On This Page
NetSuite SuiteAnalytics is a powerful business intelligence and analytics toolset available within the NetSuite. It is designed to provide users with real-time access to their data and help them make informed business decisions based on insights gathered from that data. SuiteAnalytics includes a variety of features and tools, such as customizable dashboards, reporting and analysis tools, and data exploration capabilities. It allows you to create and view reports, analyze data using a range of metrics, and share insights with others.
Hevo uses the SuiteAnalytics Connect Service to replicate your SuiteAnalytics data and load it to the desired Destination for scalable analysis.
Prerequisites
-
An active Netsuite account from which data is to be ingested exists.
-
You are logged in as an Admin user to create a role and user for Hevo, and obtain the API credentials.
-
The SuiteAnalytics Connect Service is enabled with access to the Netsuite2.com data source.
Obtaining the API Credentials
Hevo uses the Service Host and Port, and Account ID to establish a connection with the SuiteAnalytics Connect service, which enables Hevo to ingest data from NetSuite. To authenticate Hevo on your NetSuite account, various credentials are required, including the Consumer Key and Secret, the Data Warehouse Integrator Role ID, and the Token ID and Secret.
Note: You must log in as an Admin user to perform these steps.
To obtain these credentials, perform the following steps:
1. Obtain your Service Host, Port, and Account ID
Perform the following steps to obtain your SuiteAnalytics Connect credentials:
-
Log in to your NetSuite account.
-
On the NetSuite home page, in the Settings section, click Set Up SuiteAnalytics Connect.
-
On the SuiteAnalytics Connect Driver Download page, from the Your Configuration section, copy the SERVICE HOST, SERVICE PORT, and ACCOUNT ID, and save them securely like any other password.
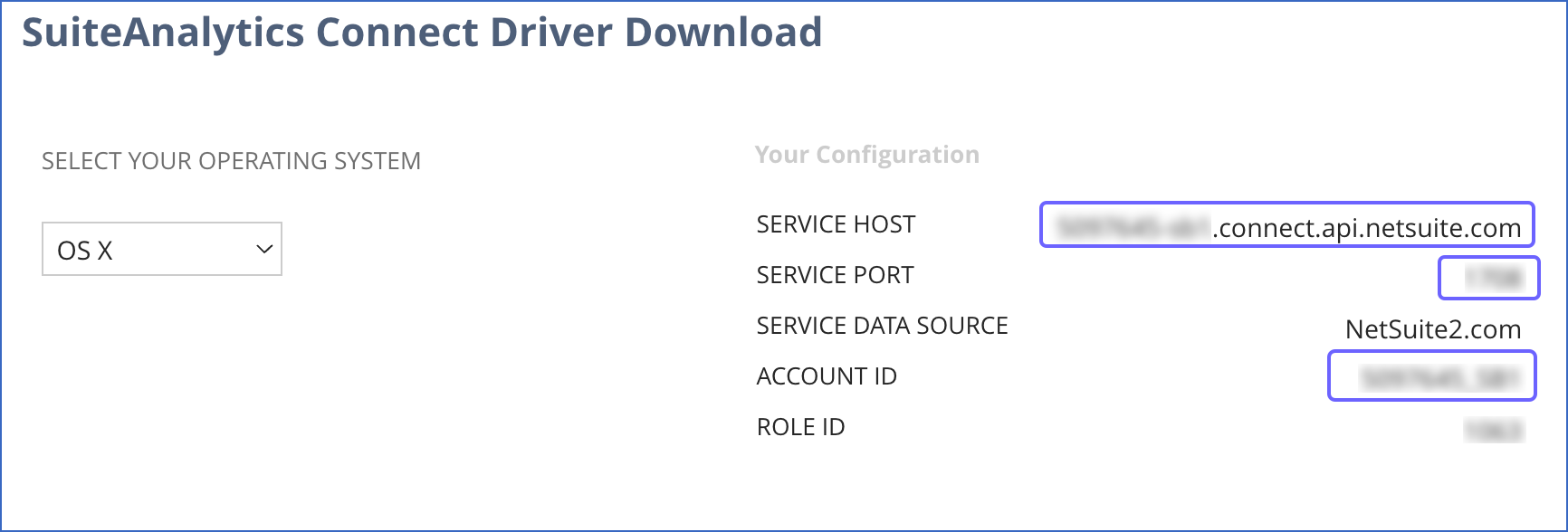
You can use these credentials while configuring your Hevo Pipeline.
2. Enable web services and token-based authentication
Perform the following steps to generate the access token to authenticate Hevo:
-
Log in to your NetSuite account as an Administrator user.
-
In the NetSuite global search bar, enter page: enable, and select the Page: Enable Features result.

-
On the Enable Features page, click SuiteCloud.
-
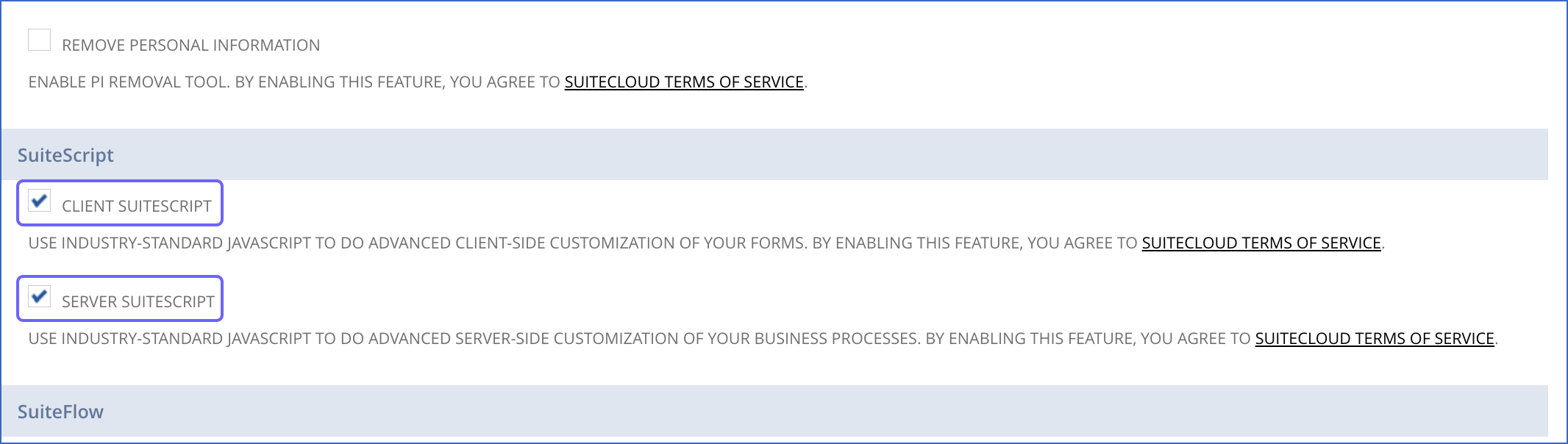
In the SuiteCloud tab, SuiteScript section, select the CLIENT SUITESCRIPT check box, and click I Agree in the pop-up dialog displayed.
