On This Page
Starting Release 2.19, Hevo has stopped supporting XMIN as a query mode for all variants of the PostgreSQL Source. As a result, you will not be able to create new Pipelines using this query mode. This change does not affect existing Pipelines. However, you will not be able to change the query mode to XMIN for any objects currently ingesting data using other query modes.
Amazon Aurora PostgreSQL is a fully managed, PostgreSQL-compatible relational database engine that combines the speed and reliability of high-end commercial databases with the simplicity and cost-effectiveness of open-source databases. Its enterprise database capabilities combined with compatibility with PostgreSQL helps deliver throughput that is much higher compared to the standard PostgreSQL running on the same hardware.
You can ingest data from your Amazon Aurora PostgreSQL database using Hevo Pipelines and replicate it to a Destination of your choice.
Prerequisites
-
IP address or host name of your PostgreSQL server is available.
-
The PostgreSQL version is 9.6 or higher, up to 17.x.
-
Log-based incremental replication is enabled if ingestion mode is Logical Replication.
Note: Hevo currently does not support logical replication on read replicas.
-
SELECT, USAGE, and CONNECT privileges are granted to the database user.
Note: We recommend that you create a database user for configuring your Amazon Aurora PostgreSQL Source in Hevo. However, if you already have one, refer to section Grant privileges to the user.
-
You are assigned the Team Administrator, Team Collaborator, or Pipeline Administrator role in Hevo, to create the Pipeline.
Perform the following steps to configure your Amazon Aurora PostgreSQL Source:
Set up Log-based Incremental Replication
1. Create a parameter group
-
Log in to the Amazon RDS console.
-
In the left navigation pane, select Parameter groups.
-
On the Parameter groups page, click Create parameter group.
-
On the Create parameter group page, under Parameter group details, perform the following steps:
-
Specify the Parameter group name and Description, and select Aurora PostgreSQL from the Engine type drop-down.
-
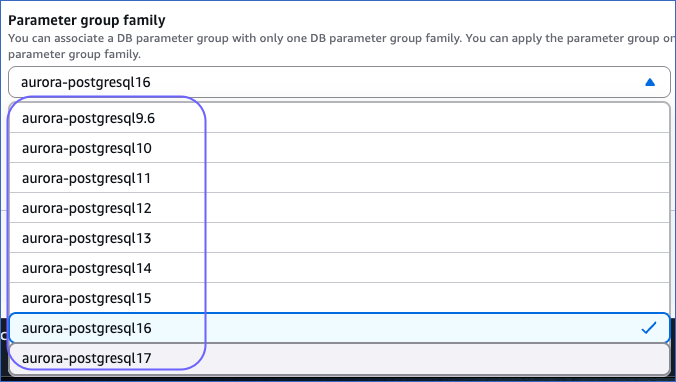
Select an aurora-postgresql version from the Parameter group family drop-down.
-
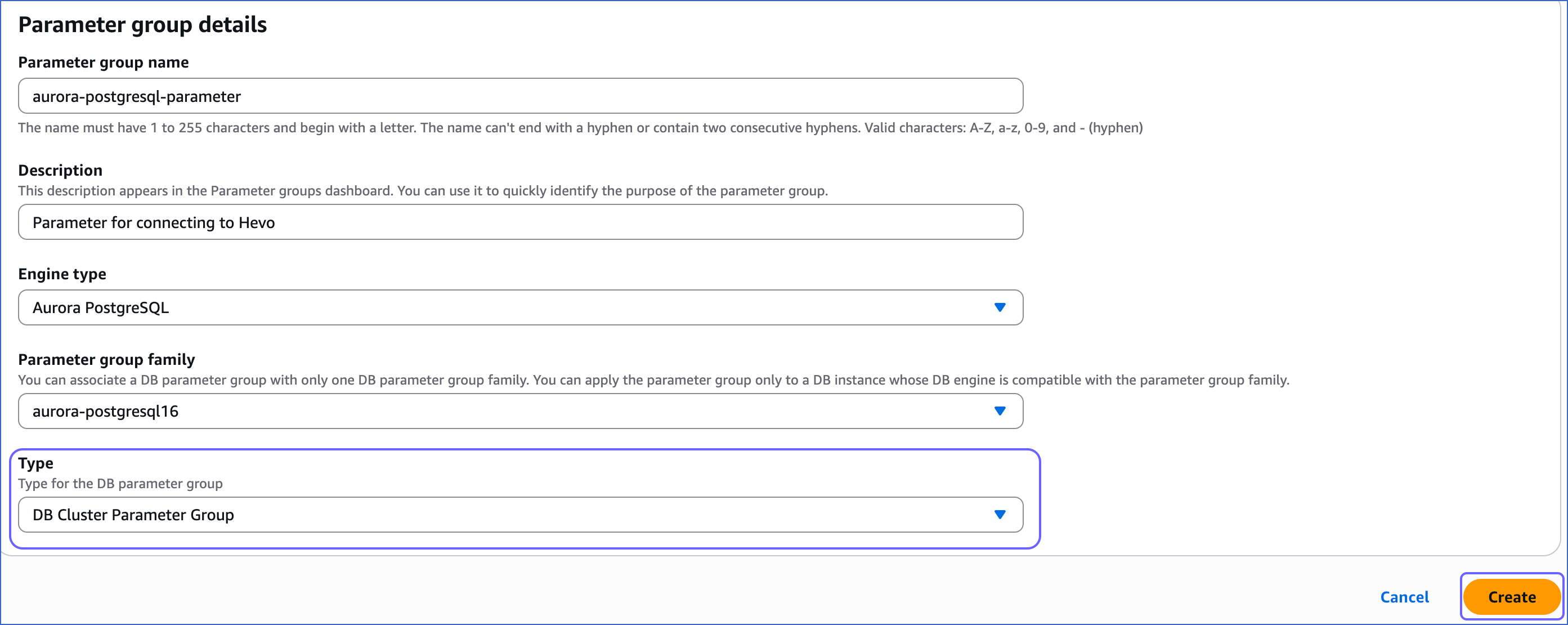
Select DB Cluster Parameter Group from the Type drop-down and then click Create.
You have successfully created a parameter group.
-
2. Configure the parameters
-
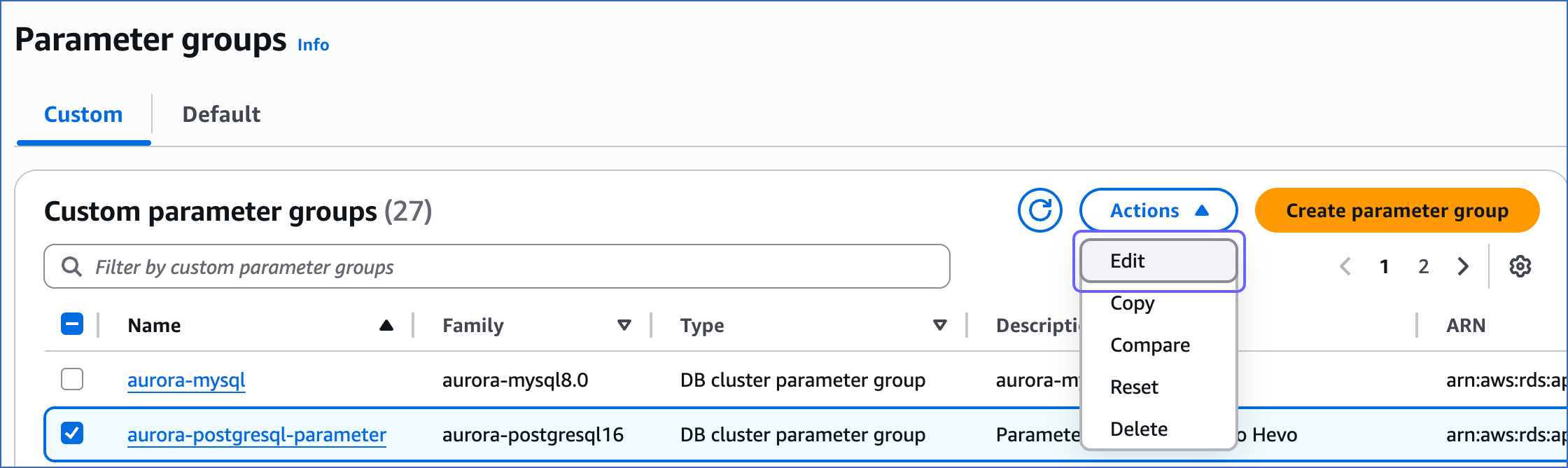
On the Parameter groups page, select the check box corresponding to the parameter group that you created above.
