REST API
On This Page
Hevo allows you to bring data from various Sources through its native connectors. However, for situations where you need to fetch data from several applications or an in-house REST API, you can use the REST API connector.
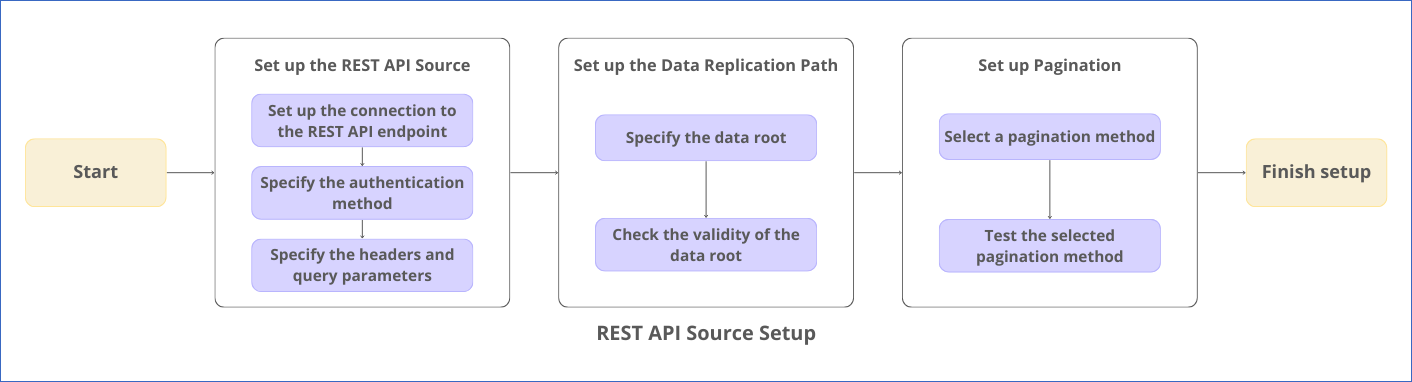
The following image illustrates the key steps that you need to complete to configure REST API as a Source in Hevo:
Prerequisites
-
The REST API endpoint, or the location from where data is to be ingested, is available.
-
You have registered the app for Hevo in your REST API Source if you want to use OAuth 2.0 for authentication. Read your Source API documentation for the steps to do this.
Note: It is recommended to add https://<your-hevo-region>.hevodata.com/rest-api/oauth as the redirect URL while registering your app. Replace the placeholder value with your Hevo region. For example, <your-hevo-region> with asia if your Hevo region is Asia.
-
The credentials, such as a username and password or an API key, to authenticate Hevo’s connection with your REST API Source are available. You can obtain these from your Source administrator or generate them. Read your Source API documentation for more information.
-
You have a basic understanding of JSONPath and JSONPath expressions.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo, to create the Pipeline.
Configuring REST API as a Source
Perform the following steps to configure REST API as a Source in Hevo:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select REST API.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
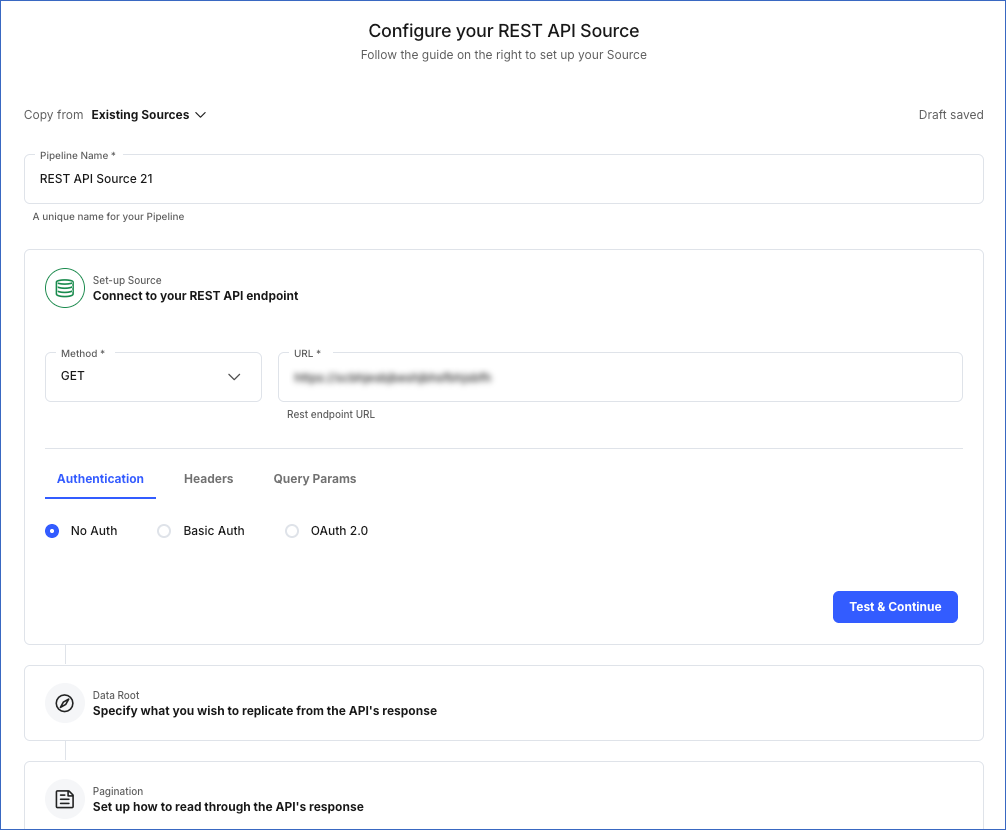
On the Configure your REST API Source page:
-
Specify a unique Pipeline Name, not exceeding 255 characters.
