On This Page
Salesforce is a cloud-based Customer Relationship Management (CRM) platform that allows businesses to effectively handle customer interactions, streamline sales and marketing processes, and analyze the data received from it. It also allows you to create customized applications as per your business requirements that can help enhance customer relationships.
Hevo uses Salesforce’s Bulk API 2.0 to replicate data from your Salesforce applications to the Destination database or data warehouse. To replicate this data, you need to authorize Hevo to access data from the relevant Salesforce environment.
If you have an existing Pipeline that uses Salesforce Bulk API V1, you can upgrade it to V2. To do so, in the banner displayed in on the Pipeline Overview page, click UPGRADE PIPELINE.
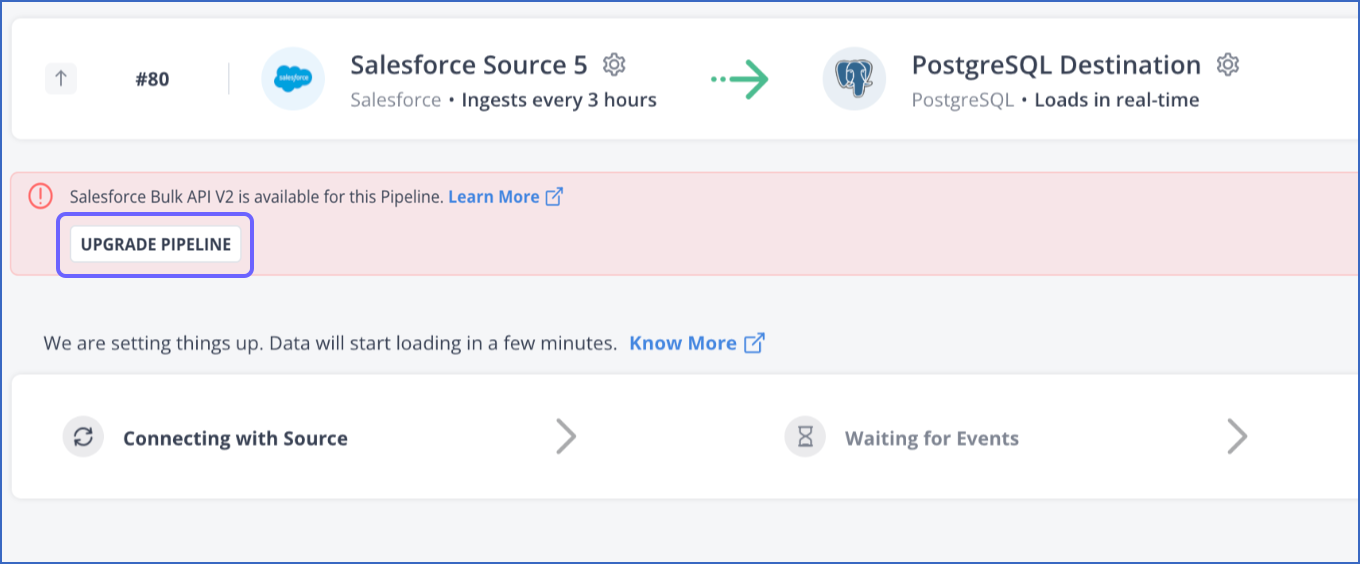
All Events loaded using Salesforce’s Bulk API V2 are billed post-upgrade.
Salesforce Environments
Salesforce allows businesses to create accounts in multiple environments, such as:
-
Production: This environment holds live customer data and is used to actively run your business. A production organization is identified by URLs starting with https://login.salesforce.com.
-
Sandbox: This is a replica of your production organization. You can create multiple sandbox environments for different purposes, such as one for development and another for testing. Working in the sandbox eliminates risk of compromising your production data and applications. A sandbox is identified by URLs starting with https://test.salesforce.com.
Prerequisites
-
An active Salesforce production or sandbox account from which data is to be ingested exists.
