Amazon Redshift
On This Page
Amazon Redshift is a fully managed, reliable data warehouse service in the cloud that offers large-scale storage and analysis of data set and performs large-scale database migrations. It is a part of the larger cloud-computing platform Amazon Web Services (AWS).
You can ingest data from your Amazon Redshift database using Hevo Pipelines and replicate it to a Destination of your choice.
Prerequisites
-
An active AWS account is available.
-
The Amazon Redshift instance is running.
-
Database hostname and port number of the Source instance are available.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Whitelist Hevo’s IP Addresses
You need to whitelist the Hevo IP address for your region to enable Hevo to connect to your Amazon Redshift database.
To do this, you need to add the inbound rules for your database, and verify Hevo IPs are whitelisted:
1. Add Inbound Rules
-
Log in to the Amazon Redshift dashboard.
-
In the left navigation pane, click Clusters.
-
Click the Cluster that you want to connect to Hevo.
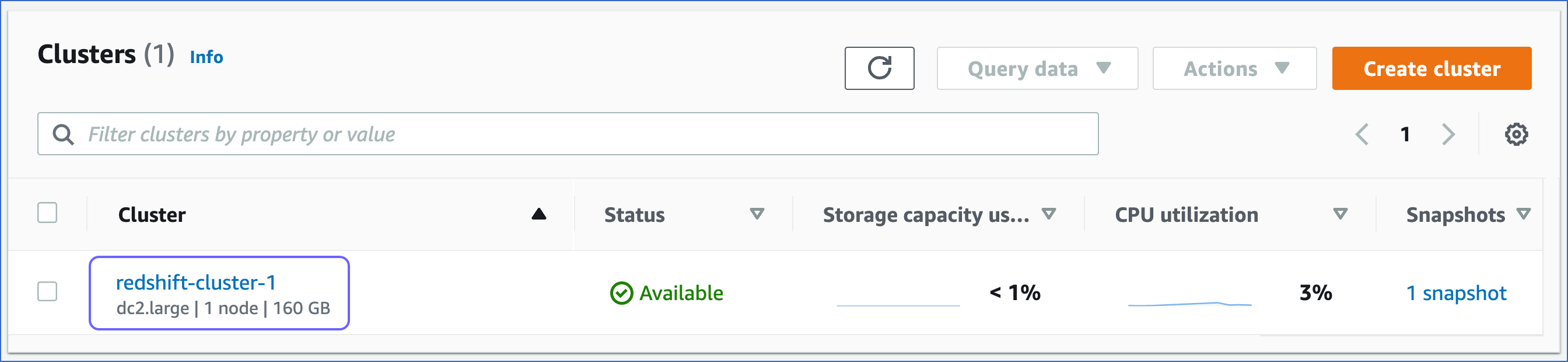
-
In the Properties tab, Network and security settings, click the link text under the VPC security group to open the Security Groups page.
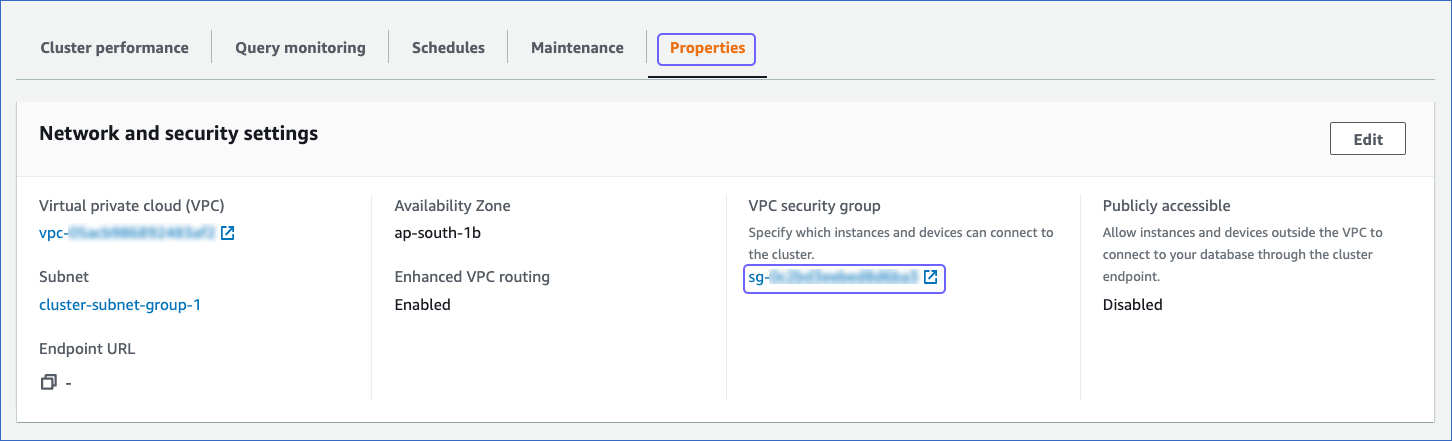
-
On the Security Groups page, click the Inbound rules tab, and then click Edit inbound rules.