-
Specify the data root, or the path, from where you want Hevo to replicate the data.
-
Select the pagination method to read through the API response. Default selection: No Pagination.
-
-
Click Finish Setup and proceed to set up the Destination.
1. Set up the REST API Source
To allow Hevo to ingest data from your REST API Source in the Set-up Source section, you must:
-
Specify the authentication method. Default selection: No Auth.
-
Click Test & Continue to ensure that your connection is set up correctly. Next, proceed to set up the Data Root.
1.1 Set up the connection to your REST API Source endpoint
Perform the following steps to connect to your REST API endpoint:
-
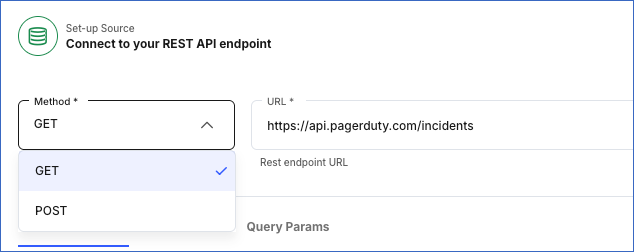
Select the Method for making API requests:
-
GET (Default): The HTTP method for requesting data from an API endpoint.
-
POST: The HTTP method for sending data to an API endpoint.
-
-
Specify the complete URL of your REST API endpoint. For example, https://slack.com/api/users.list.
-
If you selected the POST method, specify the Request Body, which contains the data to be sent to your API endpoint. Else, skip to setting up the authentication method.
The request body must be a valid JSON or Form Data in a key-value pair format. For example, the request body in the image below is in JSON format and contains the data for creating a PagerDuty incident.
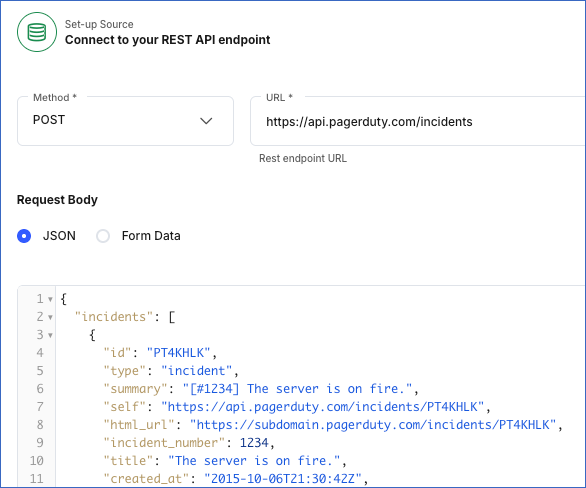
1.2 Specify the authentication method
Select one of the following methods to authenticate Hevo and authorize it to ingest data from your REST API Source:
-
No Auth (Default): This is the default selection. You can leave it unchanged if your REST API Source does not require any authentication or authenticates using credentials received in custom headers.
-
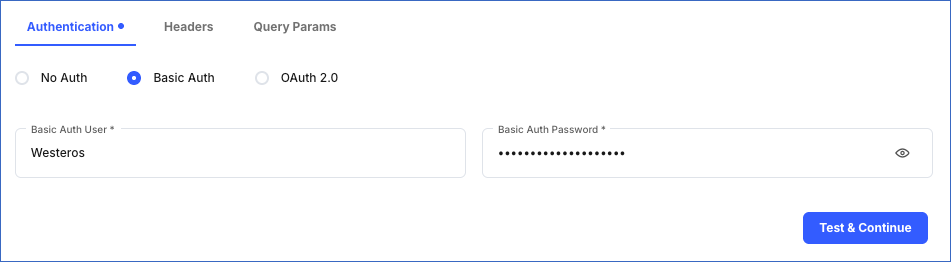
Basic Auth: This method uses HTTP Basic Authentication, where authentication is done via a username and password. To set up Basic Auth, specify the following:
-
Basic Auth User: Your API username or API key.
-
Basic Auth Password: Your API password or API secret.
-
-
OAuth 2.0: This method uses the Open Authorization protocol, where authentication takes place via an exchange of tokens.
Note: Hevo supports only the Authorization Code grant type with the OAuth 2.0 authentication method. A grant type is used by an app to get the access token.
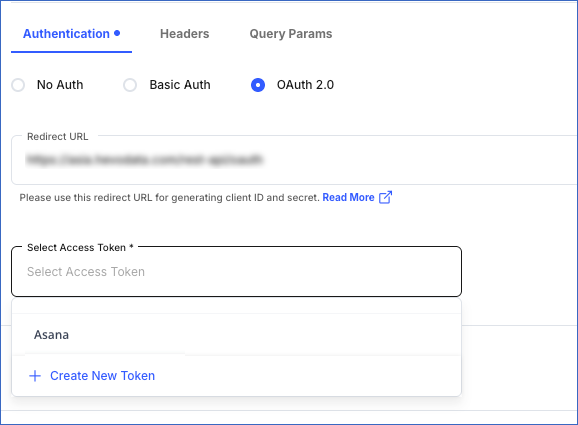
To set up OAuth2.0, specify the following:
-
Redirect URL: The URL to which the Source API authorization server directs Hevo after authorizing the app you registered for Hevo. This URL must match the one you provided while registering your app. Default value: https://<your-hevo-region>.hevodata.com/rest-api/oauth. For example, https://in.hevodata.com/rest-api/oauth.