Note: Hevo supports connecting to Salesforce accounts only through OAuth. Single sign-on (SSO) is not supported.
-
History tracking is enabled to track history objects.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo to create the Pipeline.
Configuring Salesforce Bulk API V2 as a Source
Perform the following steps to configure Salesforce Bulk API V2 as the Source in your Pipeline:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Salesforce Bulk API V2.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
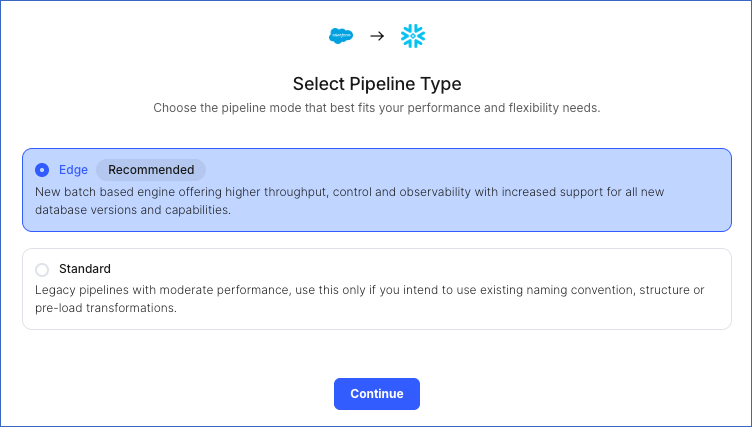
On the Select Pipeline Type page, choose the type of Pipeline you want to create based on your requirements, and then click Continue.
-
If you select Edge, read Salesforce Bulk API V2 to configure your Edge Pipeline.
-
If you select Standard, skip to step 6 below.
This page appears only if all the following conditions are met:
-
The selected Destination type is supported in Edge.
-
Your Team was created before September 15, 2025, and has an existing Pipeline created with the same Destination type.
For Teams that do not meet the above criteria:
-
If the selected Destination type is supported in Edge, you can proceed to create an Edge Pipeline. Read Salesforce Bulk API V2 to configure your Edge Pipeline.
-
If the Destination type is not supported, you can proceed to create a Standard Pipeline.
-
-
On the Configure Your Salesforce Account page, do one of the following:
-
Select a previously configured account and click Continue.
-
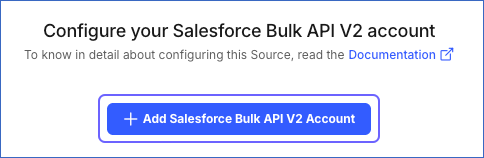
Click + Add Salesforce Bulk API V2 Account and perform the following steps to configure an account:
-
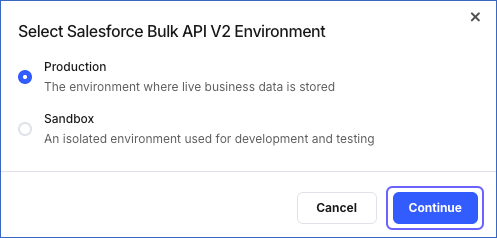
Select the environment from which Hevo must ingest the data, and click Continue.
-
Log in to your Salesforce account.

Note: Hevo supports connecting to Salesforce accounts only using OAuth. SSO-enabled accounts are not supported.