-
Select the SERVER SUITESCRIPT check box, and click I Agree in the pop-up dialog displayed.
-
In the Manage Authentication section, select the TOKEN-BASED AUTHENTICATION check box, and click I Agree in the pop-up dialog displayed.
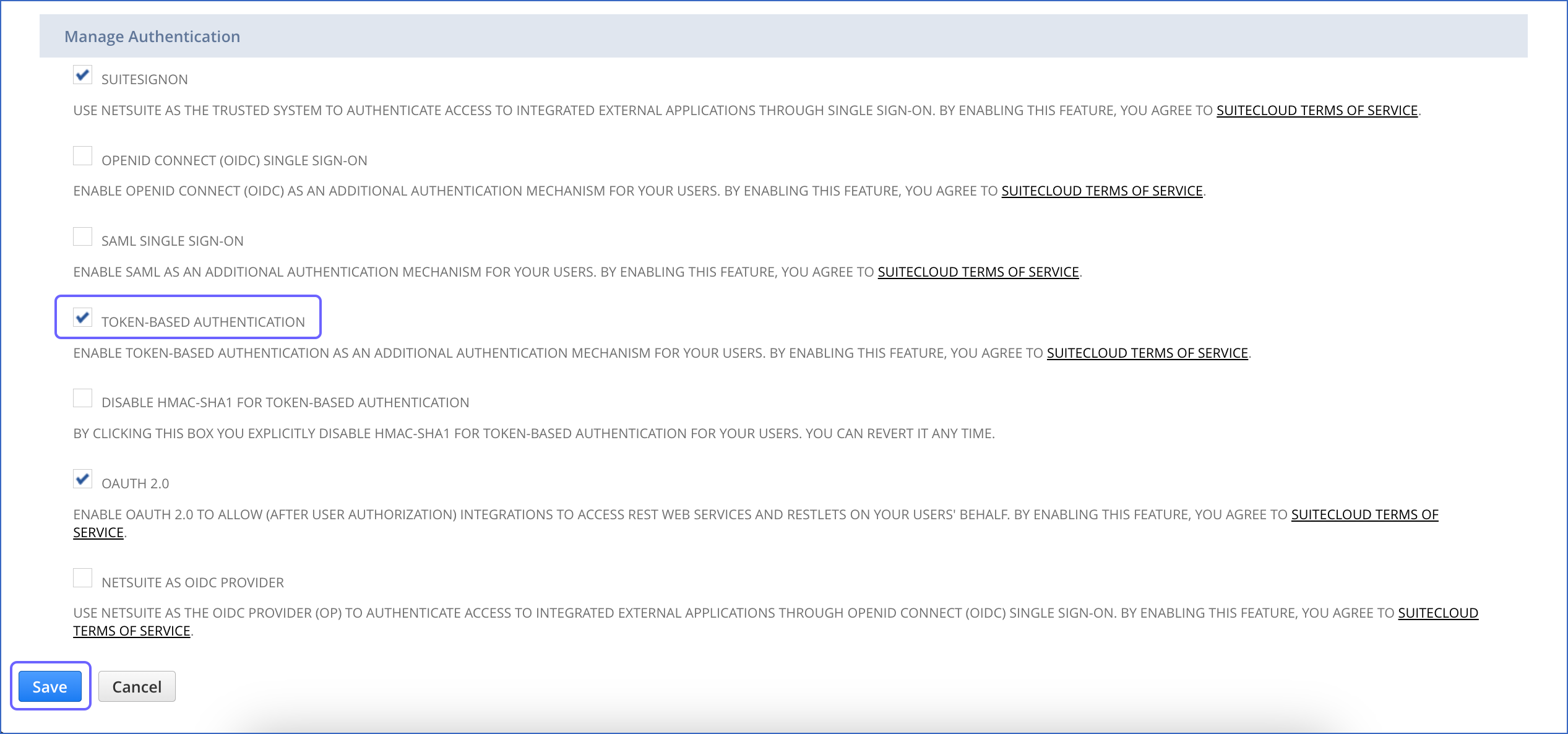
-
At the bottom of the page, click Save.
3. Create an integration record for Hevo
An integration record is required to uniquely identify Hevo in your NetSuite account.
-
In the NetSuite global search bar, enter page: integrations, and click the Page: Manage Integrations result.

-
On the Integrations page, click New.

