Project
Read Enable billing for a project to set up the billing details for the project that you want to use while configuring Google BigQuery as a Warehouse in Hevo.
Configure Google BigQuery as a Data Warehouse
Note: Once the Warehouse is created, only certain settings can be modified. Refer to the section, Modifying BigQuery Warehouse Configuration.
To configure Google BigQuery as a Warehouse:
-
Do one of the following:
-
Click ACTIVATE in the Navigation Bar, and:
-
In the Activations tab, click + CREATE ACTIVATION.

-
On the Select Warehouse page, click + Add Warehouse.
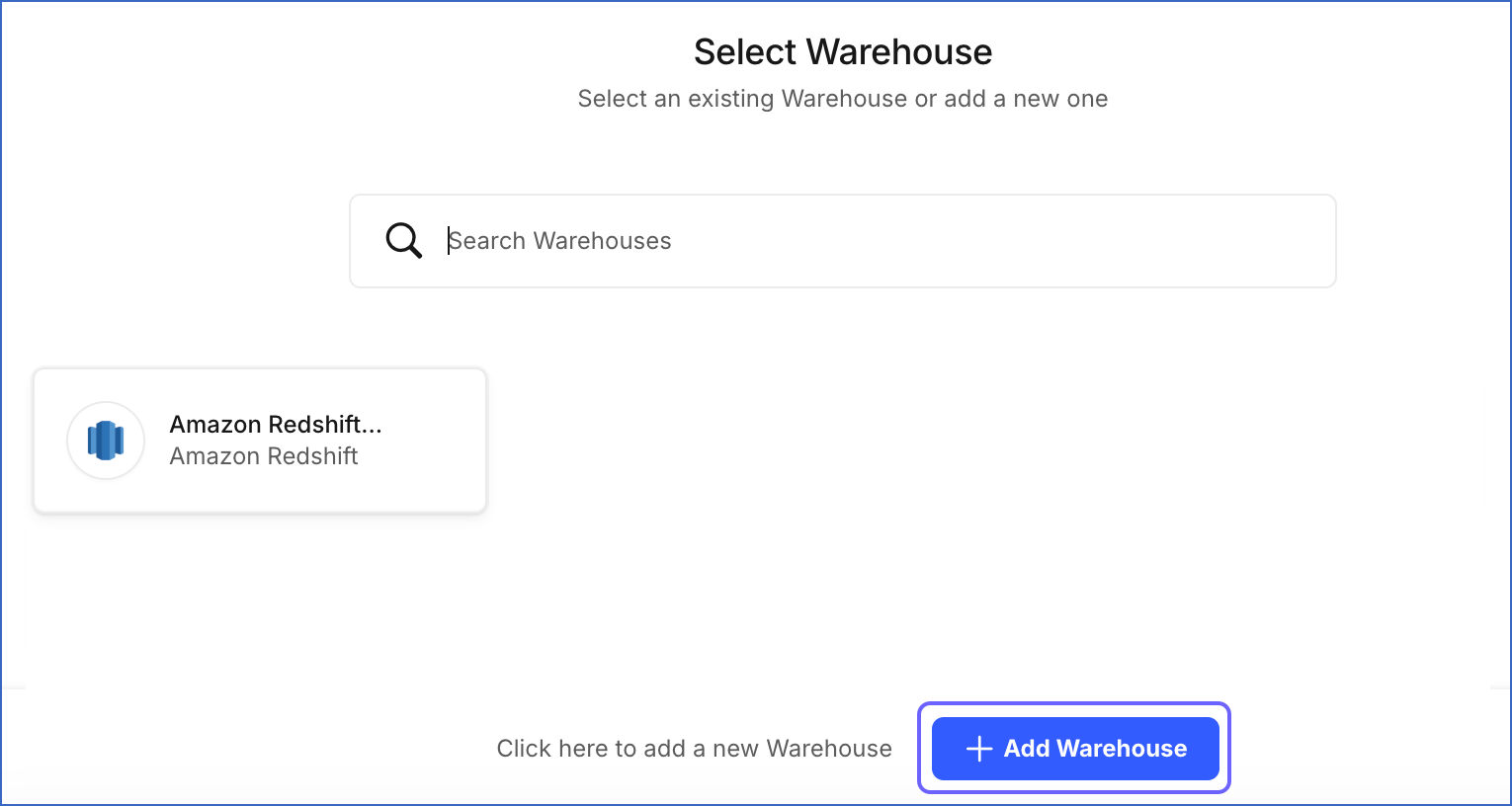
-
On the Select Warehouse Type page, select Google BigQuery.