-
Select Access Token: The access token used by Hevo to make API requests. Select an existing token for your Source from the drop-down list. For example, Asana, as seen in the image above.
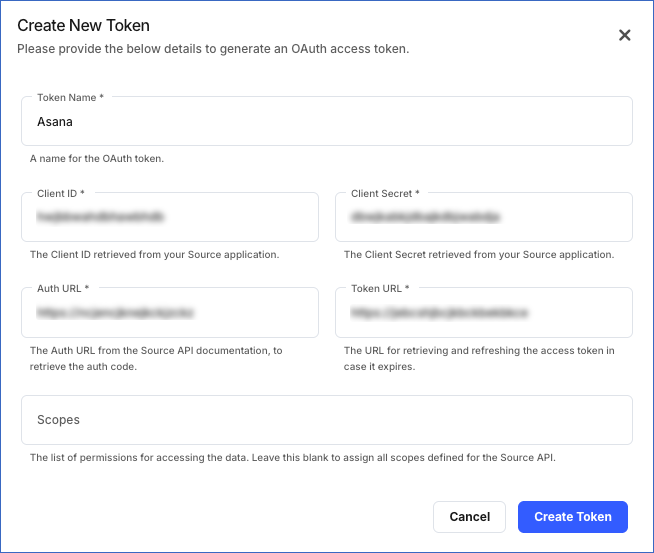
You can also create a token at this time. To do this, click + Create New Token, and in the Create New Token pop-up window, specify the following:
-
Token Name: A unique name for the access token.
-
Client ID: The ID assigned by your REST API Source to uniquely identify the app registered for Hevo.
-
Client Secret: The secret key associated with the client ID of your app registered for Hevo.
-
Auth URL: The URL of the Source API authorization server from where your app retrieves the authorization code.
-
Token URL: The URL of the Source API authentication server where your app exchanges the retrieved authorization code for an access token.
-
Scopes: A comma or space-delimited list of permissions that you want to grant Hevo for accessing your Source data. You can leave this field blank to assign all the scopes required by the Source API to the access token. Read your Source API documentation for information on the list format and the supported OAuth 2.0 scopes.
-
-
1.3 Specify the headers and query parameters
To provide any additional information required by your REST API Source, you can use:
-
Headers: Headers are a part of the HTTP request and provide metadata about the request or the request body. These contain the additional information required by an API to complete the call and are given as key-value pairs.
For example, specifying Authorization as the key and the token as the value for authorization or the email address of a user in the From key.
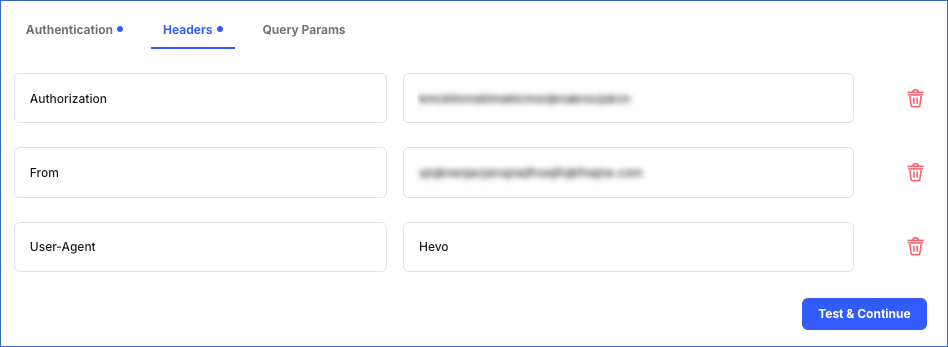
-
Query Params: Query parameters are a part of the URL in the HTTP request and can be used to filter, sort, or paginate the API results. These are appended to the URL after a question mark ( ? ) and are usually given as key-value pairs. Hevo supports the following types of query parameters:
-
Text: A static query parameter.
-
Key: The name of the parameter.
-
Value: The value of the parameter.
For example, consider the API endpoint https://api.thedogapi.com/v1/images/search that, by default, returns a single image. Now, if you want the API to return ten images, you can specify the key as limit and the value as 10.

-
-
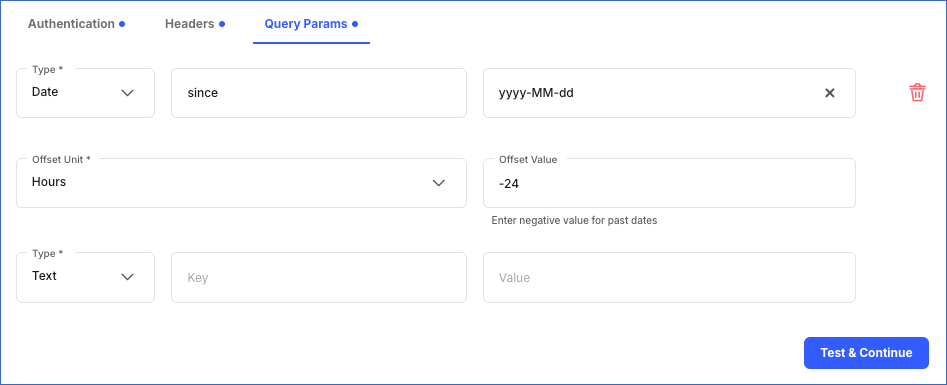
Date: A dynamic Date type query parameter.