-
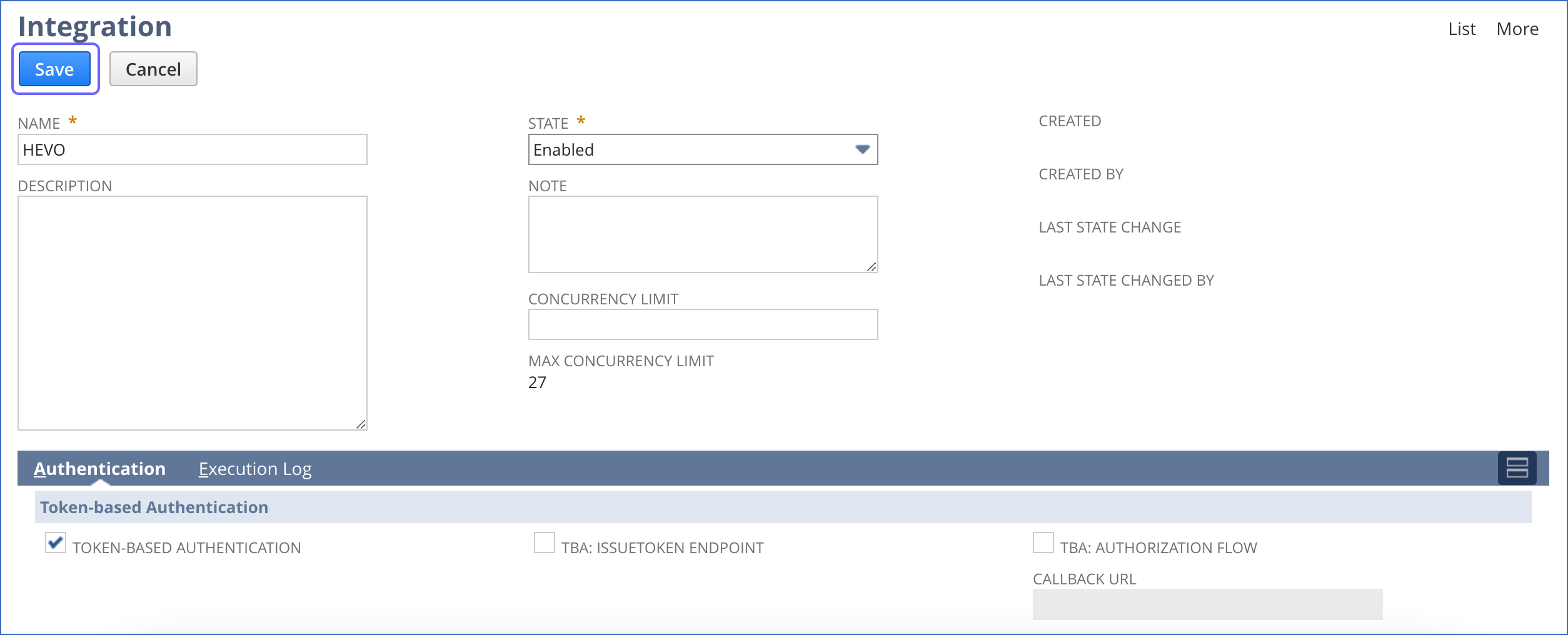
On the Integration page, specify the following settings:
-
Name: A unique name for the integration. For example, HEVO.
-
Token-based Authentication: Select this check box to allow Hevo to access your data.
-
-
Click Save.
-
In the confirmation page that is displayed, from the Consumer key/secret section, copy the consumer key and secret and save them securely like any other password.
You can use these credentials while configuring your Hevo Pipeline.
4. Create a role for Hevo and configure permissions
We recommend that you create a Hevo-specific role and user so that it is easier to assign and manage the permissions required for Hevo to replicate your data.
To do this, perform the following steps:
-
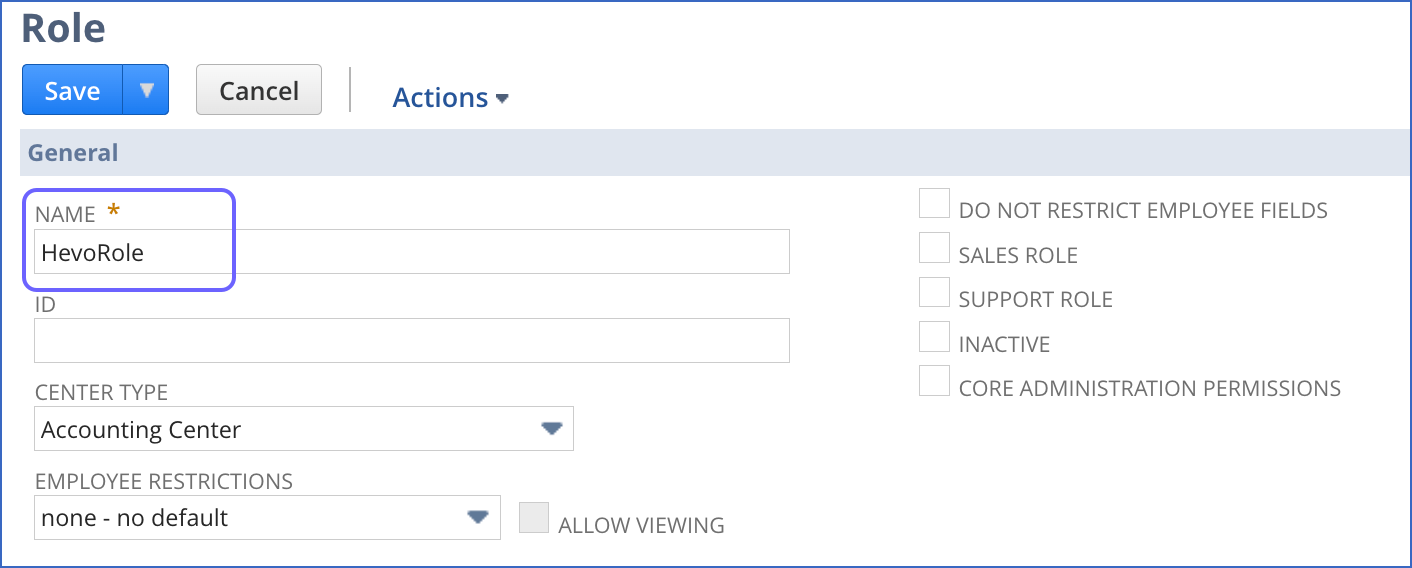
In the NetSuite global search bar, enter Page: New role, and select the Page: New Role result.

-
On the Role page, specify a name for the role in the Name field. For example, HevoRole.
-
In the Permissions tab, click Setup, and do the following:
-
From the drop-down, select Log in using Access Tokens, and click Add.
-
From the drop-down, select SuiteAnalytics Connect, and click Add.