-
In the Actions drop-down, click Edit.
-
On the page that appears, search and update the value of the following parameters:

Parameter Value Description max_replication_slots5 The number of clients that can connect to the server. Default value: 10. RDS recommends to set this value to at least 5 so that internal replication by RDS is not affected. rds.logical_replication1 The setting to enable or disable logical replication. The value of 1 is required to enable write-ahead logging (WAL) at the logical level. wal_sender_timeout0 The time, in seconds, after which PostgreSQL terminates the replication connections due to inactivity. Default value: 60 seconds. You must set the value to 0 so that the connections are never terminated and your Pipeline does not fail.
You can use the following query to check the value configured for the parameter:
show wal_sender_timeout -
Click Save Changes.
3. Apply the parameter group to your PostgreSQL database
-
In your Amazon RDS console, click Databases in the left navigation pane.
-
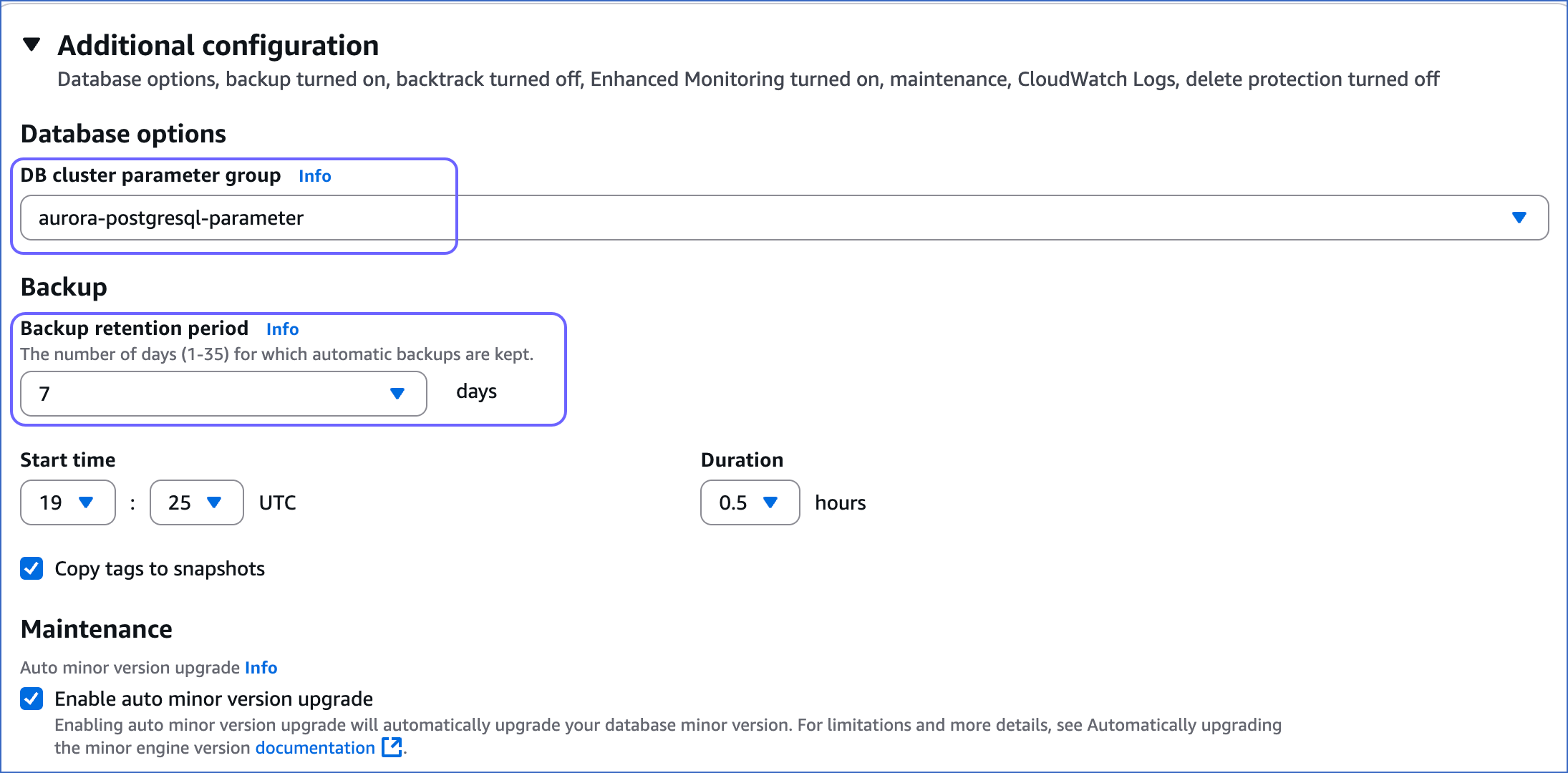
On the Databases page, click the DB identifier for your database, and then click Modify.
-
Select the DB cluster parameter group you just created.
-
Set the Backup retention period to at least 3 days. This setting defines the number of days for which automated backups are retained.
-
For the changes to take effect, reboot the DB instance.
Whitelist Hevo’s IP Addresses
You need to whitelist the Hevo IP addresses for your region to enable Hevo to connect to your PostgreSQL database.
To do this:
1. Add inbound rules
-
Open the Amazon RDS console.
-
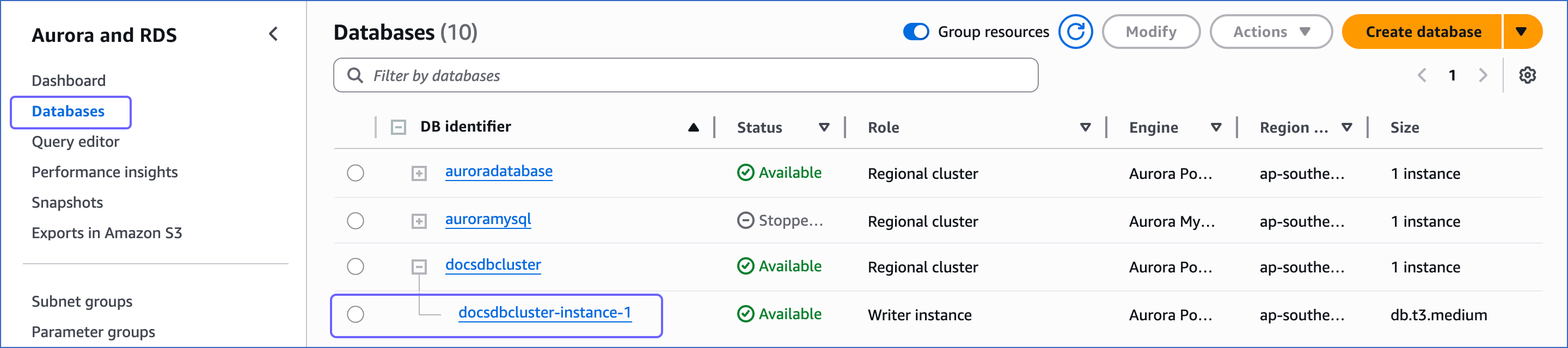
In the left navigation pane, click Databases.
