PostgreSQL
On This Page
PostgreSQL is a powerful, open source object-relational database system that uses the SQL language combined with many features that safely store and scale complicated data workloads. PostgreSQL is compatible with all major operating systems.
Hevo can load data from any of your Pipelines into a PostgreSQL database. Follow the steps in this page to add PostgreSQL as a Destination.
If you are new to PostgreSQL, you can follow the steps listed below to install and set up a PostgreSQL instance, and then create a database to which the Hevo Pipeline must load the data. You can also create users and grant them the necessary permissions to set up and manage the PostgreSQL databases.
The following image illustrates the key steps that you need to complete to configure PostgreSQL as a Destination in Hevo:

Prerequisites
-
The IP address or hostname and port of your PostgreSQL server are available. If you do not have these details, you can obtain them from the PostgreSQL server administrator.
-
The necessary privileges are granted on the database to your database user.
-
You are assigned the Team Collaborator, or any administrator role except the Billing Administrator role in Hevo to create the Destination.
Installing PostgreSQL (Optional)
Before you can use PostgreSQL you need to install it. It is possible that PostgreSQL is already installed in the system, either because it was included in your operating system distribution or because the system administrator already installed it.
To verify if PostgreSQL is already installed, run the following command in the Terminal window:
systemctl status postgresql
The expected response when PostgreSQL is:
-
Installed:
Active: active -
Not installed:
Unit postgresql.service could not be found
If PostgreSQL is not already available, you can install it yourself. This does not require superuser (root) access.
PostgreSQL is available as binary packages for most common operating systems. This is the recommended way to install PostgreSQL. For an updated list of platforms providing binary packages, please visit the Download section on the PostgreSQL website at PostgreSQL: Downloads and follow the instructions for your specific platform.
Note: This section explains how to install PostgreSQL on a Linux machine running Ubuntu.
-
Open the Terminal window on your machine.
-
Enter the following commands:
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list' wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add - sudo apt-get update sudo apt-get -y install postgresqlThis installs the PostgreSQL server on your machine and creates a postgres user.
Creating a Database Cluster and Database (Optional)
A database cluster is a single directory where all your data is stored. You can choose the location of the directory.
Perform the following steps to create (initialize) the database cluster:
-
Log in to your PostgreSQL server as the
postgresuser created in step 1. -
Enter the following command to create the database cluster. The -D option allows you to specify where the database cluster should be stored.
$ initdb -D /usr/local/pgsql/data
Note: The initdb command attempts to create the directory you specify if it does not already exist. This fails if initdb does not have permissions to write in the parent directory. It is recommended that the PostgreSQL user own not just the data directory but its parent directory as well. If the desired parent directory does not exist, you need to create it first, using root privileges. To do this, enter the following commands:
root# mkdir /usr/local/pgsql
root# chown postgres /usr/local/pgsql
root# su postgres
$ initdb -D /usr/local/pgsql/data
When a cluster is created, a database named postgres is created by default, which is used by utilities, users, and third-party applications. You can use this database instance to set up the Destination.
Create a Database User and Grant Privileges
1. Create a database user
Perform the following steps to create the database user in your PostgreSQL database:
-
Log in to your PostgreSQL server as a Superuser using an SQL client, such as
psql. -
Enter the following command:
CREATE USER <user_name> WITH PASSWORD '<strong password>';Note: Replace the placeholder values in the command given above with your own.
2. Grant privileges to the user
-
Log in to your PostgreSQL server as a Superuser using an SQL client, such as
psql. -
Run the following commands to grant the required privileges to the database user, to create the database objects needed to load and store your data:
GRANT CREATE, CONNECT, TEMPORARY ON DATABASE <database_name> TO <database_username>; GRANT CREATE, USAGE ON SCHEMA <schema_name> to <database_username>; GRANT SELECT ON ALL TABLES IN SCHEMA <schema_name> to <database_username>;Note: Replace the placeholder values in the commands given above with your own.
Configure PostgreSQL Connection Settings
Perform the following steps to configure PostgreSQL as a Destination in Hevo:
-
Click DESTINATIONS in the Navigation Bar.
-
Click + Create Standard Destination in the Destinations List View.
-
On the Add Destination page, select PostgreSQL.