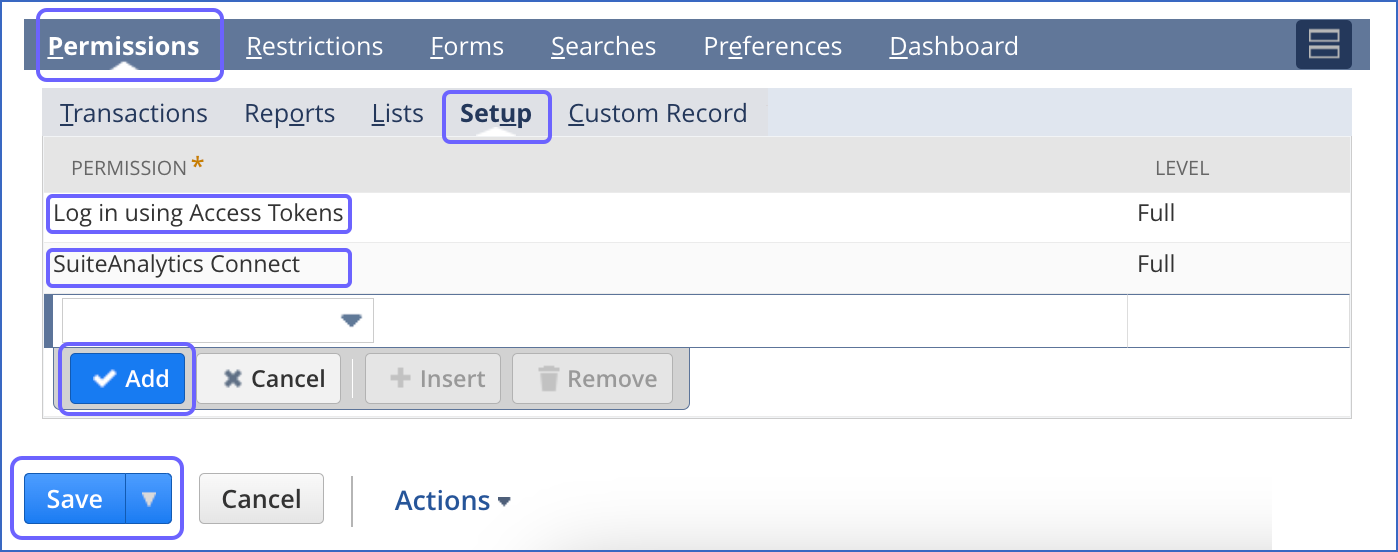
Repeat this step to add permissions according to the data you need to replicate.
-
-
After permissions for all tabs are added, click Save.
5. Create a Hevo user
-
In the NetSuite global search bar, enter Page: New Employees, and select the Page: New Employees result.

-
On the Employee page, specify the NAME, EMAIL, and SUBSIDIARY.
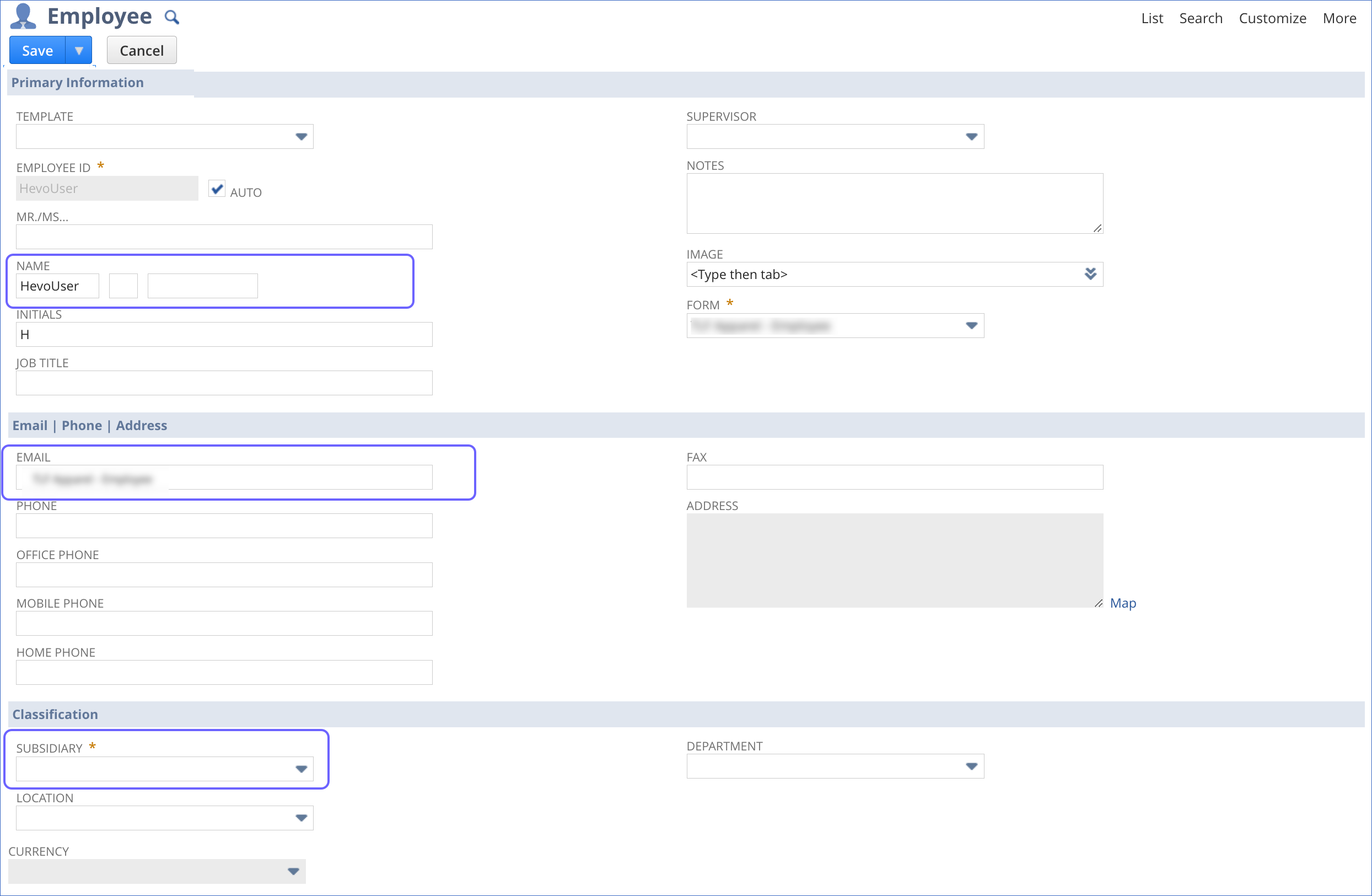
-
Scroll down and select the Access tab.