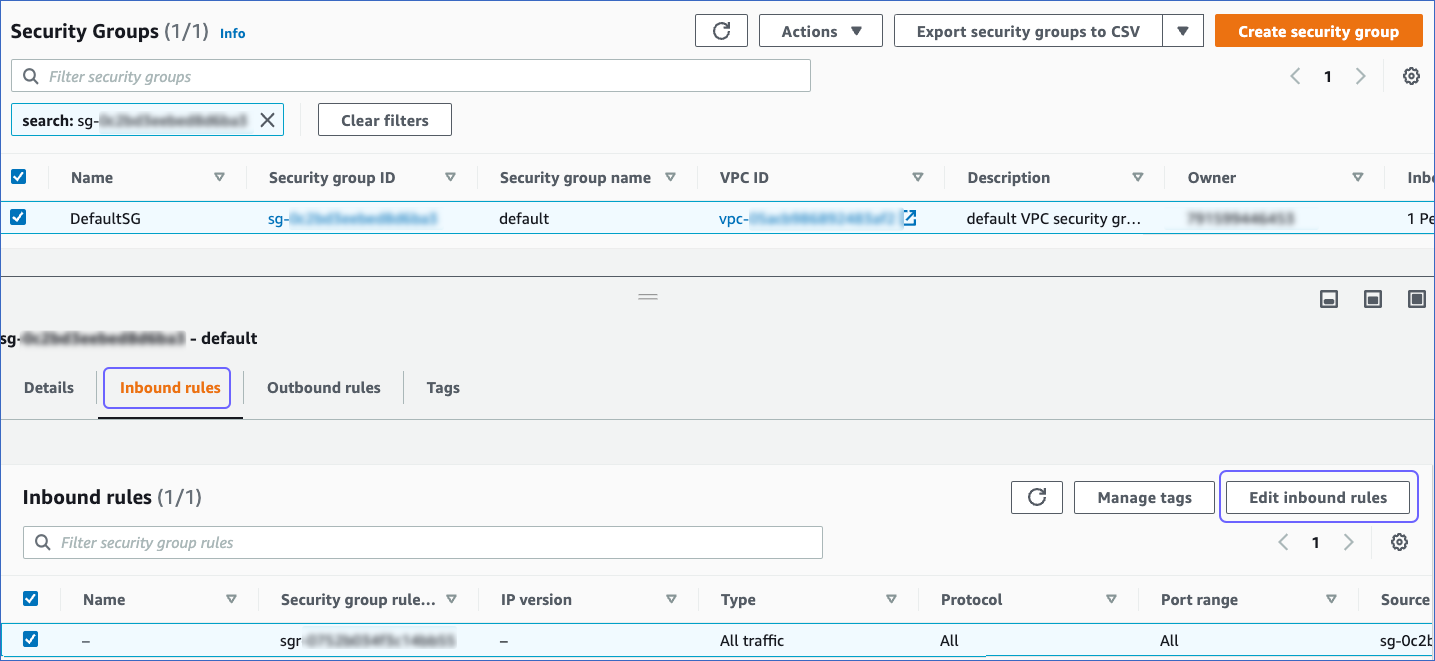
-
On the Edit inbound rules page:
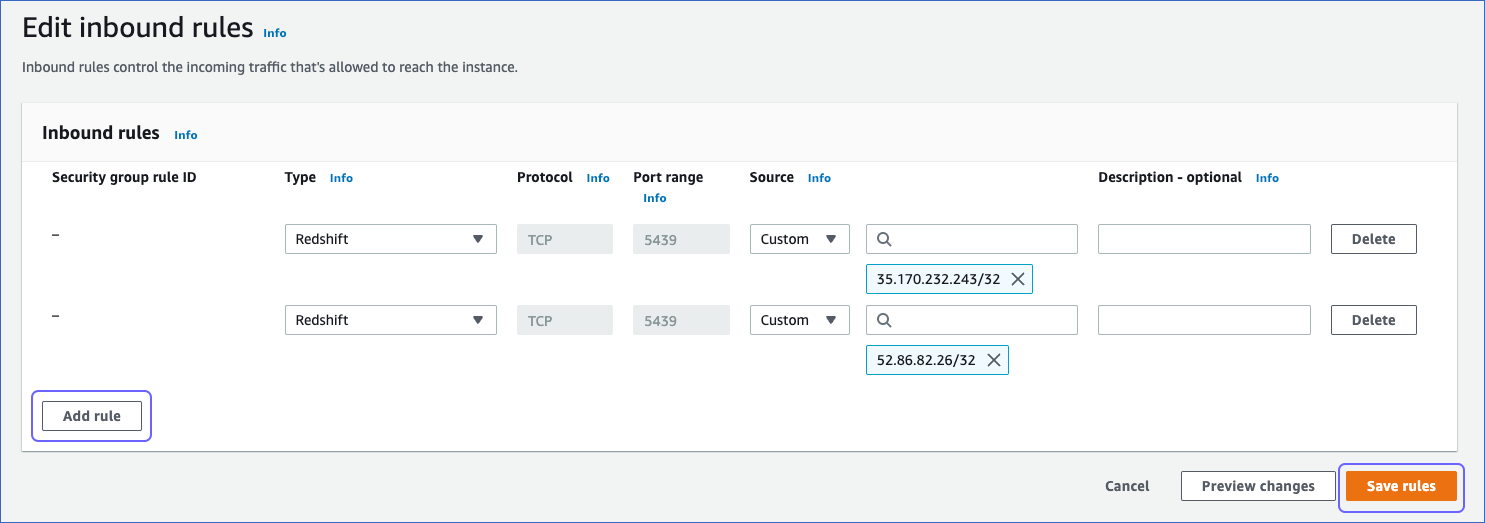
-
Click Add Rule.
-
In the Type column, select Redshift from the drop-down.
-
In the Port Range column, enter the port of your Amazon Redshift cluster. Default value: 5439.
-
In the Source column, select Custom from the drop-down and enter Hevo’s IP address for your region. Repeat this step to whitelist all the IP addresses.