-
Key: The name of the parameter.
-
Format: The string value describing the pattern in which the date must be generated. Select a format from the drop-down list.
Note: Hevo generates DateTime values according to Java’s SimpleDateFormat.
-
Offset Unit (Optional): The unit in which the DateTime value should be generated. Select a unit from the drop-down.
-
Offset Value (Optional): A numerical value for the selected unit. If you want to generate a date in the past, provide a negative offset value. A positive offset value generates future date times.
The Offset Unit and Offset Value are used together to generate a DateTime value relative to the time at which the API call is made. For example, suppose you want to fetch the incidents that were reported only in the past 24 hours. For this, you need to generate a DateTime that is 24 hours ago. To do so, provide the Offset Unit as Hours and the Offset Value as -24.
-
-
2. Specify the data replication path
You can direct Hevo to the element in the API response from where you want to fetch data. For this, in the Data Root section, you must:
-
Specify the data root and check its validity.
-
Click Continue and proceed to set up pagination.
Specify the Data Root
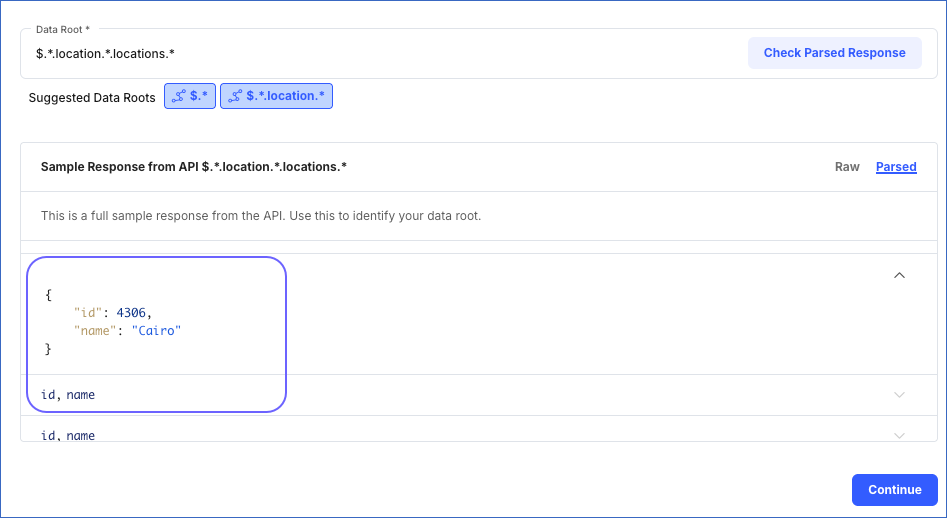
The Data Root is the JSONPath expression for the element in the API response from where you want to replicate data. Hevo suggests possible data roots based on the response received from the URL specified in the connection settings. You can select a suggested data root or provide one of your own. In the latter case, you must check the validity of your data root. To do this, click Check Parsed Response to view the parsed response.
By default, the Data Root field displays the first suggested data root and the parsed response for it in the Sample Response from API section. For example, the image below shows the first suggested data root, $.*, and the parsed response for it.
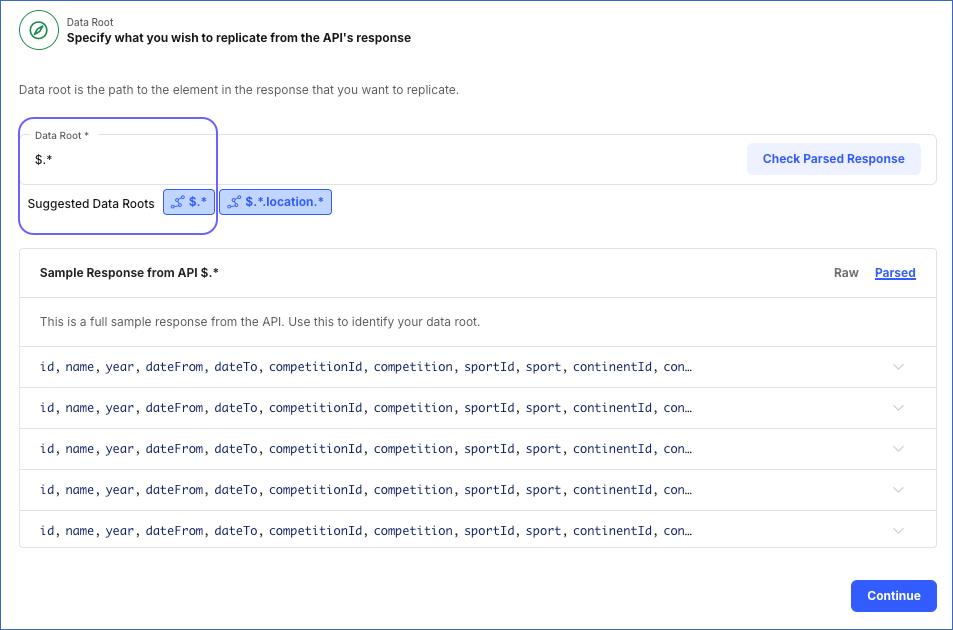
Note: The data root can contain only a JSONPath expression that returns an array or an object, and each element of the data root should return a JSON object. Read JSONPath Expression Examples for more information on writing valid expressions.