-
In the Access tab, do the following:
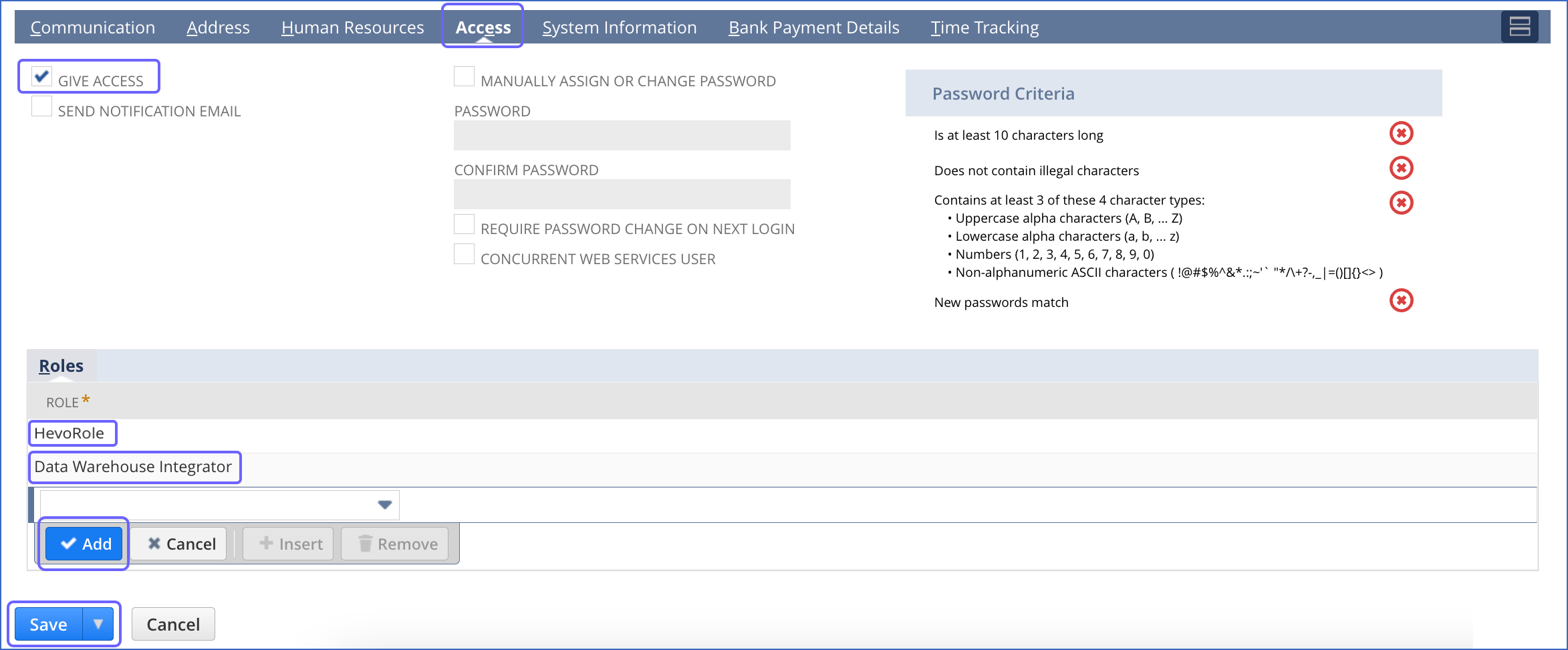
-
Select the GIVE ACCESS check box.
-
In the Roles section, from the ROLE drop-down, select:
-
The Hevo role that you created in Step 4 above. For example, HevoRole.
-
The system Data Warehouse Integrator role.
-
-
Click Add.
-
-
Click Save.
You have successfully created a user for Hevo.
6. Create an access token
Perform the following steps to create an access token for Hevo:
-
In the NetSuite global search bar, enter Page: Access Tokens, and click the Page: Access Tokens result.

-
On the Access Tokens page, click New Access Token.