-
In the Databases section on the right, click the DB identifier of the Amazon Aurora instance to configure a security group on.
-
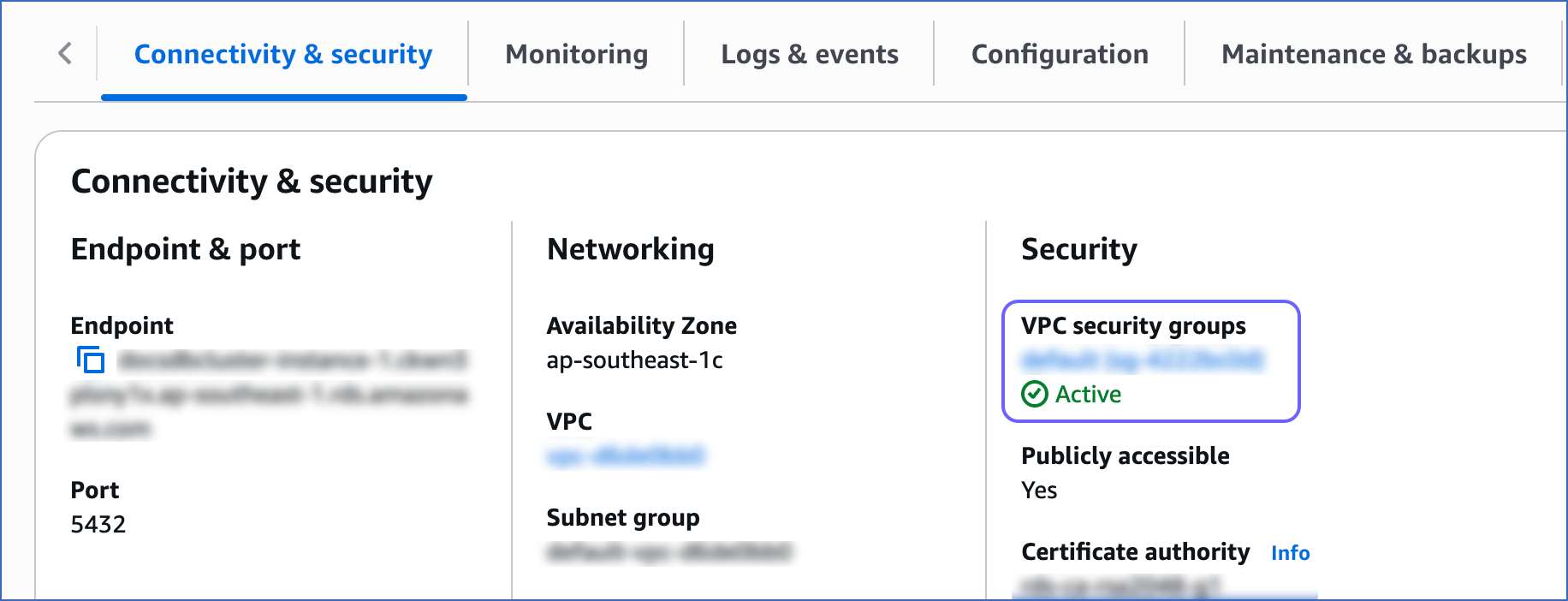
In the Connectivity & security tab, click the link text under Security, VPC security groups.
-
On the Security Groups page, select the check box for your Security group ID, and from the Actions drop-down, click Edit inbound rules.
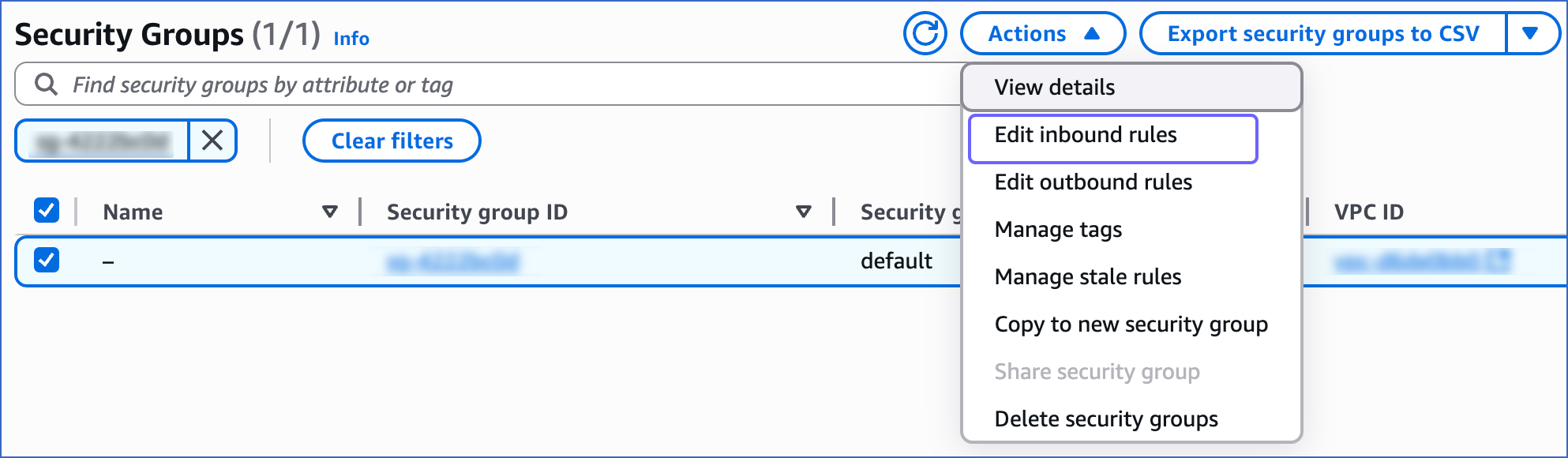
-
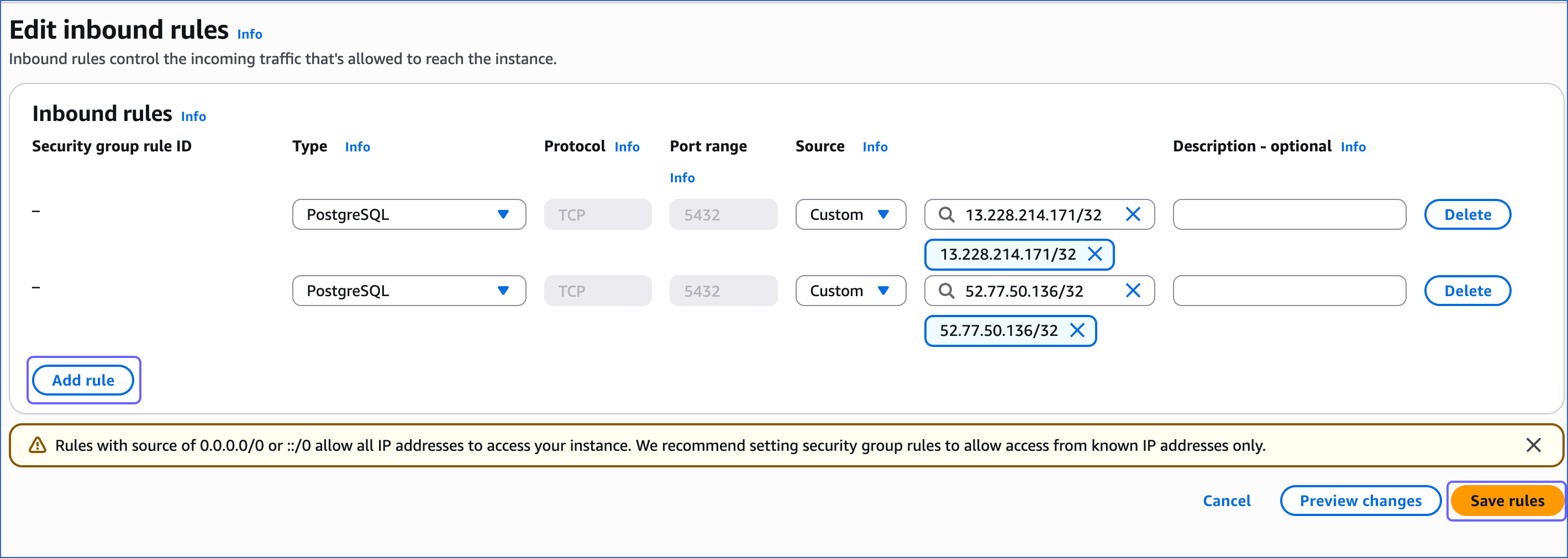
On the Edit inbound rules page:
-
Click Add rule.