-
-
Click DESTINATIONS in the Navigation Bar, and:
-
Click + CREATE DESTINATION in the Destinations List View.
-
On the Add Destination page, select Google BigQuery as the Destination type.
-
-
-
On the Configure your Google BigQuery Warehouse page, specify the following:

-
Warehouse Name: A unique name for your Warehouse.
-
Account: The type of account for authenticating and connecting to BigQuery.
Note: You can switch between account types after the Warehouse is created.
-
To connect with a user account, select User Account from the drop-down, click + ADD ACCOUNT, sign in to your account, and click Allow to authorize Hevo to access your data.
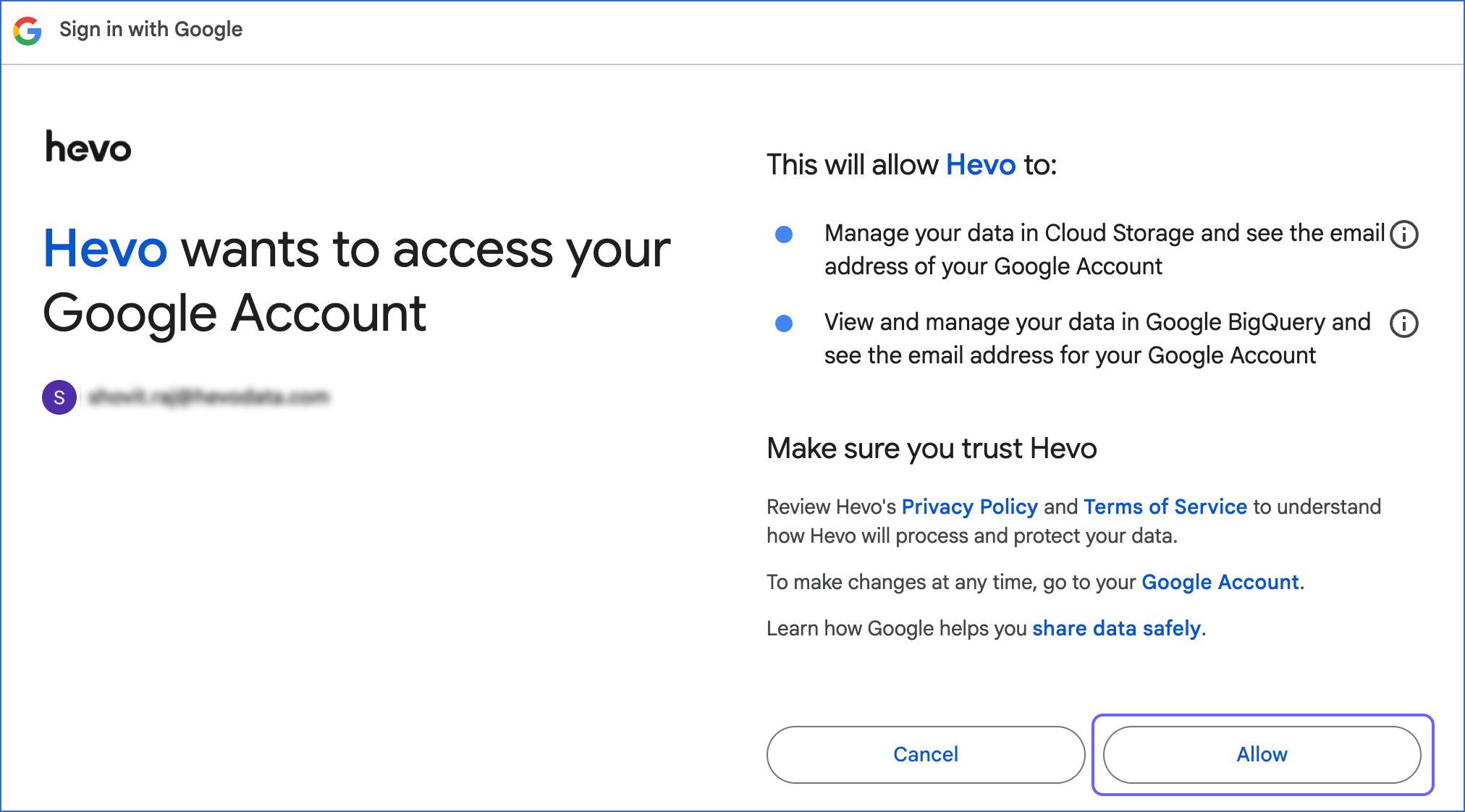
-
To connect with a service account, select Service Account from the drop-down, click
 ADD ACCOUNT, and upload the Service Account Key JSON file that you created in GCP.