-
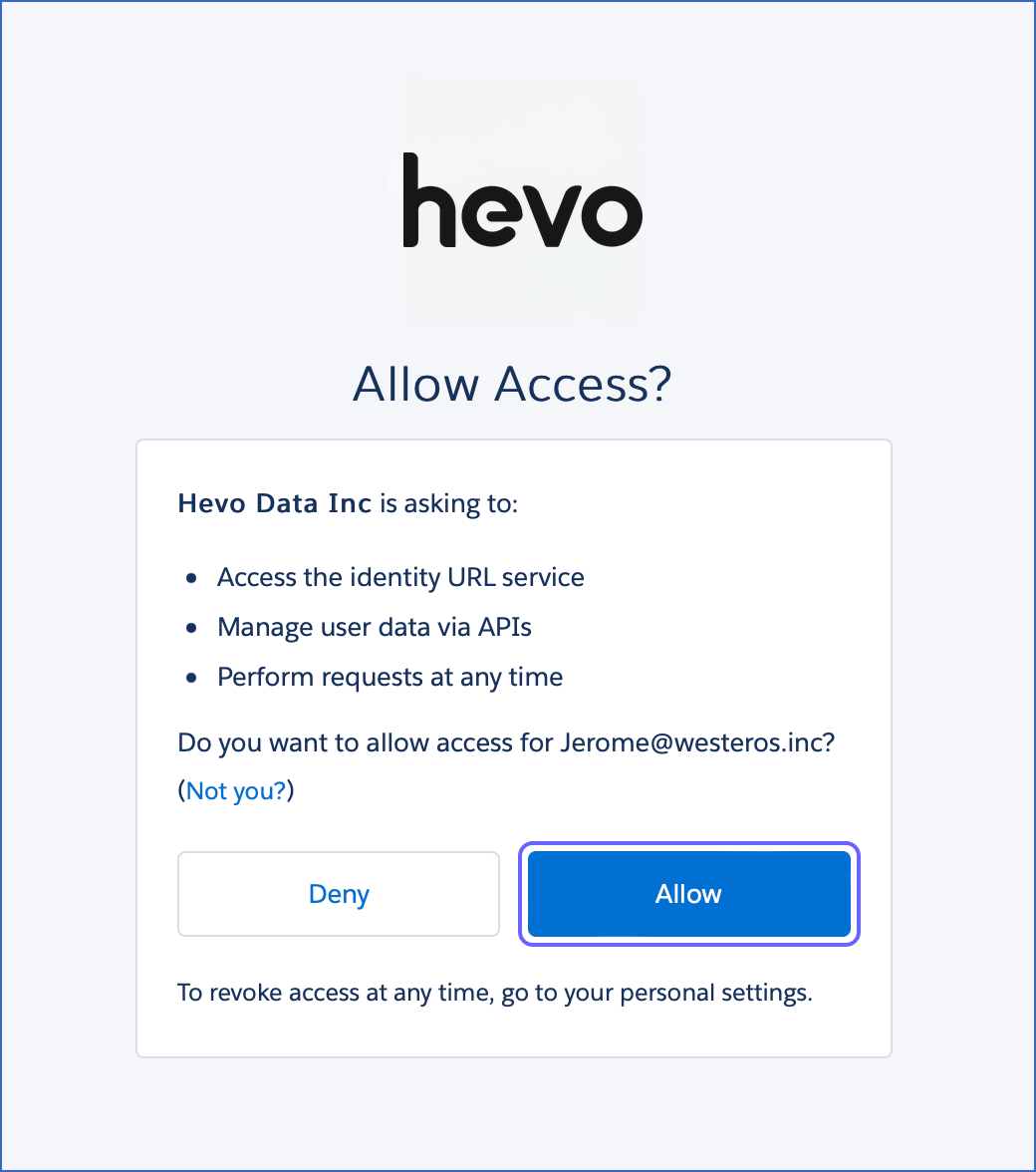
Click Allow to authorize Hevo to access data from your Salesforce account.