-
Add a new rule with Hevo’s IP addresses for your region to give access to the PostgreSQL instance.
-
Click Save rules.
-
2. Configure Virtual Private Cloud (VPC)
-
Follow steps 1-3 from the section above.
-
In the Connectivity & security tab, click the link text under Networking, VPC.
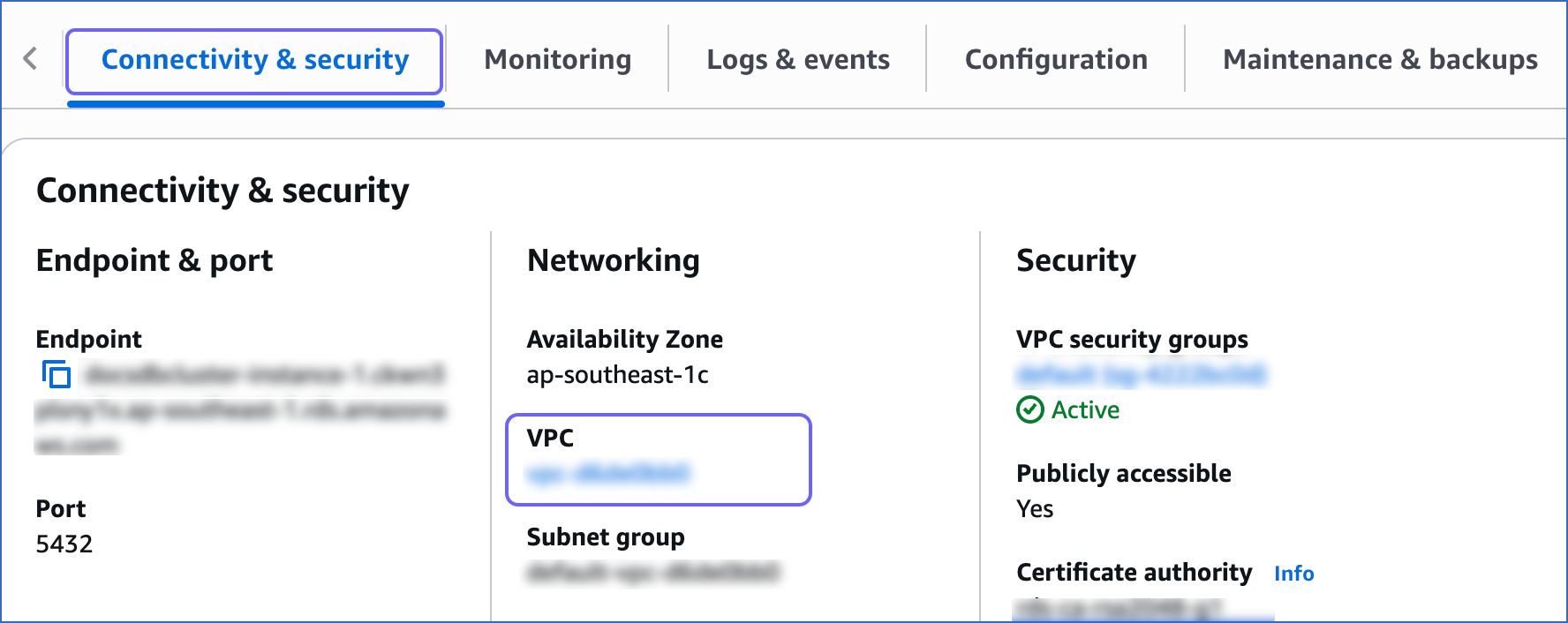
-
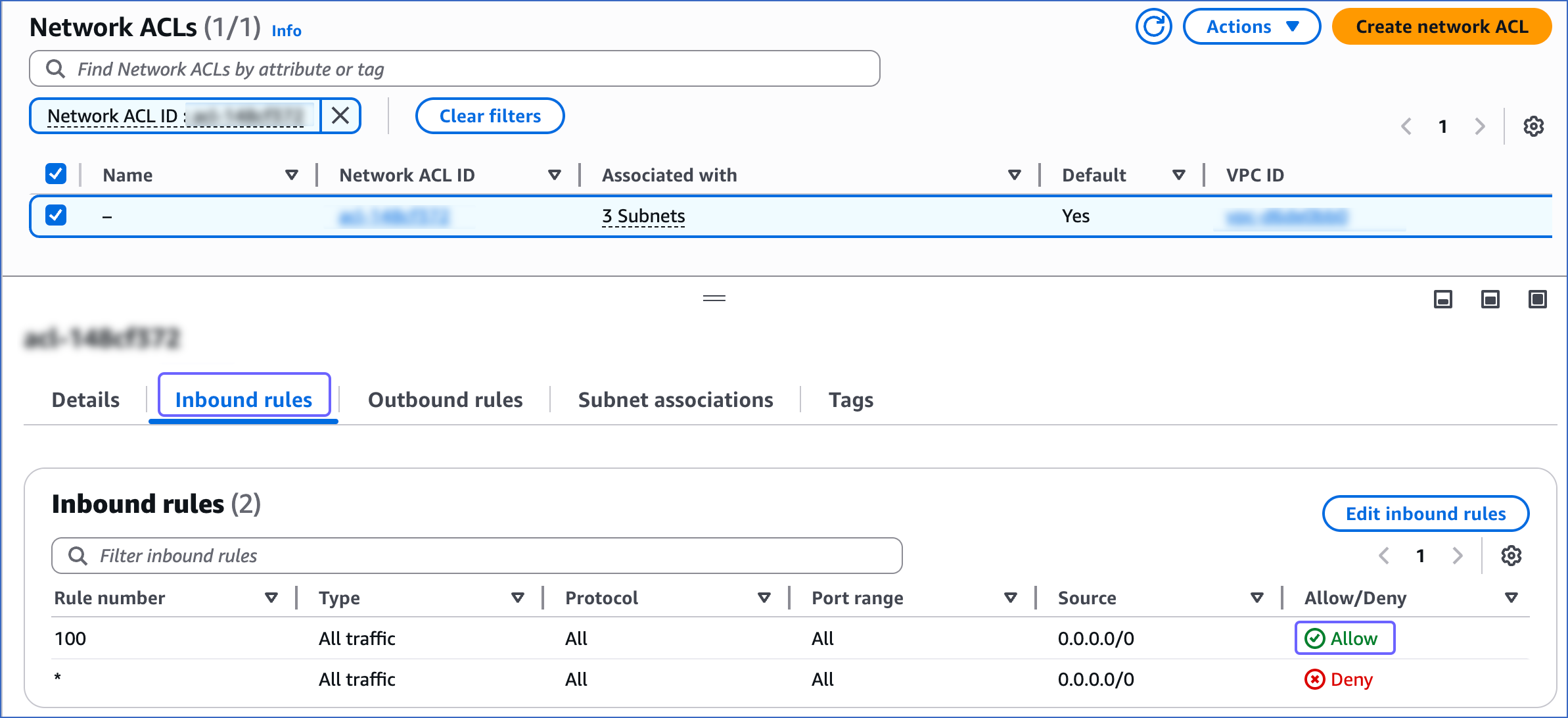
On the Your VPCs page, select the VPC ID, and then click the Main network ACL link text.
