Elasticsearch
On This Page
Elasticsearch is a distributed, RESTful search and analytics engine that centrally stores your data so you can search, index, and analyze data of all shapes and sizes. As Elasticsearch relies on indices to search and fetch documents from your data, it preempts operations that may cause memory issues and stops them with exceptions. Hevo parses some of these exceptions and recommends corrective actions. Read Configuration Changes in Elasticsearch to know about these.
Hevo connects to your Elasticsearch cluster using the Elasticsearch Transport Client and synchronizes the data available in the cluster to your preferred data warehouse using indices. Currently, Hevo supports the following variants:
- Generic Elasticsearch
- AWS Elasticsearch
Prerequisites
-
Elasticsearch version greater than 7.0. View versions.
-
There is at least one sortable field in each document. To be sortable, the fields can be of any of these types:
unsigned_long,long_,_ integer,short,byte,float,_ doublehalf_floatscaled_floatdateanddate_nanos. -
The database username and password are available if your Elasticsearch host uses Native Realm authentication.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo, to create the Pipeline.
Perform the following steps to configure your Elasticsearch Source:
Retrieve the Hostname
-
For self-hosted or cloud-based Elasticsearch databases, contact your system admin to know the database hostname and port.
-
For AWS Elasticsearch services, contact your service provider.
(Optional) Obtain Username and Password
The Elastic Stack security features authenticate users by using realms and one or more token-based authentication services. Currently Hevo’s Elasticsearch integration supports only Native Realm authentication.
Contact your system administrator for obtaining the username and password, if you do not have these details.
(Optional) Connect to Elasticsearch hosted inside a Virtual Private Cloud (VPC)
Hevo connects to your Elasticsearch instance hosted inside a VPC using a reverse proxy server set up on Amazon EC2. The server routes all requests that Hevo makes to ingest data to your Elasticsearch instance inside the VPC.
To enable Hevo to connect to your Elasticsearch instance configured inside a VPC, you need to:
-