-
-
-
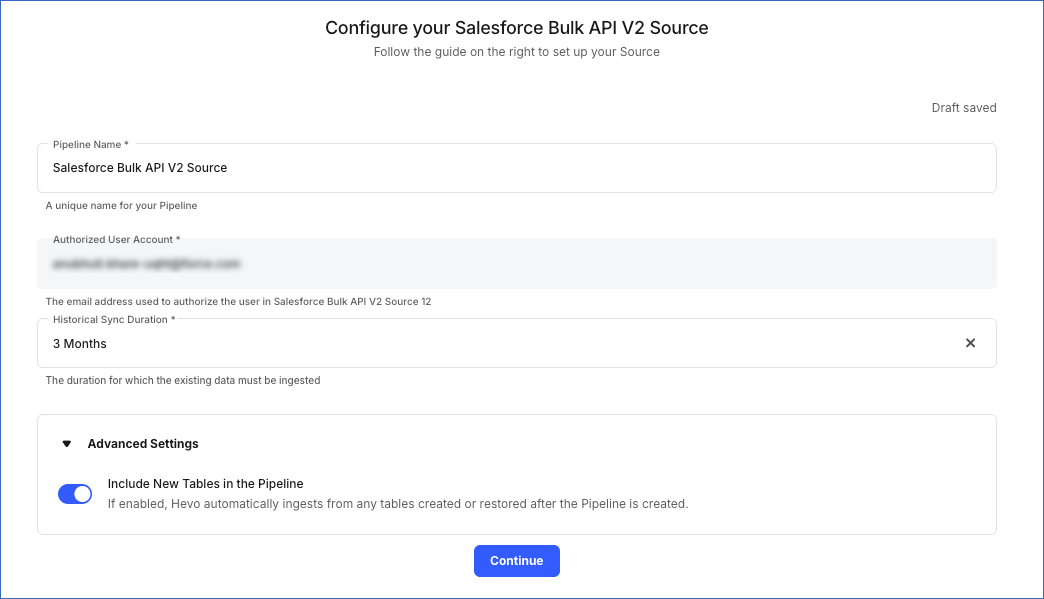
On the Configure your Salesforce Bulk Api V2 Source page, specify the following:
-
Pipeline Name: A unique name for the Pipeline, not exceeding 255 characters.
-
Authorized Account (Non-editable): The email address you selected earlier when connecting to your Salesforce account.
-
Historical Sync Duration: The duration for which you want to ingest existing data from the Source. This cannot be changed after the Pipeline is created. Default duration: 3 Months.
Note: If you select All Available Data, Hevo ingests all the data available in your Salesforce account since January 01, 1970.
-
Advanced Settings:
-
Include New Tables in the Pipeline:
If enabled, Hevo automatically ingests data from objects created in the Source post-Pipeline creation.
If disabled, Hevo does not ingest data from new objects. They are added in the SKIPPED state to the Objects list on the Pipeline Overview page. You can update their status to INCLUDED to ingest data.
You can change this setting later.
Note:
-
When a new object is included in the Pipeline for ingestion and the RUN NOW action is triggered for that object, Hevo fetches only the incremental data for it. The historical load begins in the next Pipeline run.
-
If a previously deleted object that was marked as ACTIVE in the Pipeline is re-created in the Source, Hevo does not consider it as a new object. Instead, the object is added in the ACTIVE state to the Objects list on the Pipeline Overview page, and Hevo automatically ingests data from that object.
-
-
-
-
Click Continue.
-
Proceed to configuring the data ingestion and setting up the Destination.
Note: While configuring the Destination, Hevo recommends that you add a Destination table prefix to prevent data from being loaded to the tables created using Salesforce as the Source. For example, salesforce_bulk_v2.
Data Replication
| For Teams Created | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|
| Before Release 2.21 | 3 Hrs | 15 Mins | 24 Hrs | 1-24 |
| After Release 2.21 | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3, but not 1.5 or 1.75.
Hevo loads data for all the supported objects from your Salesforce account. Refer to section, Data Model for the list of supported objects.
-
Historical Data: The first run of the Pipeline ingests historical data for the selected objects on the basis of the historical sync duration specified at the time of creating the Pipeline and loads it to the Destination. Default duration: 3 Months.
-
Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency in Full Load or Incremental mode, as applicable.