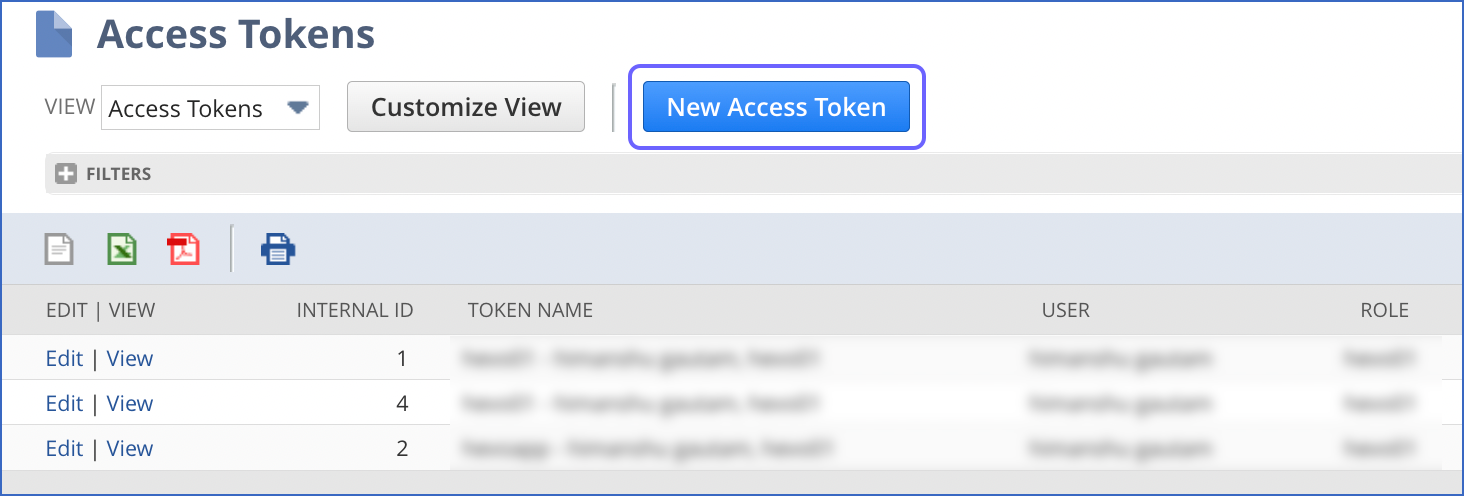
-
On the Access Token page, specify the following details:
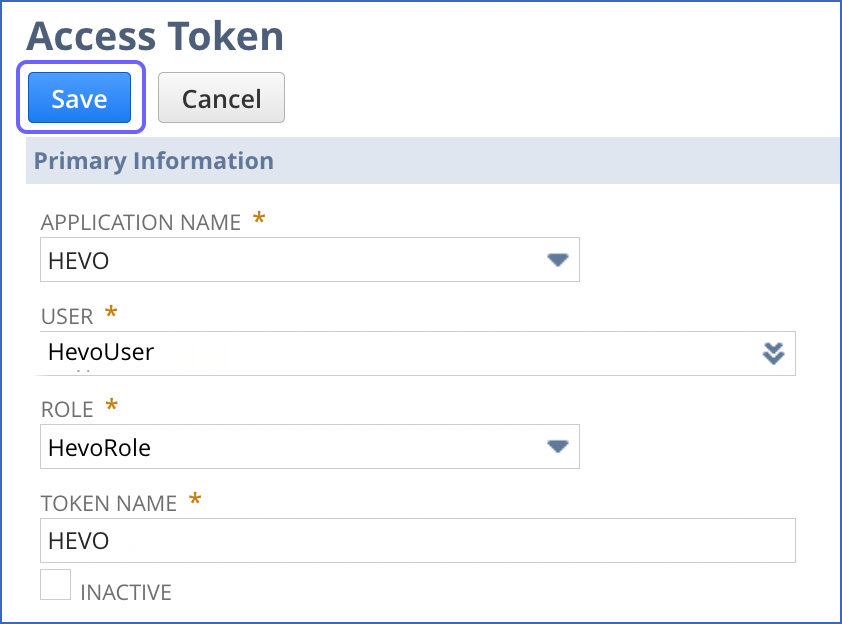
-
APPLICATION NAME: The integration record that you created in Step 3.
-
USER: The Hevo user that you created in Step 5. For example, HevoUser.
-
ROLE: The Hevo role that you created in Step 4. For example, HevoRole.
-
TOKEN NAME: A name for the token. NetSuite creates a name by default, however, you can specify a custom name. For example, HEVO.
-
-
Click Save.
-
From the confirmation page that is displayed, copy the Token ID and Secret and save them securely like any other password.
You can use these credentials while configuring your Hevo Pipeline.
7. Obtain the data warehouse integrator role ID
-
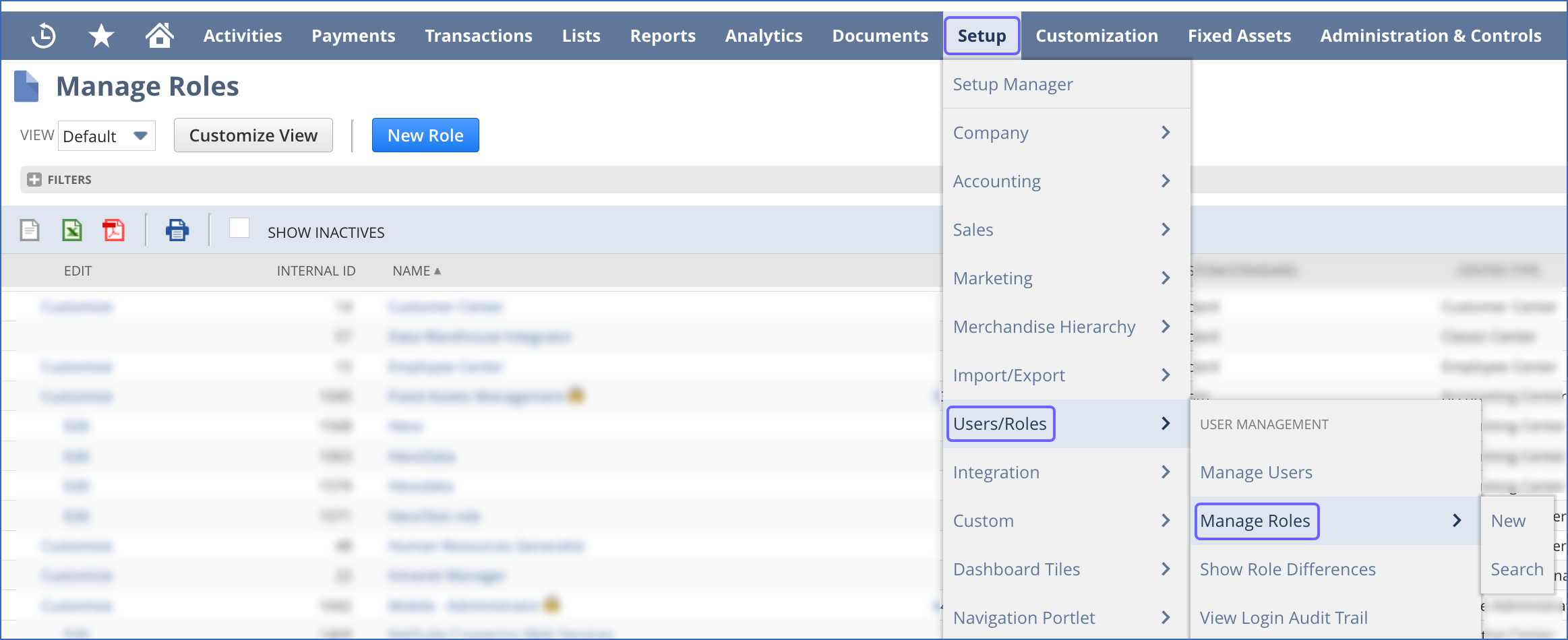
In the navigation bar at the top of the NetSuite dashboard, click Setup, Users/Roles, and Manage Roles.