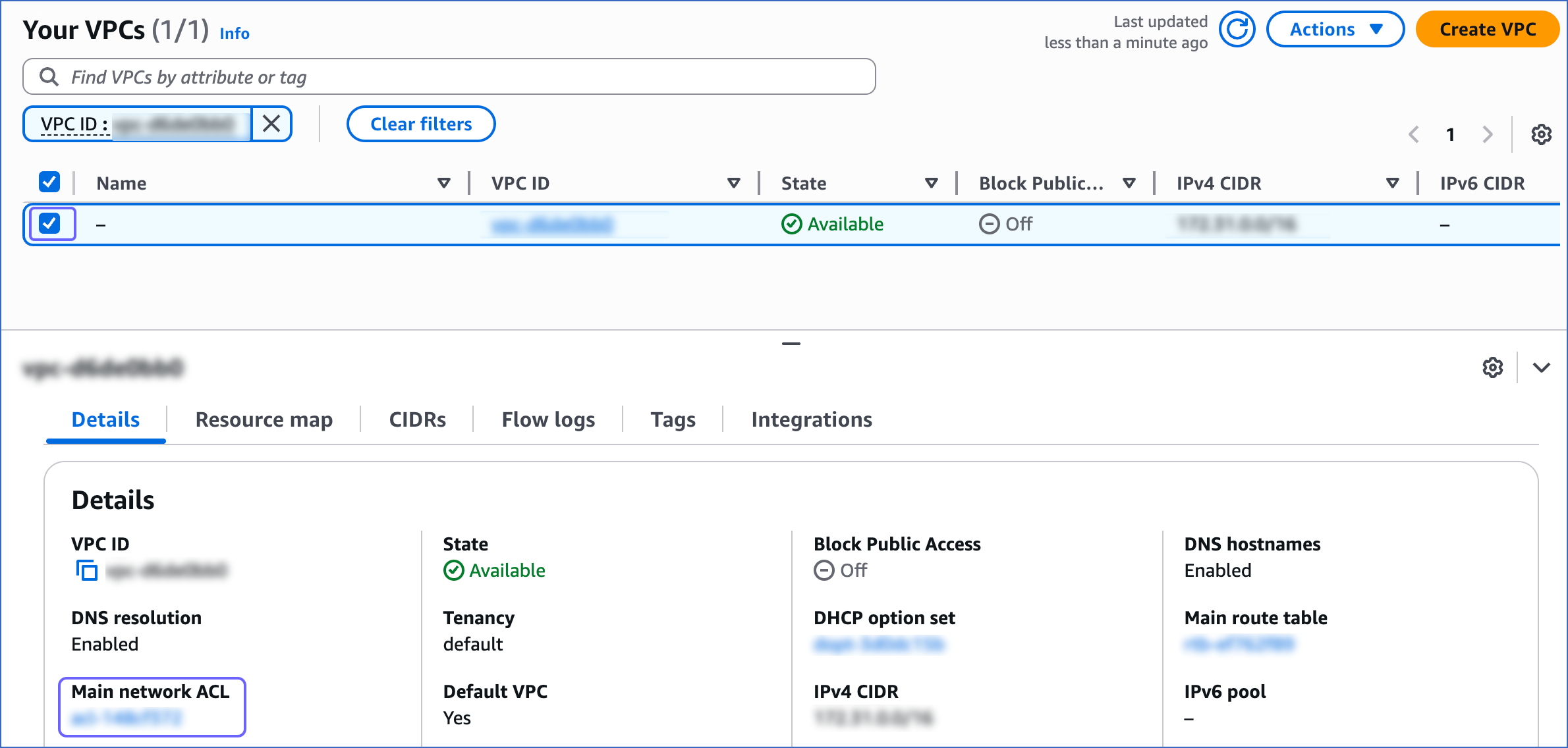
-
Click the Inbound Rules tab and ensure that the IP addresses you added have a setting of Allow.
Create a Database User and Grant Privileges
1. Create a database user (Optional)
Perform the following steps to create a user in your Amazon Aurora PostgreSQL database:
-
Connect to your Amazon Aurora PostgreSQL database instance as a root user with an SQL client tool, such as psql.
-
Create a database user:
CREATE USER <database_username> WITH LOGIN PASSWORD '<password>';Note: Replace the placeholder values in the command above with your own. For example, <database_username> with hevouser.
2. Grant privileges to the user
Grant privileges to the database user connecting to the PostgreSQL database as follows:
-
Connect to your Amazon Aurora PostgreSQL database instance as a root user with an SQL client tool, such as psql.
-
Run the following commands to grant privileges to the database user:
GRANT CONNECT ON DATABASE <database_name> TO <database_username>; GRANT USAGE ON SCHEMA <schema_name> TO <database_username>; GRANT SELECT ON ALL TABLES IN SCHEMA <schema_name> to <database_username>; -
Alter the schema’s default privileges to grant
SELECTprivileges on tables created in the future to the database user:ALTER DEFAULT PRIVILEGES IN SCHEMA <schema_name> GRANT SELECT ON TABLES TO <database_username>;Note: If you want to use Log-based Incremental Replication, grant the
rds_replicationrole to the database user. Log in to the database as a user with therds_superuserrole and run the following command:GRANT rds_replication TO <database_username>;
Note: Replace the placeholder values in the commands above with your own. For example, <database_username> with hevouser.
Specify Amazon Aurora PostgreSQL Connection Settings
Perform the following steps to configure Amazon Aurora PostgreSQL as a Source in Hevo:
-
Click PIPELINES in the Navigation Bar.
-
Click + Create Pipeline in the Pipelines List View.
-
On the Select Source Type page, select Amazon Aurora PostgreSQL.
-
On the Select Destination Type page, select the type of Destination you want to use.
