Amazon Aurora MySQL
On This Page
Hevo can load data from any of your Pipelines into an Amazon Aurora MySQL database. Follow the steps in this page to configure Amazon Aurora MySQL as a Destination.
We do not recommend using an Amazon Aurora MySQL Destination for building your production Pipelines. It can perform poorly even for low volumes of data. If you run into performance issues, these may be unresolvable, and you will have to migrate to a different Destination. Read Limitations of using MySQL as a Destination.
Prerequisites
-
The Amazon Aurora MySQL instance is running.
-
The MySQL version is 5.5 or higher. You can choose the MySQL version while creating the instance.
-
The database hostname and port number of the Amazon Aurora MySQL instance are available.
-
You are assigned the Team Collaborator or any administrator role except the Billing Administrator role in Hevo to create the Destination.
Retrieve the Hostname and Port Number (Optional)
Note: The Amazon Aurora MySQL hostnames start with your database name and end with rds.amazonaws.com. For example, mysql-rds-replica-1.xxxxxxxxx.rds.amazonaws.com.
-
In the left navigation pane of the Amazon RDS console, click Databases.
-
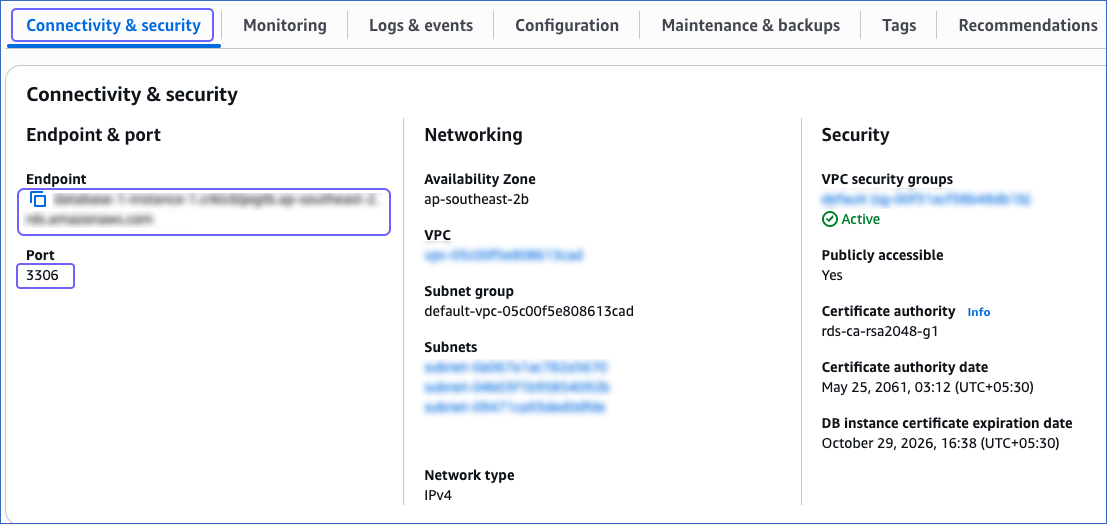
In the Databases section on the right, click the DB identifier of the Amazon Aurora MySQL instance. For example, database-1-instance-1 in the image below.

-
Click the Connectivity & security tab, and copy the values under Endpoint and Port. Use these values as the database host and database port respectively while configuring your Amazon Aurora MySQL Destination.
Whitelist Hevo’s IP Addresses
You need to whitelist the Hevo IP address(es) for your region to enable Hevo to connect to your Amazon Aurora MySQL database.
To do this:
-
Open the Amazon RDS console.
-
In the left navigation pane, click Databases.
