YouTube Analytics
On This Page
YouTube Analytics provides you reports that help you understand channel performance, expenses, and user base of your videos to help you boost and manage your views. You can also generate reports around the monetary spends and ad performance.
The reports are generated using YouTube’s Bulk API and are classified as Channel Reports, as these provide details of statistics and trends of a particular YouTube channel.
Prerequisites
-
An active YouTube account with access to at least one YouTube channel.
-
The user has Viewer or Owner channel access for generating channel reports.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Configuring YouTube Analytics as a Source
Perform the following steps to configure YouTube Analytics as a Source in Hevo:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
In the Select Source Type page, select YouTube Analytics.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
In the Configure your YouTube Analytics account page, do one of the following:
-
Select a previously configured account and click Continue.
-
Click + Add YouTube Analytics Account and perform the following steps to configure an account:

-
Log in to your Google account that has Viewer or Owner channel access to generate channel reports.
-
Click Allow to authorize Hevo to access your Google account data.
-
-
-
In the Configure your YouTube Analytics Source page, specify the following:

-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Channel Reports: One or more channel reports that you want to load to the Destination.
-
-
Click Test & Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
In YouTube, a job has to be explicitly triggered to generate the Reports. Hevo triggers this job when you create the Pipeline, and once the reports are ready, Hevo fetches these. The first time the reports are triggered, it takes up to two days for these to get generated.
The reports are generated daily and contain data that is two days old. This is loaded as rows in the Destination. If on a given day, there is no data for a report, YouTube generates an empty report. In such a case, Hevo does not make any update in your Destination, that is, no NULL rows are added to the Destination. The position in the Pipeline Overview page reflects the date of creation of the reports.
For example, if a report is created on 10th June 2020, then the data in this report will be up till 8th June 2020.
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 12 Hrs | 15 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 12 Hrs | 30 Mins | 24 Hrs | 1-24 |
-
Historical Data: By default, Hevo loads reports for up to 30 days prior to the date the Pipeline is created. For example, if you create a Pipeline on Oct 1st, then, you would get the historical reports from Sept 1st.
The historical reports are retained for 30 days. If you refresh an object (report) using Restart or Change Position option, you can obtain the historical reports only if any historical report period remains within the last 30 days.
For example, if the Pipeline was created on Oct 1st, and on Oct 10th, you change the position to Oct 1st, then, you would get historical reports from Sept 10 to Oct 1 (remaining historical report period).
However, if you change the position on Nov 5th, you cannot retrieve the historical reports as these are saved only for 30 days from Pipeline creation, which would be Nov 1st in this case.
-
Incremental Data: Once the historical data ingestion is complete, every subsequent run of the Pipeline fetches new and updated data for the reports as per the ingestion frequency.
Incremental reports (generated after the Pipeline creation date) are retained for 60 days.
If you change the position for incremental reports, then, you can get the data for up to 60 days prior.
For example, if a Pipeline is created on Oct 1st, and on Dec 5th you change the position to Oct 2nd, you would get reports for Oct 5th to Dec 5th, in accordance with the 60 days retention stipulation.
-
Data Refresh: YouTube generates backfill data reports along with daily reports, and Hevo loads these reports in each run.
Read Types of Data Synchronization
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination. For a detailed view of the objects, fields, and relationships, click the ERD.
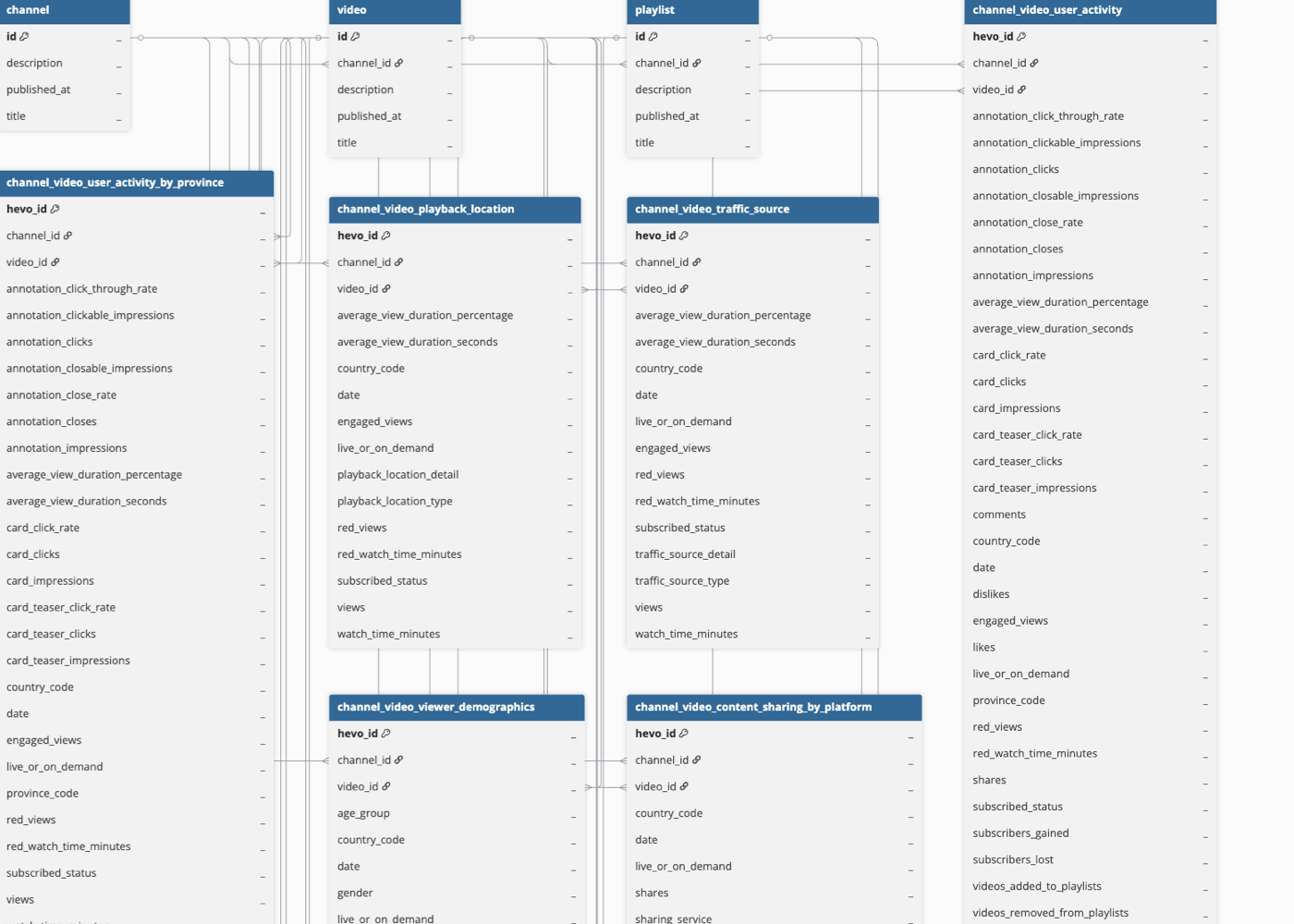
Data Model