-
On the page that appears, do the following:
-
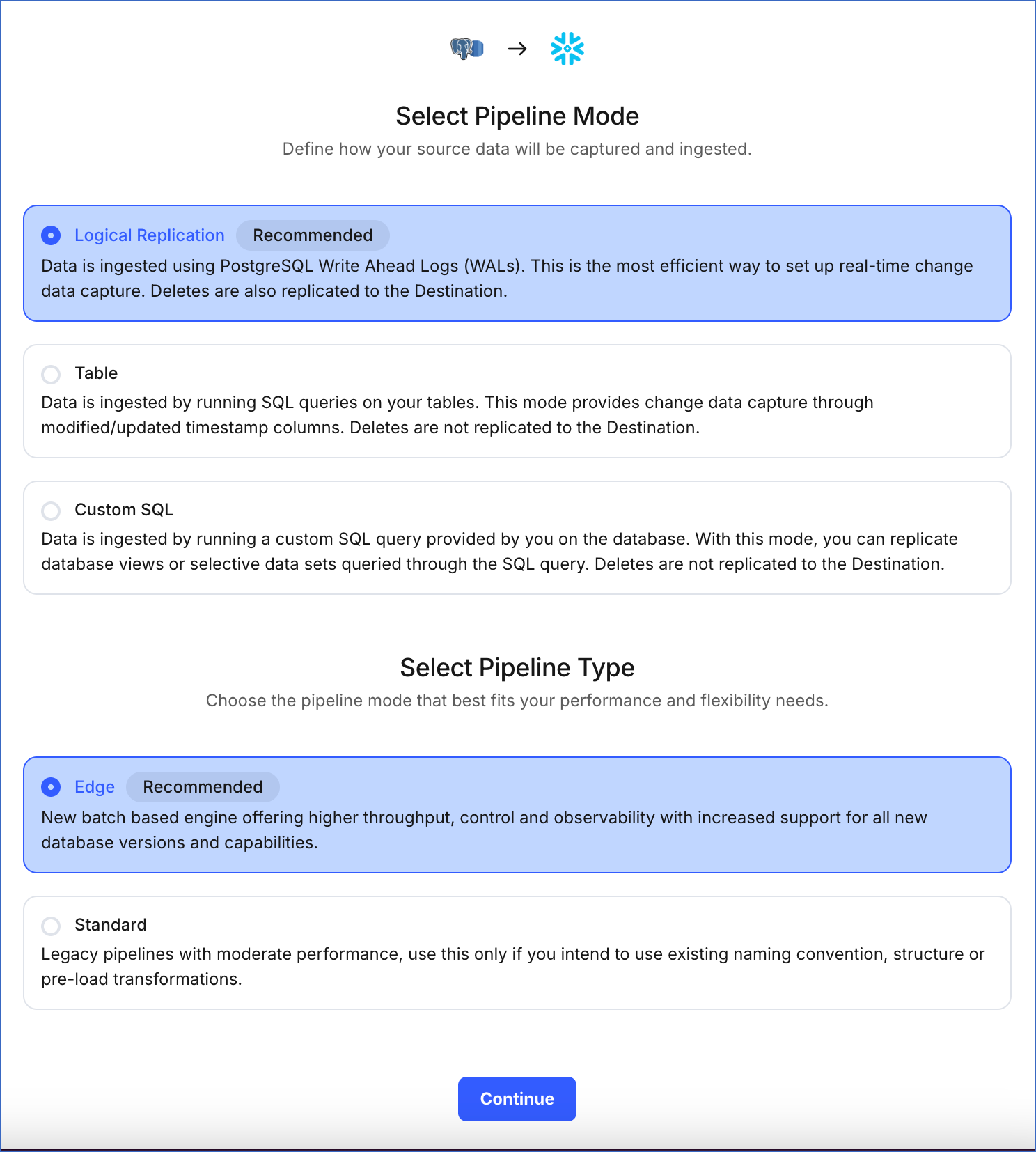
Select Pipeline Mode: Choose the mode for ingesting data from the Source. Default value: Logical Replication. The available modes are Logical Replication, Table, and Custom SQL. Additionally, the XMIN Pipeline mode is available for Early Access. Read Ingestion Modes for more information.
Depending on the Pipeline mode you select, you must configure the objects to be replicated. Refer to section, Object and Query Mode Settings for the steps to do this.
Note: For Custom SQL Pipeline mode, all Events loaded to the Destination are billable.
-
Select Pipeline Type: Choose the type of Pipeline you want to create based on your requirements, and then click Continue.
-
If you select Edge, read Amazon Aurora PostgreSQL to configure your Edge Pipeline.
-
If you select Standard, skip to step 6 below.
This section is displayed only if all the following conditions are met:
-
The selected Destination type is supported in Edge.
-
The Pipeline mode is set to Logical Replication.
-
Your Team was created before September 15, 2025, and has an existing Pipeline created with the same Destination type and Pipeline mode.
For Teams that do not meet the above criteria, if the selected Destination type is supported in Edge and the Pipeline mode is set to Logical Replication, you can proceed to create an Edge Pipeline. Read Amazon Aurora PostgreSQL to configure your Edge Pipeline. Otherwise, you can proceed to create a Standard Pipeline.
-
-
-
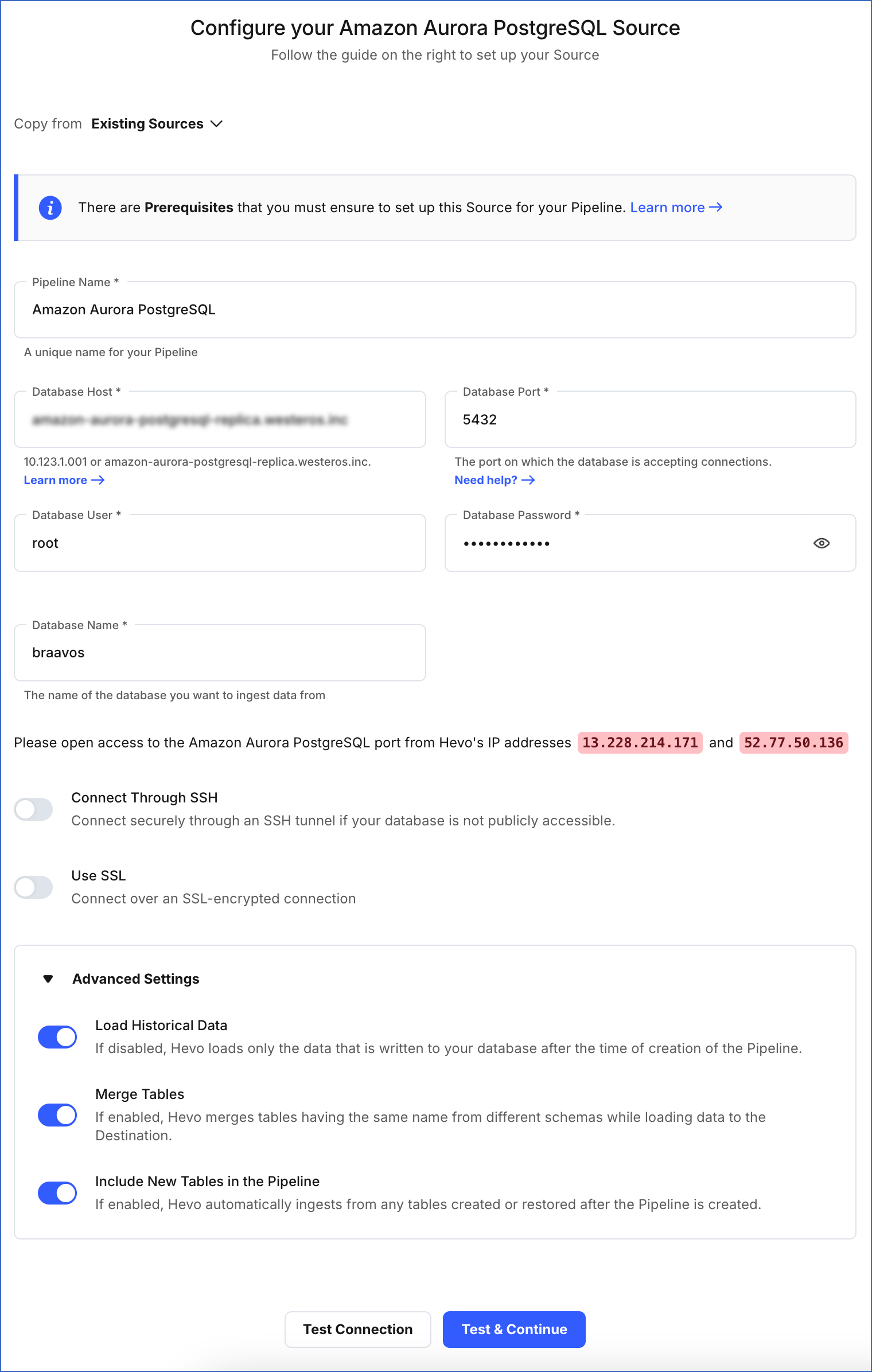
On the Configure your Amazon Aurora PostgreSQL Source page, specify the following:
-
Pipeline Name: A unique name for your Pipeline, not exceeding 255 characters.