-
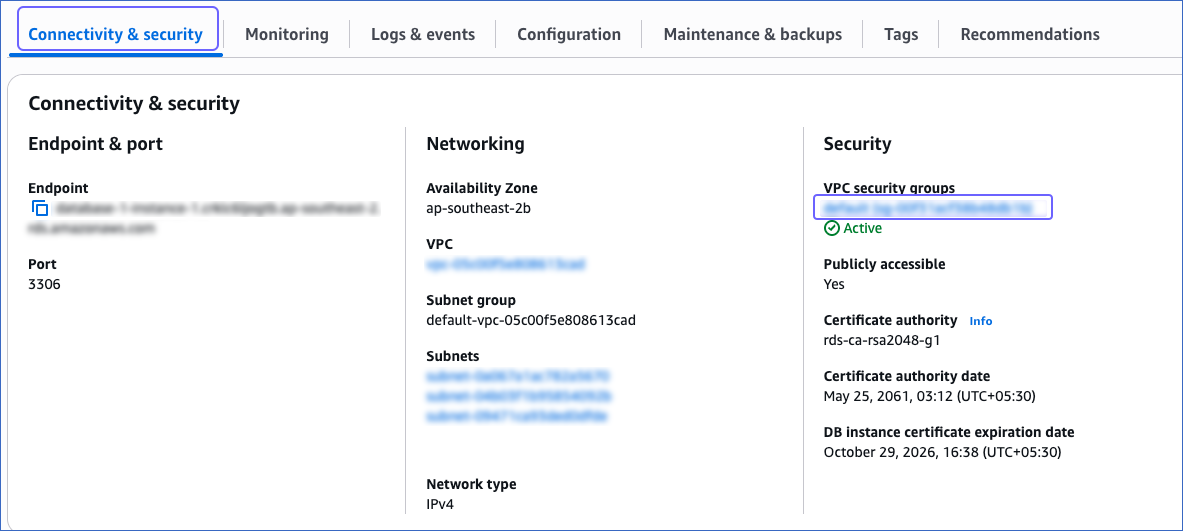
In the Databases section on the right, click the DB identifier of the Aurora MySQL instance to configure its security group. For example, database-1-instance-1 in the image below.
-
In the Connectivity & security tab, click the link text under Security, VPC security groups.
-
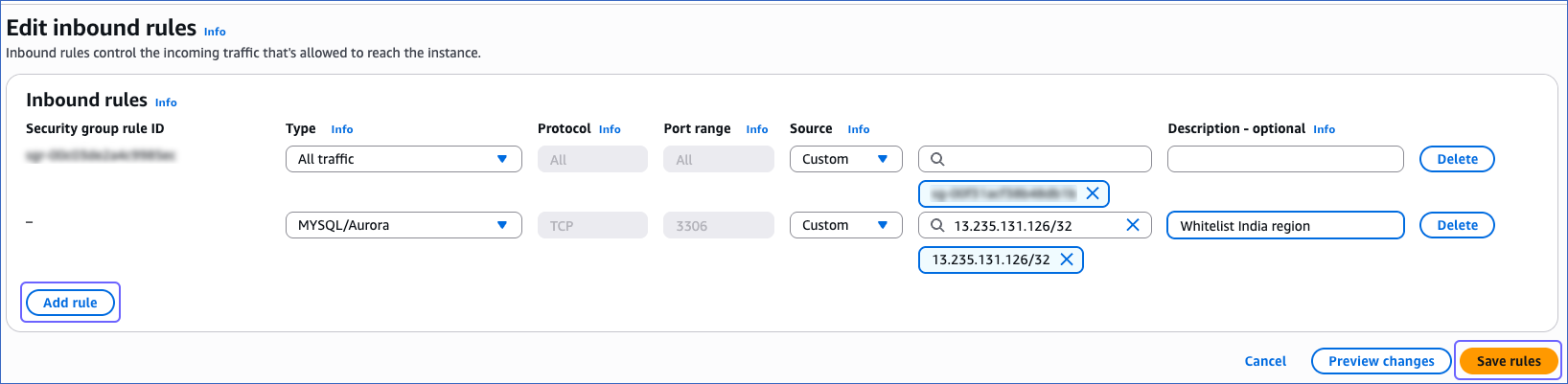
In the Actions drop-down at the top, select Edit inbound rules.

-
In the Edit inbound rules page:
-
Click Add rule.
-
Add the Hevo IP address(es) for your region to grant Hevo access to the Amazon Aurora MySQL instance.
-
Click Save rules.