Note: To prevent excessive Event consumption, Hevo ingests data from Full Load objects once every seven days.
Schema and Primary Keys
Hevo uses the following schema to upload the records in the Destination database. For a detailed view of the objects, fields, and relationships, click the ERD.

Data Model
Hevo uses the following data model to ingest data from your Salesforce account:
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
During incremental loads, derived or calculated fields that obtain their values from other fields or formulas are not updated in the Destination. This implies that even if the values change as a result of a formula or the original field being modified, these fields remain unchanged.
In Salesforce, whenever any change occurs in an object, its
SystemModStamptimestamp field is updated. Hevo uses thisSystemModStampfield to identify Events for incremental ingestion. In case of derived fields, a change in the formula or the original field does not affect the object’sSystemModStampvalue. As a result, such objects are not picked up in the incremental load. However, if another field in the object is updated simultaneously, then the subsequent incremental load picks up the derived field updates also.As a workaround, Hevo automatically restarts the historical load for all such objects in your Pipelines every 20 days by default. You can contact Hevo Support to change this historical load frequency. Additionally, you can also restart the historical load for the object manually. If the object was created after Pipeline creation, you need to restart the historical load at the Pipeline level.
-
Hevo cannot ingest incremental data for back-dated records, as Salesforce does not update the
SystemModStampcolumn for such records. Hevo uses this column to identify Events for incremental ingestion.As a workaround, you can restart the historical load for the object.
-
Some Salesforce objects, such as EntityDefinition, do not contain the
SystemModStamptimestamp field. As a result, Hevo cannot capture data changes for such objects and marks them as Full Load objects. For these objects, Hevo replicates the entire dataset in each ingestion. Additionally, Hevo cannot differentiate between historical and incremental data, so all consumed Events are marked as billable. -
The
SystemModStamptimestamp field tracks changes made to the entire object, rather than individual columns within a record. Hence, even if you skip the frequently updated columns for an object from the Schema Mapper, Hevo picks up the object for ingestion if itsSystemModStamptimestamp field has changed since the last ingestion. -
When a record from a replicable object is deleted in Salesforce, the IsDeleted column for it is set to True. Salesforce moves the deleted records to the Salesforce Recycle Bin, and they are not displayed in the Salesforce dashboard. Now, when Hevo starts the data replication from your Source, using either the Bulk APIs or REST APIs, it also replicates data from the Salesforce Recycle Bin to your Destination. As a result, you might see more Events in your Destination than in the Source.
-
Salesforce retains deleted data in its Recycle Bin for 15 days. Therefore, if your Pipeline is paused for more than 15 days, Hevo cannot replicate the deleted data to your Destination. Apart from this, Salesforce automatically purges the oldest records in the Recycle Bin every two hours if the number of records in the Recycle Bin exceeds the record limit for your organization, which is 25 times your organization’s storage capacity. Therefore, to capture information about the deleted data, you must run the Pipeline within two hours of deleting the data in Salesforce.
-
The maximum number of Events that can be ingested per day is calculated based on your organization’s quota of batches.
Suppose your organization is allocated a daily quota of 15000 batches per 24 hours, and each batch can contain a maximum of 10000 Events.
Then, the daily Event consumption is calculated as follows:
-
The number of batches created per object (X) = Number of Events for the Object/10000.
Note: This value, X is rounded off to the next integer.
-
And,
The total number of batches created across all objects in the Pipeline (Y) = Sum of the number of batches created for each object (ΣX).
This number, Y is the number of batches that are submitted in one run of the Pipeline. This number may vary in each run of the Pipeline and is calculated as follows:
The number of Pipeline runs in a day (Z) = 24/Ingestion frequency (in hours).
The number of batches that can be submitted in a day = 15000
Therefore,
The maximum number of batches that can be submitted in one run of the Pipeline = 15000/Z.
