Release Version 2.22
On This Page
The content on this site may have changed or moved since you last viewed it. As a result, some of your bookmarks may become obsolete. Therefore, we recommend accessing the latest content via the Hevo Docs website.
This release note also includes the fixes provided in all the minor releases since 2.21.
To know the complete list of features available for early adoption before these are made generally available to all customers, read our Early Access page.
In this Release
Upcoming Breaking Changes
Sources
-
Migration to API Version v2024-02-15 for Klaviyo Source

-
Effective June 30, 2024, Klaviyo’s legacy APIs v1-2 are scheduled to sunset. We will soon be upgrading to the newer API Version v2024-02-15, which contains new and improved capabilities. This enhancement will also include changes in the schema that may impact Pipelines created with this Source.
Please stay tuned for further communication about the enhancement and its release date.
-
New and Changed Features
User Assistance
-
Connecting through AWS VPC Peering
-
Enhanced the product documentation to include information about connecting through AWS VPC peering. Further, new content has been created to help you set up VPC peering and seamlessly allow Hevo to connect to your Source or Destination database hosted within an AWS VPC.
Read Connection Options and Connecting Through AWS VPC Peering.
-
Fixes and Improvements
Refer to this section for the list of fixes and improvements implemented from Release 2.21.1 to 2.22.
Destinations
-
Improved Handling of Epoch Timestamp Values in Google BigQuery
- Fixed an issue whereby Hevo was not able to ingest epoch timestamp values with microsecond precision, leading to data mismatch issues.
-
Optimizing Schema Refresh Costs in Snowflake Destinations
- Fixed an issue whereby the query to fetch the primary keys for a table retrieved the primary keys for the entire database. This issue occurred when the schema name was either null or contained unescaped wildcard characters such as underscores or percentage signs. For example, hevo_schema or hevo%schema. For such schema names, Snowflake’s default behavior is to fetch the primary keys for the entire database. Now, Hevo escapes the wildcard characters in the schema name before running the query.
Sources
-
Handling a Data Type Issue for Apple Search Ads
-
Fixed an issue in the Apple Search Ads connector whereby Pipeline creation failed when the Campaign object was selected. The issue was seen when the value in the
adamIdfield, which was mapped to an integer data type, exceeded the allowed range. Now, Hevo maps theadamIdfield to a suitable data type (long).This fix applies to new and existing Pipelines. If Auto Mapping is turned off in your existing Pipeline, then any Event ingested from the Campaign object is sidelined. To resolve this, you can change the data type of the
adamIdfield to long and restart the object.
-
-
Handling of Data Ingestion Issues in Salesforce Bulk API V2
-
Fixed an issue whereby Hevo was not able to ingest data for Jobs that were started, paused, and then restarted later. Hevo relies on unique Job IDs, and reusing the IDs during restarts led to conflicts, resulting in job failures.
This fix ensures data ingestion resumes seamlessly when jobs are restarted.
-
-
Resolving Data Ingestion Issues in Shopify
-
Fixed the following issues in the Shopify connector that were causing the Pipeline to not ingest data from the Customer Journey Summary and Customer Visit objects:
-
The date or timestamp till when the data is to be fetched (toDate) was being incorrectly set. To fix this issue, the incremental load task query now uses a toDate that is 24 hours later than the fromDate, which is the starting date or timestamp. The fromDate is set to the last modified timestamp of a successfully ingested record.
-
The ingestion query timed out while fetching high volumes of data over a larger window size. The window size or range is the time difference between the fromDate and toDate. Now, if the query times out, it is re-run over a reduced range.
-
Hevo was unable to fetch data correctly from paused Pipelines or if data ingestion was deferred for a long period. This was because the offset maintained by Hevo to get the next page of data became invalid. Hevo records the nextPageToken received from Shopify as the offset. Post the fix, if the offset becomes invalid, Hevo requests a new token from Shopify by resetting the nextPageToken to the default value of NULL.
These fixes apply to new and existing Pipelines.
-
-
User Experience
-
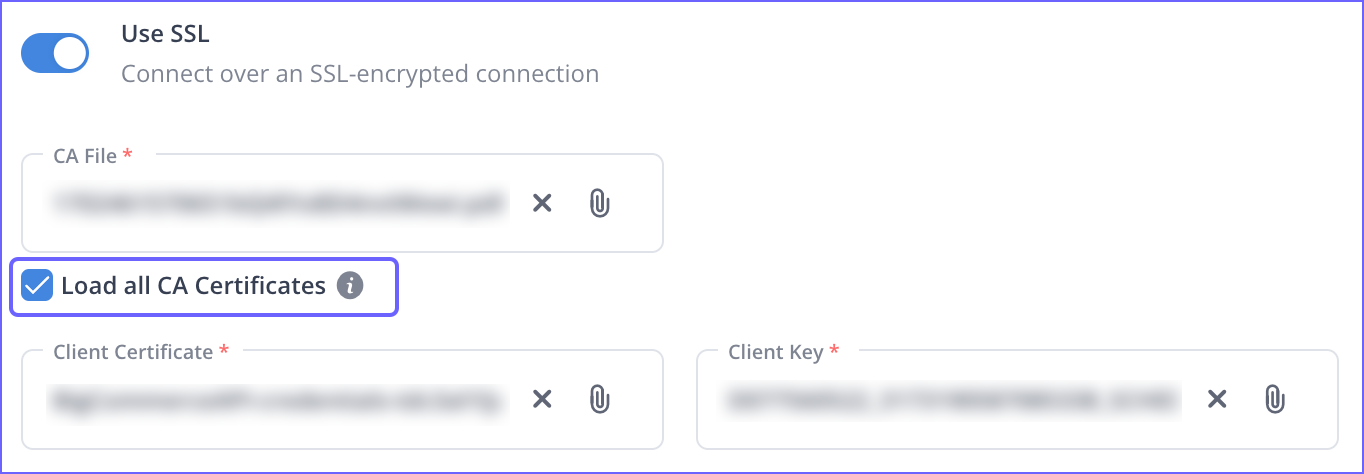
Loading all CA Certificates for SSL-Enabled Sources and Destinations
-
Provided an option to load all certificates (up to 50) from the CA file that you uploaded during Pipeline creation. Hevo automatically selects the required certificate from the uploaded CA file to verify the SSL connection. Previously, only the first certificate in the CA file was loaded, leading to authentication failures if the loaded certificate was incorrect.
This feature is available for new and existing Pipelines for which SSL is enabled.
-
Documentation Updates
The following pages have been created, enhanced, or removed in Release 2.22:
Destinations
Getting Started
Transform
-
Troubleshooting Models