-
Create a Database User and Grant Privileges
1. Create a database user
Perform the following steps to create a user in your Amazon Aurora MySQL database:
-
Log in to your Amazon Aurora MySQL database instance as a
rootuser using an SQL client tool. -
Enter the following command:
CREATE USER '<user_name>'@'%' IDENTIFIED BY '<strong password>';Note: Replace the placeholder values in the command above with your own.
2. Grant privileges to the user
The following table lists the privileges that Hevo requires to connect to and load data into your Amazon Aurora MySQL Destination:
| Privilege Name | Allows Hevo to |
|---|---|
| ALTER | Edit database tables. |
| CREATE | Create databases and tables. |
| CREATE TEMPORARY TABLES | Create temporary tables. |
| DELETE | Delete rows from database tables. |
| DROP | Delete databases and tables. |
| INSERT | Insert rows into database tables. |
| SELECT | Select rows from database tables. |
| UPDATE | Update rows in database tables. |
Perform the following steps to grant the required privileges to the user:
-
Log in to your Amazon Aurora MySQL database instance as a
rootuser using an SQL client tool. -
Enter the following command:
GRANT ALTER, CREATE, CREATE TEMPORARY TABLES, DELETE, DROP, INSERT, SELECT, UPDATE ON *.* TO '<user_name>'@'%';Note: Replace the placeholder values in the command above with your own.
Configure Amazon Aurora MySQL Connection Settings
Perform the following steps to configure Amazon Aurora MySQL as a Destination in Hevo:
-
Click DESTINATIONS in the Navigation Bar.
-
Click + Create Standard Destination in the Destinations List View.
-
On the Add Destination page, select Amazon Aurora MySQL.
-
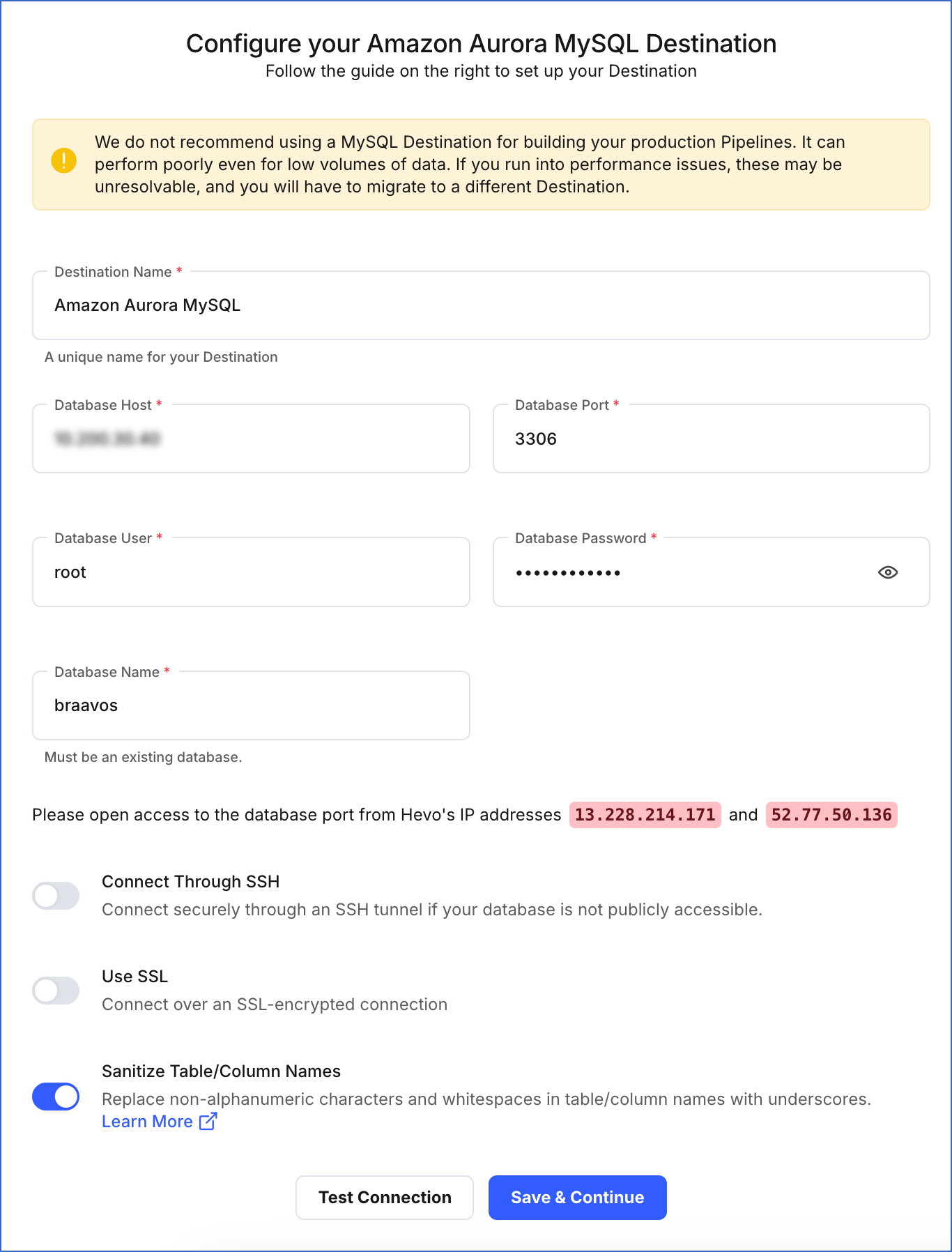
On the Configure your Amazon Aurora MySQL Destination page, specify the following:
-
Destination Name: A unique name for your Destination, not exceeding 255 characters.
-
Database Host: The Amazon Aurora MySQL host’s IP address or DNS. This is the endpoint that you retrieved in Step 1 above.
-
Database Port: The port on which your Amazon Aurora MySQL server listens for connections. This can be the port number that you retrieved in Step 3 above or the one that you specified while configuring the database. Default value: 3306.
-
Database User: The database user that you created. This is a user with a non-administrative role in the Amazon Aurora MySQL database.
-
Database Password: The password of the database user.
-
Database Name: The name of the Destination database where data is to be loaded.
