Mailchimp
On This Page
Hevo can replicate your Mailchimp data to your data warehouse using Mailchimp’s API.
Prerequisites
- You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Configuring Mailchimp as a Source
Perform the following steps to configure Mailchimp as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Mailchimp.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Configure your Mailchimp account page, do one of the following:
-
Select a previously configured account and click Continue.
-
Click + Add Mailchimp Account and give Hevo access to your account by entering your Mailchimp credentials.
-
-
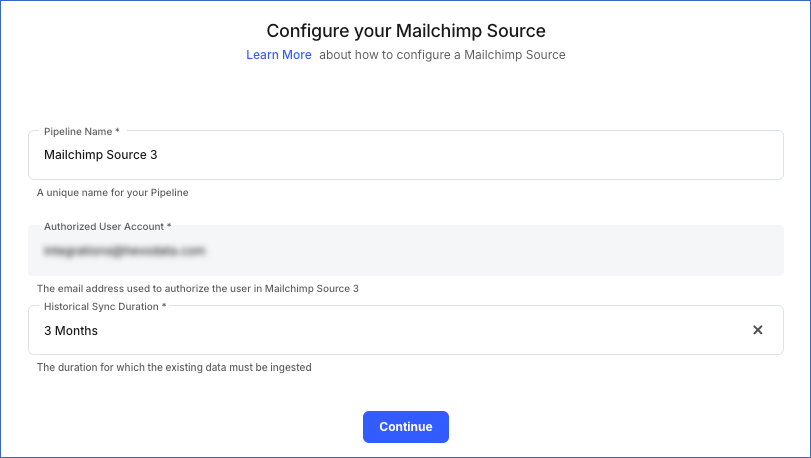
On the Configure your Mailchimp Source page, specify the following:
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Historical Sync Duration: The duration for which you want to ingest existing data from the Source. This cannot be changed after the Pipeline is created. Default duration: 3 Months.
Note: If you select All Available Data, Hevo ingests all the data available in your Mailchimp account since January 01, 2010.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 1 Hr | 1 Hr | 48 Hrs | 1-48 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: From Release 1.82, Hevo ingests your historical data using the Recent Data First approach. This enables you to have quicker access to your historical data.
-
For Pipelines created before Release 1.82: By default, Hevo replicates all the historical data present in your Mailchimp account.
-
For Pipelines created after Release 1.82: You can select the historical sync duration at the time of creating a Pipeline. Default duration: 3 Months.
-
-
Incremental Data: Once the historical load is complete, all new and updated records for the List Members, Member Tags, and Tags objects are ingested as per the ingestion frequency. The remaining objects are ingested in Full Load mode.
Note: From Release 1.85, Hevo ingests only new and updated data for Full Load objects to optimize the quota consumption. This feature is currently available on request only. You need to contact Hevo Support to enable it for your team.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination. For a detailed view of the objects, fields, and relationships, click the ERD.
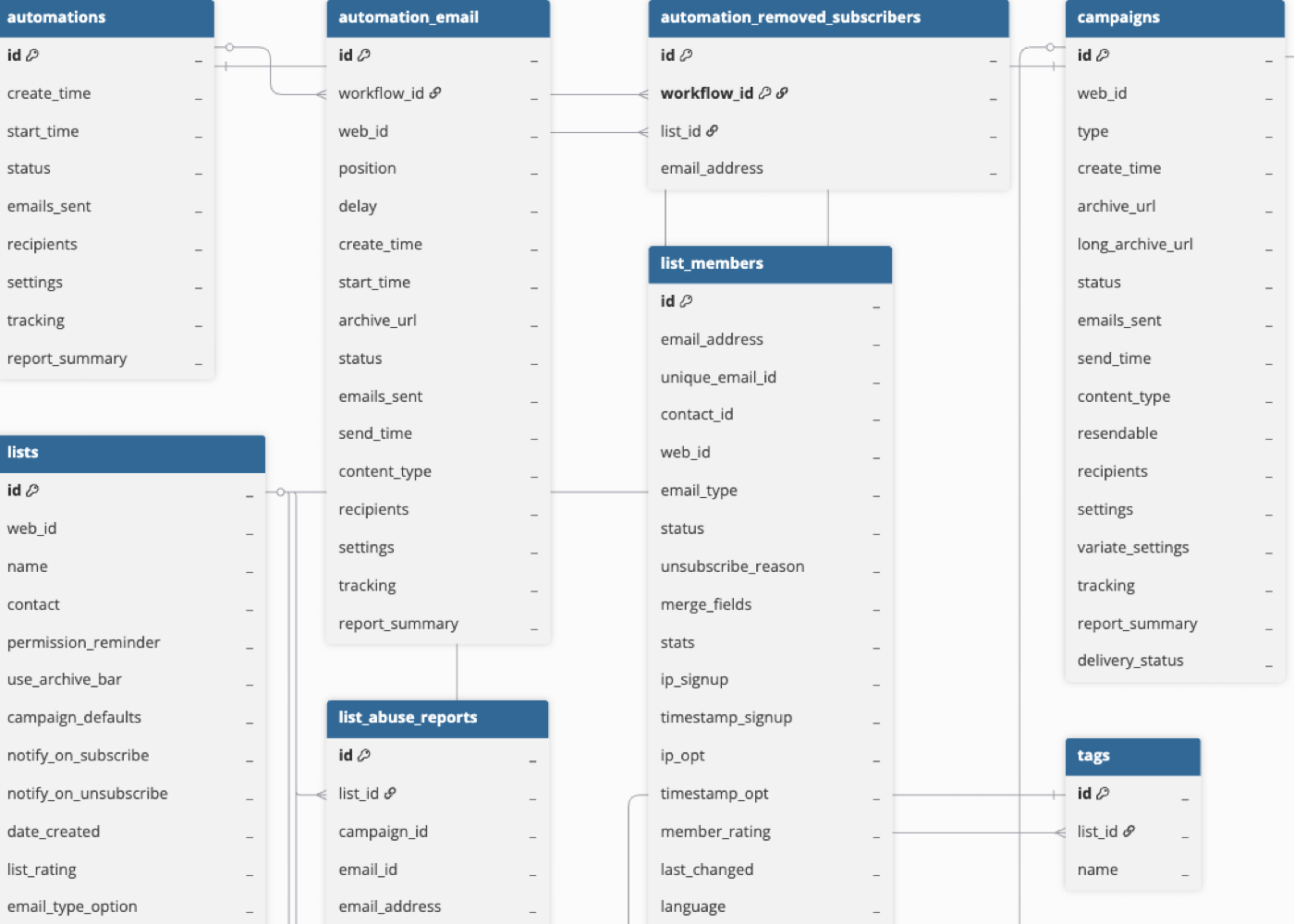
Data Model
The following is the list of tables (objects) that are created at the Destination when you run the Pipeline:
Note:
- For Pipelines created from Release 1.99 onwards: Hevo supports the data ingestion of the email activity reports object for winning variate campaigns.
- All objects other than List Members, Member Tags, and Tags are Full Load objects.
| Object | Description |
|---|---|
| Automations | Contains the details of a series of automation emails that are sent to subscribers when triggered by a specific date, activity, or event. Hevo also ingests information about emails and unsubscribers associated with each automation. |
| Automation Emails | Contains the details of all emails that are parts of an Automation, such as create time, update time, recipients, number of opens, and number of clicks. |
| Automation Removed Subscribers | Contains the details about members that have unsubscribed or have been removed from an Automation recipient list. |