Sample Response from API: A view-only field that displays a sample of the response from the API. Hevo shows the following types of responses:
-
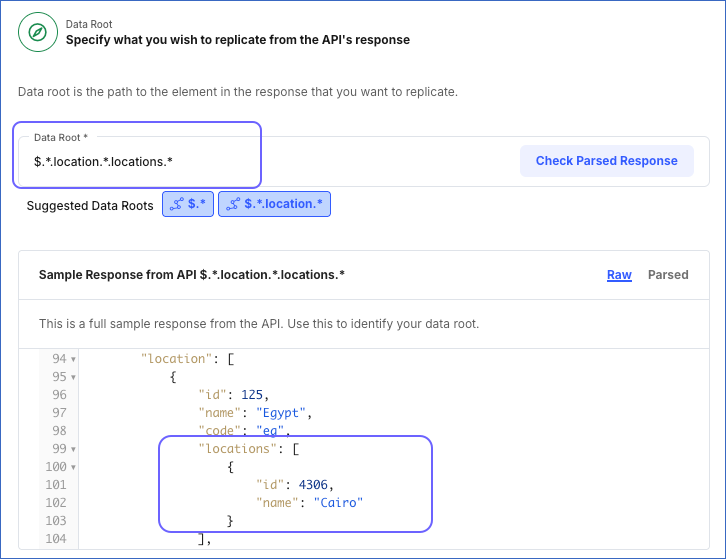
Raw: This displays the API response in JSON format. Hevo suggests data roots from this response. You can also use this response to derive an alternate data root.
For example, in the image below, the Hevo-suggested data roots are $.* and $.*.location.* and $.*.location.*.locations.* is the alternate data root.
-
Parsed: This displays the API response parsed based on the data root specified above. If the API response cannot be parsed as per the selected data root, Hevo displays an error.
For example, the image below displays the parsed response for the $.*.locations.*.locations.* data root.
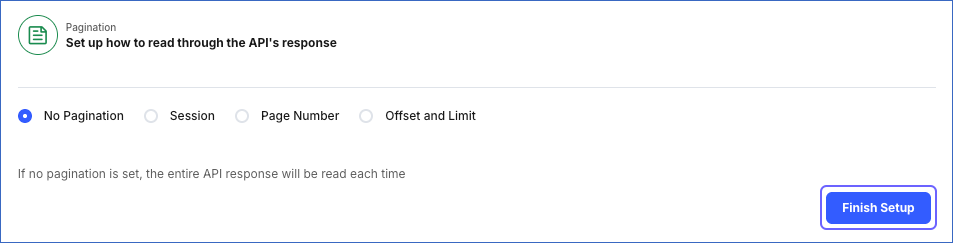
3. Set up Pagination
You can set up pagination to enable Hevo to read through long API responses in smaller chunks. For this, in the Pagination section, select from one of the following pagination methods:
| Pagination Type | Description |
|---|---|
| No Pagination (Default) | This option does not require any setup. Use this when your Source does not paginate data. |
| Session | Use this option when your Source paginates data using pointers or cursors. |
| Page Number | Use this option when your Source paginates data using page numbers. |
| Offset and Limit | Use this option when your Source paginates data using an offset and a limit. |
For all pagination options except No Pagination, you must check the API response to ensure that it is as expected. If you are unsure of the pagination option supported by your Source API, refer to its documentation, or contact the API developer.
Note: If you set up pagination, Hevo stops calling the API when the current API response does not contain information for fetching the next set of records or returns zero results.
No Pagination
Hevo attempts to fetch the entire result set of the API in a single call. However, depending on the way pagination is implemented within the API, the complete response may be fetched as a single page or divided into multiple pages. In the latter case, you need to select a different pagination option to retrieve the entire result set.
For example, consider a REST API that fetches a list of 1000 books and their reviews in a single call. If you configure this API as a Source with no pagination, then, in each Pipeline run, the API fetches the details of all the 1000 books. Now, suppose the Source has the data of 3000 books. Since the API only gets 1000 records in a single call, with no pagination, Hevo fetches the same list of 1000 books in every call. You would need to select a different pagination option to fetch the remaining 2000 records.
Hevo imposes no limit on the payload size sent or received by a REST API Source configured with no pagination. However, it is recommended to use the pagination method supported by your Source to limit the response size, especially while testing the pagination method. Additionally, there may be restrictions imposed by the APIs, the HTTP clients, or the web servers hosting the API endpoints.
For example:
-
A web server such as Apache allows a payload size of 2 GB.
-
Google’s Photo APIs allow photos with a maximum file size of 200 MB.
Session-based Pagination
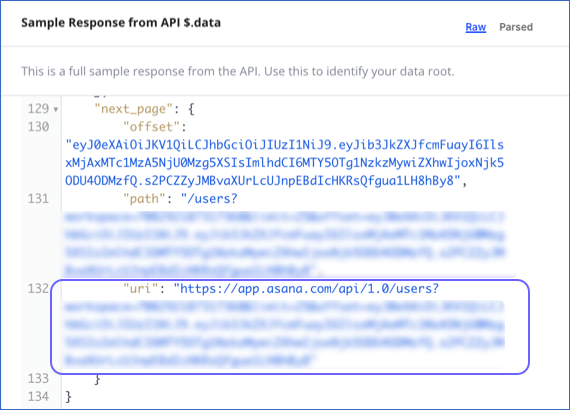
In session-based pagination, one of the parameters in the API response serves as a pointer to the next set of records. For example, in the image below, the parameter next_page.uri contains this pointer.