-
Click Save.
-
2. (Optional) Verify Hevo IPs are Whitelisted
-
Log in to the Amazon Redshift dashboard.
-
In the left navigation pane, click Clusters.
-
Click the Cluster that you want to connect to Hevo.
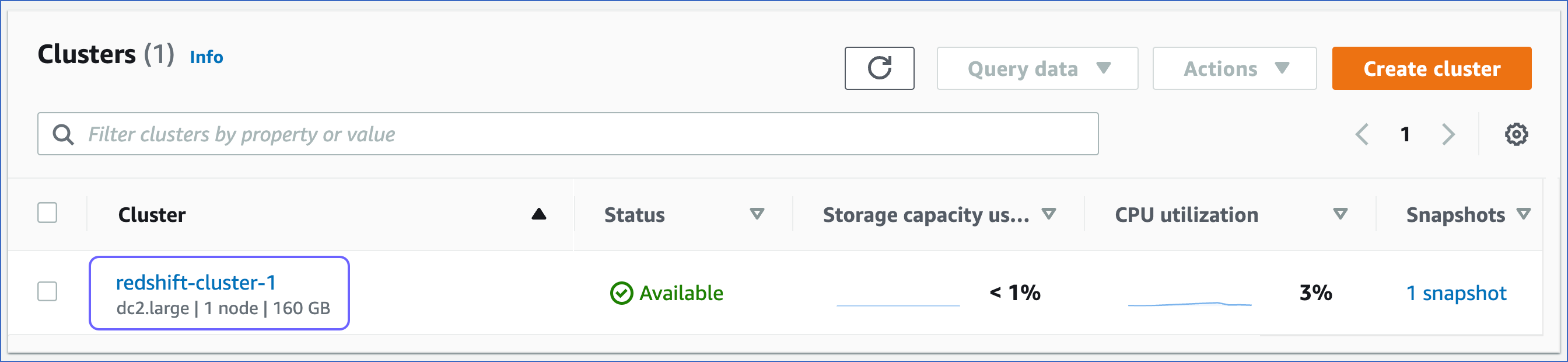
-
In the Properties tab, Network and security settings, click the link text under the VPC ID link.