ADD ACCOUNT, and upload the Service Account Key JSON file that you created in GCP.
-
-
Project: The project containing the dataset from which you want to synchronize data.
-
Dataset: The dataset from which you want to synchronize your data.
-
GCS Bucket: The cloud storage bucket where files are staged before synchronizing them with the Target objects.
-
Advanced Settings: These settings are not applicable for configuring Google BigQuery as an Activate Warehouse.
-
-
Click TEST CONNECTION to test connectivity with the Google BigQuery data warehouse.
-
Once the test is successful, click SAVE & CONTINUE.
Any user with BigQuery admin and Storage admin permissions on the configured data warehouse can modify, create, and run Activations.
Such a user will have access to the hevo dataset maintained by Activate for Bookkeeping.
Modifying BigQuery Data Warehouse Configuration
You can modify some of the settings post-creation of the BigQuery data warehouse. However, changing any configuration would affect all the Activations and Pipelines that are using this data warehouse. Refer to the Potential Impacts of Modifying the Configuration Settings section to know the impacts of making these changes.
Perform the following steps to modify the BigQuery Data Warehouse configuration:
-
In the detailed view of your Destination, do one of the following:
-
Click the Settings (
 ) icon next to the Destination name, and then click the Edit icon.
) icon next to the Destination name, and then click the Edit icon.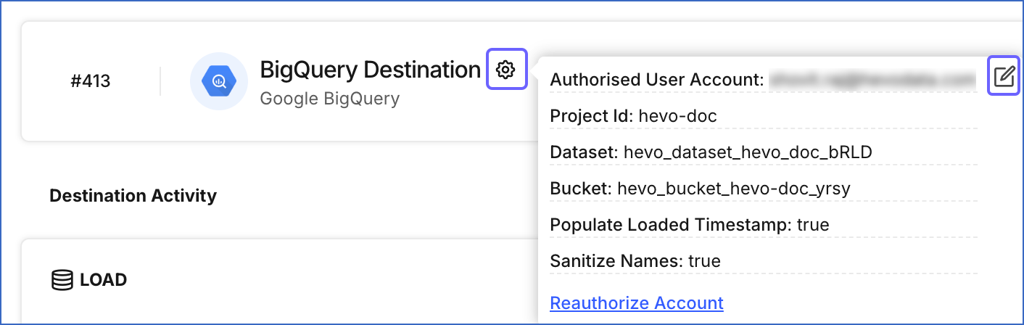
-
Click the More (
 ) icon to access the Destination actions menu, and then click Edit.
) icon to access the Destination actions menu, and then click Edit.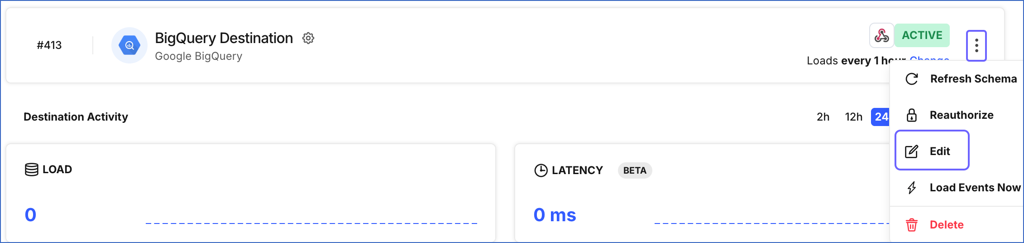
-
-
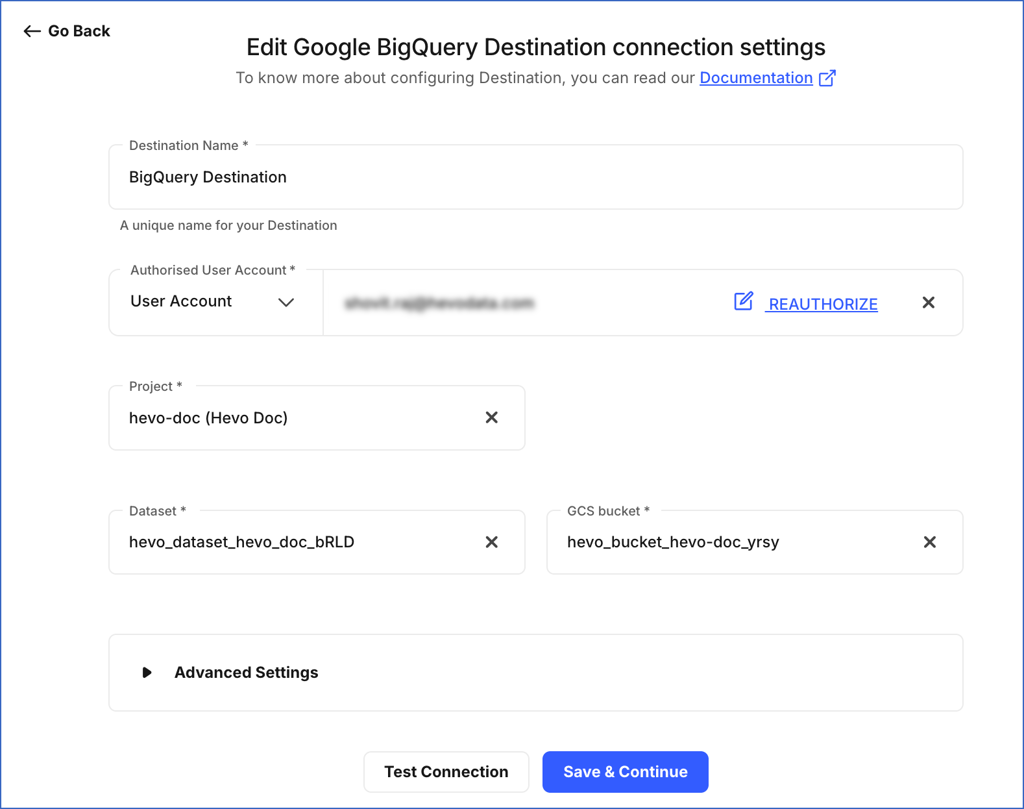
On the Edit Google BigQuery Destination connection settings page, you can modify the following settings:
-
Destination Name: Specify a new name for your Destination, not exceeding 255 characters.
-
Authorised User/Service Account: Select the account type from the drop-down to authenticate and connect to BigQuery.
-