The next page pointer can be derived in one of the following ways:
-
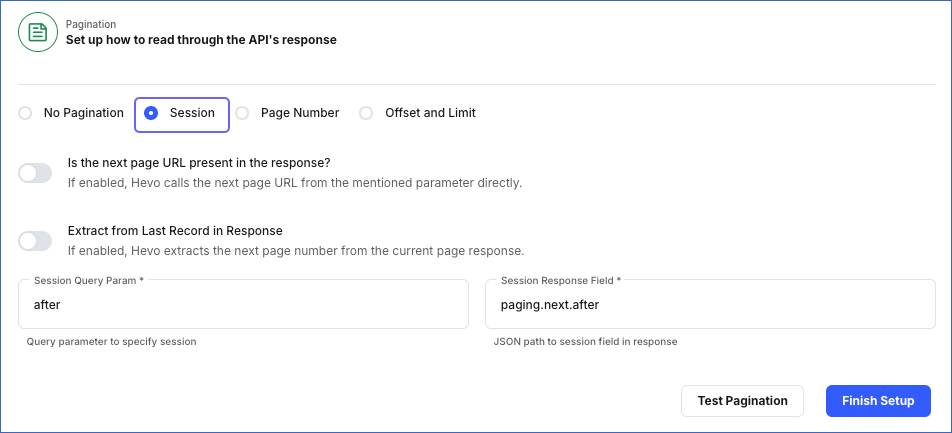
Specifying Query-based parameters: This is the default method whereby the next page is retrieved using query parameters. To set this up, specify the following:
-
Session Query Param: The name of the query parameter that Hevo appends to the URL for fetching subsequent pages from the second call onwards.
-
Session Response Field: The JSONPath expression for the field containing the pointer to the next set of records.
-
-
Specifying URL-based parameters: In this method, the next page is retrieved from a URL. To set this up:
-
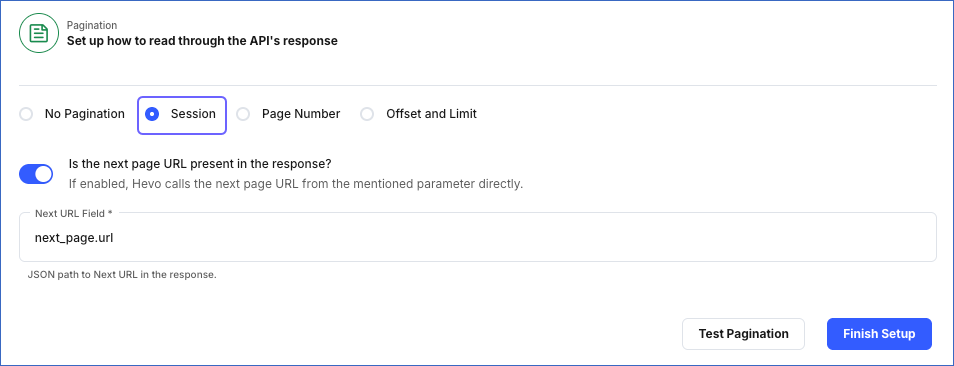
Enable the Is the next page URL present in the response? option. Hevo extracts the URL to the next page from the specified parameter.
-
In the Next URL Field specify the JSONPath expression for the field that contains the URL for the next set of records. You can find this in the API response.
-
-
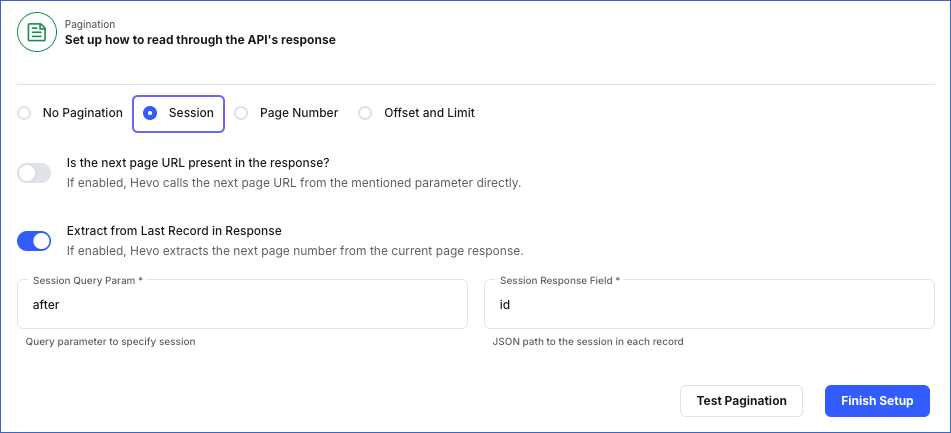
Specifying Field-based parameters: In this method, the next page is retrieved from a field in the last record of the current API response. To set this up:
-
Enable the Extract from Last Record in Response option. Hevo extracts the pointer to the next page from a field in the last record.
-
In the Session Query Param, specify the name of the query parameter that Hevo must append to the URL for fetching subsequent pages from the second call onwards.
-
In the Session Response Field, specify the JSONPath expression of the field that contains the value from where Hevo must start fetching the next set of records.