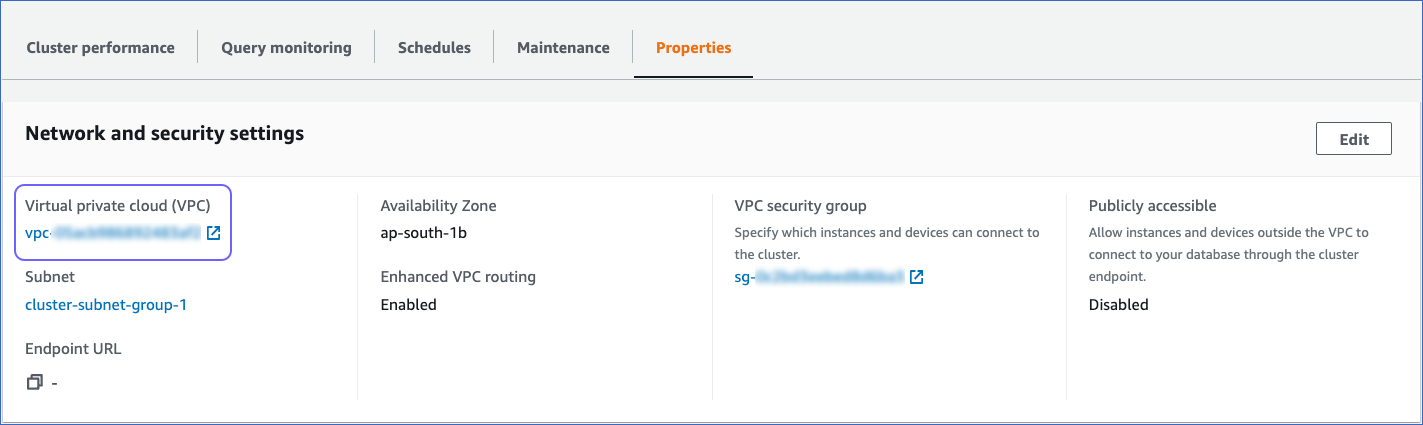
-
On the Your VPCs page, Details section, click the link text under Main network ACL.