Example:
Suppose you have two objects containing 55800 and 25000 Events respectively, and the ingestion frequency is 12 hours. Then,
The number of batches created for object 1 (X1) = 55800/10000 = 5.58.
Therefore, six batches are created; five with 10000 Events each and the sixth with 5800 Events.
The number of batches created for object 2 (X2) = 25000/10000 = 2.5.
Therefore, three batches are created; two with 10000 Events each and the third with 5000 Events.
The total number of batches created across all objects in the Pipeline (Y) = X1 + X2 = 6 + 3 = 9.
These nine batches are submitted in one run of the Pipeline.
Now, as the Ingestion frequency is 12 hours,
The total number of Pipeline runs in 24 hours (Z) = 24/12 = 2.
And,
The maximum number of batches that can be submitted in one run of the Pipeline = 15000/2 = 7500.
Here, against the available limit of 7500 batches per Pipeline run, only 9 batches are being submitted.
Therefore, as long as
Z x Y <= 15000, you are within the daily prescribed quota. -
-
Salesforce Bulk API V2 does not support the following objects:
-
Attachment
-
ContentDocumentLink
-
ContentFolderItem
-
ContentFolderMember
-
FieldDefinition
-
FlowVersionView
-
IdeaComment
-
ListViewChartInstances
-
PlatformAction
-
SearchLayout
-
Vote
-
-