-
Additional Settings:
-
Connect through SSH: Enable this option to connect to Hevo using an SSH tunnel, instead of directly connecting your Amazon Aurora MySQL database host to Hevo. This provides an additional level of security to your database by not exposing your Amazon Aurora MySQL setup to the public. Read Connecting Through SSH.
If this option is disabled, you must whitelist Hevo’s IP addresses. Refer to the section Whitelist Hevo’s IP addresses for the steps to do this.
-
Use SSL: Enable this option to use an SSL-encrypted connection. Specify the following:
-
CA File: The file containing the SSL server certificate authority (CA).
-
Client Certificate: The client public key certificate file.
-
Client Key: The client private key file.
For the steps to create the required files and keys, read Amazon Aurora MySQL.
-
-
Sanitize Table/Column Names?: Enable this option to remove all non-alphanumeric characters and spaces in a table or column name, and replace them with an underscore (_). Read Name Sanitization.
-
-
-
Click Test Connection. This button is enabled once all the mandatory fields are specified.
-
Click Save & Continue. This button is enabled once all the mandatory fields are specified.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Destination Considerations
- You must disable any foreign keys defined in the target tables. Foreign keys do not allow data to be loaded until the reference table has a corresponding key defined.
Limitations
- Hevo replicates a maximum of 4096 columns to each Amazon Aurora MySQL table, of which, six are Hevo-reserved metadata columns used during data replication. Therefore, your Pipeline can replicate up to 4090 (4096-6) columns for each table.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-12-2025 | NA | Updated the document as per the latest Hevo UI. |
| Nov-05-2025 | NA | Updated the page content as per the latest Amazon Aurora MySQL UI. |
| Apr-25-2023 | 2.12 | Updated section, Configure Amazon Aurora MySQL Connection Settings to add information that you must specify all fields to create a Pipeline. |
| Sep-07-2022 | NA | Added the following sections: - Prerequisites, - Whitelist Hevo’s IP Addresses, - Create a Database User and Grant Privileges, - Retrieve the Hostname and Port Number. |
| Feb-21-2022 | 1.82 | Updated section, Configure Amazon Aurora MySQL Connection Settings to provide support for SSL in Amazon Aurora MySQL as a Destination. |
| Jul-12-2021 | NA | Added section, Destination Considerations. |