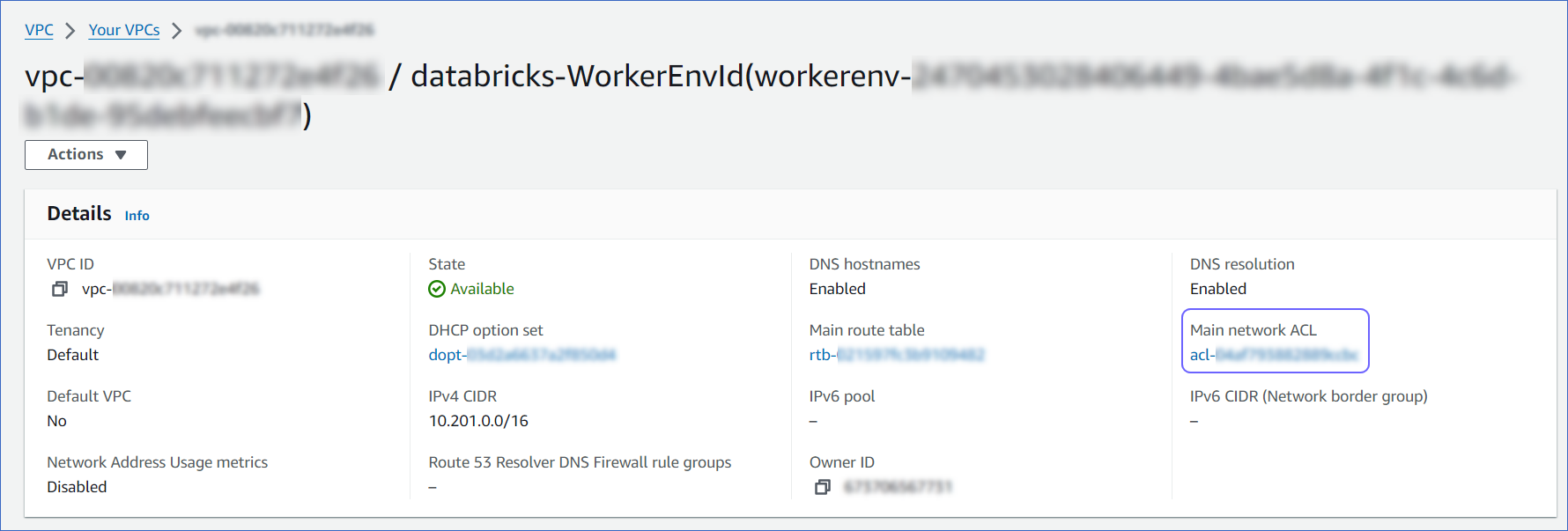
-
On the Network ACLs page, click the Inbound rules tab and ensure that the IP addresses you added appear in the range of IPs that are set to Allow. Else, click Edit inbound rules to include these IPs in the allowed range.
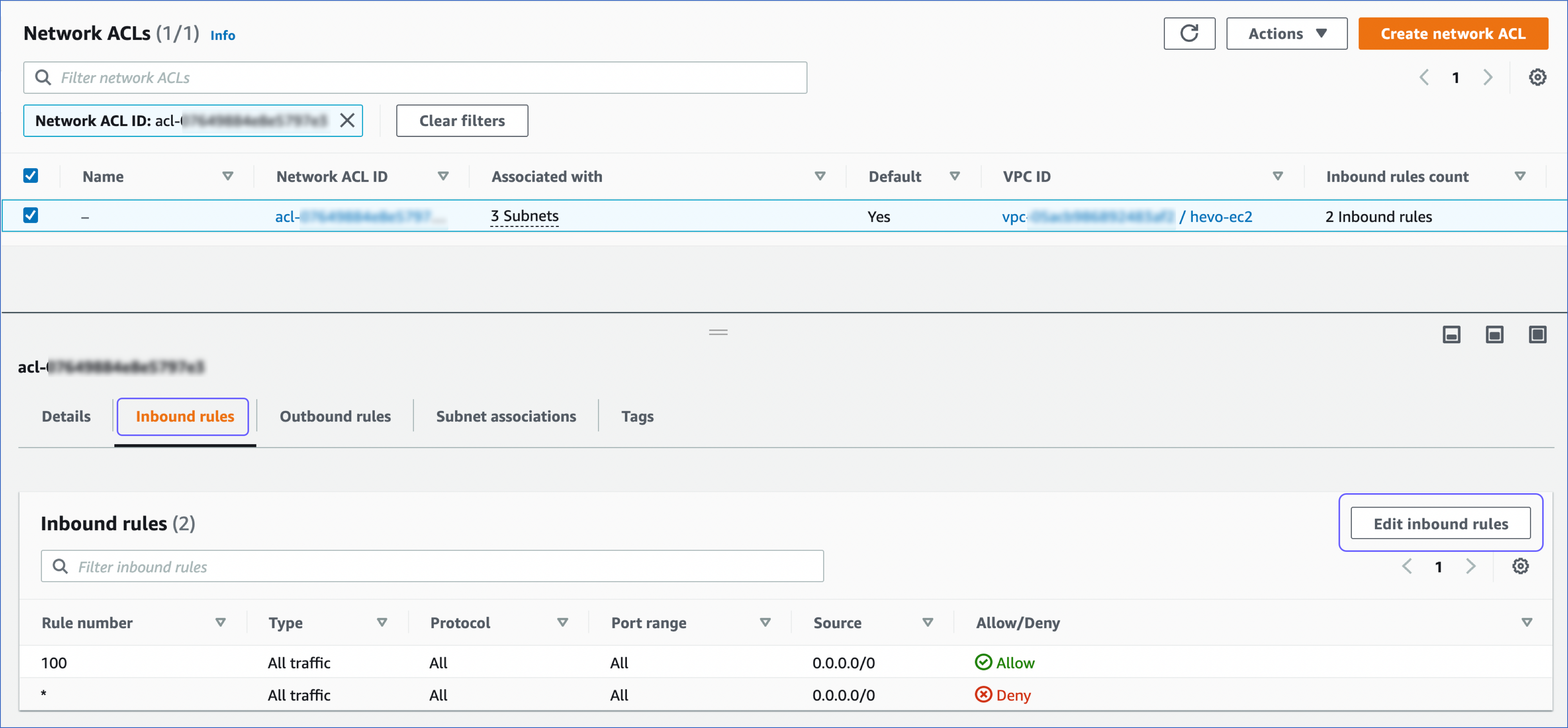
Create a Database User and Grant Privileges
-
(Optional) Create a database user.
-
Log in to your Amazon Redshift database as a
superuseror a user withCREATEprivilege. -
Enter the following command:
CREATE USER hevo WITH PASSWORD '<password>';
-
-
Grant
SELECTprivilege for all or specific tables to the user.-
Log in to your Amazon Redshift database as a
superuser. -
Enter the following commands:
GRANT SELECT ON ALL TABLES IN SCHEMA <schema_name> TO hevo; GRANT SELECT ON TABLE <schema_name>.<table_name> TO hevo;
-
-
Optionally, view the list of tables available in a schema:
SELECT distinct(<table_name>) FROM pg_table_def WHERE <schema_name> = 'pg_catalog';
(Optional) Retrieve the Hostname and Port Number
-
Log in to the Amazon Redshift dashboard.
-
In the left navigation pane, click Clusters.
-
Click the Cluster that you want to connect to Hevo.
-
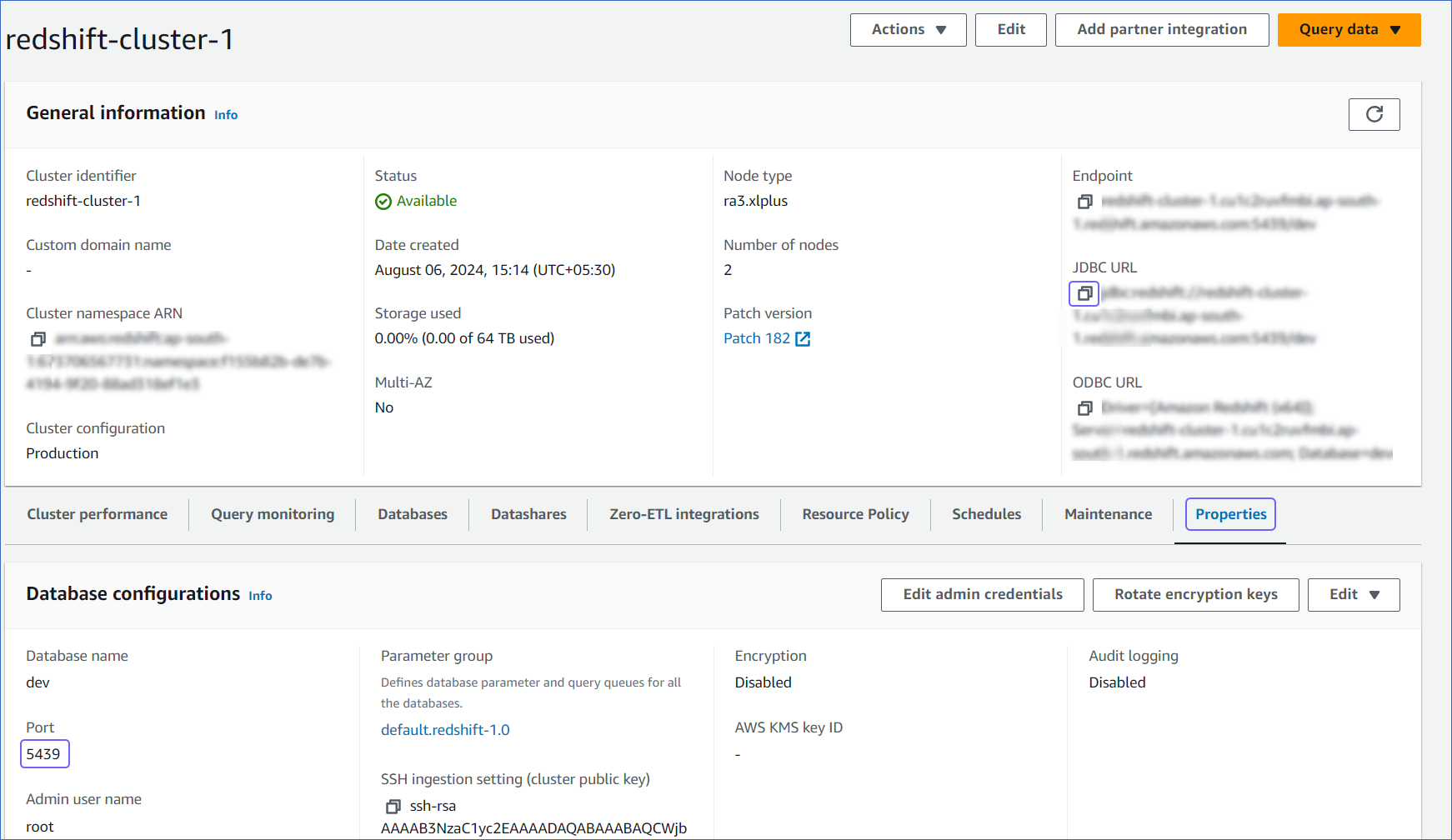
On the <Cluster_name> page, do the following:
-
Click the Copy icon to copy the JDBC URL and save it securely like any other password.
-
Navigate to the Properties tab, copy the Port and save it.
Use this JDBC URL (without the jdbc:redshift:// part) as the database host and the Port as the database port in Hevo while creating your Pipeline.
For example, in the JDBC URL jdbc:redshift://examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.com:5439/dev, the database host is examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.com.
-
Configure Amazon Redshift Connection Settings
Perform the following steps to configure Amazon Redshift as a Source in Hevo:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Amazon Redshift.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the Select Pipeline Mode page, choose the mode for ingesting data from the Source, and then click Continue. The available modes are Table and Custom SQL. These Pipeline modes do not capture deletes in the Source objects.

Depending on the Pipeline mode you select, you must configure the objects to be replicated. Refer to section, Object and Query Mode Settings for the steps to do this.
Note: For Custom SQL Pipeline mode, all Events loaded to the Destination are billable.
-
On the Configure your Amazon Redshift Source page, specify the following:

-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Database Cluster Identifier: Amazon Redshift host’s IP address or DNS name.
Note: For URL-based hostnames, exclude the initial jdbc:redshift:// part. For example, if the hostname URL is jdbc:redshift://examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.com:5439/dev, enter examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.com.
-
Database Port: The port on which your Amazon Redshift server listens for connections. Default value: 5439.
-
Database User: The database user that you created. This authenticated user has the permissions to read tables in your database.
-
Database Password: The password for the database user.
-
Database Name: The database that you wish to replicate.
-
Connect through SSH: Enable this option to connect to Hevo using an SSH tunnel, instead of directly connecting your Amazon Redshift database host to Hevo. This provides an additional level of security to your database by not exposing your Amazon Redshift setup to the public. Read Connecting Through SSH. To set up an SSH tunnel for your Redshift cluster hosted on Amazon Web Services (AWS), read Configuring an SSH Tunnel.