Salesforce enforces strict API usage limits based on a 24-hour window. Hevo monitors your account’s API consumption and triggers an alert when usage crosses 80% of the allocated API quota. If the quota is breached, Salesforce blocks further API calls, which may cause delays or temporary failures in your Pipeline. If you receive this alert, you can do the following:
-
Identify any third-party tools, internal scripts, or processes that might be consuming your Salesforce API quota.
-
If Hevo is running historical syncs or full data loads, consider pausing those jobs temporarily to avoid breaching the limit. Salesforce resets API limits every 24 hours. You can resume operations after the reset to prevent further interruptions.
-
If you continue to receive frequent quota warnings, contact Hevo Support.
-
-
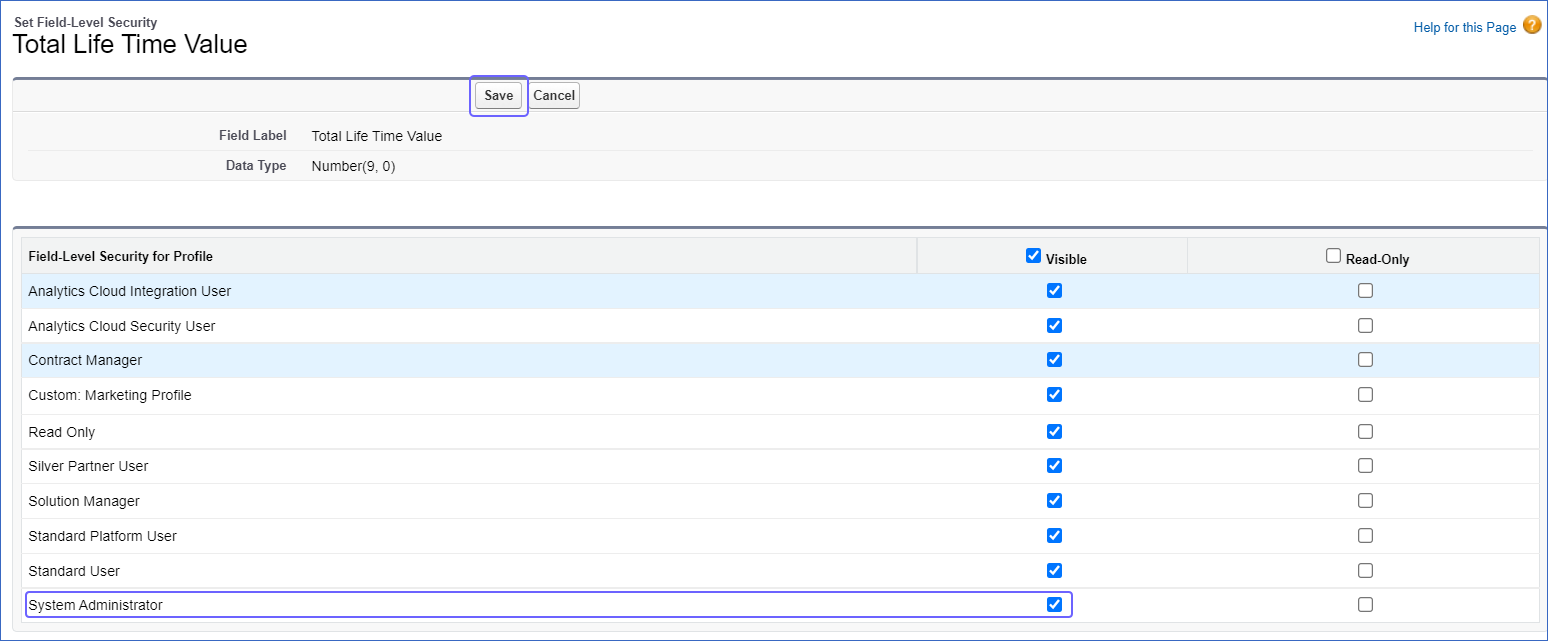
To view custom fields added to your Salesforce object, you must set the field-level security of these fields to Visible for the System Administrator profile in Salesforce. To do so:
-
Log in to Salesforce.
-
In the top right corner of the page, click the Settings (
 ) icon, and then click Setup in the drop-down.
) icon, and then click Setup in the drop-down.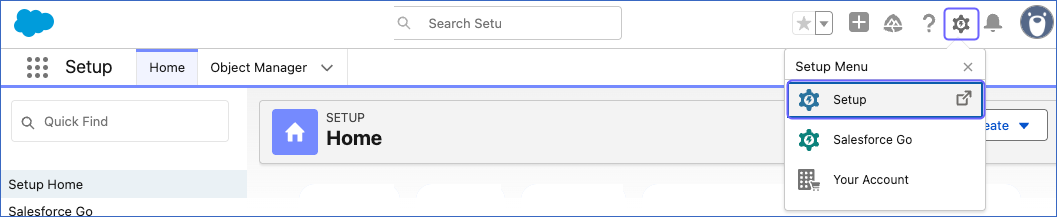
-
In the Object Manager tab, using the search bar, search for and select the object that contains your desired field. For example, Customer in the image below.

-
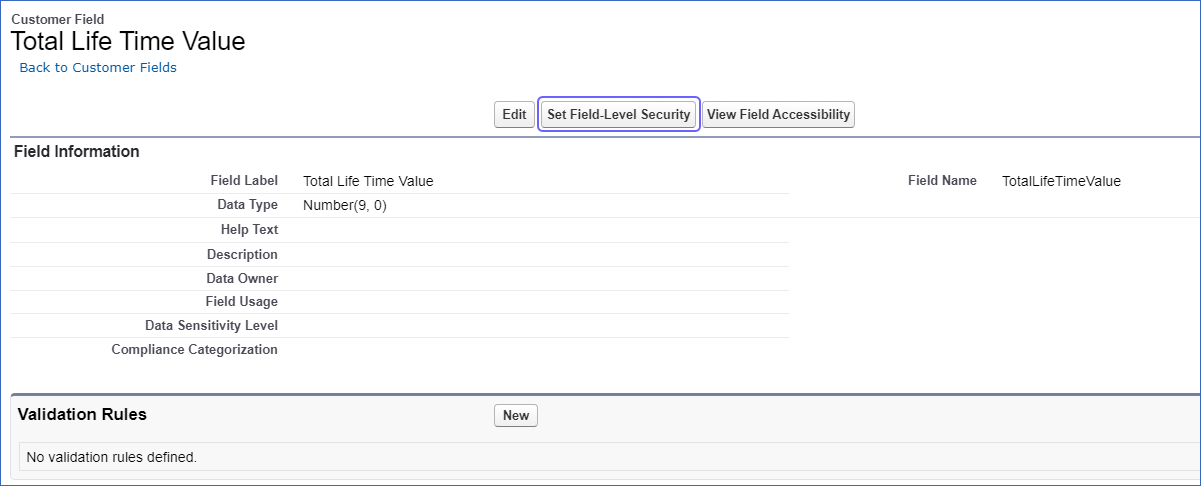
In the left panel, click Fields & Relationships and select the required field. For example, Total Life Time Value in the image below.