Note: When you select this option, the JSONPath expression for the Session Response Field must be relative to the object being fetched.
For example, suppose the API response contains a field, id, used to identify each record. And, the after field in the last record holds the information for the next set of records. Then, to retrieve all the pages in the API response, you must specify the Session Query Param as after and the Session Response Field as id. With these settings, when Hevo fetches the after field, it uses the value in the id field and picks records for the next page starting from that value.
-
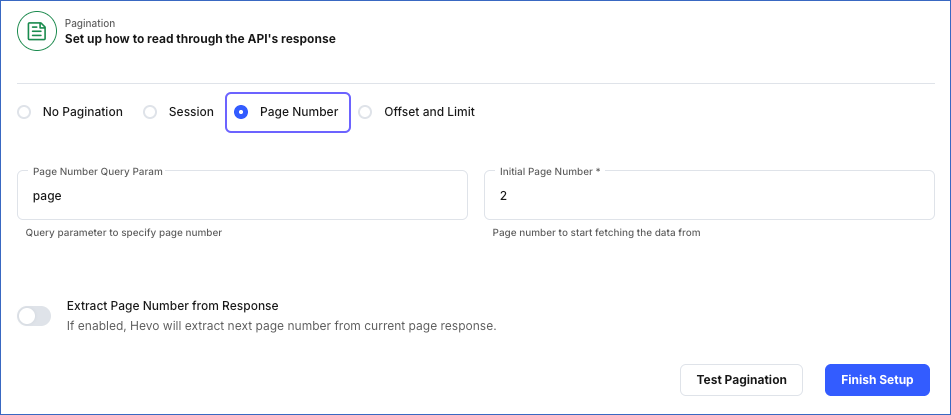
Page number-based Pagination
Page number-based pagination works through a page number, either provided by you or extracted from the API response. To set this up, specify the following:
-
Page Number Query Param: The name of the query parameter that Hevo appends to the URL to specify the page number.
-
Initial Page Number: The value of the page number in the API response from which Hevo must fetch records. It increments the page number for each call until the API stops returning results. Default value: 1.
-
Extract Page Number from Response: If enabled, Hevo extracts the page number from the response of the API call as per the settings you provide.

-
Page Response Field: The JSONPath expression to the field that contains the next page number.
-
Increment for next page: If enabled, Hevo increments the page number value when it makes the subsequent API call.
-
Offset and Limit-based Pagination
Offset-based pagination uses a numerical value to determine the starting point for fetching data. This value defines the number of records to be skipped each time from the API response. To set this up, specify the following:

-
Offset Query Param: The name of the query parameter that specifies the offset. Hevo appends this parameter to the URL. You can find this name in the API response.
-
Offset Starting Value: The value for the offset parameter from which the API starts fetching data.
-
Offset Increment Value: The number of records that the API must skip before it starts to fetch data from the second call onwards.
-
Limit Query Param: The name of the query parameter that Hevo appends to the URL to limit the number of records that the API fetches per page.
-
Limit Initial Value: The number of records fetched by the API on each call.
For example:
Suppose an API result set contains 100 records. If you want to generate a sample data set that contains the first five records out of every 20 records, set the parameters as follows:
-
Offset Query Param: offset
-
Offset Starting Value: 0
-
Offset Increment Value: 15
-
Limit Query Param: limit
-
Limit Initial Value: 5
With this configuration, the API:
-
Starts from an offset of 0, indicating the first record.
-
It fetches the first five (0-4) records.
-
Next, it skips 15 records (5-19). The offset is now 20.
-
Again, it fetches five records (20-24) and skips the next 15 (offset is now 40), and so on.
-
It repeats this pattern on every call to fetch five records every 20 until it receives zero results.
Test the pagination method
Perform the steps in this section if you set up a pagination method other than No Pagination.
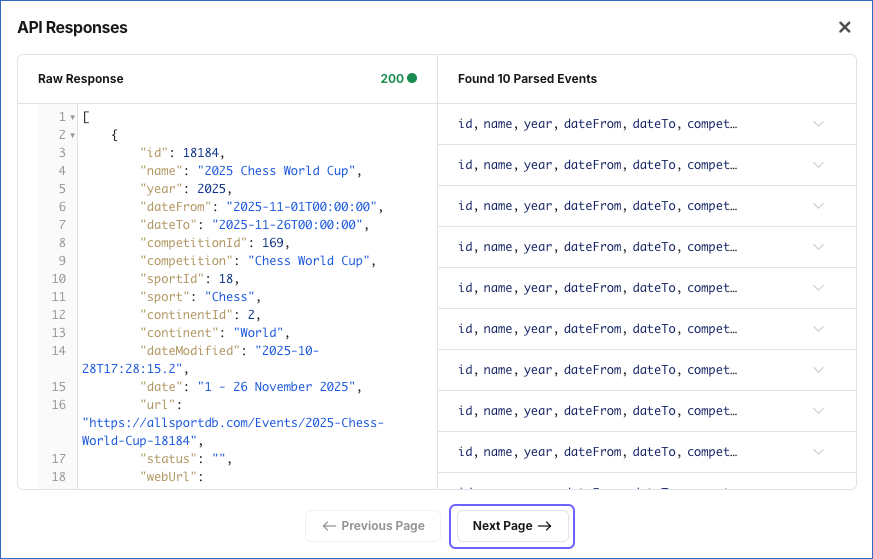
To verify the pagination settings and check the API response:
-
In the Pagination section, specify the required parameters to set up the selected pagination method. For example, consider the following settings:

-
Pagination type: Page Number
-
Page Number Query Param: page
-
Initial Page Number: 1
-
-
Click Test Pagination to see the API response paginated as per the settings you specified. Click Next Page to retrieve the page(s) in sequence until you reach the last page.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 15 Mins | 5 Mins | 168 Hrs | 1-168 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
- For REST API Sources, it is not possible to identify new or changed records from the API response. As a result, Hevo cannot perform only incremental ingestion. Thus, when Hevo reaches the end of the data on the last page of the API response, it flushes the offset that it maintains to track data. In the next Pipeline run, Hevo begins ingesting data from the start. This mechanism allows it to fetch the new and updated data from the Source.