To connect with a service account, click EDIT and attach the service account key JSON file.
-
To connect with a user account, do the following:
-
Click + ADD ACCOUNT.
-
Sign in to your account, and click Allow to authorize Hevo to access your data.
-
-
-
Project: Select the project ID for your BigQuery instance from the drop-down.
-
Dataset: Select the dataset from the drop-down.
-
GCS bucket: Select the GCS bucket from the drop-down.
-
Advanced Settings: These settings are not applicable for configuring Google BigQuery as an Activate Warehouse.
-
-
Click Test Connection to check the connection to your Google BigQuery Destination. Once the connection is successful, click Save & Continue to save the modified configuration.
Potential Impacts of Modifying the Configuration Settings
-
Changing any configuration setting impacts all Activations using the Warehouse.
-
Changing the Project ID or Dataset ID may lead to data getting split between the old and the new Dataset. This is because the data in the old Dataset is not copied to the new one. Further, new tables for all the existing Activations that are using this data warehouse are created in the new Dataset.
-
Changing the Bucket ID may lead to data getting lost. The data not yet copied from the old bucket is not copied to the Dataset.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Jun-09-2026 | NA | Updated sections, Configure Google BigQuery as a Data Warehouse and Modifying BigQuery Data Warehouse Configuration to add information about switching the account type when editing a Warehouse. |
| Aug-26-2024 | NA | Updated section Configure Google BigQuery as a Data Warehouse to reflect the latest UI. |
| Apr-25-2023 | NA | Updated the information in the page to reflect the latest Hevo UI. |
| May-10-2022 | 1.88 | Added information about support for service accounts in the Configure Google BigQuery as a Data Warehouse section. |
| Sep-09-2021 | 1.71 | Added a note at end of the section, Configure Google BigQuery as a Data Warehouse about permissions required for executing and modifying Activations. |
| Jul-12-2021 | 1.67 | New document. |