| Campaigns | Contains the details of all the email templates that are designed to send to a mailing list. Hevo ingests data of all campaigns associated with your Mailchimp account and stores them in the campaigns table. Subscriber activity in a specific campaign as well as unsubscriber reports are also extracted for each campaign. |
| Click Reports | Contains the details of the clicks on specific links within a campaign. |
| Click Reports Members | Contains the details of the subscribers who clicked on links within a campaign. |
| Email Activity Reports | Contains the details of any subscriber activity within a campaign. Each activity is accompanied by a timestamp. |
| Lists | Contains the details about where you store and manage all of your contacts. The lists table contains detailed statistics for each list present in your Mailchimp account. |
| List Abuse Reports | Contains the details of all the members from a particular list that have marked an email as spam, along with the timestamp of that action. |
| List Members | Contains the details about all the members in a specific mailing list. |
| List Segments | Contains the details of all subscribers who share common information in specific fields. A tag that is created and assigned to members is also considered a segment. This tag is indicated by the type static. |
| Member Tags | Contains the details of all the tags that are associated with a contact in your Mailchimp account. |
| Reports | Contains the details of all automation and campaign reports in your Mailchimp account. These reports analyze clicks, opens, subscribers’ social activity, e-commerce data, and more. A report is generated for each campaign that is part of your account and stored in the reports table. Reports are updated each time a campaign is sent. |
| Segment Members | Contains the details about members belonging to various segments. |
| Tags | Contains the details of all the tags used to organize your contacts into multiple categories. |
| Unsubscribes | Contains the details of list members who unsubscribed from a specific campaign. |
Limitations
- Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Apr-28-2026 | NA | Updated section, Configuring Mailchimp as a Source to mention that the historical sync duration cannot be changed after the Pipeline is created. |
| Nov-07-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring Mailchimp as a Source as per the latest UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Apr-04-2023 | NA | Updated section, Configuring Mailchimp as a Source for more clarity. |
| Oct-17-2022 | 1.99 | Updated the section, Data Model to include information about the new objects supported by Hevo. |
| Sep-07-2022 | 1.97 | Updated section, Data Model to include information about new objects. |
| Aug-24-2022 | NA | Updated sections, Data Replication and Data Model to reorganize content for better understanding and coherence. |
| Jul-27-2022 | NA | Updated Note in section, Data Replication. |
| Mar-21-2022 | 1.85 | Added a note in section, Data Replication to inform about optimized quota consumption for Full Load objects. |
| Feb-21-2022 | 1.82 | Updated section, Data Replication to add information about reverse historical load and configurable historical sync duration. |
| Oct-25-2021 | NA | Added the Pipeline frequency information in the Data Replication section. |