-
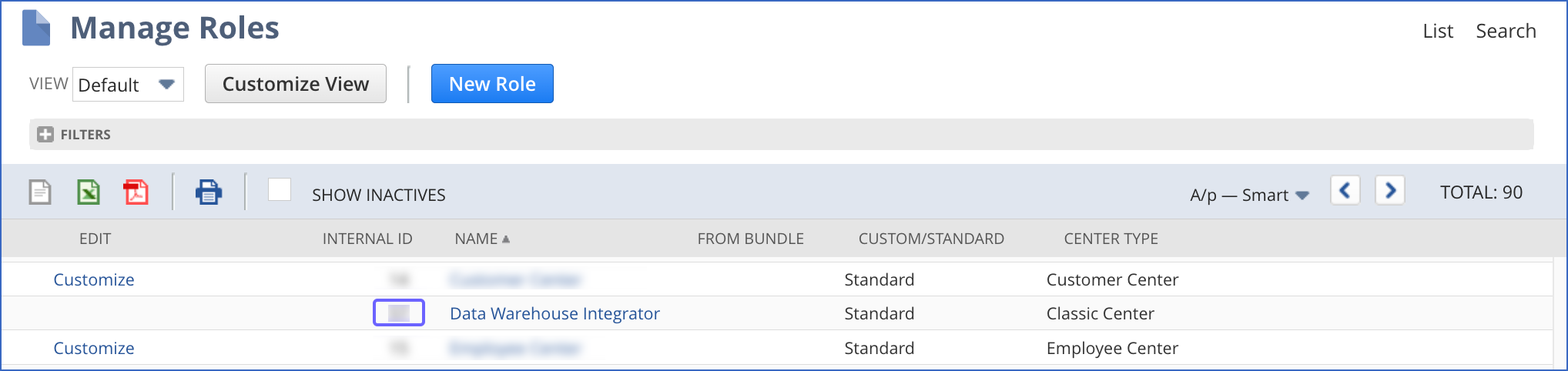
On the Manage Roles page, copy the INTERNAL ID of the Data Warehouse Integrator role in the role list, and save it securely like any other password. Use this ID while configuring your Hevo Pipeline.
Configuring NetSuite SuiteAnalytics as a Source
Perform the following steps to configure NetSuite SuiteAnalytics as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select NetSuite SuiteAnalytics.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
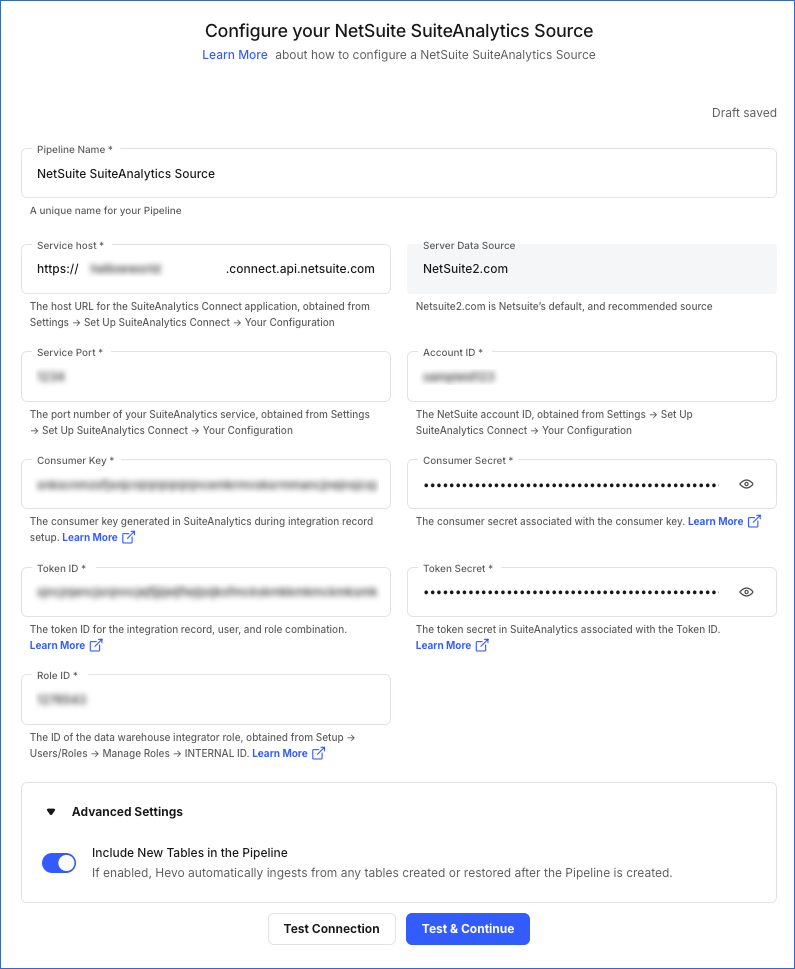
On the Configure your NetSuite SuiteAnalytics Source page, specify the following:
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Service Host: The host URL that you obtained in Step 1 above. For example, in https://12345678-sb1.connect.api.netsuite.com, the service host is 12345678-sb1.
-
Server Data Source (Non-editable): The data source that Hevo uses to obtain data from your NetSuite account.
-
Service Port: The port number that you obtained in Step 1 above.
-
Account ID: The unique ID that you obtained in Step 1 above.
-
Consumer Key: The key that you obtained upon creating the integration record for Hevo.