If this option is disabled, you must whitelist Hevo’s IP addresses.
-
Advanced Settings:
-
Load Historical Data: Applicable for Pipelines created with Table mode. If this option is enabled, the entire table data is fetched during the first run of the Pipeline. If disabled, Hevo loads only the records written to your database after the Pipeline was created.
-
Include New Tables in the Pipeline: Applicable for all ingestion modes except Custom SQL.
If enabled, Hevo automatically ingests data from tables created in the Source after the Pipeline has been built. These may include completely new tables or previously deleted tables that have been re-created in the Source. All data for these tables is ingested using database logs, making it incremental.
If disabled, new and re-created tables are not ingested automatically. They are added in SKIPPED state in the objects list, on the Pipeline Overview page. You can update their status to INCLUDED to ingest data.
You can change this setting later.
-
-
-
Click Test Connection. This button is enabled once you specify all the mandatory fields. Hevo’s underlying connectivity checker validates the connection settings you provide.
-
Click Test & Continue to proceed for setting up the Destination. This button is enabled once you specify all the mandatory fields.
Object and Query Mode Settings
Once you have specified the Source connection settings in Step 4 above, do one of the following:
-
For Pipelines with Table mode:
-
On the Select Objects page, select the objects you want to replicate and click Continue.

Note: Each object represents a table in your database.
-
On the Configure Objects page, specify the query mode you want to use for each selected object.

-
-
For Pipelines with Custom SQL mode:
-
On the Provide Query Settings page, enter the custom SQL query to fetch data from the Source.
-
In the Query Mode drop-down, select the query mode, and click Continue.

-
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 15 Mins | 15 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests all available data for the selected objects from your Source database.
-
Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Limitations
- Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-07-2025 | NA | Updated the document as per the latest Hevo UI. |
| Oct-09-2025 | NA | Updated section, Configure Amazon Redshift Connection Settings to add description for the Load Historical Data option. |
| Sep-18-2025 | NA | Updated section, Configure Amazon Redshift Connection Settings as per the latest UI. |
| Aug-1-2025 | NA | Added clarification that data ingested from new and re-created tables is billable. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Mar-12-2025 | NA | Updated section, Configure Amazon Redshift Connection Settings to clarify that Table and Custom SQL ingestion modes do not capture deletes. |
| Jan-07-2025 | NA | Added a limitation about Event size. |
| Oct-22-2024 | NA | Updated sections, Whitelist Hevo’s IP Addresses and (Optional) Retrieve the Hostname and Port Number as per the Amazon Redshift UI. |
| Mar-05-2024 | 2.21 | Added the Data Replication section. |
| Nov-03-2023 | NA | Renamed section, Object Settings to Object and Query Mode Settings. |
| Apr-21-2023 | NA | Updated section, Configure Amazon Redshift Connection Settings to add a note to inform users that all loaded Events are billable for Custom SQL mode-based Pipelines. |
| Dec-19-2022 | 2.04 | Updated section, Configure Amazon Redshift Connection Settings to add information that you must specify all fields to create a Pipeline. |
| Dec-07-2022 | 2.03 | Updated section, Configure Amazon Redshift Connection Settings to mention about including skipped objects post-Pipeline creation. |
| Dec-07-2022 | 2.03 | Updated section, Configure Amazon Redshift Connection Settings to mention about the connectivity checker. |
| Apr-21-2022 | 1.86 | Updated section, Configure Amazon Redshift Connection Settings. |
| Jan-24-2021 | NA | Updated section, Whitelist Hevo’s IP Addresses as per the latest Amazon Redshift interface. |
| Jan-03-2022 | 1.79 | Updated the description of the Include New Tables in the Pipeline advance setting in the Configure Amazon Redshift Connection Settings section. |
| Jul-26-2021 | 1.68 | Added a note for the Database Cluster Identifier field. |
| Jul-12-2021 | 1.67 | Added the field Include New Tables in the Pipeline under Source configuration settings. |
| Feb-22-2021 | 1.57 | Revised the document to include the end-to-end procedure for configuring Amazon Redshift as a Source. |