Retrieve the public Endpoint and connect to the EC2 instance.
-
Configure a reverse proxy server in the EC2 instance.
These steps are to set up using NGINX Open Source as the reverse proxy server. You can also use another web server, such as Apache or Caddy.
1. Set up the EC2 instance and Whitelist Hevo’s IP addresses
-
Open the EC2 Management Console in your AWS account and click Launch instance. Read Launch an EC2 instance
-
On the Launch an instance page, under Name and tags, specify a name for your instance.
-
In the Key pair (login) section, click Create new key pair to create one or select an existing option from the Key pair name drop-down. It consists of public and private keys and enables a secure connection to your instance. Read Key pair (login).

-
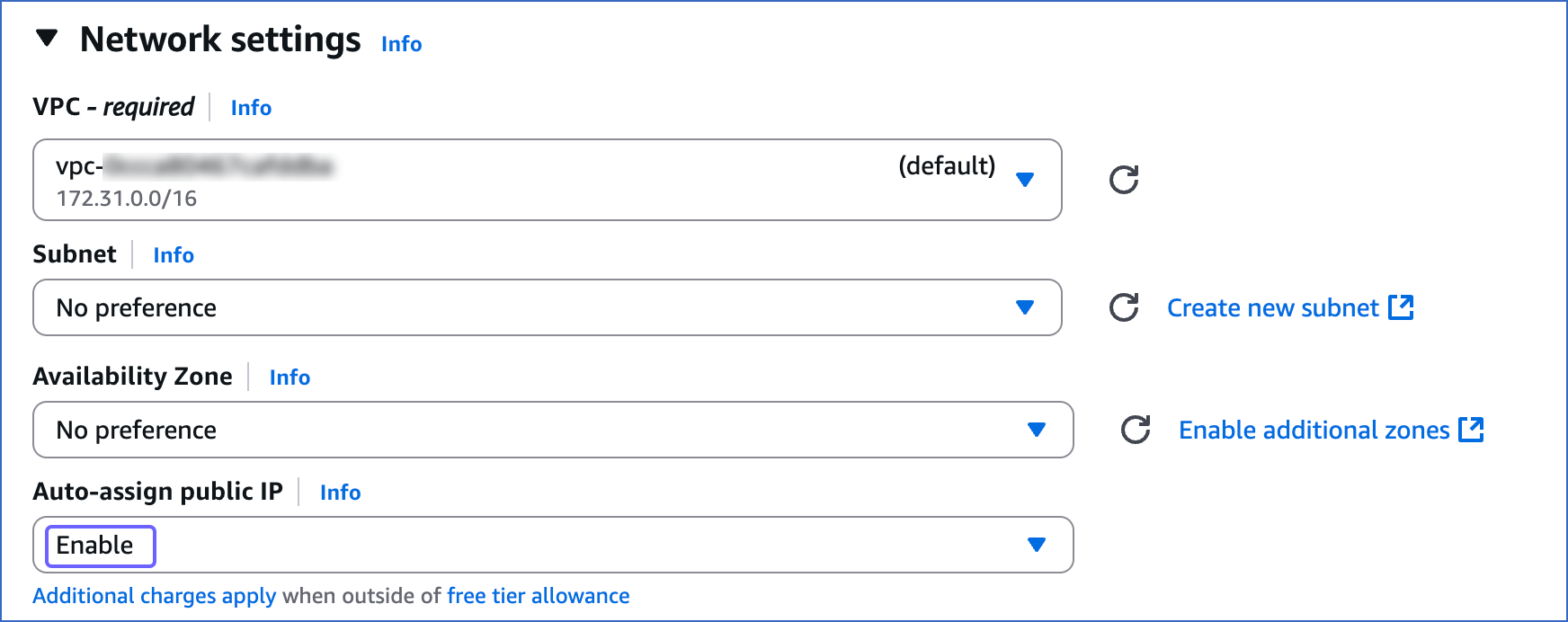
In the Network settings panel, click Edit and do the following:
-
Select the VPC from the drop-down, such that it is in the same VPC as your Elasticsearch database.
-
Enable the Auto-assign public IP, to assign a public IP and DNS to the instance.
-
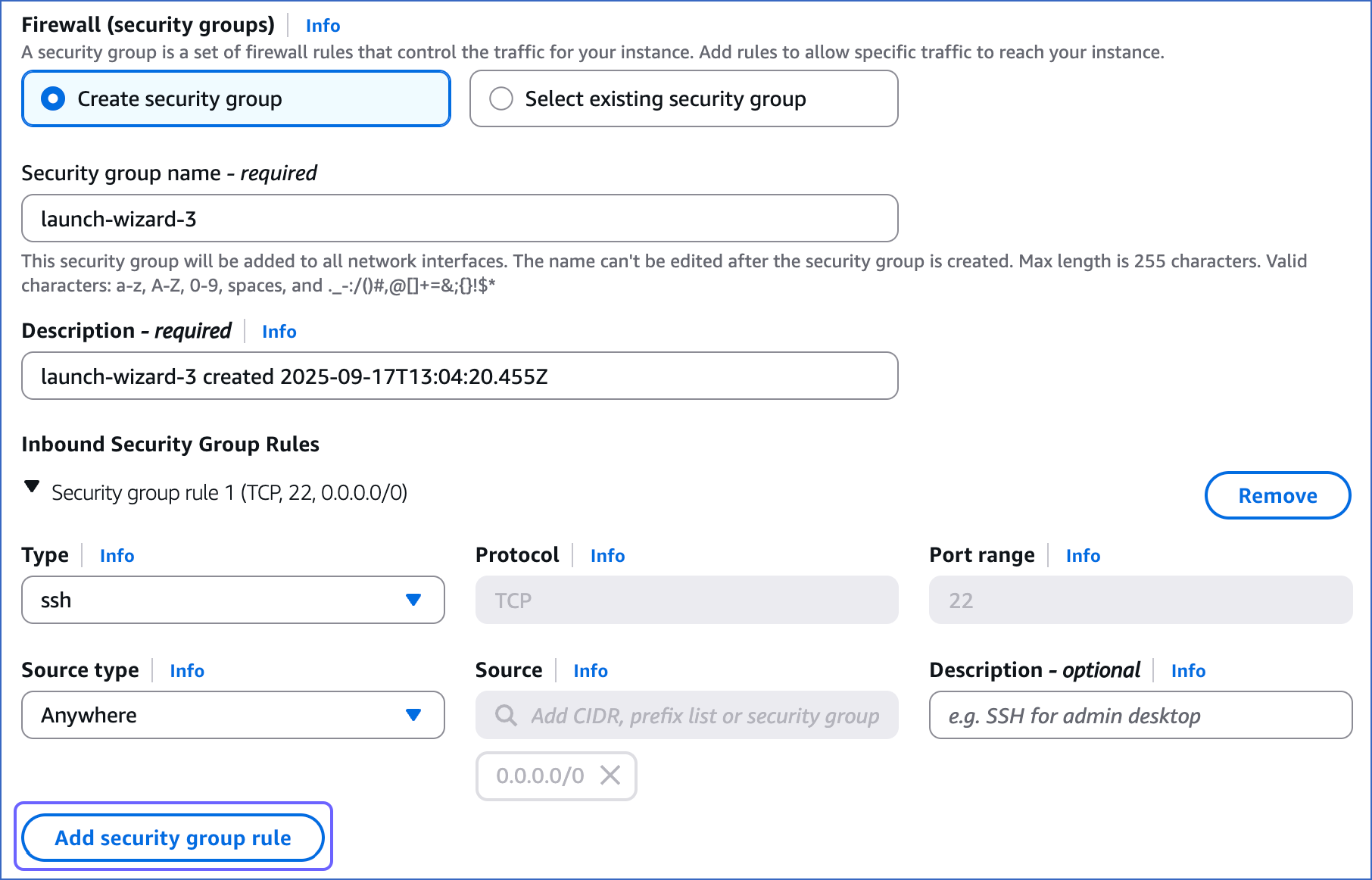
Under Firewall (security groups), select Create security group and specify the following:
-
Security group name: The name of your security group.
-
Description: The purpose of your security group.
-
-
Under Inbound Security Group Rules, click Add security group rule. Enter the details to whitelist Hevo’s IP addresses of your region for the HTTP and HTTPS protocol types. Read Network Settings.
-
Click Launch Instance.
-
2. Retrieve the public Endpoint and connect to the EC2 instance
-
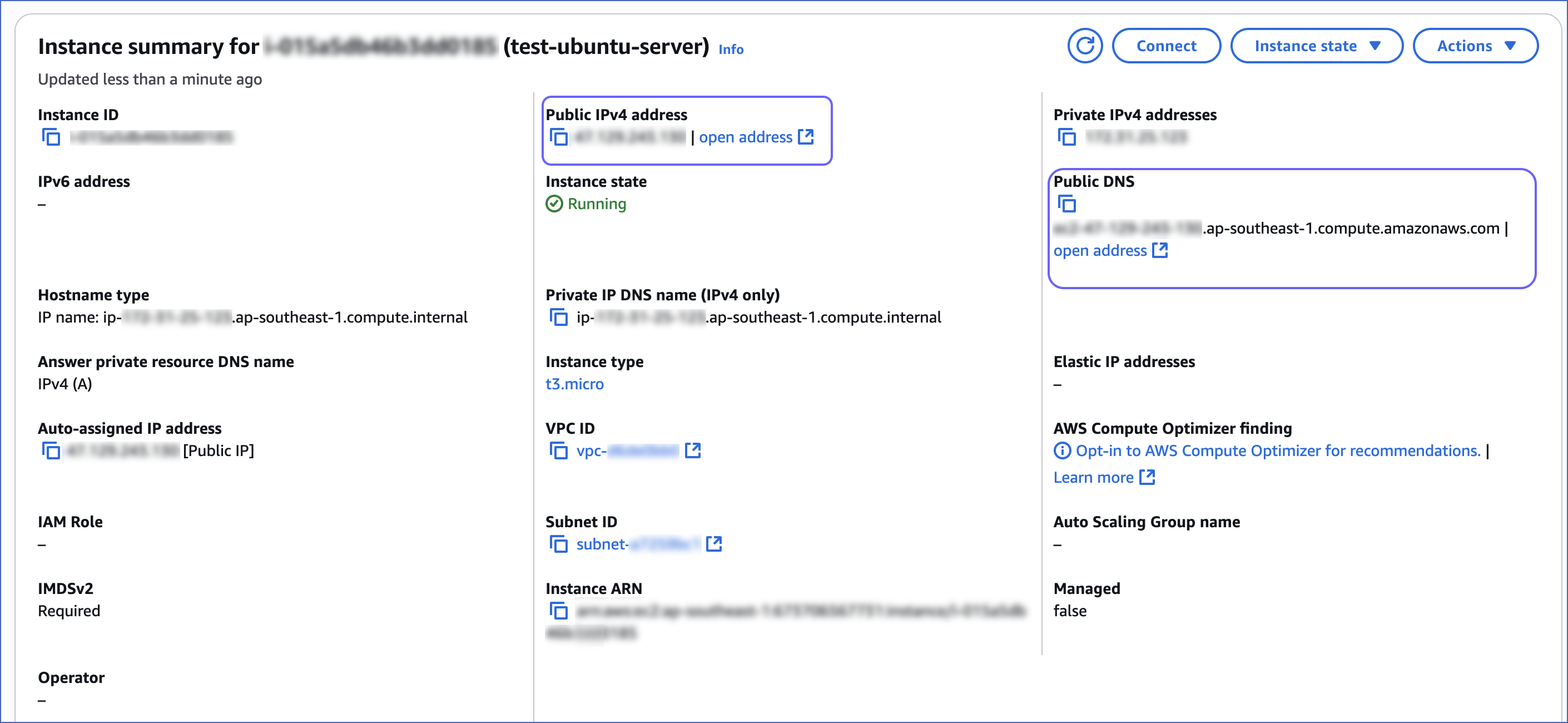
On the Launch an instance page, scroll down and click View all instances.
-
Click the instance for which you want to retrieve the public endpoint.

-
The public endpoint could be Public IPv4 address or Public IPv4 DNS.
-
Connect to the EC2 instance using one of the available methods, such as SSH or EC2 Instance Connect. Read Connect to your Linux instance.
3. Configure your reverse proxy server
-
Install NGINX Open Source in the EC2 instance. Read Installing NGINX.
-
Perform the following steps to edit the NGINX configuration, and add your Elasticsearch instance public endpoint and port number:
-
Navigate to the configuration file directory. For example, /etc/nginx.