-
Consumer Secret: The consumer secret that you obtained from your Netsuite account upon creating the integration record for Hevo.
-
Token ID: The ID of the access token that you created in Step 6 above, to allow Hevo to access your data.
-
Token Secret: The secret for the token that you created in Step 6 above.
-
Role ID: The data warehouse integrator role ID that you obtained from Step 7 above.
-
Advanced Settings:
-
Include New Tables in the Pipeline:
If enabled, Hevo automatically ingests data from objects created in the Source post-Pipeline creation.
If disabled, Hevo does not ingest data from new objects. They are added in the SKIPPED state to the Objects list on the Pipeline Overview page. You can update their status to INCLUDED to ingest data.
You can change this setting later.
Note:
-
When a new object is included in the Pipeline for ingestion and the RUN NOW action is triggered for that object, Hevo fetches only the incremental data for it. The historical load begins in the next Pipeline run.
-
If a previously deleted object marked as ACTIVE in the Pipeline is re-created in the Source, Hevo adds it in the SKIPPED state. This applies irrespective of whether the Include New Tables in the Pipeline setting is enabled or disabled. You must manually change its state to INCLUDED to resume ingestion.
-
-
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 3 Hrs | 5 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests all the existing data for the selected objects from your NetSuite SuiteAnalytics account and loads it to the Destination.
-
Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency in Full Load or Incremental mode, as applicable.
Custom frequency for Full Load objects
Hevo allows you to set the ingestion frequency for Full Load objects separately from the Pipeline ingestion frequency. You can reduce your Events quota consumption by ingesting Full Load objects at a lower frequency without affecting other objects in the Pipeline. Read Query Modes and Events Quota Consumption to know how different query modes affect your Events quota consumption.
You can identify the Full Load objects in the Pipelines Detailed View by the FL tag corresponding to their name. Alternatively, you can view only Full Load objects in your Pipeline by selecting Full Load from the Filter ( ![]() ) menu.
) menu.

Perform the following steps to set a custom ingestion frequency for Full Load objects:
-
In the Pipelines Detailed View, click the More (
 ) icon to open the Pipeline’s Action menu and click Change Schedule.
) icon to open the Pipeline’s Action menu and click Change Schedule.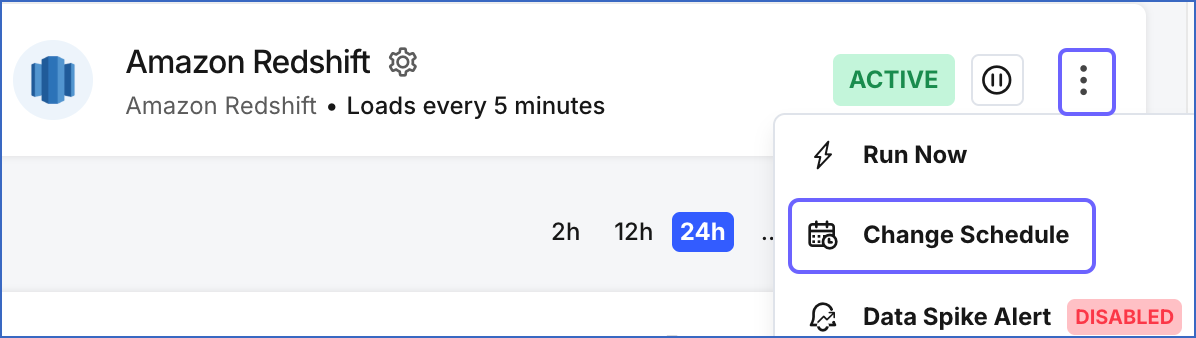
-
In the Change the Pipeline Ingestion Schedule pop-up window, enable the Enable Full Load Object Ingestion Schedule option.

Note:
- For custom frequency, this option is available only when Run at fixed interval is selected.
- If your Pipeline ingests data from Full Load objects on an independent schedule, manual actions such as Run Now and Restart Object are automatically deferred to the next ingestion schedule. To run any of these actions immediately, turn off the Full Load Object Ingestion Schedule option, trigger the required action, and then re-enable the schedule.
-
Select the ingestion frequency for the Full Load objects as per your requirements. You can select Custom and define the ingestion frequency by specifying an integer value in hours.
Note: Full Load objects can be ingested at a frequency more than or equal to the Pipeline’s ingestion frequency.

-
Click Schedule.
The updated schedule is applied immediately.
Data Model
Hevo allows you to ingest most objects from the Analytics Browser of SuiteAnalytics. Read Analytics Browser to view the list of objects available for ingestion.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
- NetSuite SuiteAnalytics limits the number of concurrent API requests that can be made to an account. This limit is based on the service tier and the number of SuiteCloud Plus licenses associated with the account. If the limit is exceeded, Hevo is temporarily unable to fetch data from that account. In such cases, Hevo retries the API request up to 10 times. If all retry attempts fail, data ingestion is deferred to the next Pipeline run.
Limitations
-
Hevo does not capture records permanently deleted from NetSuite SuiteAnalytics. However, it does allow ingesting data from the Deleted Record object that NetSuite uses for deletion tracking.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-11-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring NetSuite SuiteAnalytics as a Source as per the latest UI. |
| Jul-31-2025 | NA | Added the Source Considerations section. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| May-23-2025 | NA | Added a note in the Configuring NetSuite SuiteAnalytics as a Source section about the Include New Tables in the Pipeline Advanced Settings. |
| May-22-2025 | NA | Updated section, Custom frequency for Full Load objects to add a note about the behavior of manual ingestion actions. |
| May-13-2025 | NA | - Updated the limitation about Hevo capturing deletes using NetSuite’s Deleted Record object. - Moved the note about backward re-ingestion window to Change Data Capture query mode. |
| Apr-28-2025 | NA | - Added section, Custom frequency for Full Load objects to inform users about the option to change ingestion frequency for Full Load objects. - Updated section, Data Replication to add a note about the backward re-ingestion window. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Jun-14-2023 | NA | Updated section, Data Replication to add information about Hevo ingesting all available historical data. |
| Apr-10-2023 | 2.11 | New document. |