-
On the Configure your PostgreSQL Destination page, specify the following:
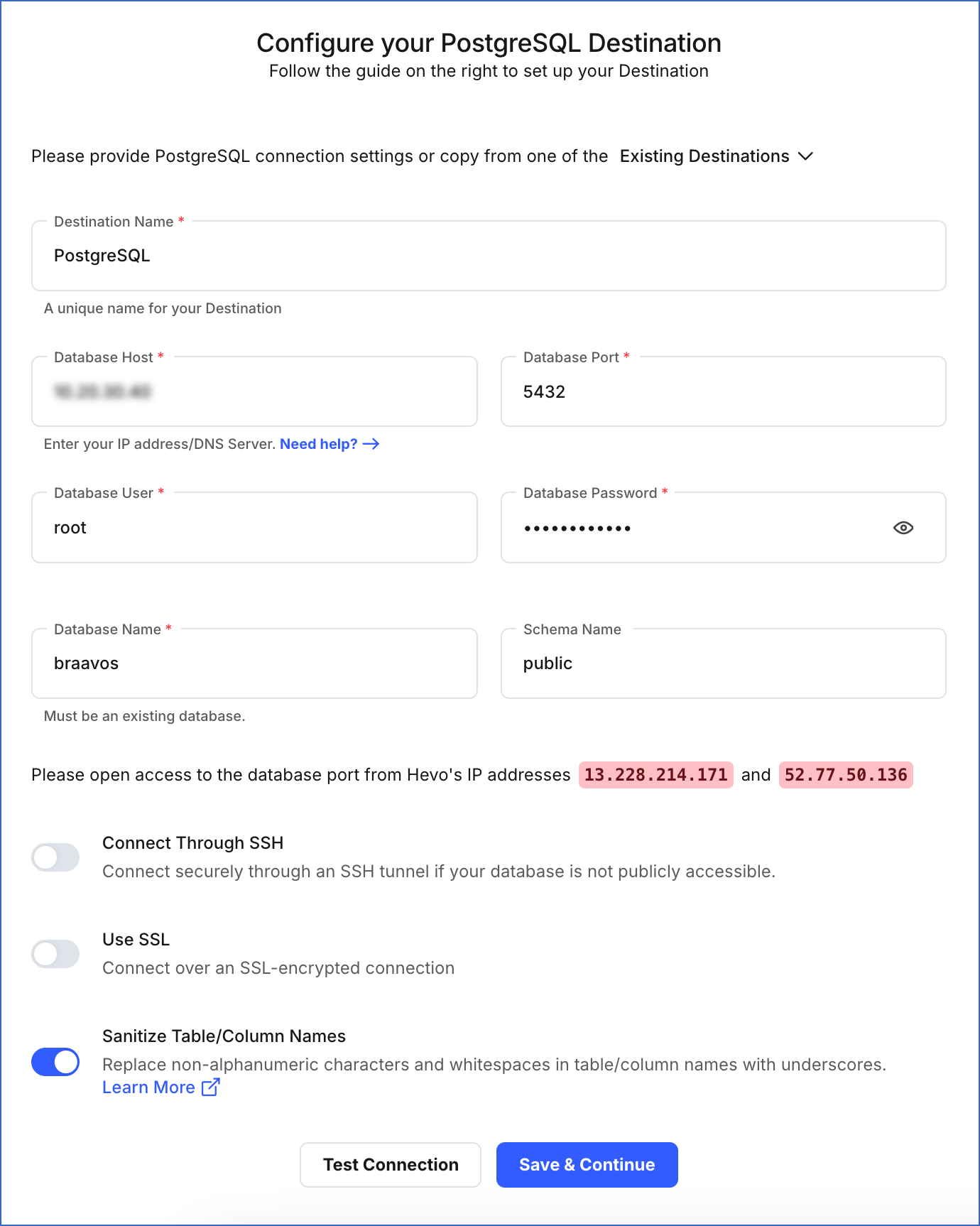
-
Destination Name: A unique name for your Destination, not exceeding 255 characters.
-
Database Host: The PostgreSQL host’s IP address or DNS.
-
Database Port: The port on which your PostgreSQL server listens for connections. Default value: 5432.
-
Database User: A user with a non-administrative role in the PostgreSQL database.
-
Database Password: The password of the database user.
-
Database Name: The name of the Destination database to which the data is loaded.
-
Schema Name (Optional): The name of the Destination database schema. Default value: public.
-
Additional Settings:
-
Connect through SSH: Enable this option to connect to Hevo using an SSH tunnel, instead of directly connecting your PostgreSQL database host to Hevo. This provides an additional level of security to your database by not exposing your PostgreSQL setup to the public. Read Connecting Through SSH.
If this option is disabled, you must whitelist Hevo’s IP addresses. You can refer to the PostgreSQL Source documentation pages for the steps to whitelist the IP addresses of your region for your PostgreSQL variant.
-
Use SSL: Enable this option to use an SSL-encrypted connection. Specify the following:
-
CA File: The file containing the SSL server certificate authority (CA).
-
Load all CA Certificates: If selected, Hevo loads all CA certificates (up to 50) from the uploaded CA file, else it loads only the first certificate.
Note: Select this check box if you have more than one certificate in your CA file.
-
Client Certificate: The client public key certificate file.
-
Client Key: The client private key file.
For the steps to create the required files and keys, read PostgreSQL
-
-
Sanitize Table/Column Names?: Enable this option to remove all non-alphanumeric characters and spaces in a table or column name, and replace them with an underscore (_). Read Name Sanitization.
-
-
-
Click Test Connection. This button is enabled once all the mandatory fields are specified.
-
Click Save & Continue. This button is enabled once all the mandatory fields are specified.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Destination Considerations
-
You must disable any foreign keys defined in the target tables. Foreign keys do not allow data to be loaded until the reference table has a corresponding key defined.
-
You can replicate data for only 1594 columns in a given PostgreSQL table. Read Limits on the Number of Columns.
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change | |
|---|---|---|---|
| Nov-12-2025 | NA | Updated the document as per the latest Hevo UI. | |
| Aug-19-2024 | NA | Updated sub-section, Grant privileges to the user to update the command. | |
| Mar-18-2024 | 2.21.2 | Updated section, Configure PostgreSQL Connection Settings to add information about the Load all CA certificates option. | |
| Apr-25-2023 | 2.12 | Updated section, Configure PostgreSQL Connection Settings to add information that you must specify all fields to create a Pipeline. | |
| Mar-23-2023 | NA | Updated section, Grant privileges to the user with new command. | |
| Jan-10-2023 | 2.05 | Added sections, Installing PostgreSQL and Creating a Database Cluster and Database to help set up a PostgreSQL Destination. | |
| Sep-07-2022 | NA | Updated the Prerequisites section and added the Create a Database User and Grant Privileges section. | |
| Feb-21-2022 | 1.82 | Updated section, Configure PostgreSQL Connection Settings to provide support for SSL in PostgreSQL as a Destination. | |
| Jul-12-2021 | NA | Updated section, Destination Considerations. |