-
Edit the configuration file, /etc/nginx/conf.d, and add the following information:
server { listen 443; location / { proxy_pass http://<elasticsearch-services-endpoint>:443; } } -
Save the file and restart the NGINX service. For example,
$ sudo service nginx restart
-
Configure Elasticsearch Connection Settings
Perform the following steps to configure Elasticsearch as the Source in Hevo:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Elasticsearch.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
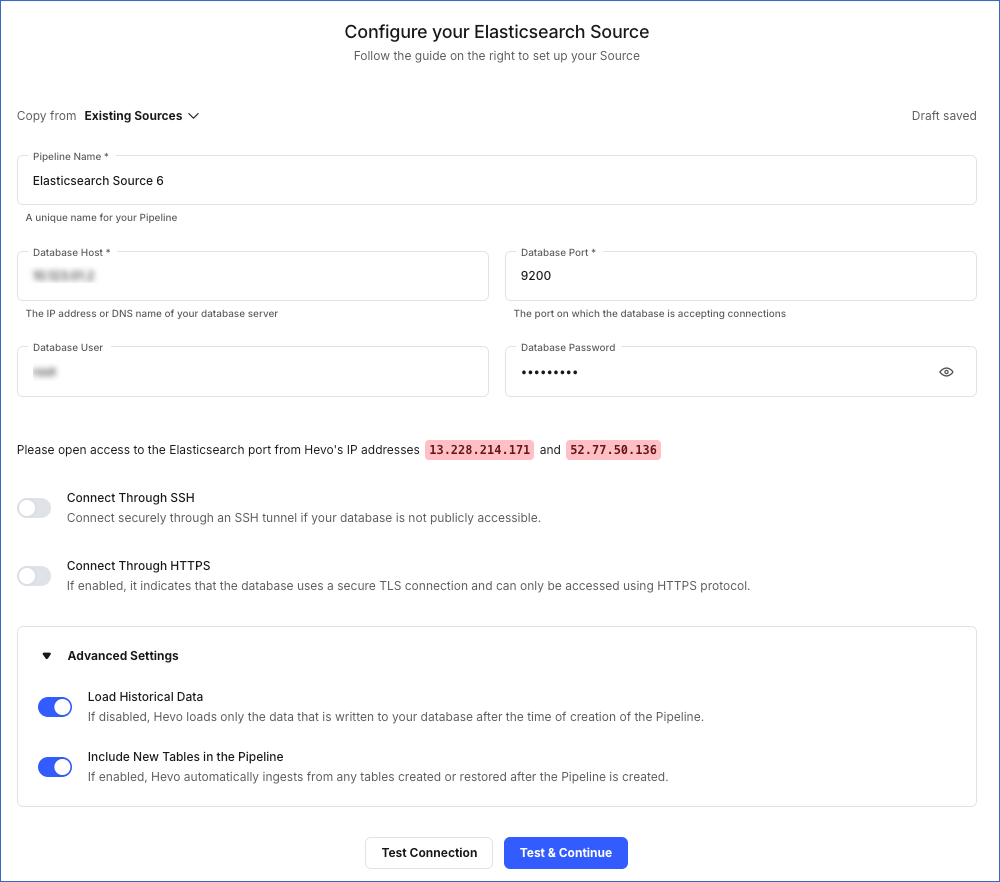
On the Configure your Elasticsearch Source page, specify the following:
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Database Host: The Elasticsearch database host’s IP address or DNS. Provide the public IP address or DNS of the EC2 instance as retrieved in Step 3 if your Elasticsearch database is hosted inside a VPC.
-
Database Port: The port on which your Elasticsearch server listens for connections. Default value: 9200.
Note: For an Elasticsearch database hosted inside a VPC, this port number is 443.
-
Database User (Optional): The authenticated user that can read the tables in your database.
-
Database Password (Optional): The password for the database user.
-
Connection Options: Select one of the following options to specify how Hevo must access your database instance:
-
Connect through SSH: Enable this option to connect to Hevo using an SSH tunnel, instead of directly connecting your Elasticsearch database host to Hevo. This provides an additional level of security to your database by not exposing your Elasticsearch setup to the public. Read Connecting Through SSH.
If this option is disabled, you must whitelist Hevo’s IP addresses to allow Hevo to connect to your Elasticsearch host.
Note: This option does not apply to an AWS Elasticsearch Source. To connect to that Source, you must set up a reverse proxy server.
-
Connect through HTTPS: Enable this option if your cluster is configured to use HTTPS. Contact your administrator if you do not have this information. Keep this option disabled to connect using HTTP.
Note: This option is mandatory for all HTTPS-enabled Elasticsearch clusters.
-
-
Advanced Settings:
-
Load Historical Data: If this option is enabled, the entire table data is fetched during the first run of the Pipeline. If disabled, Hevo loads only the data that was written in your database after the time of creation of the Pipeline.