Limitations
-
Hevo needs the client ID and client secret to be manually entered when creating the OAuth access token. These credentials are then sent as form fields in the request body during the token exchange. However, Hevo does not support token exchange flows that require the client ID and client secret to be sent in the Authorization header using base64 encoding. As a result, OAuth token creation may fail for REST API Sources that mandate base64-encoded credentials in the header.
-
Hevo does not support session-based pagination for REST API Sources that return an empty string in the next page pointer to signal the end of data. In these cases, Hevo cannot detect the last page of the API response and resets the offset it maintains to track data. As a result, all data from the beginning is re-ingested in the next Pipeline run. This behavior may lead to repeated ingestion and high Event consumption.
-
By default, Hevo uses the __hevo_id metadata column as the primary key to load data from your REST API Source to the Destination. As a result, you may see duplicate data in the Destination if you have mutable data in your Source. To avoid this, you can set another column as the primary key.
-
Hevo accepts only JSON content type in the response from your REST API Source for the requests that it makes. If your Source API returns a response in any other type, such as CSV, you may see the HTTP Status: 406 error.
-
During Source configuration, Hevo waits up to 60 seconds for a response from the REST API endpoint. If the API does not respond within this timeframe, the request times out with a 504 status code, and the Source configuration fails.
-
Hevo’s REST API connector does not support API chaining. In this technique, multiple API calls are used in sequence to achieve a specific task. The response of the last API call feeds the next call, and so on.
For example, you cannot use the bearer token received in the response of the first API request to authenticate the subsequent API request.
-
In Hevo, the request body specified for a POST method cannot be edited during a Pipeline run. As a result, pagination is not supported if the REST API Source uses parameters in the request body or headers for pagination. Hevo can paginate the API response received from the POST method only when the REST API Source accepts the pagination method information specified through Query Params.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-13-2025 | NA | Updated the document as per the latest Hevo UI. |
| Sep-18-2025 | NA | Updated section, Configuring REST API as a Source as per the latest UI. |
| Jul-28-2025 | NA | Added a limitation about unsupported authorization header format for OAuth. |
| Jul-14-2025 | NA | - Added the Source Considerations section. - Added a limitation about an empty string in the next page pointer. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jun-16-2025 | NA | Updated section, Limitations to add a limitation about API request timeout during Source configuration. |
| Apr-14-2025 | NA | Added a limitation about pagination being supported only through query parameters for POST method. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Dec-11-2023 | 2.18.1 | - Revamped the page content for clarity and coherence. - Merged the section, Troubleshooting the Rest API into the Troubleshooting the REST API Setup page. |
| Nov-28-2023 | 2.18 | Updated section, Configuring REST API as a Source to add information about the No Auth option. |
| Jul-27-2023 | NA | Added limitations about JSON content type and authorization code. |
| Dec-19-2022 | 2.04 | Updated the section, Configuring REST API as a Source to add information about enhanced data root auto-suggestion functionality. |
| Nov-23-2022 | NA | Added section, Limitations. |
| Nov-11-2022 | NA | Updated section, Troubleshooting the Rest API to include the troubleshooting scenario for Error 404. |
| Sep-05-2022 | NA | Updated the See Also section to: - Add a reference to the REST API FAQs page. - Remove the reference to the pagination-related FAQ. |
| Aug-24-2022 | 1.96 | Updated section, Configuring REST API as a Source to add information about data root auto-suggestion by Hevo. |
| May-10-2022 | 1.88 | - Added information about authentication using OAuth 2.0 protocol. - Removed section, Testing the API Response. |
| Dec-20-2021 | 1.78 | Updated the screenshot in step 4 of the section, Configuring REST API as a Source to to reflect the latest UI changes. |
| Nov-09-2021 | 1.75 | Updated: - Step 4 in the section, Configuring REST API as a Source to explain the API behavior in case No Pagination is selected. - The See Also section to add a link to a pagination-related FAQ. |
| Oct-25-2021 | NA | Added the Pipeline frequency information in the Data Replication section. Added the See Also section. |
| Oct-04-2021 | 1.73 | Updated step 4 in the section, Configuring REST API as a Source to to add: - A new pagination option, Offset and Limit. - An option Is the next page URL present in the response? in Session-based pagination. - Screenshots for each pagination option. |
| Sep-20-2021 | 1.72 | Updated step 4 in the section, Configuring REST API as a Source to add: - The Request Body property for the POST method. - A note in the Data Root property about expected JSONPath expressions. |
| Apr-06-2021 | 1.60 | Added the following sections: - Testing the REST API. - Troubleshooting the REST API. Updated the section Configuring REST API as a Source to include the field Extract from last record in response. |