-
Database Host: The Amazon Aurora PostgreSQL host’s IP address or DNS.
-
Database Port: The port on which your Amazon Aurora PostgreSQL server listens for connections. Default value: 5432.
-
Database User: The read-only user who has the permissions to read tables in your database.
-
Database Password: The password for the read-only user.
-
Database Name: The database that you wish to replicate.
-
Connection Settings:
-
Connect through SSH: Enable this option to connect to Hevo using an SSH tunnel, instead of directly connecting your PostgreSQL database host to Hevo. This provides an additional level of security to your database by not exposing your PostgreSQL setup to the public. Read Connecting Through SSH. To set up an SSH tunnel for your Amazon Aurora PostgreSQL database hosted on Amazon Web Services (AWS), read Configuring an SSH Tunnel.
If this option is disabled, you must whitelist Hevo’s IP addresses. Refer to the content for your PostgreSQL variant for steps to do this.
-
Use SSL: Enable it to use SSL encrypted connection. You should also enable this if you are using Heroku PostgreSQL databases. To enable this, specify the following:
-
CA File: The file containing the SSL server certificate authority (CA).
-
Load all CA Certificates: If selected, Hevo loads all CA certificates (up to 50) from the uploaded CA file, else it loads only the first certificate.
Note: Select this check box if you have more than one certificate in your CA file.
-
-
Client Certificate: The client public key certificate file.
-
Client Key: The client private key file.
-
-
-
Advanced Settings
-
Load Historical Data: Applicable for Pipelines created with Logical Replication or Table mode. If this option is enabled, the entire table data is fetched during the first run of the Pipeline. If disabled, Hevo loads only the records written to your database after the Pipeline was created.
-
Merge Tables: Applicable for Pipelines with Logical Replication mode. If this option is enabled, Hevo merges tables with the same name from different databases while loading the data to the warehouse. Hevo loads the Database Name field with each record. If disabled, the database name is prefixed to each table name. Read How does the Merge Tables feature work?.
-
Include New Tables in the Pipeline: Applicable for all ingestion modes except Custom SQL.
If enabled, Hevo automatically ingests data from tables created in the Source after the Pipeline has been built. These may include completely new tables or previously deleted tables that have been re-created in the Source. All data for these tables is ingested using database logs, making it incremental.
If disabled, new and re-created tables are not ingested automatically. They are added in SKIPPED state in the objects list, on the Pipeline Overview page. You can update their status to INCLUDED to ingest data.
You can change this setting later.
-
-
-
Click Test Connection. This button is enabled once you specify all the mandatory fields. Hevo’s underlying connectivity checker validates the connection settings you provide.
-
Click Test & Continue to proceed for setting up the Destination. This button is enabled once you specify all the mandatory fields.
Object and Query Mode Settings
Once you have specified the Source connection settings in Step 4 above, do one of the following:
-
For Pipelines configured with the Table or Logical Replication mode:
-
On the Select Objects page, select the objects you want to replicate and click Continue.

Note:
-
Each object represents a table in your database.
-
From Release 2.19 onwards, for log-based Pipelines, you can keep the objects listed in the Select Objects page deselected by default. In this case, when you skip object selection, all objects are skipped for ingestion, and the Pipeline is created in the Active state. You can include the required objects post-Pipeline creation. Contact Hevo Support to enable this option for your team.
-
-
On the Configure Objects page, specify the query mode you want to use for each selected object.

Note: In Full Load mode, Hevo attempts to replicate the full table in a single run of the Pipeline, with an ingestion limit of 25 Million rows.
-
-
For Pipelines configured with the XMIN mode:
-
On the Select Objects page, select the objects you want to replicate.
Note:
-
Each object represents a table in your database.
-
For the selected objects, only new and updated records are ingested using the
XMINcolumn. -
The Edit Config option is unavailable for the objects selected for XMIN-based ingestion. You cannot change the ingestion mode for these objects post-Pipeline creation.
-
-
Click Continue.
-
-
For Pipelines configured with the Custom SQL mode:
-
On the Provide Query Settings page, enter the custom SQL query to fetch data from the Source.
-
In the Query Mode drop-down, select the query mode, and click Continue.

-
Data Replication
| For Teams Created | Ingestion Mode | Default Ingestion Frequency | Minimum Ingestion Frequency | Maximum Ingestion Frequency | Custom Frequency Range (in Hrs) |
|---|---|---|---|---|---|
| Before Release 2.21 | Table | 15 Mins | 15 Mins | 24 Hrs | 1-24 |
| Log-based | 5 Mins | 5 Mins | 1 Hr | NA | |
| After Release 2.21 | Table | 6 Hrs | 30 Mins | 24 Hrs | 1-24 |
| Log-based | 30 Mins | 30 Mins | 12 Hrs | 1-24 |
Note: The custom frequency must be set in hours as an integer value. For example, 1, 2, or 3 but not 1.5 or 1.75.
-
Historical Data: In the first run of the Pipeline, Hevo ingests all available data for the selected objects from your Source database.
-
Incremental Data: Once the historical load is complete, data is ingested as per the ingestion frequency.
Additional Information
Read the detailed Hevo documentation for the following related topics:
Source Considerations
-
If you add a column with a default value to a table in PostgreSQL, entries with it are created in the WAL only for the rows that are added or updated after the column is added. As a result, in the case of log-based Pipelines, Hevo cannot capture the column value for the unchanged rows. To capture those values, you need to:
-
Restart the historical load for the respective object.
-
Run a query in the Destination to add the column and its value to all rows.
-
-
When you delete a row in the Source table, its XMIN value is deleted as well. As a result, for Pipelines created with the XMIN Pipeline mode, Hevo cannot track deletes in the Source object(s). To capture deletes, you need to restart the historical load for the respective object.
-
XMIN is a system-generated column in PostgreSQL, and it cannot be indexed. Hence, to identify the updated rows in Pipelines created with the XMIN Pipeline mode, Hevo scans the entire table. This action may lead to slower data ingestion and increased processing overheads on your PostgreSQL database host. Due to this, Hevo recommends that you create the Pipeline in the Logical Replication mode.
Note: The XMIN limitations specified above are applicable only to Pipelines created using the XMIN Pipeline mode, which is currently available for Early Access.