The following reports (objects) are created at the Destination when you run the Pipeline:
| Report | Description |
|---|---|
| CHANNEL REPORTS | |
| channel_video_user_activity | User activity statistics for channels and their videos. |
| channel_video_user activity_by_province | User activity statistics for channels and their videos, segmented by province. |
| channel_video_playback_location | Statistics related to the type of page or application where video playbacks occurred. |
| channel_video_traffic_source | Statistics related to sources which led a viewer to the videos. |
| channel_video_device_type_and_operating_system | Statistics related to a viewer’s device type and operating system. |
| channel_video_viewer_demographic | Statistics related to viewers’ age group and gender. |
| channel_video_content_sharing_by_platform | Statistics related to frequency and type of sharing platform. |
| channel_video_annotation | Statistics related to annotations that display during a channel’s videos. |
| channel_video_card | Statistics related to performance of individual cards. |
| channel_video_end_screen | Statistics related to end screens that display after a video stops playing. |
| channel_video_subtitle | Statistics related to subtitles and language used in the videos. |
| channel_video_combined | Statistics for videos obtained by combining dimensions used in the playback location, traffic source, and device/OS reports. |
| channel_playlists_user_activity | User activity statistics for playlists and its videos. |
| channel_playlists_user_activity_by_province | User activity statistics for playlists & its videos, segmented by province. |
| channel_playlists_playback_location | Statistics related to the type of page or application where playlist playbacks occurred. |
| channel_playlists_traffic_source | Statistics related to sources which led the viewer to the playlist. |
| channel_playlists_device_type_and_operating_system | Statistics related to viewer’s device type and operating system. |
| channel_playlists_combined | Statistics for playlists obtained by combining dimensions used in the playback location, traffic source, and device/OS reports. |
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
- Google’s YouTube Analytics API requires time to authorize newly created or linked YouTube channels for third-party OAuth access. Hence, after creating a new channel or adding an existing one to your Google account, you must wait for at least 48 hours before attempting to connect it to Hevo.
Limitations
-
The scope of this integration is channel reports only. Hevo does not support targeted queries currently.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
FAQs
How can I become a Content Manager?
Read How to become a Content Manager?
How can I see the monetary reports?
Check if you have Content Owner/Content Manager access. If not, ask your Youtube Content owner to grant you Content Owner or Content Manager access.
If you are a Content Manager, by default you should have access to Monetary reports. If you do not have it, ask your Content Owner/Content Manager to provide Read access for these reports.
For which dates can I generate reports?
The reports generated today will have data for dates up to two days prior, as defined by YouTube.
If you find that the latest date in your reports table is not 2 days before today, then it may be the case that there is no data for that particular date. In case there is no data in the report type for a given day, Youtube generates an empty report. In such cases, Hevo does not load any data into the Destination.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-07-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-22-2025 | 2.41 | Updated section, Schema and Primary Keys to include the engaged_views metric in certain tables. |
| Sep-18-2025 | NA | Updated section, Configuring YouTube Analytics as a Source as per the latest UI. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Apr-29-2025 | NA | Added section, Source Considerations to inform users about OAuth delay of 48 hrs due to Google’s YouTube Analytics API. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Mar-07-2022 | 1.83 | Removed information related to content owner reports as these reports are not supported by Hevo now. |
| Oct-25-2021 | NA | Added the Pipeline frequency information in the Data Replication section. |