-
Click Set Field-Level Security.
-
Select the Visible check box for the System Administrator profile, and click Save.
-
Limitations
-
Hevo does not fetch any columns of Compound data type.
-
It is not possible to avoid loading the deleted data. Hevo loads the new, updated, and deleted data from your Salesforce account.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
-
Hevo does not capture records permanently deleted from Salesforce. Permanent deletion removes records without moving them to the Salesforce recycle bin. As a result, if a record is deleted after the ingestion, it still shows in the Destination. If you do not want to retain the deleted data in the Destination, you can truncate the affected Destination tables and manually restart the historical load for the corresponding Source objects.
-
Hevo connects to Salesforce Sources only through OAuth with a username, password, and security token. As a result, if Single Sign-On is enabled for the user, Hevo cannot connect to your Salesforce account. In such cases, you should create a dedicated user for Hevo and do the following:
-
Create a permission set and grant the user:
-
Access to all objects from where data is to be ingested
-
Ensure that Is Single Sign-On Enabled is bypassed for this user. Read Require Users to Log In with Single Sign-On (SSO) if you need assistance with checking this information.
-
Ensure that the user can log in from the appropriate Salesforce URL for your environment. For example, https://test.salesforce.com in the case of a sandbox environment.
-
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Apr-28-2026 | NA | Updated section, Configuring Salesforce Bulk API V2 as a Source to mention that the historical sync duration cannot be changed after the Pipeline is created. |
| Nov-07-2025 | NA | Updated the document as per the latest Hevo UI. |
| Nov-04-2025 | NA | Added a limitation about Hevo connecting only through OAuth to Salesforce accounts. |
| Oct-13-2025 | NA | Updated section, Configuring Salesforce Bulk API V2 as a Source to clarify when the Select Pipeline Type section is displayed during Pipeline configuration. |
| Sep-18-2025 | NA | Updated section, Configuring Salesforce Bulk API V2 as a Source as per the latest UI. |
| Jul-18-2025 | NA | Added a Source Consideration for changing the field-level security of custom fields. |
| Jul-15-2025 | NA | Updated section, Source Considerations to add information about Salesforce API usage alerts. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| May-19-2025 | NA | Added a note in the Data Replication section about ingestion from Full Load objects. |
| Apr-19-2025 | NA | Updated Source Considerations to add information about - Events consumption for Full Load objects. - Skipped columns in an object not affecting the Events consumed. |
| Apr-17-2025 | NA | Added a note in the Configuring Salesforce Bulk API V2 as a Source section about the ACTIVE objects in the Pipeline. |
| Apr-14-2025 | NA | Added a note in the Configuring Salesforce Bulk API V2 as a Source section about the Include New Tables in the Pipeline Advanced Setting. |
| Apr-11-2025 | NA | Added limitation about permanently deleted Salesforce records. |
| Feb-03-2025 | 2.32.2 | Updated the info container in the page overview to add information on upgrading Pipelines to Bulk API V2. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Mar-05-2024 | 2.21 | Updated the ingestion frequency table in the Data Replication section. |
| Sep-11-2023 | 2.16.2 | New document. |