-
PostgreSQL retains Write-Ahead Logs (WALs) until all replication clients, such as Hevo or other consumers, have acknowledged the receipt of relevant changes. In other words, PostgreSQL waits for each client to catch up to a certain point in the WAL stream before it can safely discard older logs. As a result, the WAL size may grow even though Hevo consistently ingests new changes without lag and has no backlog. This growth can be due to long-running transactions, inactive or lagging replicas, or delays in PostgreSQL’s internal cleanup. If the WAL size exceeds the retention threshold, PostgreSQL may drop the replication slot, causing Pipeline failure. To prevent this, monitor long-running transactions and ensure other replication clients are progressing as expected. Read Viewing Statistics in PostgreSQL.
Limitations
-
If you are using PostgreSQL version 17.x, Hevo does not support logical replication failover. As a result, if your standby server is promoted to primary, Hevo will not synchronize the replication slots from the primary server with the standby. This can lead to Pipeline failures.
-
The data type Array in the Source is automatically mapped to Varchar at the Destination. No other mapping is currently supported.
-
Hevo does not support data replication from foreign tables, temporary tables, and views.
-
Hevo supports only RSA keys for establishing SSL connections. Hence, you must ensure that your SSL certificates and keys are generated using the RSA encryption algorithm.
-
Hevo does not load data from a column into the Destination table if its size exceeds 16 MB, and skips the Event if it exceeds 40 MB. If the Event contains a column larger than 16 MB, Hevo attempts to load the Event after dropping that column’s data. However, if the Event size still exceeds 40 MB, then the Event is also dropped. As a result, you may see discrepancies between your Source and Destination data. To avoid such a scenario, ensure that each Event contains less than 40 MB of data.
-
For log-based Pipelines, you may see duplicate data in your Destination tables for interleaved transactions. This occurs because Hevo may replicate data from the WAL multiple times for the nested transactions.
-
Hevo does not support the TimescaleDB extension for PostgreSQL databases. If your Pipeline uses logical replication to ingest data, Hevo cannot replicate data from the hypertables created by this extension. However, you can ingest data from these databases using the Table or Custom SQL modes.
Note: In Hevo, the Table and Custom SQL ingestion modes capture only inserts and updates; deletes are not captured.
See Also
Revision History
Refer to the following table for the list of key updates made to this page:
| Date | Release | Description of Change |
|---|---|---|
| Nov-06-2025 | NA | Updated the document as per the latest Hevo UI. |
| Oct-29-2025 | NA | Added a limitation about Hevo not supporting the TimescaleDB extension. |
| Oct-13-2025 | NA | Updated section, Specify Amazon Aurora PostgreSQL Connection Settings to clarify when the Select Pipeline Type section is displayed during Pipeline configuration. |
| Oct-09-2025 | NA | Updated section, Specify Amazon Aurora PostgreSQL Connection Settings to mention that the Load Historical Data option is also applicable for Pipelines created with Table mode. |
| Sep-18-2025 | NA | Updated section, Specify Amazon Aurora PostgreSQL Connection Settings as per the latest UI. |
| Sep-16-2025 | NA | Updated the Prerequisites section to add a note about read replicas. |
| Sep-04-2025 | NA | Updated sections, Prerequisites, Specify Amazon Aurora PostgreSQL Connection Settings, and Source Considerations to remove references regarding read replica support. |
| Aug-01-2025 | NA | Added clarification that data ingested from new and re-created tables is billable. |
| Jul-22-2025 | NA | Updated sections, Prerequisites to add information about the maximum supported version of PostgreSQL and Limitations to mention that Hevo does not support logical replication failover for PostgreSQL version 17.x. |
| Jul-21-2025 | NA | Updated the document as per the latest Amazon Aurora PostgreSQL UI. |
| Jul-08-2025 | NA | Updated section, Prerequisites to add information about the maximum supported version of PostgreSQL. |
| Jul-07-2025 | NA | Updated the Limitations section to inform about the max record and column size in an Event. |
| Jun-23-2025 | NA | Updated section, Source Considerations to add information about WAL size growth issue in PostgreSQL. |
| Jun-02-2025 | NA | Added a limitation about duplicate data for interleaved transactions. |
| Jan-07-2025 | NA | Updated the Limitations section to add information on Event size. |
| Nov-18-2024 | NA | Updated sub-section, Create a parameter group as per the latest Amazon Aurora PostgreSQL UI. |
| Sep-30-2024 | NA | Updated sections, Prerequisites and Source Considerations to add information about the logical replication support for read replicas. |
| Jun-27-2024 | NA | Updated section, Limitations to add information about Hevo supporting only RSA-based keys. |
| May-30-2024 | NA | Updated section, Grant privileges to the user to add all the necessary permissions. |
| Apr-29-2024 | NA | Updated section, Specify Amazon Aurora PostgreSQL Connection Settings to include more detailed steps. |
| Mar-18-2024 | 2.21.2 | Updated section, Specify Amazon Aurora PostgreSQL Connection Settings to add information about the Load all CA certificates option. |
| Mar-05-2024 | 2.21 | Added the Data Replication section. |
| Feb-05-2024 | NA | Updated sections, Specify Amazon Aurora PostgreSQL Connection Settings and Object and Query Mode Settings to add information about the XMIN ingestion mode. |
| Jan-22-2024 | 2.19.2 | Updated section, Object and Query Mode Settings to add a note about the enhanced object selection flow available for log-based Pipelines. |
| Jan-10-2024 | NA | - Updated section, Source Considerations to add information about limitations of XMIN query mode. - Removed mentions of XMIN as a query mode. |
| Nov-03-2023 | NA | Renamed section, Object Settings to Object and Query Mode Settings. |
| Oct-27-2023 | NA | Added subsection, Create a database user. |
| Oct-18-2023 | NA | Updated section, Apply the parameter group to your PostgreSQL database to add information about rebooting an AWS instance. |
| Sep-19-2023 | NA | Updated section, Limitations to add information about Hevo not supporting data replication from certain tables. |
| Sep-11-2023 | NA | Updated the page as per the latest AWS UI. |
| Jun-26-2023 | NA | Udpated section, Source Considerations to add information about capturing data for columns with default values. |
| Apr-21-2023 | NA | Updated section, Specify Amazon Aurora PostgreSQL Connection Settings to add a note to inform users that all loaded Events are billable for Custom SQL mode-based Pipelines. |
| Mar-09-2023 | 2.09 | Updated section, Specify Amazon Aurora PostgreSQL Connection Settings to mention about SEE MORE in the Select an Ingestion Mode section. |
| Dec-19-2022 | 2.04 | Updated section, Specify Amazon Aurora PostgreSQL Connection Settings to add information that you must specify all fields to create a Pipeline. |
| Dec-07-2022 | 2.03 | Updated section, Specify Amazon Aurora PostgreSQL Connection Settings to mention about including skipped objects post-Pipeline creation. |
| Dec-07-2022 | 2.03 | Updated section, Specify Amazon Aurora PostgreSQL Connection Settings to mention about the connectivity checker. |
| Jul-04-2022 | NA | - Added sections, Specify Amazon Aurora PostgreSQL Connection Settings and Object Settings. |
| Apr-25-2022 | NA | - Added section, Source Considerations. - Added a prerequisite for connecting to a master database if logical replication is required. |
| Feb-07-2022 | 1.81 | Updated section, Whitelist Hevo’s IP Address to remove details about Outbound rules as they are not required. |
| Jan-24-2022 | 1.80 | Removed from Limitations that Hevo does not support UUID datatype as primary key. |
| Dec-20-2021 | 1.78 | Updated section, Configure the parameters. |
| Sep-09-2021 | 1.71 | Updated the section, Limitations to include information about columns with the UUID data type not being supported as a primary key. |
| Jun-14-2021 | 1.65 | Updated the Grant Privileges to the User section to include latest commands. |