-
Include New Tables in the Pipeline: Applicable for all ingestion modes except Custom SQL.
If enabled, Hevo automatically ingests data from tables created in the Source after the Pipeline has been built. These may include completely new tables or previously deleted tables that have been re-created in the Source. All data for these tables is ingested using database logs, making it incremental and therefore billable.
If disabled, new and re-created tables are not ingested automatically. They are added in SKIPPED state in the objects list, on the Pipeline Overview page. You can update their status to INCLUDED to ingest data.
You can change this setting later.
-
-
-
Click Test & Continue. This button is enabled once you specify all the mandatory fields.
-
Proceed to configuring the data ingestion and setting up the Destination.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 15 Mins | 15 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests all the data available in your Elasticsearch database.
-
Incremental Data: Once the historical load is complete, all new and updated data is synchronized with your Destination as per the ingestion frequency.
Note: A maximum of 500 Events are ingested in each call to the database, to optimize the processing load on your cluster. Contact Hevo Support if you want to modify this limit.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
Elasticsearch does not have the capability to expose each document modification. As a result, it can be difficult to sort multiple documents if they have the same value in the field used for sorting. Therefore, an additional unique identifier is required to sort them properly. This identifier differs based on your Elasticsearch version.
- For versions 8.0 and above: Specify the unique identifier field while configuring your objects. This field must be one of the following data types: unsigned long, long, integer, short, byte, float, double, half float, or scaled float.
- For versions below 8.0: The _id field is used by default as the unique identifier field.
Limitations
-
Only Native Realm authentication is supported.
-
Hevo currently does not support deletes. Therefore, any data deleted in the Source may continue to exist in the Destination.
-
Hevo does not support the replication of hidden objects.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
See Also
- Configuration Changes in Elasticsearch
- Connecting Through Reverse SSH Tunnel
- Amazon EC2
- Launch your instance
- NGINX
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Dec-08-2025 | NA | Added clarification about the Connect through HTTPS option being mandatory. |
| Nov-12-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configure Elasticsearch Connection Settings as per the latest UI. |
| Sep-17-2025 | NA | Updated section, (Optional) Connect to Elasticsearch hosted inside a Virtual Private Cloud (VPC) as per the latest Elasticsearch UI |
| Aug-1-2025 | NA | Added clarification that data ingested from new and re-created tables is billable. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Nov-18-2024 | NA | Renamed section Set up the EC2 instance to Set up the EC2 instance and Whitelist Hevo’s IP addresses and updated it as per the latest Elasticsearch UI. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Jan-16-2024 | NA | Updated section, Source Considerations to add information about _id field being used for sorting only in specific Elasticsearch versions. |
| Jul-21-2023 | NA | Updated section, Limitations to add information about Hevo not supporting replication for hidden objects. |
| Nov-22-2022 | NA | Updated section, Limitations to add information about Hevo not capturing deletes. |
| Aug-24-2022 | NA | Updated sections, Data Replication and Configure Elasticsearch Connection Settings to restructure the content for better understanding and coherence. |
| Jun-09-2022 | NA | Added a reference to the Configuration Changes in Elasticsearch page in the Overview section. |
| Apr-11-2022 | 1.86 | Added a note in the Connection Settings about setting up a reverse proxy server for connecting to an AWS Elasticsearch Source. |
| Feb-21-2022 | 1.82 | Added section, (Optional) Connect to Elasticsearch hosted inside a Virtual Private Cloud (VPC) |
| Jan-03-2022 | 1.79 | Updated the description of the Include New Tables in the Pipeline advance setting in the Configure Elasticsearch Connection Settings section. |
| Jul-26-2021 | 1.68 | Added a note for the Database Host field. |
| Jul-12-2021 | 1.67 | Added the field Include New Tables in the Pipeline under Source configuration settings. |
| Jun-01-2021 | 1.64 | Updated the Configure Elasticsearch Connection Settings section to include the Connect Through HTTPS setting. |